×![]()

 All guides
All guidesHow to natively annotate a PDF document
PDF documents are inherently complex – they often contain lots of text, images, charts, graphs, and more. Information within PDFs can be interpreted in many different ways and traditional OCR solutions are not sufficient in capturing both text and visual information, which is vital for document image understanding and can limit the accuracy of your model.
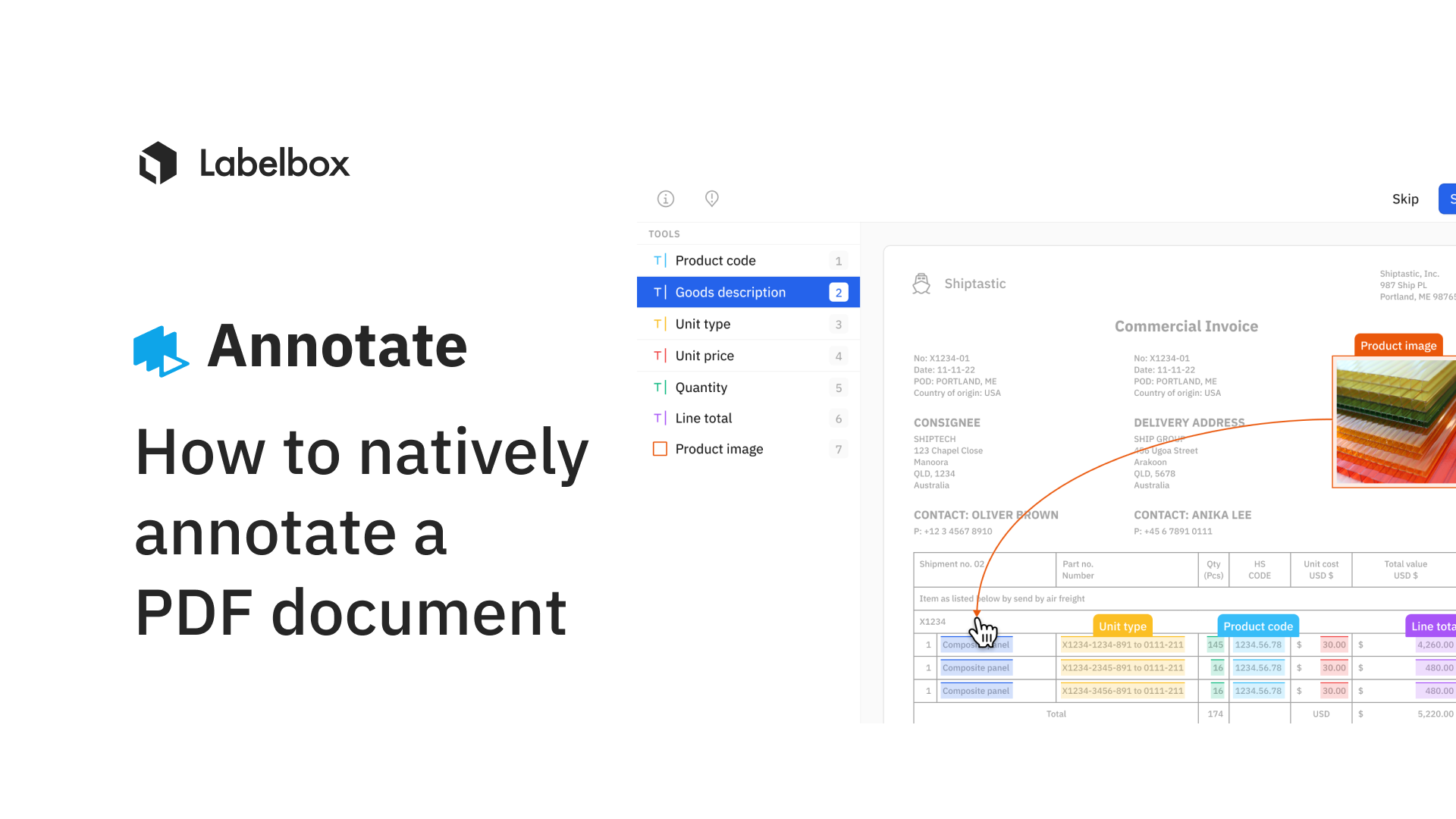
Our Document editor is a multimodal annotation platform. You can easily turn stores of PDF files and documents into performant ML models. With the ability to use an NER text layer, you can easily annotate text of interest alongside OCR, without losing context.
With our Document editor, teams can:
- Natively upload whole PDF files
- Easily navigate pages and zoom in & out
- Create and use a custom text layer
- Save and export raw text
- Create entities (for NER) - including tokenization at the word-level & character-level
- Create bounding boxes (for OCR)
- Use model-assisted labeling to import bounding boxes
- Create annotation relationships - including between annotations that span different pages
- Classify your PDF - with radio, checklist, and free-text classification
- Use hotkeys to speed up your workflow
To learn more about our Document editor, please refer to our documentation.


