×![]()

 All blog posts
All blog postsLabelbox•July 21, 2022
Iterate and ship models faster with our newest features

With more and more companies looking for ways to increase efficiency while also reducing spend, machine learning (ML) teams are under new pressure to ship their models faster. We’ve focused recent product development on end-to-end workflow to help teams iterate and ship models faster than ever. Teams can now curate and prepare training datasets directly through Labelbox, have greater visibility into the processing status and searchability of their data rows, and use our SDK to powerfully interact with our product programmatically.
Annotate
Workflows
The ultimate orchestration tool for training data cycles.

In the coming days, we'll be adding an exciting new feature called Workflows. This is another important addition to the growing suite of orchestration and collaboration tools from Labelbox. This new feature lets managers fine-tune review sequences, pinpoint issues as they arise, and track key metrics every step of the way.
See the whole picture
Get a 360-degree view of your labeling operations with custom review sequences, pinpoint issues as they arise, and surface insights like throughput and labeler performance.
Human-centered labeling
Labeling often relies on collaboration across a range of functions, platforms, languages, and time zones, which can be messy without the right tools. With Workflows, you can loop in the right teammate for the right job at the right time.
The new standard for efficiency
Set up review sequences that ensure higher quality with less team time. Labeling QA reimagined—so you can spend your time and budget on the things that matter.
