
 All guides
All guidesHow to accelerate and automate data labeling with labeling functions
When it comes to data labeling and annotation, an approach that teams like to evaluate is the efficacy of using programmatic labeling via labeling functions to speed up their labeling operations. You can think of labeling functions as a set of rules or instructions that you follow in order to help automatically assign labels or categories to your data. This is especially useful when working with large datasets where manually labeling each piece of data could be resource or time-intensive. In this guide, we'll cover two specific workflows around how teams can perform labeling functions within Labelbox.
With recent advances in foundation models, teams can now incorporate models such as GPT, Gemini, Claude, etc to kickstart a zero-shot or rules-based approach for labeling at scale. This can work well for regular expressions to identify phone numbers, zip codes, currencies, etc. Without having to train any models from scratch, you're able to simply call an API and have it complete many of these tasks. However, the nature of these generative AI models is that there may still be prone to hallucinations or there may be a desire to include custom business level logic that you may want to supplement in your labeling workflows. Generative AI models are also not inherently meant to address rules-based approaches as typically found in custom business level logic or reg expression. In these situations, having the ability to leverage custom labeling functions is needed.
Let's get started and you can follow along using the Colab notebook here.
Part 1: An SDK-Approach to Creating Labeling Functions
You can follow this guide via text or watch the video walkthrough above. To get started, imagine you have a dataset of customer comments for product reviews, and your goal is to run sentiment analysis in order to identify positive, negative or neutral emotions across different comments.
1) With an SDK-approach, you can first navigate over to your coding environment, and install the appropriate set up steps shown in the notebook provided. The first step is to come up with several different rules or labeling functions based on keywords, phrases, heuristics, or knowledge sources that are commonly associated or attributed to your different sentiment categories.
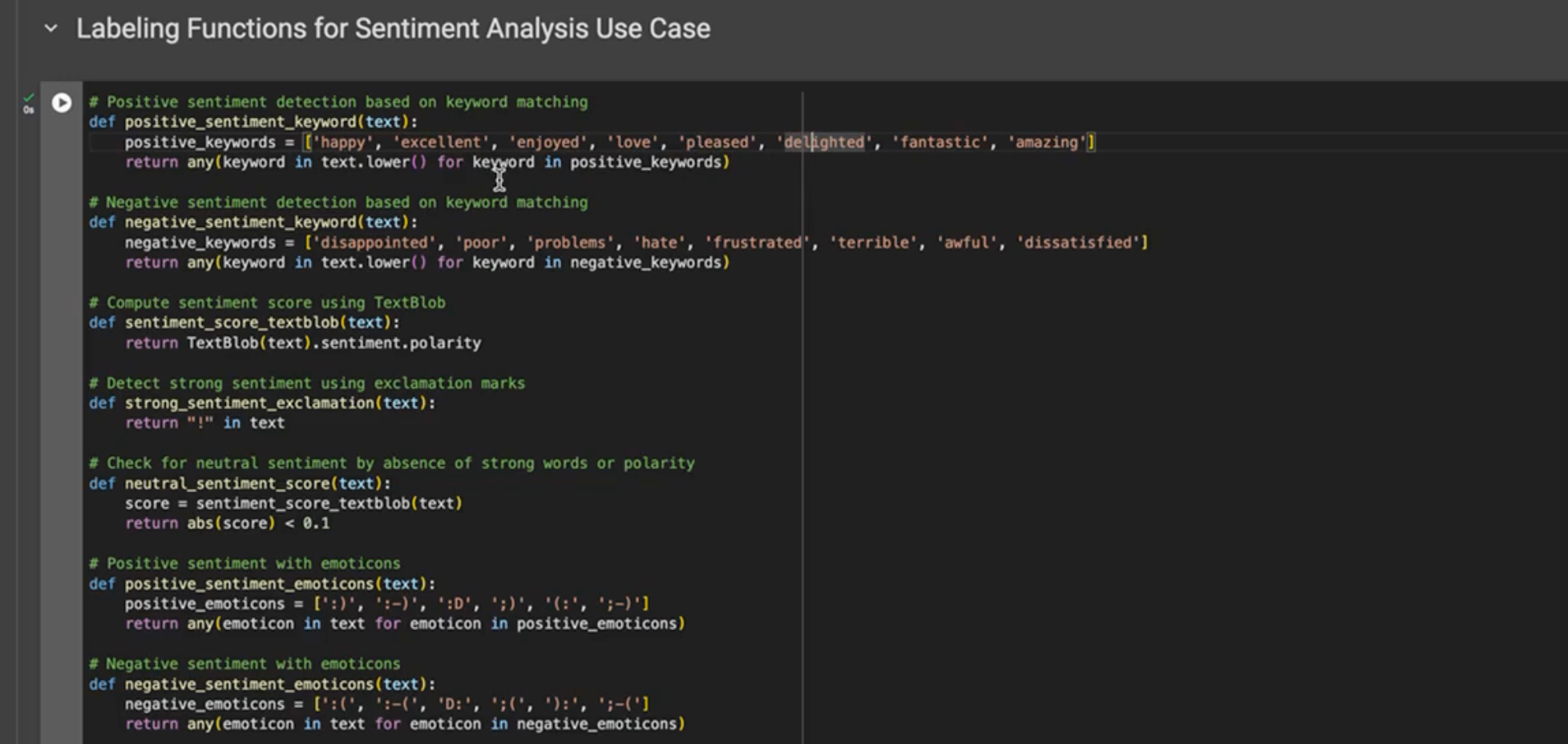
2) An example of a rule that you could use is if your comments data set contains the words "happy" or "excellent" or "delighted". You can use these words as the anchor for your keywords and assign a positive label. Similarly, if the text contains any of the negative words that serves as the basis for negative keywords, then you can assign this as a negative label.
