×![]()

 All blog posts
All blog postsLabelbox•March 11, 2022
How to use vector embeddings to create high-quality training data

Functions and embeddings in machine learning (ML) are a powerful way to quickly search and explore your unlabeled and labeled data. Using them can help you break down silos across datasets so you can focus on curating and labeling the data that will most significantly improve model performance.
When it comes to producing high-quality training data for data-centric AI, labeling is only one part of the solution. The most successful training datasets are carefully curated to increase model performance at each iteration. For example, if a model being trained to recognize various fruits in images has subpar performance in identifying apples, the next dataset used to train that model should contain more images of apples.
However, combing through a large unstructured dataset for just the right assets can be a challenge. Advanced AI teams have discovered a solution: using ML embeddings to sort through both labeled and unlabeled data.
What is an embedding in machine learning?
An embedding, or feature vector, in machine learning is an array of numbers assigned to an asset by a neural net. Assets that have similar content will also have similar embeddings. For example, in a dataset comprising images of apples and oranges, an appropriate embedding used for image similarity will show that all the vectors corresponding to apples have similar values. The vectors for all images of oranges will also be grouped together.
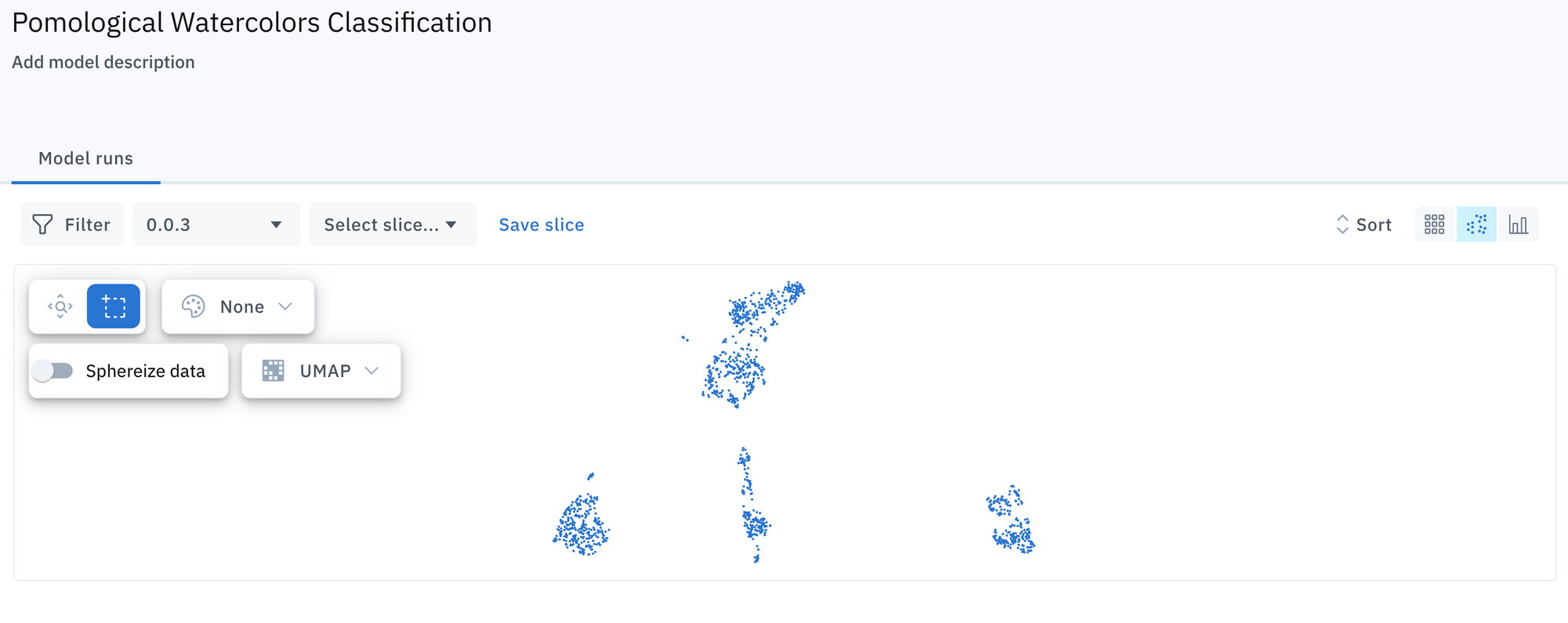
These similarity embeddings are typically generated by a convolutional neural network (CNN) and have dimensions in the order of thousands. Once you have implemented ML embeddings, similarity search is just a matter of comparing the distances between these vectors.
