×![]()

 All blog posts
All blog postsLabelbox•February 13, 2019
Model Predictions, Semi-Automatic Labeling and Quality Assurance in Production
Model Predictions, Semi-Automatic Labeling and Quality Assurance in Production
Model Predictions
In the field of machine learning, a prediction is the output of a trained model. A basic premise of supervised learning is that raw data needs to be layered by human decisions in order to train a model to make similar decisions on new pieces of data. In order for a model to learn, human decisions must be rendered in a form that is intelligible to it. Annotations is the way in which humans can translate their knowledge into a form that can be understood by the model and the way in which model predictions can in turn be understood by humans. The training data (input) and predictions (output) of a model take the same form: data plus annotations.
Model predictions play two vital roles in a machine learning pipeline. In one use case, predictions is used to semi-automate the labeling process. Semi-automating the labeling process reduces human labor costs and also reduces the time it takes to get a model trained and into production.
Another use case for model predictions is to monitor model assessments and improve the accuracy of deployed machine learning systems. Model predictions accompany a confidence score whereby low confidence scores would go through a human reviewal process. The human's decision would override the model's prediction and the resultant data would feedback into training that very same model in production. In this article, we will go over these two use cases of model predictions in building your machine learning pipeline.
Semi-Automatic Labeling
Curating training data is typically thought of as a strictly manual process. However, predictions subverts this notion by adding a machine into this labor intensive development process. Given that training data takes the same form as predictions, a model's output can used to make an initial annotation of raw data in real time. This data can then be fed through the training data pipeline where it can be improved upon by a labeling review team. The improved annotations would then be fed back into the model to increase its prediction accuracy. This tight feedback loop is referred to as semi-automatic labeling.
In the case of semi-automatic labeling, predictions are used to pre-label data. An experiment was conducted in 2018 by UC Berkeley, Georgia Institute of Technology, Peking University and Uber AI Labs to evaluate the efficiency of semi-automatic systems. In this particular experiment, the model was completely accurate 40% of the time and the average time for labeling was reduced by 60%. This is one such experiment showing that semi-automatic labeling can outperform manual labeling across bounding boxes and polygon shapes.
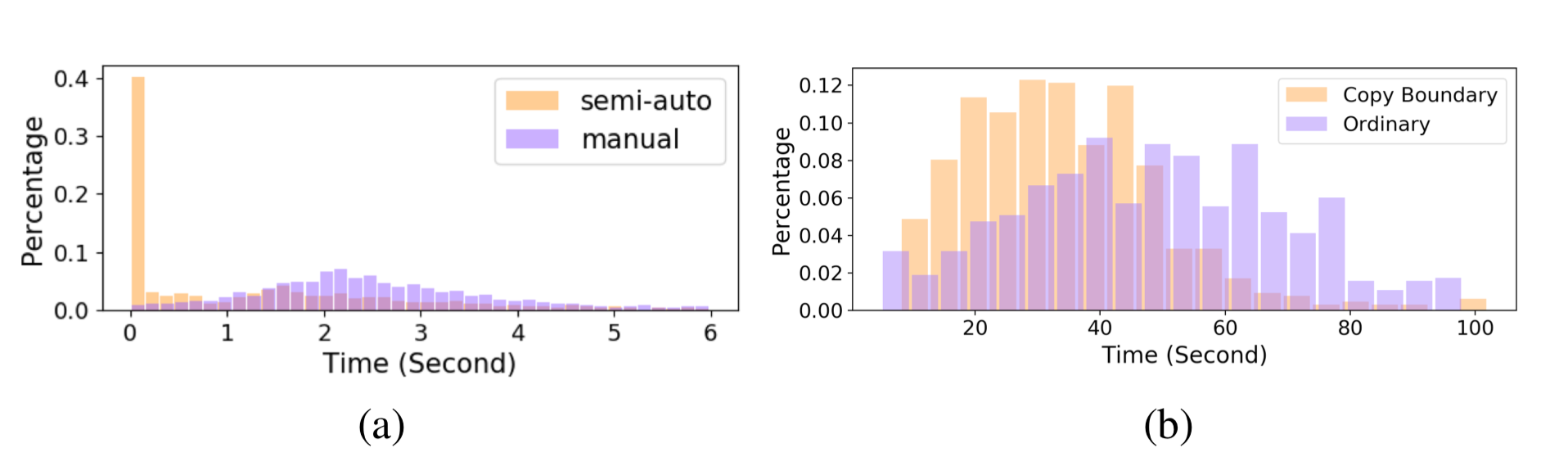
An accurate prediction will always be faster than manually labeling. However, when a prediction is incorrect, it is often but not always faster to correct a label rather than label it from scratch. The type of labeling configuration is one such influencer. For example, while it might be quicker to adjust a polygon shape over mutated cells, if the shape were a bounding box identifying bad spots in a solar panel, it might be quicker to draw the bounding box from scratch. However, just because a label is not faster to fix does not necessarily mean that it wouldn't be faster overall to use predictions to pre-label data. The question would be how often the model is correct and calculate the benefit of time saved.