3) Note that there may be times when a comment is ambiguous or contains both positive and negative words. As an example, this could be something like "I love how this product looks but I hate how it works". In such cases, labeling functions can be designed with more nuanced rules to decide the overall sentiment such as considering the context or the number of positive versus negative words. In the example shown, we've used a library like TextBlob to help with defining several of these labeling functions and returning true if the text meets the criteria and false otherwise.
4) Now that you have all of your initial labeling functions, the next step is to aggregate the outputs from these labeling functions in order to make a more accurate and reliable prediction about the text sentiment. You can choose to use a variety of aggregation approaches, whether that's majority voting, weighted voting or any other voting based technique.
The process whereby you're taking several noisy or weak labels and aggregating them to a strong label using an aggregation technique is commonly referred to as "weak supervision". Each labeling function can be thought of as an "expert" that provides their opinion on how a data point should be labeled, but these experts may not always be right.
5) The goal is to amortize the cost of these potentially noisy or weaker labels by coming up with a strong label. In the example shown, if you were to go with a majority voting-based approach, the idea is that we can define our classes and our aggregation function through a tally up score for your different labels. By going ahead and doing that for positive, negative, or neutral sentiments, you're taking the max score and the max label associated with the max score and assigning that as your final sentiment value. By applying this on you sample piece of text, it returns positive as expected.