Simplify project management with the new Data Rows tab
Our revamped Data Rows tab is now available for all users. It includes powerful new functionality to make your labeling operations more efficient. We’ve revamped the search and filtering experience, improved load times, and added flexible querying.
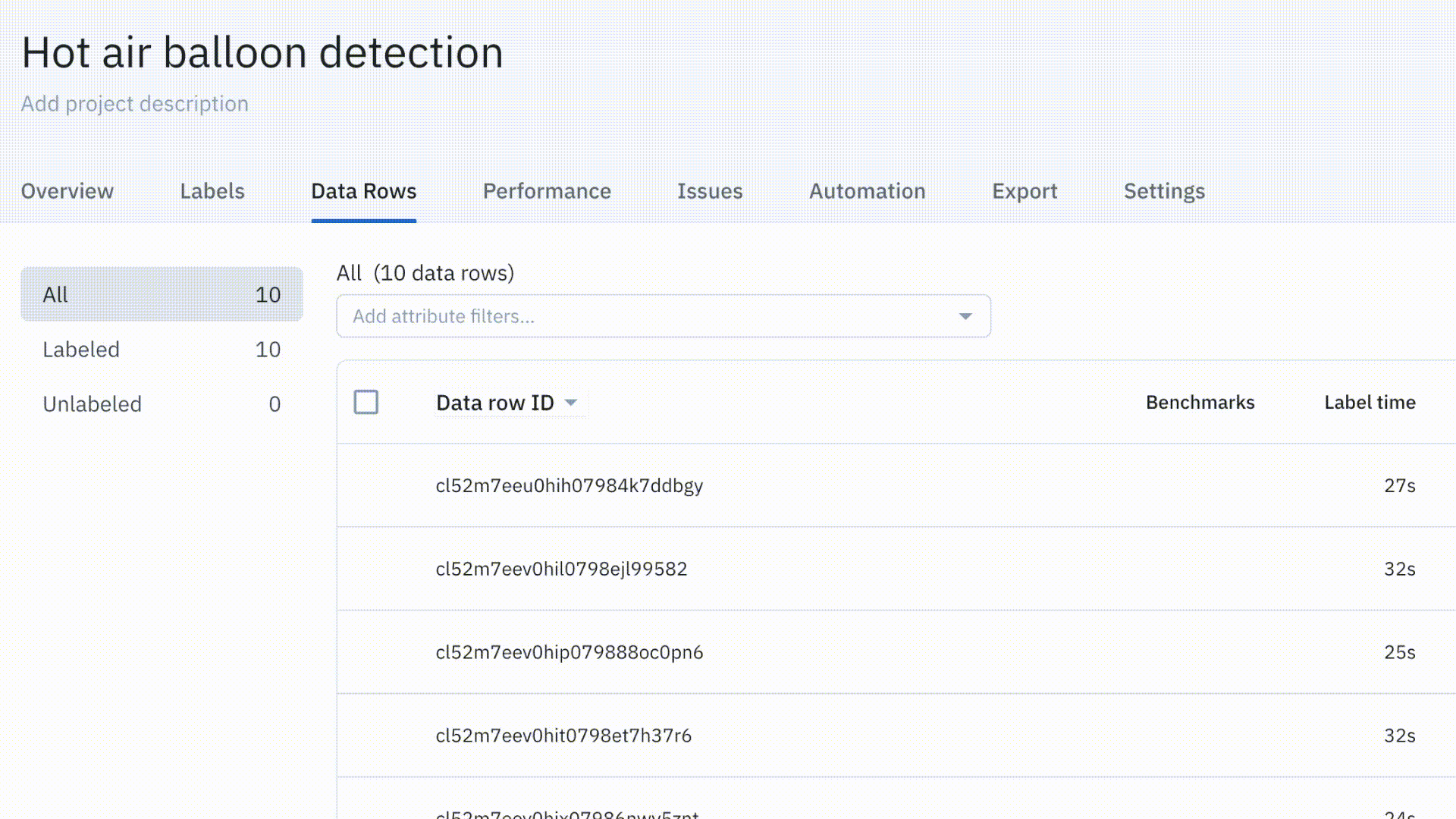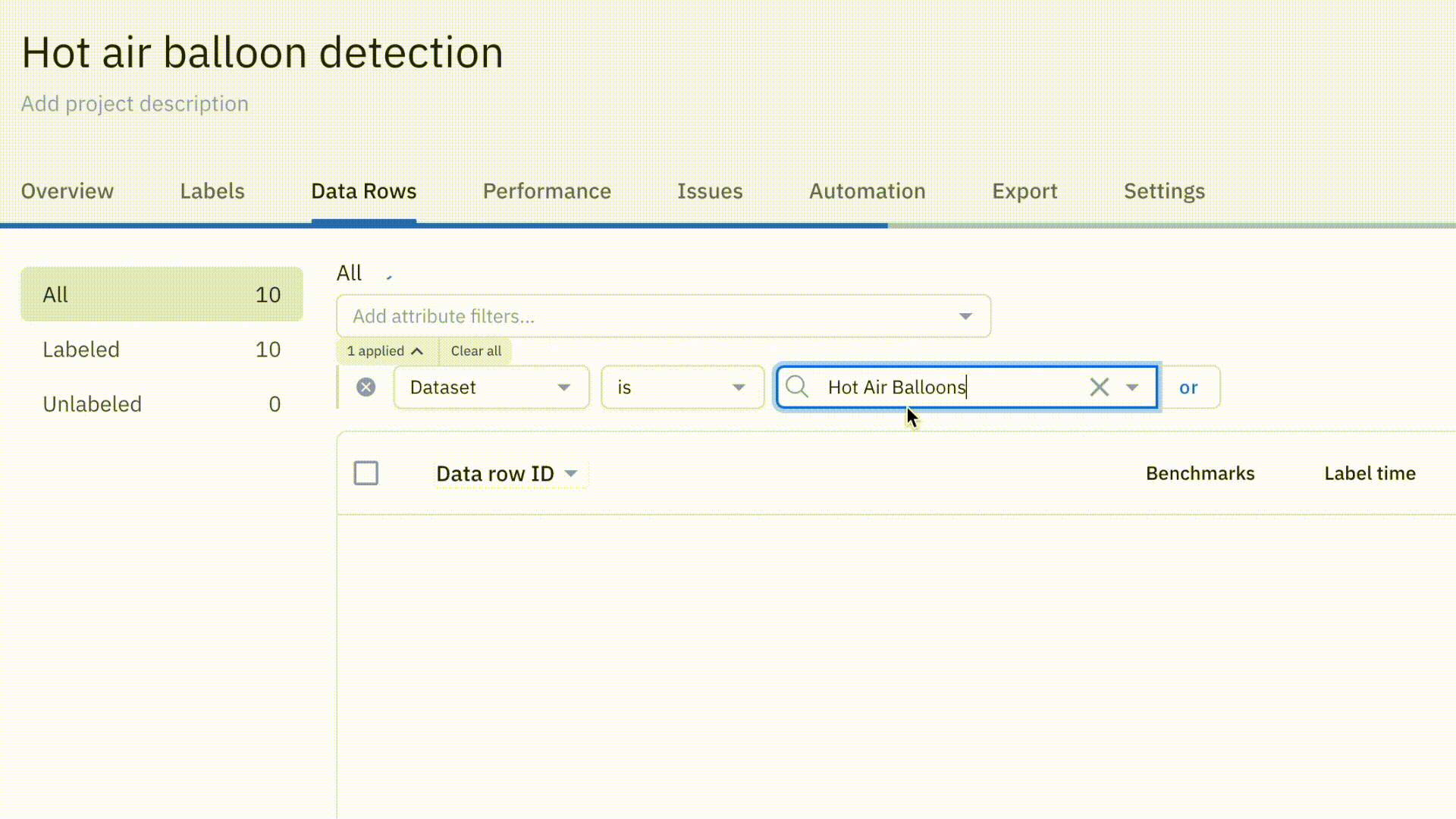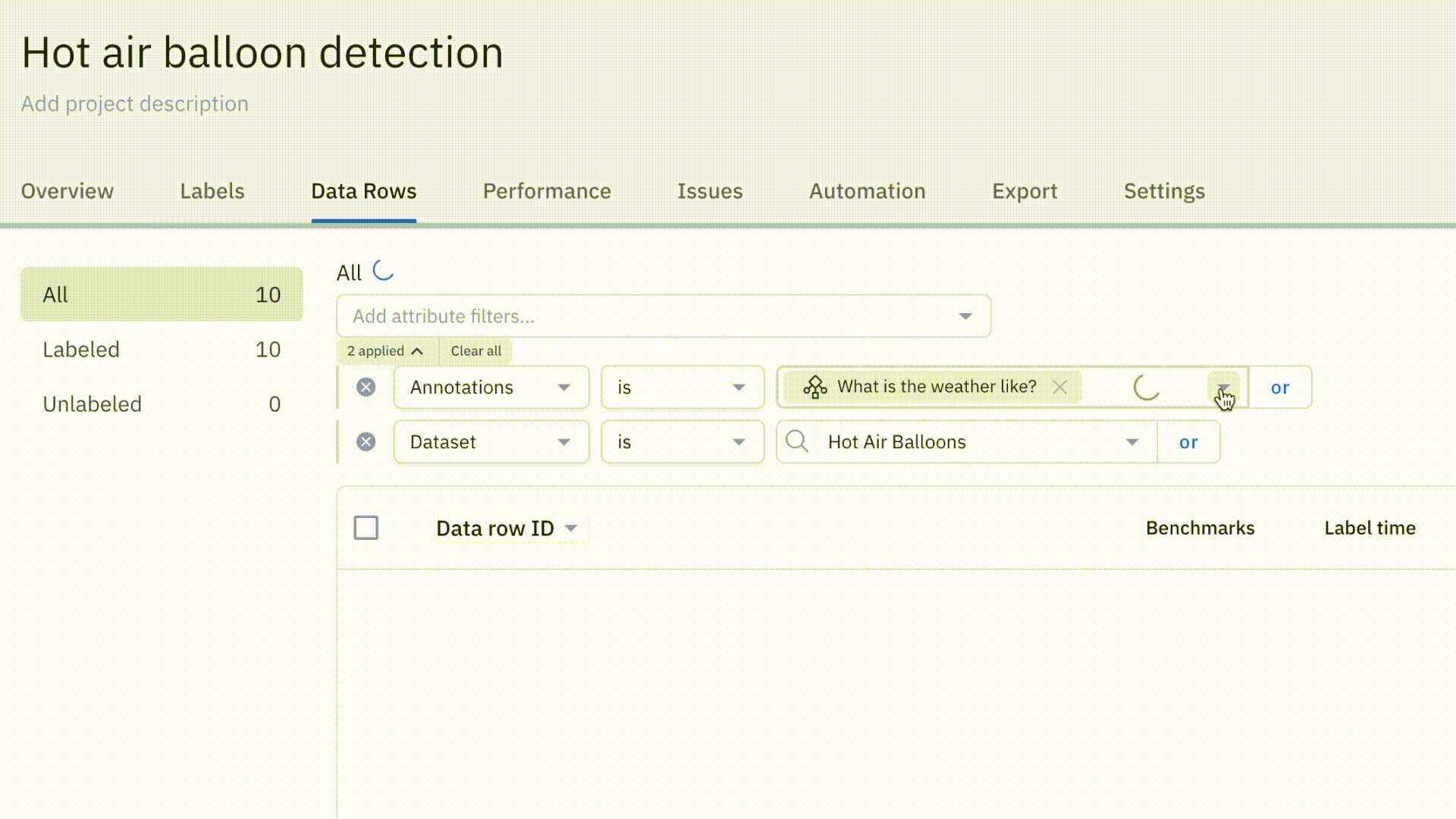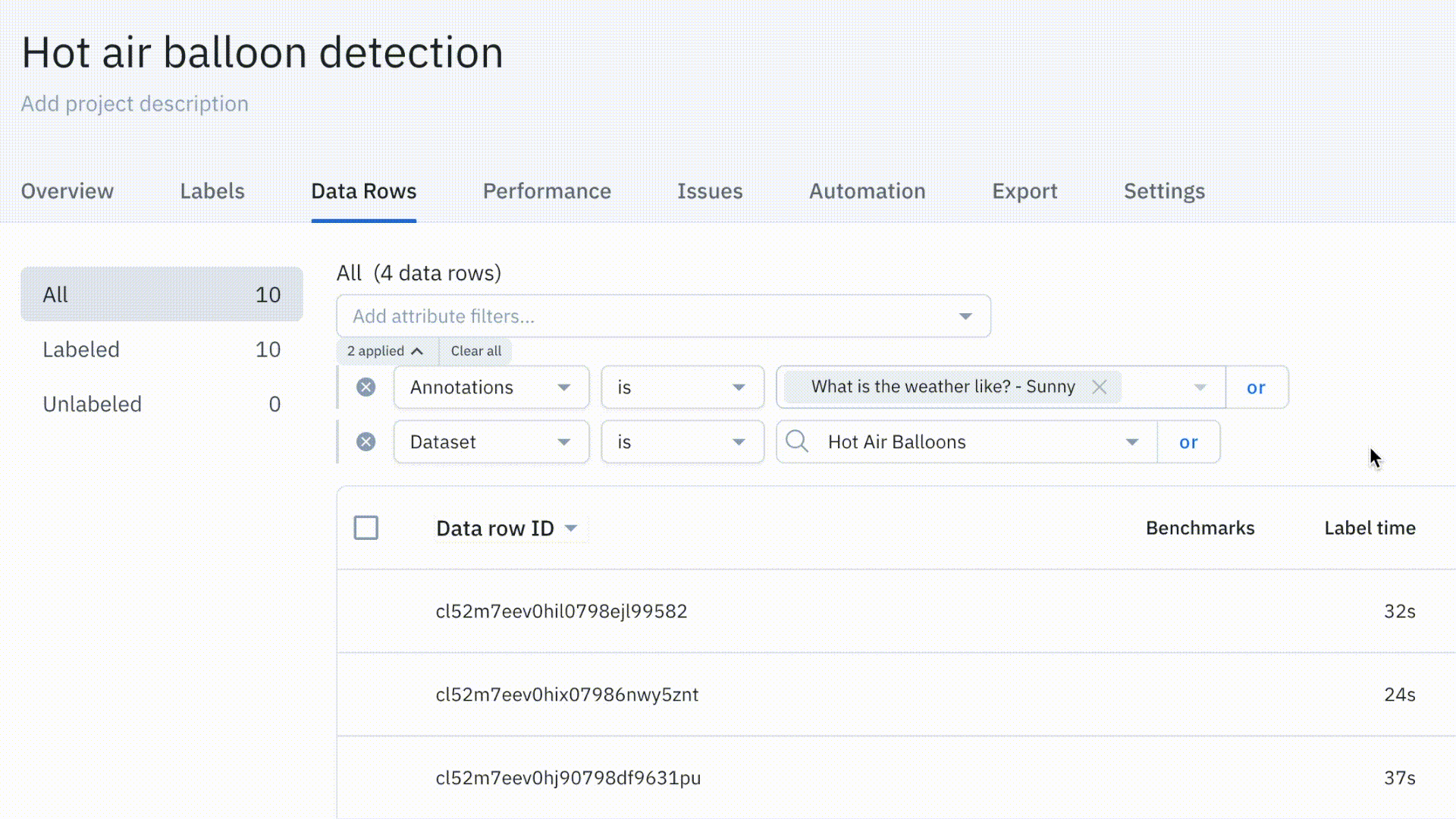
Read more about our new Data Rows tab in our documentation or in our June Product Update.
