×![]()

 All blog posts
All blog postsLabelbox•June 3, 2021
Productionizing unstructured data for AI & analytics: 3 key takeaways

Most businesses today collect large volumes of data — from cameras, website activity, social media, and more. This unstructured data then sits in a lake or warehouse. To make it useful for AI/ML initiatives, ML teams will need to process and structure the data. Building an algorithm that identifies threats from security footage, for example, will require the team to take unstructured video data and annotate it with masks or bounding boxes identifying objects and answer questions about the content of each video.
At the Data + AI Summit last week, Labelbox launched a connector between Labelbox and Databricks that will make this process easier and faster for enterprise ML teams. Adding a training data platform like Labelbox to your ML workflow can help you produce better models from your originally unstructured data. Below are three key takeaways from the Labelbox session, Productionizing unstructured data for AI & analytics, during which the connector was launched.
The LabelSpark library is easy to set up
There’s no complicated setup required to use the LabelSpark library. You can import the library and register your dataset with Labelbox in just a few lines of code.
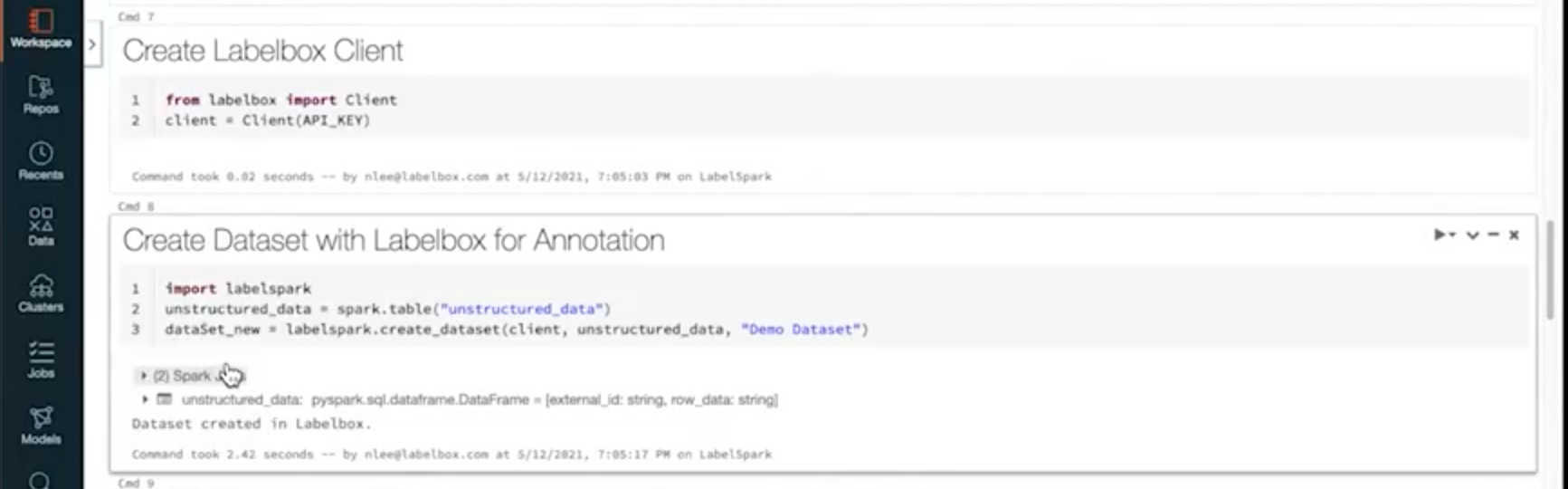
