
 All blog posts
All blog postsLabelbox•November 10, 2020
Teach your ML model to perceive time

At Labelbox, our mission is to give you the best tools to train machine learning models to perceive reality. For a supervised machine learning system, this means teaching machines how to understand and predict patterns in our surroundings.
Video is fundamentally more complex than a series of frames or images. It captures and conveys relational concepts that children learn early on but that a machine will struggle to learn without the right tools. These concepts, namely, are of temporality and object permanence.
Temporality
A video file contains more than imagery played back at a specified frame rate. It conveys the passage of time and relationships between objects that are shaped by the passage of time. Humans can perceive and predict adversarial and cooperative relationships because we see and understand the full context of objects through time that an image, or even a series of images, can’t capture. For example, a video can more clearly track relationships between players on a soccer field as they pass the ball and try to create a scoring opportunity. To teach ML models this context, we built the video editor to identify and track objects through time.
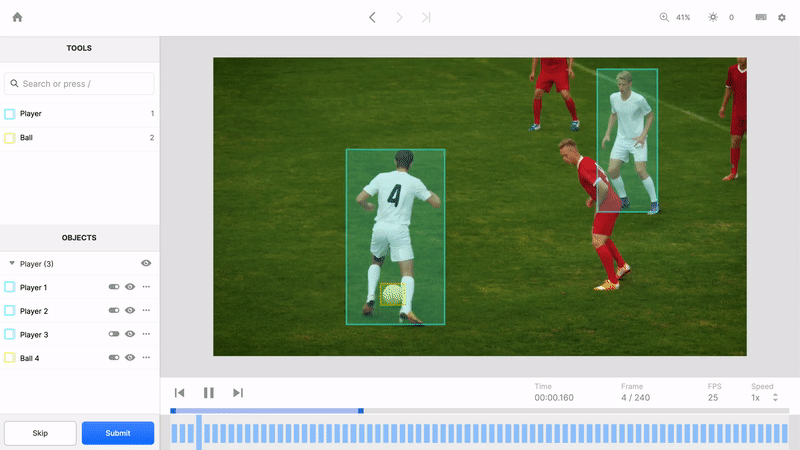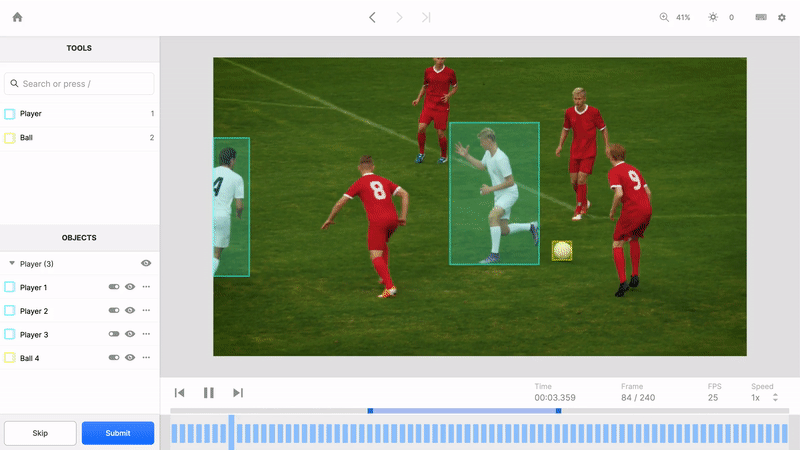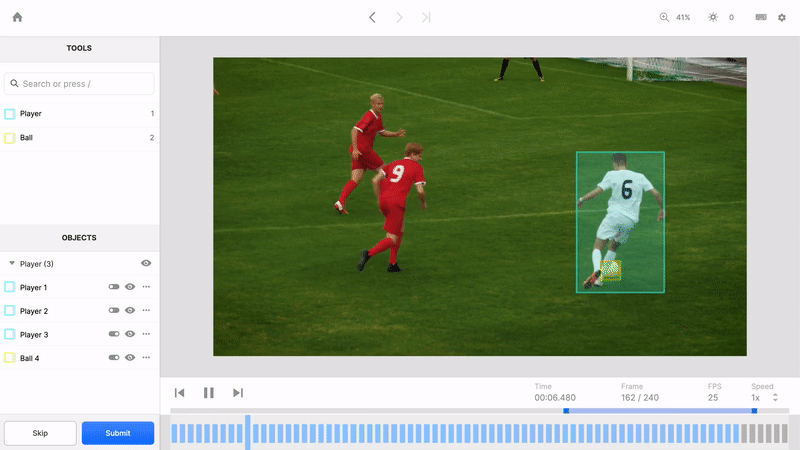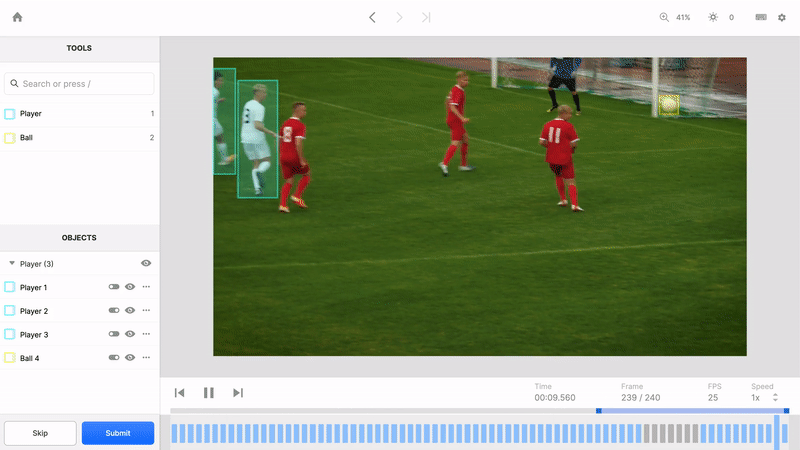
Unique featureIDs form the foundation of understanding this context. By assigning persistent objects unique featureIDs across all the frames they appear in, Labelbox teaches your ML model how to observe where objects have been, predict where they’re going, and understand how their context has changed over time. Some other tools treat each frame as a standalone image and can’t intuitively identify an object as the same object from one frame to the next. Without this awareness, it’s much harder to teach a model how to understand the passage of time and how time impacts objects.
Object permanence
Another important concept to train ML models is object permanence, which is the ability to understand that an object exists even if it’s no longer visible. Again, children typically understand this concept intuitively at a very early age, and it’s an important concept to help your model better understand reality.
Labelbox teaches models to recognize objects when they’re temporarily hidden or out of frame by using unique featureIDs and letting you dictate when an object is no longer in the current view. Our intuitive UI lets you quickly toggle object presence on or off on individual frames or across frames in bulk. By tracking what matters, Labelbox trains models to better understand and predict object behavior.
Faster labeling workflows
The Labelbox video editor helps labelers quickly grasp context surrounding objects and relationships between objects so they can apply more accurate annotations faster than if they were reviewing a series of images. While not all stages of model development using video training data benefit from understanding the inherent temporal nature of a video file, the video editor can help teams label this data much faster.
Advanced tools to power your breakthroughs
Our training data platform is designed from the ground up to teach your models how to understand the complexities and nuances of human perception that we take for granted. From the labeling UI through the data export, each step is meticulously engineered to capture details about the world surrounding your models.
Learn more about how Labelbox can help your machine learning team develop video training data.


