×![]()

 All blog posts
All blog postsLabelbox•June 27, 2022
How VirtuSense built an AI data engine that dramatically increased model performance

When VirtuSense founder Deepak Gaddipati’s active and healthy grandmother had a fall, broke her hip, and passed away within days due to resulting complications, it left the entire family shocked — even the physicians in the family. No one had known that she was a fall risk, as she’d never fallen before. The tragedy led Gaddipati to research how hospitals and care facilities could better identify fall risks and prevent similar deaths. He began his research in 2012, and by 2014, he had founded VirtuSense, an AI-based system of sensors that monitors the activity of patients and alerts caretakers when their movements indicate they may be at risk for a fall.
Every hour, seven people die as a result of fall-related injuries in the United States. Today, VirtuSense is the #1 fall prevention system in the world. In the past two and a half years, the system has successfully prevented over 100,000 falls, saving tens of thousands of lives.
How it works
VirtuSense places LiDAR sensors in each hospital room, ambulance, or care facility room. These sensors generate data of patients’ movements as they lay in bed, sit up, stand, and walk around. The company’s AI models, placed within these edge devices, are trained to find and track movement patterns that, based on peer-reviewed research, identify potential falls 30-65 seconds before they occur. The system will then generate alerts for nearby hospital staff when the model detects fall risks. Expanding upon their initial success, VirtuSense systems now also detects risks for pressure ulcers and alerts bed-ridden individuals and/or their caregivers to shift their postures and prevent ulcers from forming.
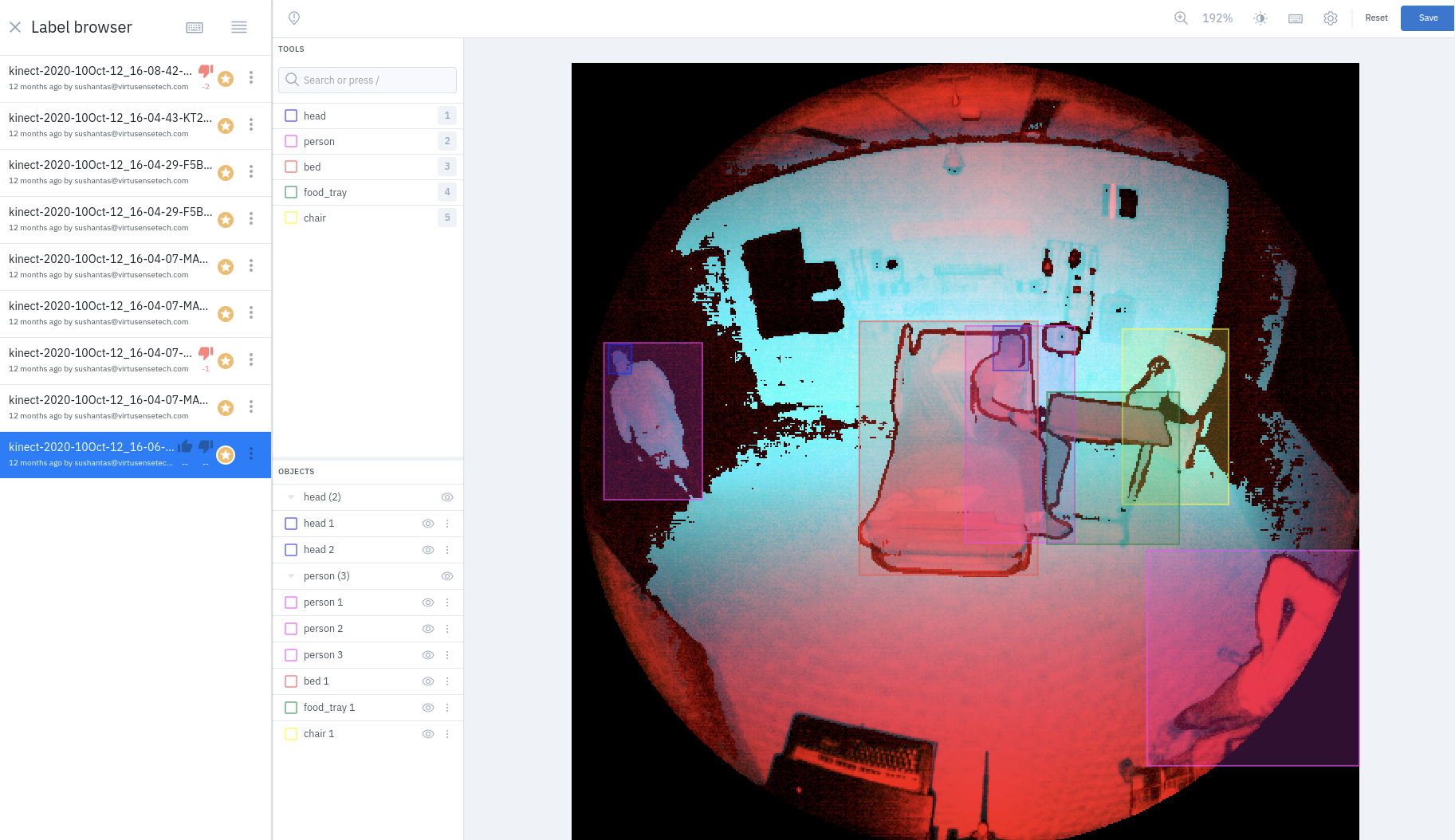
The problem of trust
Developing an AI-based solution in healthcare came with one huge challenge: gaining the trust of healthcare professionals. Nurses who experience too many false alarms tend to take alerts less seriously. With current technology, they receive anywhere from ten to twenty alerts a day, a large percent of which are false alarms. To increase the effectiveness of these warning systems and gain the trust of hospital staff, VirtuSense had to ensure that their models achieved a high level of accuracy. Within a couple of years, their technology generated an average of only seven alerts per day, and an average of two were false alarms. As the team worked to increase the accuracy of their models beyond this, however, they hit a roadblock. They needed a more diverse, higher quality training dataset, which was becoming more and more challenging to generate.