Turn your audio files into insights
Our Audio editor is now available for all users.
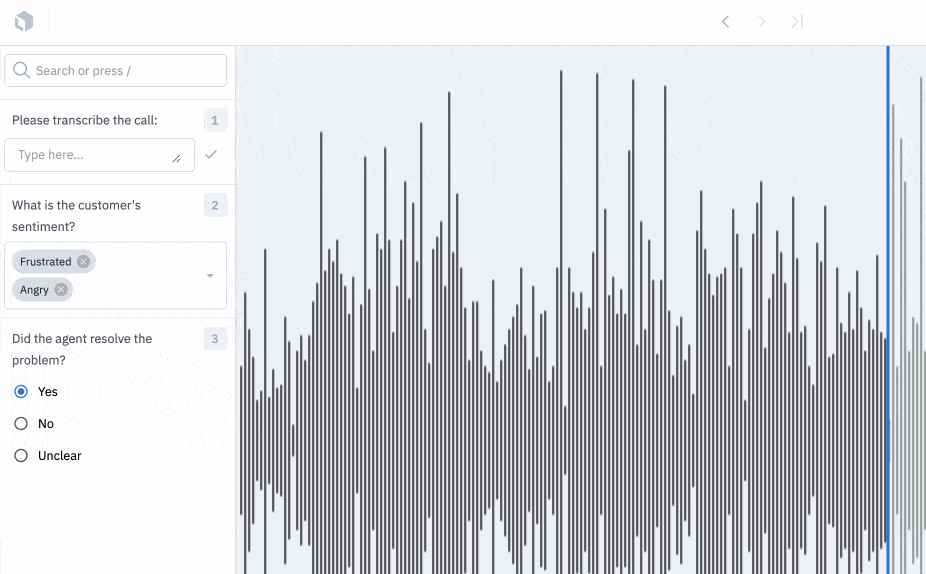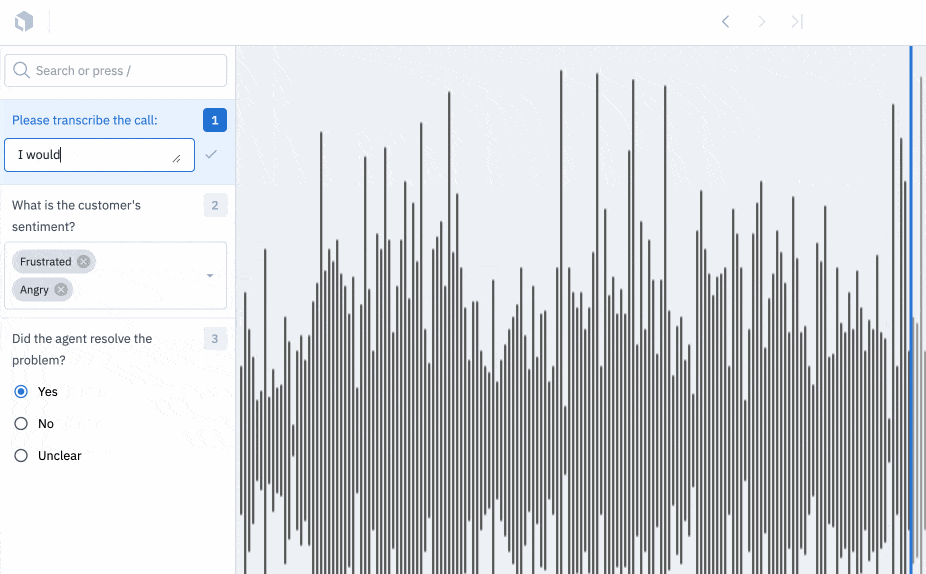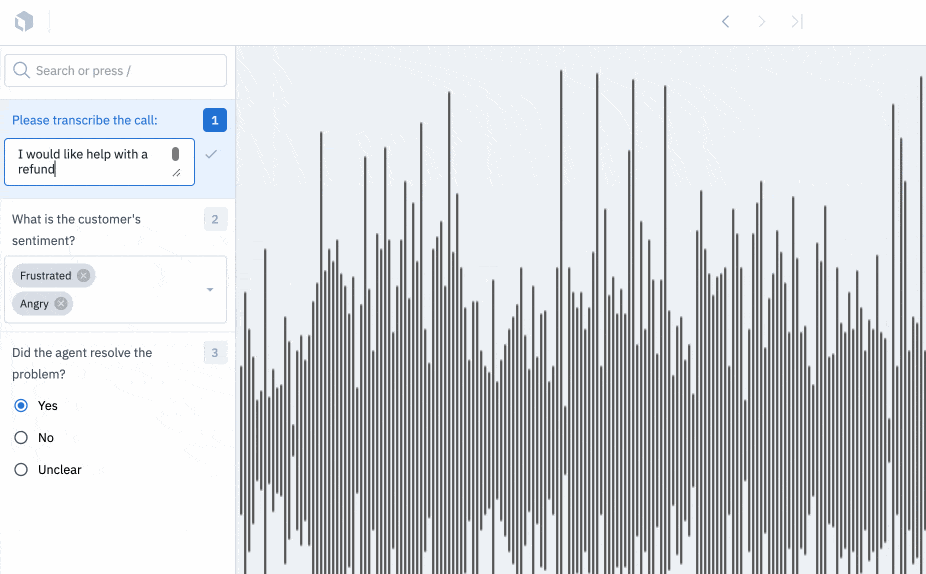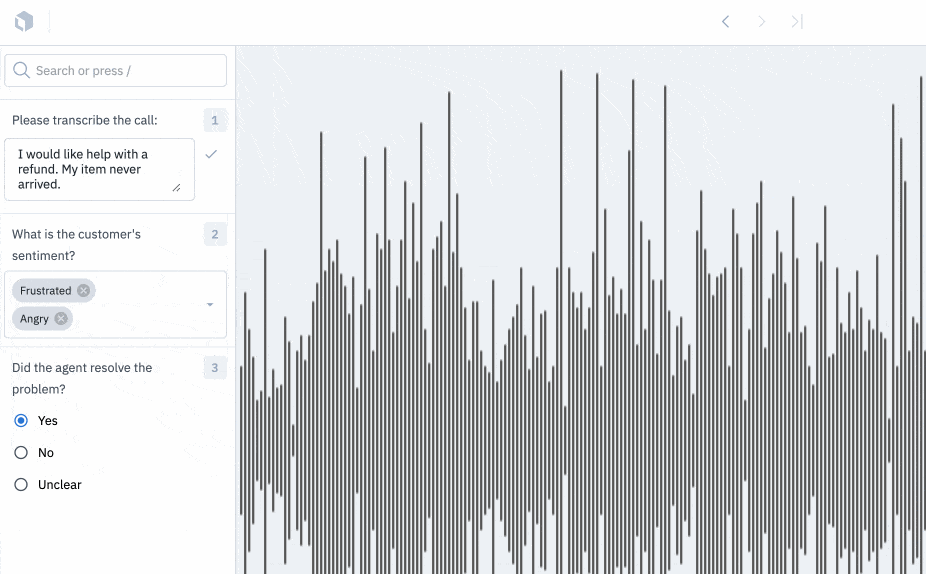
You can use our audio editor to turn raw audio files into structured data. Use our audio editor for simple transcription and translation tasks and apply global classifications to specify information such as sound quality, tone, or language spoken.
