×![]()

 All blog posts
All blog postsLabelbox•March 15, 2022
The training data practices used by the most successful AI teams

According to a recent Cognilytica study, creating and managing training data is the biggest challenge faced by typical AI/ML teams, taking up about 50% of their time spent developing AI. Another 15% of their time is spent on data augmentation. Optimizing processes around training data can help teams realize significant savings in time and budget.
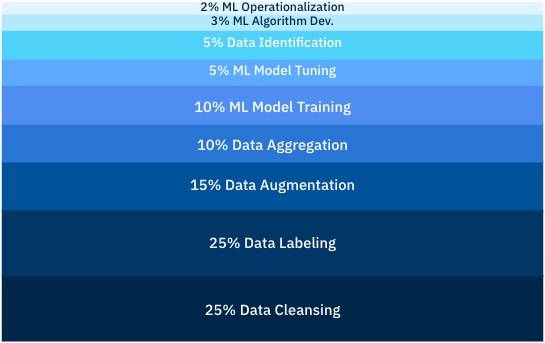
In this post, we’ll explore two categories of best practices that will help AI teams reduce the amount of time they need to spend on creating, managing, and augmenting training data.
Labeling operations
The process of creating training data can have many bottlenecks, from miscommunications between labelers and stakeholders to clunky quality management workflows. There are two simple practices your team can use to prevent such issues.
Define your labeling workflow
Before you kick off a labeling project, be sure to define your entire labeling workflow and make sure everyone involved in your project understands and agrees on it. Once you’ve laid out the process, stick to it until that batch of training data has been completed. Because iteration is a key part of creating high-quality training data, be sure to include quality control measures such as benchmarks, consensus, and review queues. To avoid delays, use a training data platform to integrate these processes seamlessly into your labelers’ workflows.
Work in small batches
This practice will help your team find issues with the workflow, communication preferences, labeler training, and ontology without affecting all of your data for a project or wasting days — or sometimes weeks or months, depending on the size of your dataset — of labeling time. By refining your processes with the first couple batches of training data, the rest of your training data will be created faster, with no sacrifice to quality.
Automate labeling
Even if labeling teams are creating training data in small batches and using predetermined processes, the act of actually labeling an asset can be slow and inefficient work, especially when ontologies get complex. To increase your team’s efficiency as it creates enough training data to achieve this, one key method to consider is labeling automation with model-assisted labeling.
Typically, when a labeler views an unlabeled image, they need to create their labels and annotations from scratch. Model-assisted labeling uses a model’s output (from an off-the-shelf model for teams that don’t yet have their own) to generate pre-labels, which labelers can modify according to your project’s ontology. Even if this method will only shave off a few seconds of time for the labeler, it can still add up to hours of efficiency for a whole training dataset.
Once AI teams have a benchmark model in place, they can use it to create pre-labels that will make labelers’ work still easier. As the model improves after each iteration, time spent labeling — or in the case of late-stage iterations, correcting labels — will be significantly shorter than labeling an asset from scratch.
Training your model
Once you’ve started training your model, there are a few practices that will help you iterate on it quickly and ensure that every iteration significantly improves performance.
Diagnose model performance
It’s important to keep a close eye on your model as it trains. One way to do this is to compare your model’s output to ground truth. A training data platform will allow you to upload them together in a model run and visualize model performance, filter down data rows, and monitor performance over time. It’s also an easy way to provide rapid feedback and updates to all stakeholders on the project.
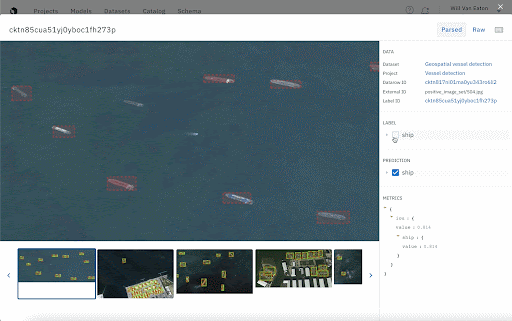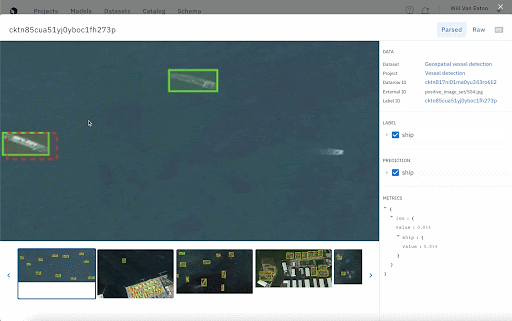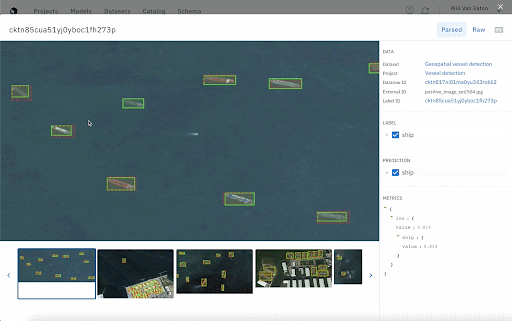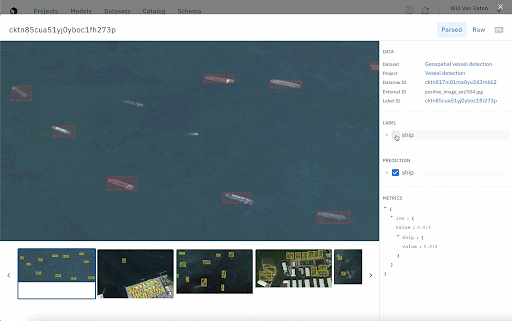
Curate your next training dataset based on model performance
If your team is creating training data in small batches as we recommended above, you’ll also have the ability to carefully select your datasets based on how your model performs in specific classes, situations, and edge cases. If your model exhibits low scores for a certain class, you can give it more examples of that class in the next dataset.
Scouring a large dataset for examples of a specific class, however, can be a time-consuming challenge. To address it, you can use embeddings (an array of numbers assigned to an asset by a neural network) to visualize your dataset and find groups of similar assets. Read our blog post about using embeddings to curate data to learn more.

To learn more about the best practices outlined in this post and see demos of how they work in Labelbox, watch our on-demand webinar, The training data practices used by the most successful AI teams. You can also read our ebook for more tips and case studies.