The team used a mix of internal and open source labeling tools, which they found difficult to manage as the amount of training data required scaled. The team struggled to distribute unstructured data to the labeling team and track progress in an efficient manner. With their open source tools, the lack of immediate support when issues cropped up became yet another blocker for the team. The VirtuSense team chose Labelbox to help them scale their labeling workflows and generate more high-quality training data.
"False alarms should ideally occur less than 99.99% of the time, even when the models are running 365 days a year, 24/7, at 30 frames a second. Otherwise people won't trust the technology." — Deepak Gaddipati, Founder & CTO of Virtusense
Building a data engine
Rather than adopting Labelbox one step at a time, the VirtuSense team laid out a plan for creating an AI data engine to maintain and raise the accuracy of their models. An AI data engine is a seamless process that brings unstructured data from storage and into a labeling platform, enables labelers to annotate data quickly and easily, incorporates quality assurance workflows, and sends high quality training data into the model training system. As a model trains and enters production, a data engine also includes model error diagnosis and curating subsequent training datasets based on errors and low confidence areas, creating a more effective and efficient iterative loop for the model.
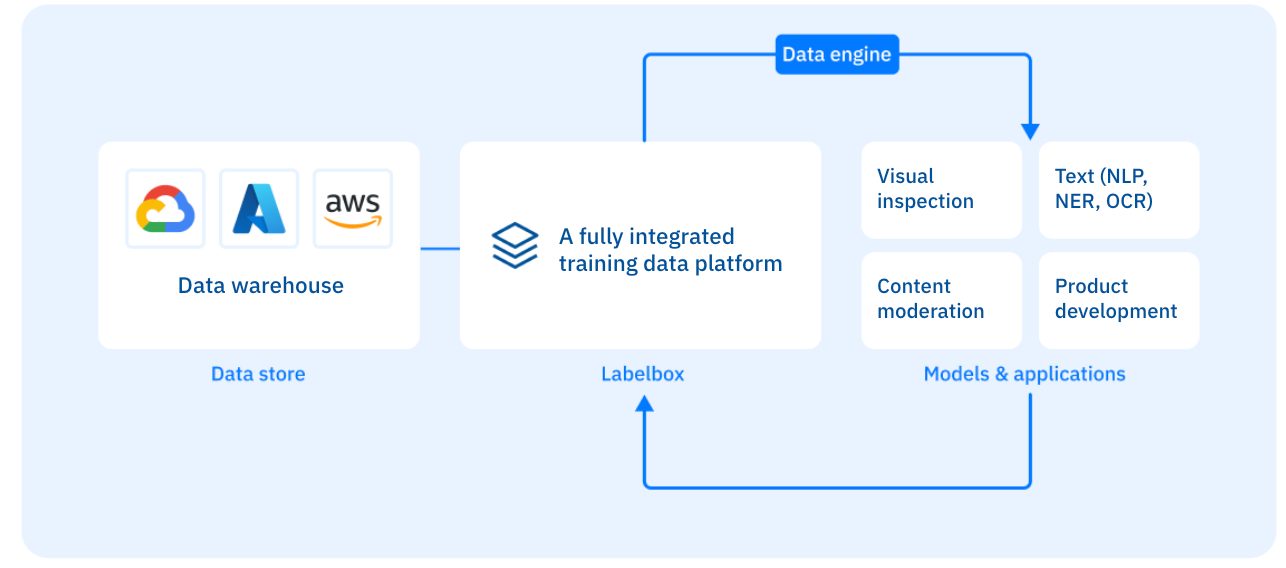
The VirtuSense team designed their data engine to automate every aspect of the model iteration loop, so that the only human involvement required is that of their labelers as they annotate data. The team’s plan also involved labeling LiDAR data not only for their current use cases (which, at the time, included only detecting falls with patients who were getting up from their beds), but also future use cases, such as detecting potential pressure ulcers. The team then implemented their vision by integrating Labelbox seamlessly into their MLOps.