You can then set up your ontology within Labelbox or programmatically by using our Python SDK. Once the ontology is established, you’re ready to start labeling with Labelbox.
Structured data is delivered in a Spark table
When you pull your annotated data back into Databricks, you’ll find the annotations for each asset in JSON. You can also pull the data in a clean silver table for readability. Your labeled data will always be easy to parse and use. JSON is an open standard — we’ll never lock your annotations behind any proprietary formats.
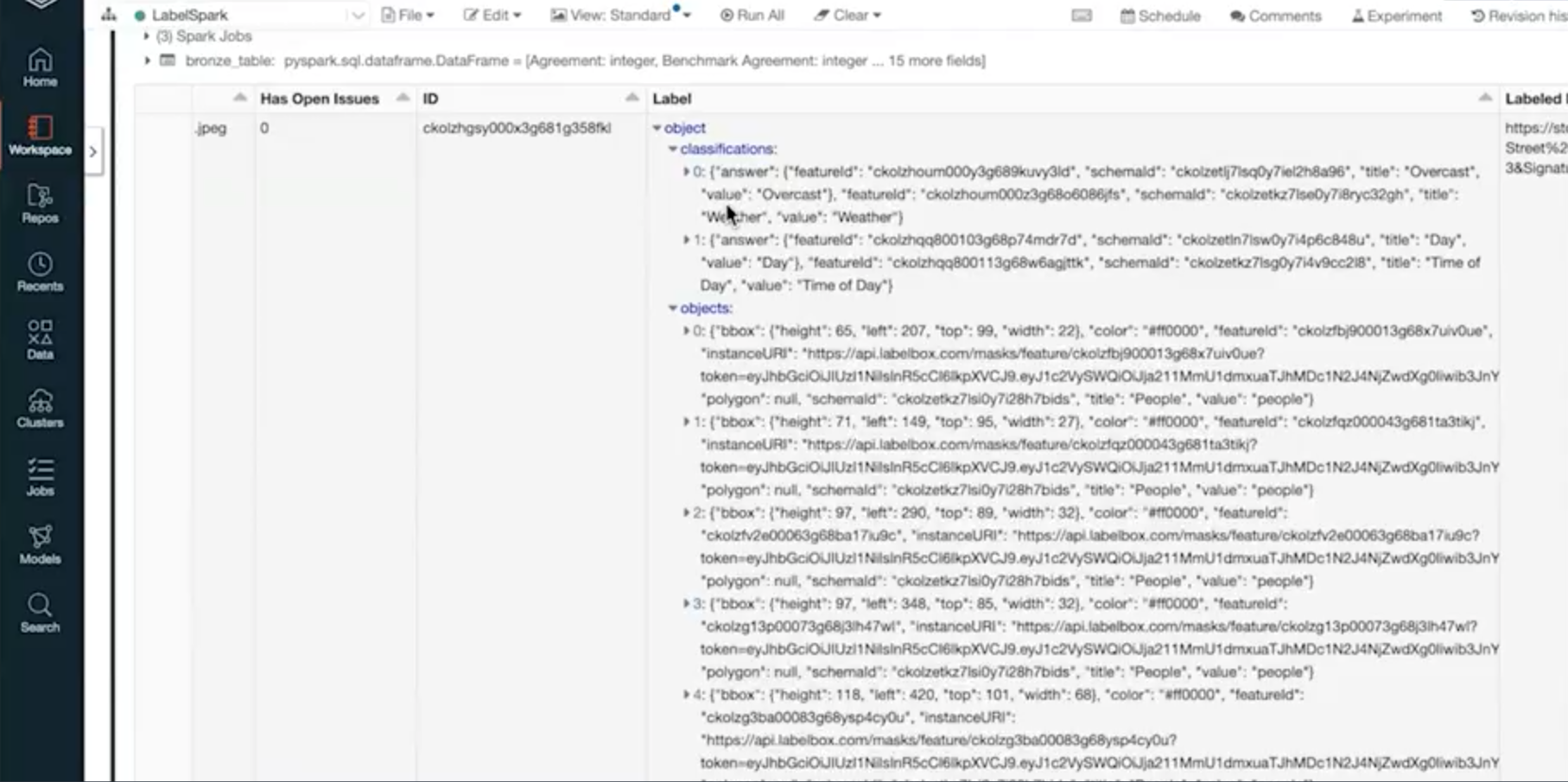
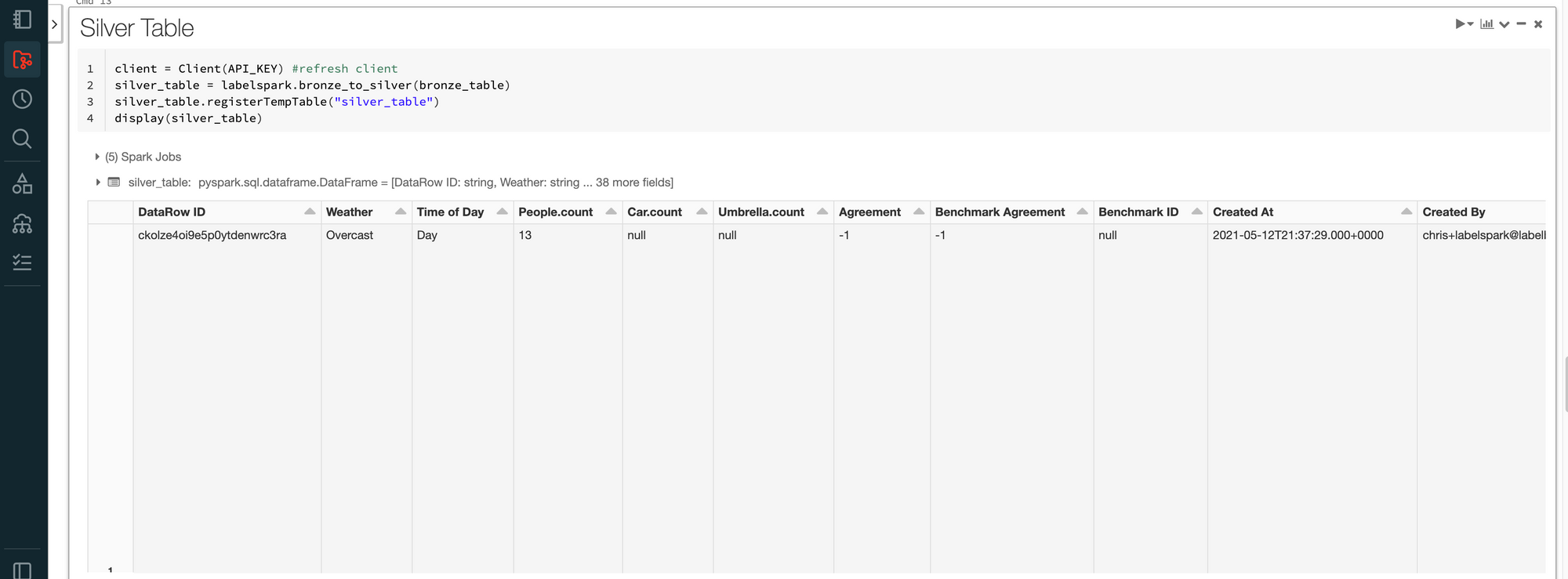
When annotated data is brought back into Databricks, you’ll also get metadata (in case you used quality management tools like benchmark or consensus), the labeler’s name, any open issues within the asset as it was being labeled, and more.
This workflow can help your model train faster
You can use Labelbox to label your unstructured data, but you can also use it to examine and correct labels created by your model. The corrected data will also have an audit history so your team can track what the original labels were and how they were changed. By refining the model’s output and feeding them back into the model, you can get it to production-level accuracy more quickly.
The LabelSpark library is open source and governed by the Apache License 2.0. Learn more about it here. You can also watch this session from the Data + AI conference in full on the conference website.


