×![]()

 All blog posts
All blog postsLabelbox•October 8, 2021
How to improve model performance with active learning

The concept of data-centric machine learning, promoted widely by leaders in AI such as Andrew Ng in recent months, is quickly taking root in the enterprise machine learning community.
Enterprises are treating their training data as IP because it’s the only component of machine learning that requires creativity and domain expertise to collect, organize, and curate. In this post, we’ll dive into some of the specific challenges of data-centric machine learning, and how your team can address them by employing active learning in ML methods.
Three challenges in data-centric machine learning

Taking a data-first approach to machine learning comes with its own specific challenges in data management, data analysis, and labeling.
- Data management. The experimental nature of machine learning usually leads to a patchwork management system. They’re generally difficult to reproduce and lack a centralized space for data storage and data exploration tools, which makes finding patterns in the data challenging.
- Getting insights from data. Data from the real world is complex, and it’s a challenge to find underlying patterns without spending hours studying individual assets. Teams might not know whether it’s possible to solve a business problem without first exploring the data. Without a reliable set of tools to help them dig deeper into the data, ML teams can find themselves overwhelmed or stuck.
- Labeling velocity. Most ML teams tend to collect large quantities of data for labeling without understanding the value that the data delivers. This approach is both costly and prevents them from adjusting their requirements quickly.
Active learning in ML can help alleviate all three of these issues. Through automation, ML teams can improve data management, gain better insights into their data, and improve the rate of iteration.
Step one: Centralize your data for better active learning
One of the foundational steps for building an active learning pipeline is to bring all the data relevant to your project, along with metadata such as embedding, previous annotations, and model predictions, together. This enables teams to access their data quickly at any time, and iterate faster.
Step two: Label a small, specific dataset
Rather than sending all the data off to be labeled at once — usually an expensive and time consuming approach — teams should instead pull together a small, curated dataset to build a baseline version of their model. Choose assets that will help the model find a general understanding of the task at hand, and ensure that all major classes of interest are represented.
If it’s available and applicable, teams can pull in an off-the-shelf model to establish a model-assisted labeling workflow. Pre-labeling images can save labelers a significant amount of time and bring the team to their first iteration much faster.
Step three: Establish a baseline model for active learning
ML teams often fail to measure their model’s performance early and often. The baseline model for active learning is a perfect point to pause and understand the nuances of its performance. Teams can then use that information to communicate with stakeholders and pivot their strategy if necessary. They may also choose to train a couple of different variations here to find the best possible baseline version.
Because ML teams have full control over the data they use for training their model, they should focus efforts on powering the iterative cycle over optimizing the model at an early stage. The baseline model for active learning will also help to identify errors, either with the data or the model itself, which can be leveraged for further iterations.
Step four: Diagnose and iterate
Teams can now establish a comprehensive iterative process, involving a detailed diagnosis of the model’s performance, a new labeled dataset informed by model performance as well as any adjustments from stakeholders, and automated workflows like model-assisted labeling that increase label quality and the speed of the iterative cycle.
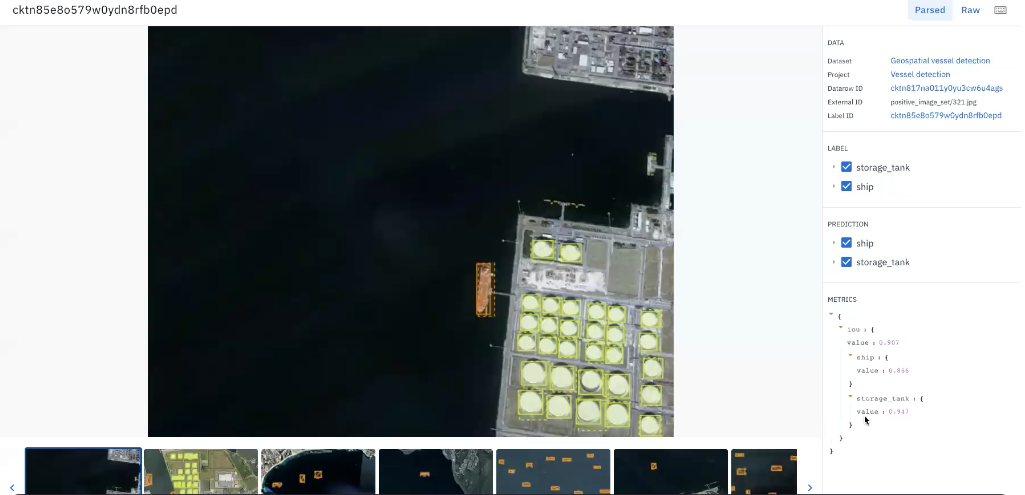
There are four types of model errors that commonly occur, and can be addressed as soon as they emerge when following this process:
- Data distribution errors occur when the model is confused by slight differences, such as color spectrum, in the same class. To address this type of error, teams can sample from a new data stream to determine how much corrective action they need to take.
- Concept clarity issues arise when new classifications, incorrect labels, and/or incomplete ontologies cause the model performance to suffer. It can be addressed by optimizing labeling operations and folding domain expertise into the process.
- Class frequency errors occur when the model hasn’t seen enough of a particular class, or there’s a large imbalance between class representation within the training data. Teams can leverage active learning here — for example, using similarity to mine for more assets of a particular class.
- Outlier errors often require special treatment, because they usually represent issues that the team doesn’t understand well about the data. They can be addressed by excluding that type of data from the dataset, rebuilding the ontology, or by redesigning the approach to include that circumstance.
Final thoughts on improving model performance with active learning
With insights from model errors analysis and their baseline model, teams can once again deliberately select assets from their larger pool rather than randomly sampling data. To learn how you can use Labelbox to diagnose your model’s errors and curate your next labeled dataset, watch our webcast.