First, the VirtuSense team finds areas of low confidence in their AI models by running them on a specially curated testing dataset that includes edge cases and rare situations. The system then identifies data relevant to these low confidence areas and “cleans” it of metadata that attaches it to a particular sensor, facility, and patient to uphold confidentiality and security requirements and prevent biases from cropping up. This data is then pre-labeled by a purpose-built model and programmatically imported into Labelbox, a setup made possible with the Labelbox Python SDK. An internal labeling team then reviews and corrects the pre-labeled data within Labelbox, after which the datasets are programmatically exported from Labelbox and into the model training system on VirtuSense servers.
Once a model is trained, it’s automatically pushed to thousands of endpoint edge devices, where it detects fall-risk movements and sends alerts accordingly. VirtuSense models are now retrained every few weeks with this data engine to increase and maintain their accuracy.
“We were very pleasantly surprised by how easy [Labelbox] is to use. People got the hang of it just like that. And it's not just about how easy it is to label data. We really like its ability to distribute data to multiple people and keep track of what's happening — it gives us a base of operations to help traverse through all that data….but the real beauty of it, the reason we really love Labelbox, is that it integrates so well with our tech. From a thousand-foot view, it looks like an AI labeling engine, which feeds into the deep learning system and spits out trained networks.” — Deepak Gaddipati, Founder & CTO of VirtuSense
Automating the labeling process
VirtuSense uses pre-labeling as a key component of their data engine. This labeling automation method imports model output (from either an off the shelf algorithm, a previous version of the model in training, or another model built by the ML team, depending on the use case) into the training data platform as pre-labeled data, which labelers can correct or edit instead of labeling unstructured data from scratch.
When the VirtuSense team decided to leverage pre-labeling, they knew that their existing models, built to exist on edge devices with only a few parameters, would be too small to pre-label data according to their needs. Instead, they built a large model specifically for pre-labeling, with enough parameters to label all necessary data as accurately as possible. Once the model has labeled training data, the dataset is imported into Labelbox, where the small internal labeling team only needs to review and correct the labels before the assets are pulled into the model training workflow.
Since they adopted Labelbox, VirtuSense has been able to increase the amount of labels created by 5X. Their team has now produced over one million labeled assets. Their false alarm rates have fallen from roughly 28% to 6%, and the daily average number of alerts have dropped from seven to five. Their average accuracy has increased by over 20%.
“As a CTO, you usually only usually hear about the technologies your team uses when things are going wrong. With Labelbox however, the only time I dealt with it is the day I signed the contract. Since then, my team has been using the technology seamlessly without any issues, and this gives me a lot of peace of mind as a technical and engineering leader.” — Deepak Gaddipati, Founder & CTO of VirtuSense
Due to their new data engine and improved labeling capabilities, the VirtuSense team is planning to expand beyond LiDAR data to detect potential stroke risks, arrhythmia, and other dangerous conditions.
“Out of all the platforms we explored, Labelbox is the easiest to use and the best for managing labelers and workflows and monitoring performance. Labelbox also keeps offering more interesting and helpful features. I find the Catalog feature very interesting. We haven’t been able to use it yet, but we are planning to update our workflow to include it in the future.” — Hithesh Reddivari, Tech Lead, VirtuSense
Watch this on-demand webinar to learn how a data engine can improve your enterprise AI projects. You can also try Labelbox's annotation and data curation features for free.