Learn more about the audio editor in our documentation.
Model
Curate, visualize, and prepare training datasets
Our Model workflow lets teams curate, visualize, and version their training data for training experiments.
Many ML teams have historically had to rely on multiple tools to keep track of their model experiment data, parameters, and model predictions. Keeping track of all this data is essential for reproducing and iterating on model experiments.
With our new update, teams can use Labelbox as a versioning tool and source of truth for all of their model experiment inputs (labels, data splits) and outputs (results, model predictions). This makes curating, visualizing, and tracking data for model training experiments easier than ever. You can now visualize inputs and export the versioned data and model predictions together.
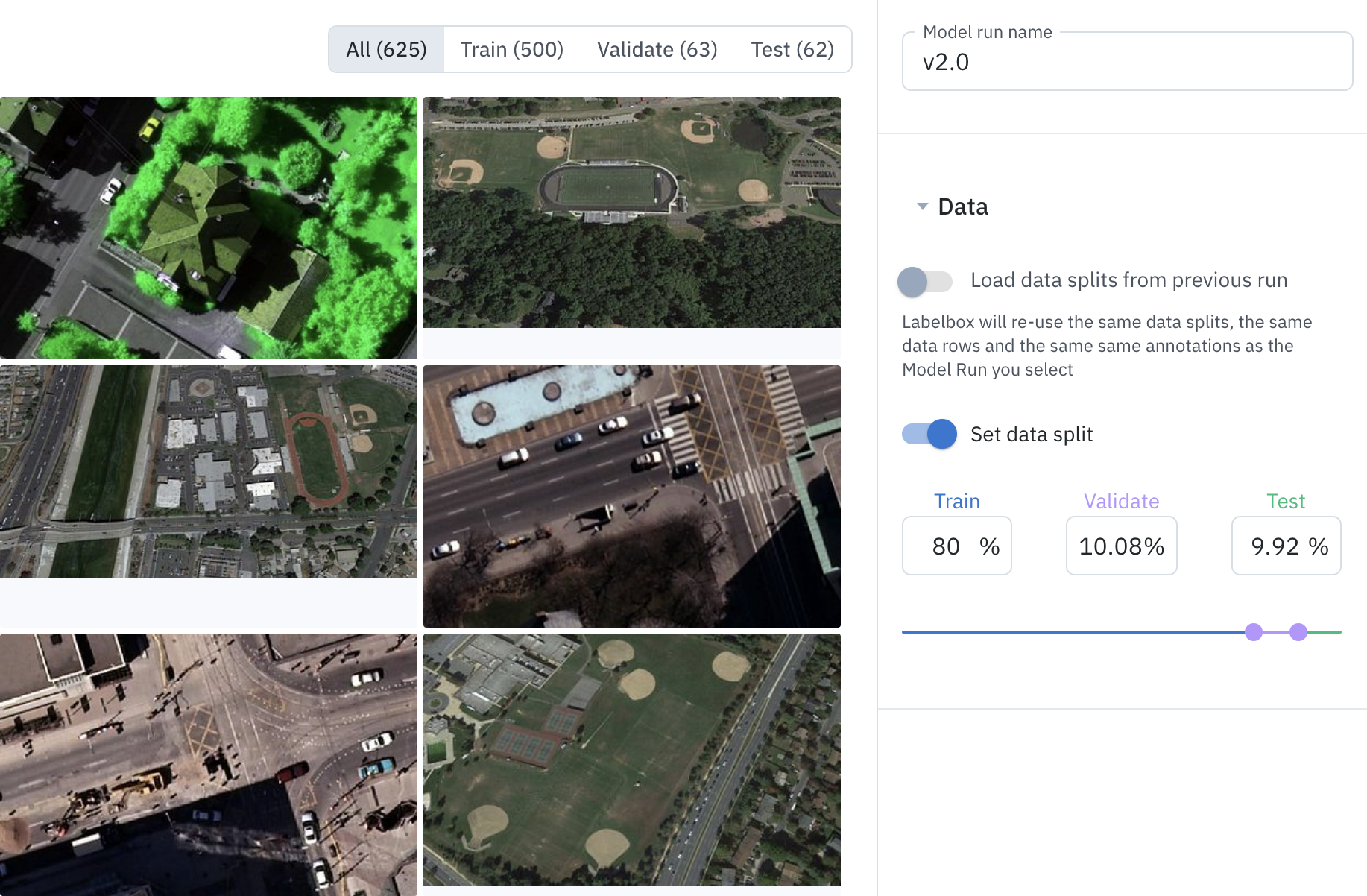

With our Models workflow, you can:
Export data for model training
Models now support 1M data rows
We’ve improved the scalability of Models and Enterprise teams can now create models and model runs that contain up to one million data rows. This update allows teams to do active learning and error analysis at scale: filter and sort based on metrics, predictions, annotations, projects, and more.
