
 All guides
All guidesHow to scale up your labeling operations while maintaining quality

Many machine learning (ML) teams are eager to label all their data at once. While this approach seems like the quickest way to feed training data into your models, it can often backfire by actually increasing time and cost. This “waterfall” approach to AI data labeling makes it difficult to ensure accuracy, as data annotation requirements often evolve as a ML project progresses.
Instead, leading ML teams manage their labeling workflow by making use of iteration with small batches and an initial calibration phase. During the calibration phase, more supervision and feedback is given to labelers to ensure they understand the task at hand. This iterative loop builds a strategy to tackle any edge cases that arise, and allows teams to adjust the ontology as both labelers and other stakeholders develop a better understanding of the project.
While incorporating these phases into your ML data labeling process, to train and validate, might seem like it lengthens your timeline, they’ll be minutes compared to the delays caused by a large labeled dataset full of errors. Despite the initial timeline looking shorter for a non-iterative labeling process, teams find that iterating quickly and early delivers better results faster.
An iterative approach to producing training data
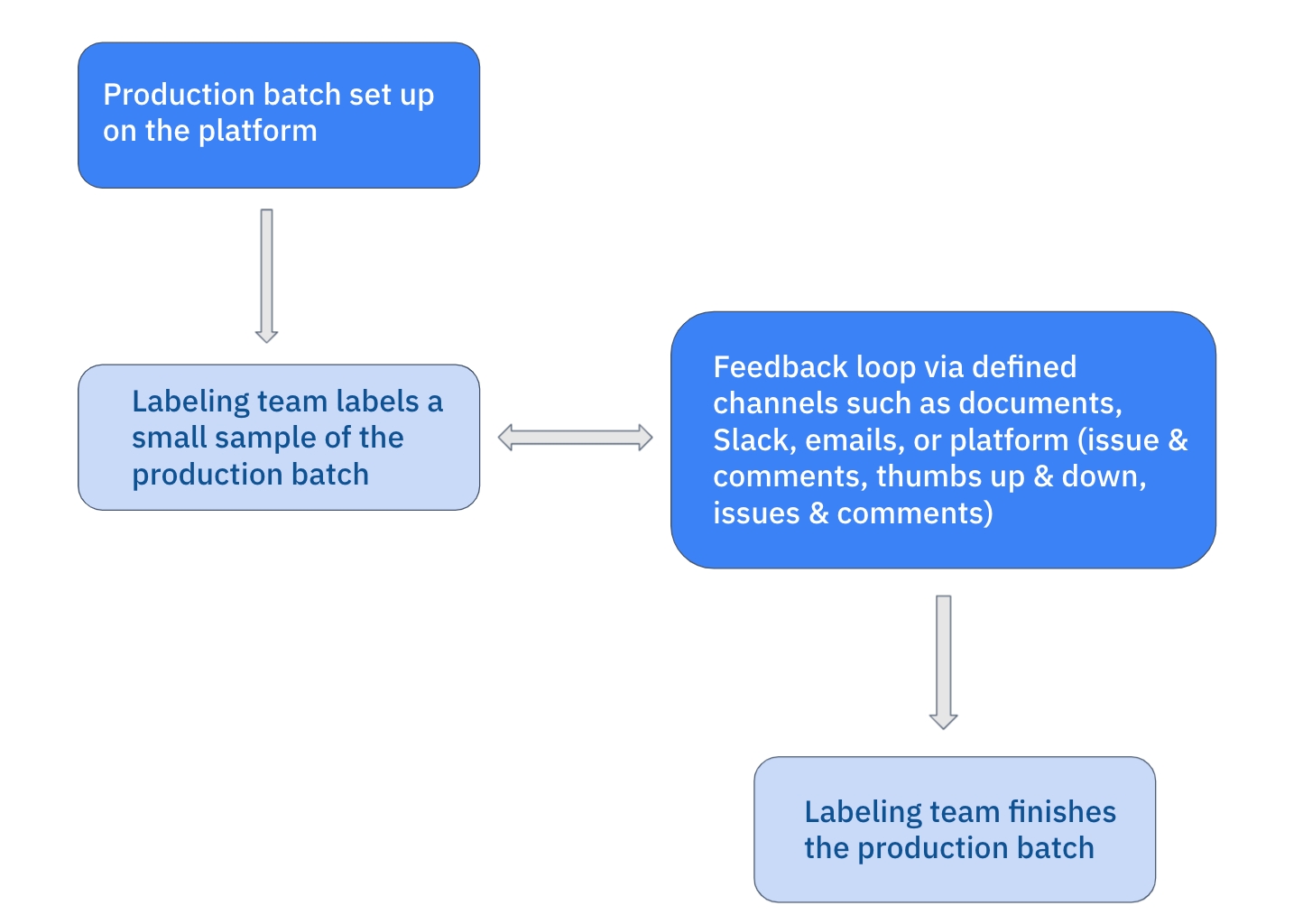
Maintaining quality while scaling
The key question we aim to answer is: how to maintain consistency and quality with a larger team and volume.
To do so we recommend implementing the following two phases into your workflow:
Calibration Phase
The calibration phase can be thought of as a smaller subset of your task. It is used to train the labeling team on the labeling instructions, the ontology, and to help them become familiar with the data in the project. This phase helps raise questions from the labeling team and identify edge cases within the data and how to handle them.
Building a sustainable communication loop here is key. The labeling team should be very communicative with questions and feedback. As the project owner, you want to be as responsive as possible in this phase and provide lots of feedback on the annotations.
Constructive feedback at this stage will help the labeling team understand your requirements better and will be used to train the labelers and reviewers going forward.
Within Labelbox there are a few ways you can incorporate feedback:
Additional ways teams provide feedback is through:
- Shared feedback documents (Google doc, quip etc.)
- Feedback through external communication channels via email, Slack etc.
- Regular syncs via Zoom, Teams etc.
The calibration phase is meant for the labeling team to iterate on the data until they reach the desired quality expectation. Speed is often not as important in this phase as the labelers overcome the learning curve of the project, and allow for new team members to get hands on and train prior to labeling in the production phase. Focus on quality first, and the speed will come.
Production Phase
During the production phase of a project, monitoring overall quality and speed is of utmost importance as it is the key for the successful outcome of your labeled data. Establishing SLA’s in this phase will ensure your team and the labeling team are synchronized on all requirements.
It is best to increase the workforce gradually. By incrementally increasing the size of your labeling team, it allows you to not be overwhelmed by metrics and ensures that each member is meeting your standards.
Having additional QA performed throughout the lifetime of a project allows errors to be noticed. When errors surface, labelers can be put back through the training cycle so that only those labelers that meet your quality standards are labeling in production.
A valuable tip when creating production projects and evaluating labeling speed is to set up multiple milestones instead of one big project. This will help you test your model earlier and make sure that your project is trending in the right direction. For a labeling team, completing a milestone should not only entail labeling all necessary assets, but also QAing them to reach high quality and to improve with every milestone.
Milestones are a great way to set up your data labeling projects because it allows for maximum flexibility. For example, if your model does not perform well or the output is not quite right, then you can still change your guidelines, your task set up or retrain the team accordingly before starting the following milestone. This way you have not lost a lot of time or created duplicative work.
All of these steps work together to ensure that your exported labels are exactly what you need and were achieved in a timely and cost effective manner.