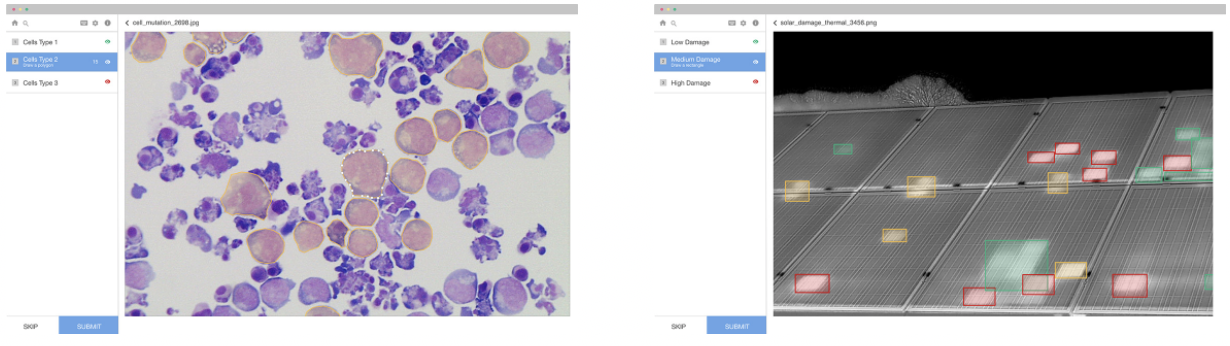
To evaluate the efficiency of using predictions on your own project you would first determine how often your model is correct. The next part of the puzzle would be assessing the change in labeling speed for a correct label and for an incorrect label. Let's imagine we have a model that is correct 80% of the time. Assuming that the average labeling time for an image is 6 seconds. When the model is correct you would save about 5 seconds per label (assuming it takes 1 second for the person to accept a correct pre-label). When the model is incorrect, you'll often gain speed, but at a slower rate than when the model is completely accurate. However for the sake of this example, let's imagine that there is a 1 second loss per label correction. So now you're at an average net positive gain of 3.8 seconds per label, resulting in a cost reduction of about 60%. This becomes compelling when considering that achieving state-of-the-art performance for deep learning models often requires millions of labeled images.
QA Production Models
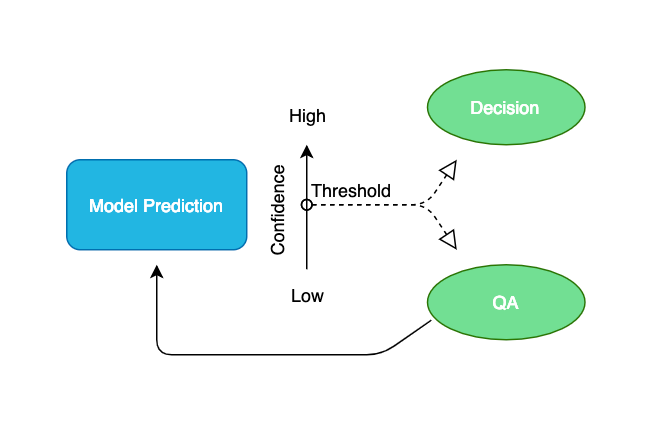
The quintessential machine learning application is believed to be one that makes decisions independent of human input. In this idealistic case, a task would be entirely automated. All predictions would be decisions and this workflow chart would collapse into a single step. However, models operating in the real world are not 100% accurate 100% of the time. While AI drastically reduces the need for human input, it does not eliminate it entirely.