Catalog
Visibility into data row processing status
Users can soon view the processing status of data rows during an upload. We'll be rolling out this feature to all customers over the next few days. Viewing the status of an upload for large files, such as Audio, Video, or DICOM, can be helpful as they typically take more time to process. Our new update gives users greater visibility into the progress of their upload and will allow users to re-compute media attributes if changes have been made to their data row or bucket.

With this update, users can intuitively see the number of data rows being processed and will be notified if a data row has failed to process. Batch creation from Catalog will only be allowed for successfully pre-processed data rows, ensuring that only correctly uploaded data rows are getting sent to projects for labeling.

If a data row contains an error or hasn’t been uploaded, such as due to a failed file conversion, users can easily take corrective action and recompute or reprocess the data rows.
SDK
We’ve made a host of improvements to our SDK to give developers and teams greater flexibility.
Use our SDK to create / update / delete metadata schema
We’ve made importing data rows with our new metadata easier than ever. Rather than only managing metadata schema through our UI (Schema tab), developers can now manage their metadata schema with our SDK.
metadata_ontology = client.get_data_row_metadata_ontology()
sensor_metadata = metadata_ontology.create_schema(name="sensor_type", kind=DataRowMetadataKind.string) # also supports number, datetime, embedding, Enum metadata typesLearn more about creating / updating / deleting metadata schema via SDK in our documentation.
Use the SDK to assign data rows to model run data splits
In addition to being able to customize data splits through our UI, developers can now customize how to split their data rows for a given model run via SDK. Teams now have more flexibility to curate data rows and splits for their model training experiments.
# You can specify the split logic however you want, or assign individual data row id to a particular split
train_split, val_split, test_split = datarow_ids[:num_train], data_row_ids[num_train:num_train+num_val], data_row_ids[num_train+num_val:]
model_run.assign_data_rows_to_split(train_split, "TRAINING")
model_run.assign_data_rows_to_split(val_split, "VALIDATION")
model_run.assign_data_rows_to_split(test_split, "TEST")Learn more about configuring data splits via SDK in our documentation.
Upload bulk conversational text in a single JSON file
Rather than spending time importing individual conversational text uploads, teams can now upload bulk conversational text in a single JSON file and view conversations in our new Conversational Text editor.
View a sample conversational text JSON file for upload.
Product Spotlight
Learn about how teams are using our products to achieve breakthroughs.
Labelbox’s Model Diagnostics helps teams boost model performance, while reducing their labeling effort, time, and spend. With error analysis and active learning, teams can quickly identify edge cases or patterns in their model predictions, while Catalog allows teams to search, discover, and prioritize the right data to label.

One of our customers, Deque, was able to combine Model Diagnostics and Catalog to reduce their data requirements and spend by more than 50%.
Being able to reduce the data requirement is huge because you can see the same amount of improvement in the model’s performance in half the time and with half the effort. That was enabled through targeting the model’s weaknesses with Model Diagnostics and then being able to prioritize the right data through Catalog. - Noé Barrell, ML Engineer at Deque
Learn more about Deque’s use case and their workflow in our recently published case study.