You can visualize embeddings by using certain techniques to “project” the points from their high dimensional space onto a plane. This can be especially useful to determine patterns in the data, like images from the same class forming clusters.
How to generate embeddings for images and text
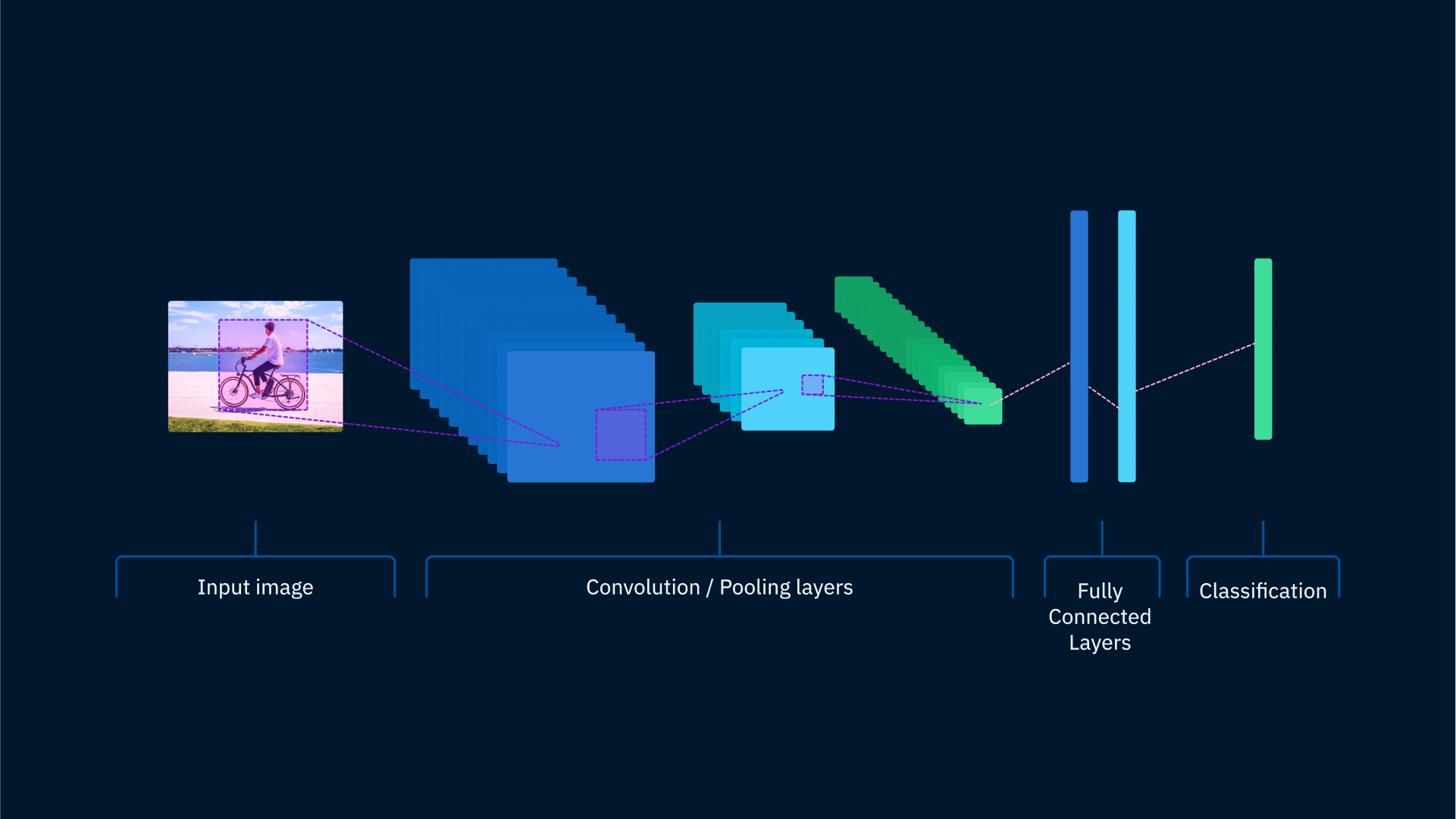
As explained above, similarity embeddings typically come out of a neural network. The diagram below shows a simplified version of what a typical classification CNN looks like.