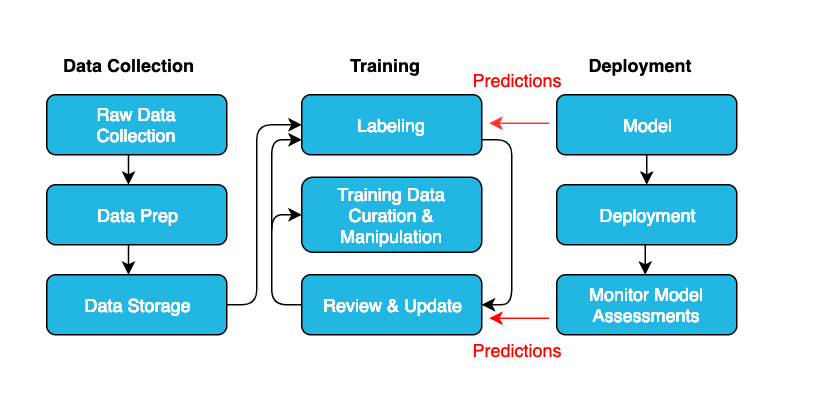
Humans play a very important role in machine learning, even after the model has been deployed. The three basic pillars of machine learning: data collection, training, and deployment, are not isolated stages that happen in chronological order. They operate simultaneously and interactively to form a sophisticated and complex workflow. Like any mission critical system, once a model has been deployed it still needs to be maintained and updated. This is another place where predictions can fit into the big picture of creating deep learning models.
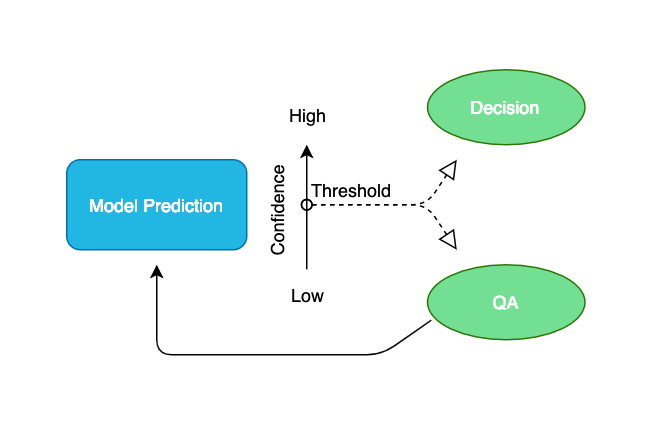
Each prediction that a model makes in a real world application is accompanied by a confidence score. And, models are very good at letting us know how confident they are in their prediction. You can set a confidence score threshold to determine how to treat a model's prediction in production. A prediction with a confidence score above the threshold will operate as a decision without human intervention while a prediction below the confidence threshold will go through a quality assurance process.
Predictions offers a way to conduct quality assurance at scale. The training data, the predictions, and the quality assurance data are all rendered visually. Since the resultant quality assurance data is of the same form as the training data, it can be fed back into the model to improve its accuracy in batch or real time.

For example, let's say there is an insurance company that has a model in production that automatically assesses damages. Imagine a customer takes a photo of their car after an accident. When the image gets submitted it is immediately forwarded to the model, which automatically predicts the location and severity of damage. The prediction always accompanies a confidence score. If the confidence score is low, the model's prediction will not become a decisive claim. Instead, the claim would route to a human who would conduct the actual damage assessment for production purposes. The resultant data would then be fed back into the model as training data in batch or in real time. Adding new training data will continue to improve the production model's accuracy and confidence in its predictions.
Conclusion
In summary, we discussed how predictions can be used to increase labeling speed and assure prediction accuracy in production. As opposed to the traditional process of labeling being a purely human process, predictions inserts mechanical automation into the training data loop. And, as apposed to models in production being a purely machine driven process, assuring quality predictions with low confidence scores are ways to improve and update increasingly performant models.
If you have already have a Labelbox account, and want more information about how to set up predictions, check out our predictions support docs.