Near the end of a neural network, before the last layer that determines the class the network will select, there’s usually one or more fully connected layers. To generate a similarity embedding for an image, input that image into the neural network and then take the values from the last fully connected layer.
The code below uses Tensorflow to load an EfficientNet pre-trained neural network and generate an embedding vector for an image:
import numpy as np
from tensorflow.keras.applications.efficientnet import EfficientNetB2
from tensorflow.keras.applications.efficientnet import preprocess_input
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing import image
efnet = EfficientNetB2(weights='imagenet')
# This is the image file we'll process
file = 'pepe.jpg'
img = image.load_img(file, target_size=(260, 260))
# Preprocess image
x = preprocess_input(np.expand_dims(img.copy(), axis=0))
# Make a new model where the output is the layer we care about
bottleneck_model = Model(inputs=efnet.input, outputs=efnet.get_layer('avg_pool').output)
# Then extract the features, which is basically a 1408-long vector
bottleneck_features = bottleneck_model.predict(x).reshape(1408)
print (bottleneck_features.shape)
print (bottleneck_features)To generate ML embeddings for text data, the process is similar, except that we use a neural network trained on text.
In the example below, the code is a lot more compact because the model was trained specifically to generate embeddings, so it’s not necessary to “tweak” a classification model.
import tensorflow_hub as hub
import numpy as np
import tensorflow_text
text = ['The quick brown fox jumps over the lazy dog']
model = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual/3")
# Compute embeddings.
embedding = model(text)
How to use embeddings in machine learning to find similar data in Labelbox
Labelbox’s embeddings projector makes it easy for AI teams to identify groups of similar assets within a dataset, filter them accordingly, and carefully curate their next training dataset based on where their model needs to improve. Embeddings can be imported via the Labelbox SDK (using precomputed embeddings is also an option).
Teams can then use the Catalog to conduct a similarity search to sort the assets by selecting one or more data rows and then selecting the “View Similar Data Rows'' option from the blue drop down menu on the top right. You can also select which embedding to use for the similarity search, including any custom embeddings previously uploaded with the SDK. Chosen assets can then be sent into a labeling project as a batch for labeling.
How to use functions in Labelbox to automatically find edge cases
- Identify edge cases or low-performing classes in your model
- Create functions to find similar low-performing data
- Use functions to find similar data when new data is uploaded
A function is a saved similarity search that you can use as a filter to find visually similar data. Functions are a useful way to find relevant new data rows as they are added to your workspace. To create a new function in Labelbox, navigate to the Catalog and select the “View Similar Data Rows” option in the drop-down menu. The actively selected data rows and the chosen embedding metadata field will be used to define the function. Once you have created the function, it will start a background task to score all of the data rows that share the ML embedding.
A function can also be used as a filter in the left hand side panel in Catalog. You can mix function queries with all other filter types in Catalog. For additional details, please refer to the help section on Functions in our documentation.
Start curating high-value data faster
Functions and embeddings are a powerful way to quickly search and explore your unlabeled and labeled data. Using them can help you break down silos across datasets so you can focus on curating and labeling the data that will most significantly improve model performance. These features are available to all users on Labelbox. Sign in or create a free account to try it today!