6) The next step is to iterate through all of your text assets in your datasets. Using your aggregation function turns your predictions for the sentiment using the rules-based functions that we had seen above, reconstructing the Python annotation and you can use this as the sentiment schema in your ontology, collect your labels, and import it as a label import job to upcert all of these labels into Labelbox .
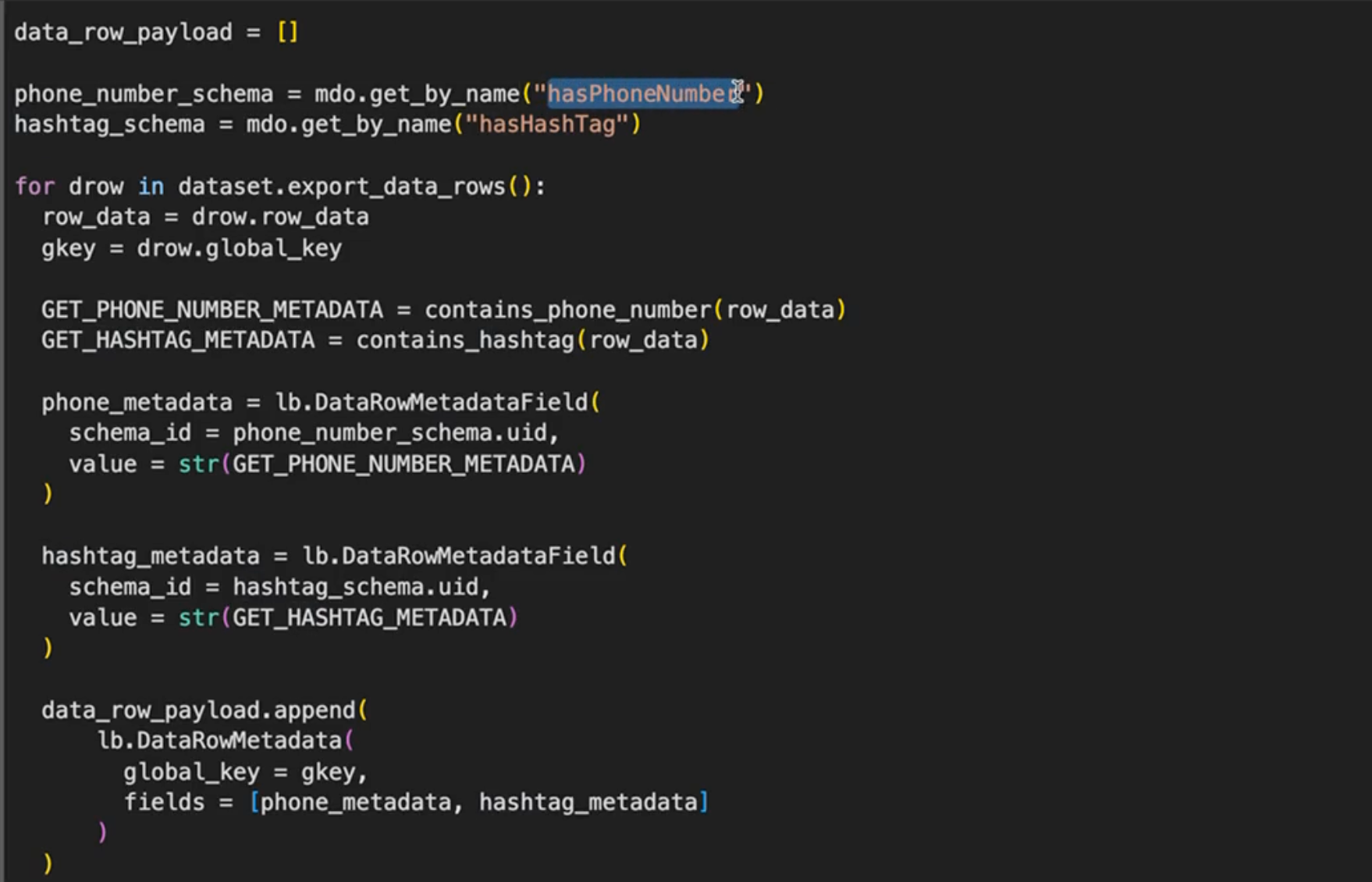
In this example shown above, we are defining metadata fields for whether or not the text contains a phone number, whether or not the text contains a hashtag, and define your labeling functions. If it meets that criteria then you'll want to set the metadata value to be whatever is returned from that labeling function. Go ahead and bulk upcert those metadata fields. And once this is all done, you can navigate over to the Labelbox UI.
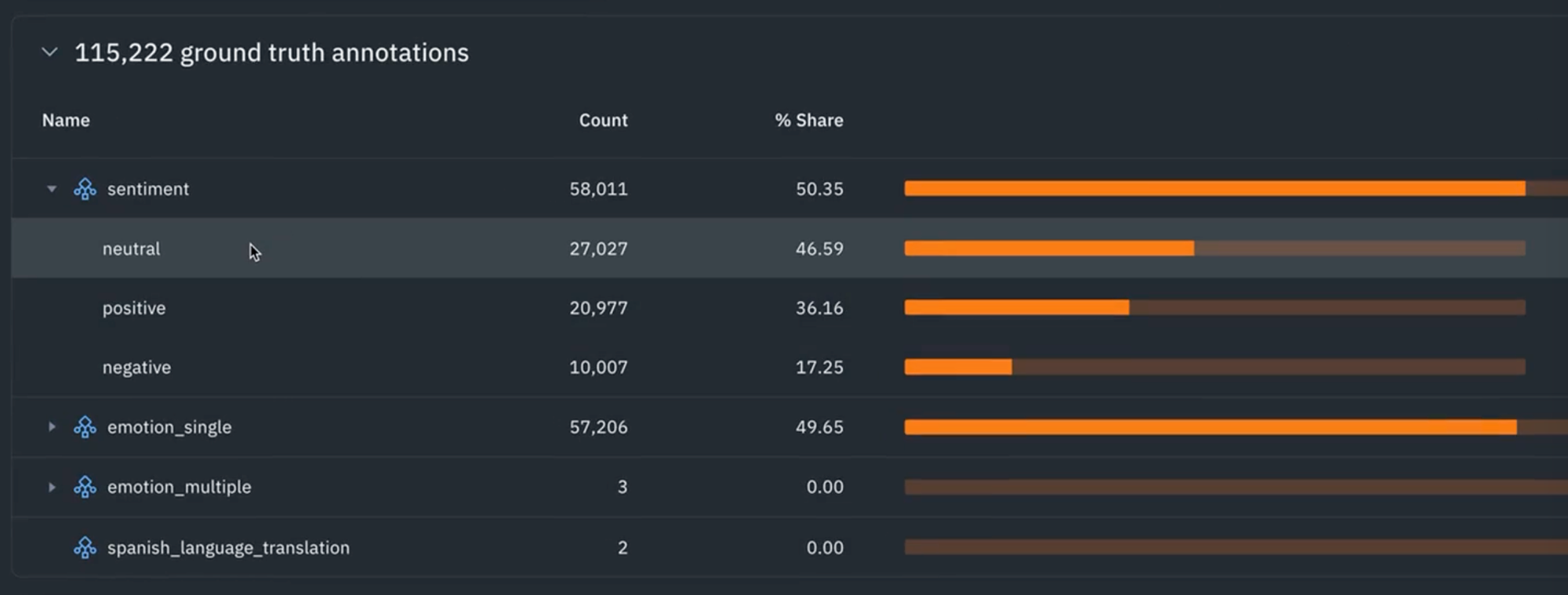
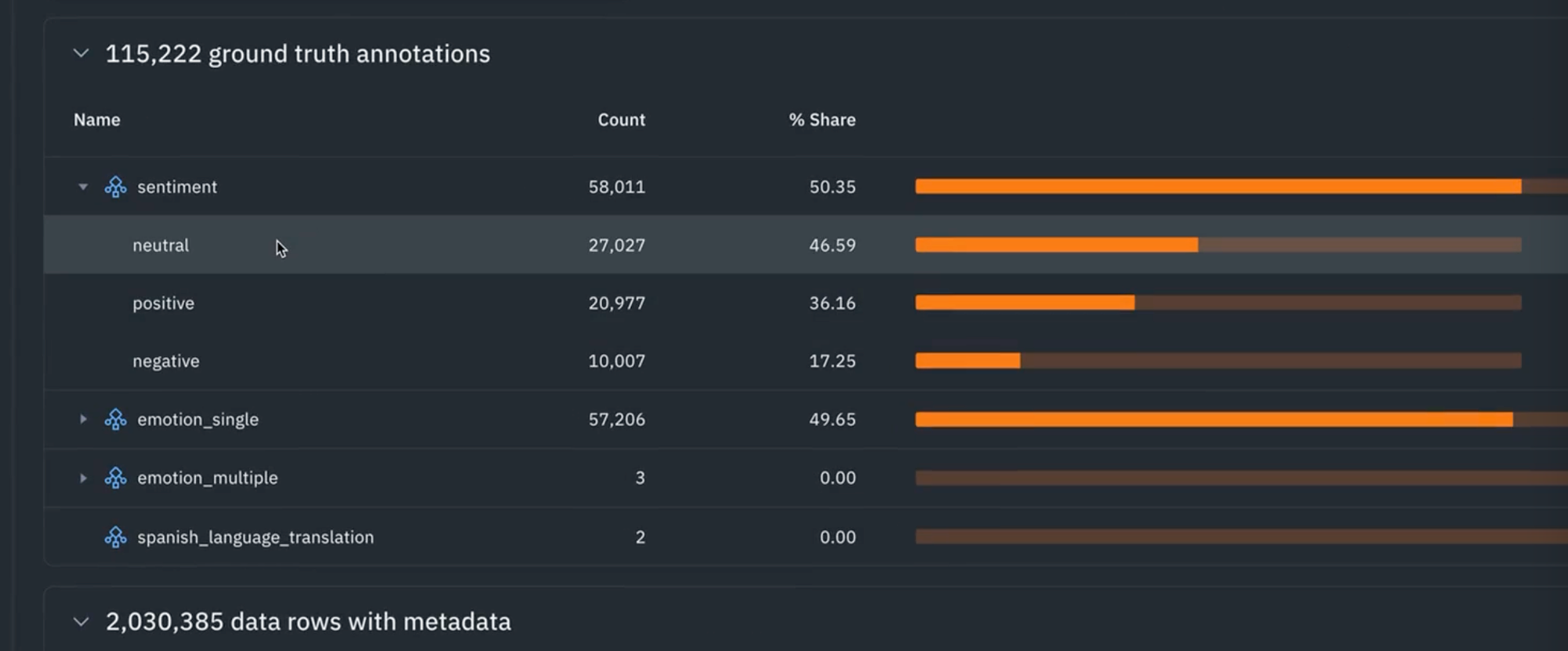
7) By clicking on the Analytics tab, you can now see all of your sentiments labels. These are the labels that are a result of running the labeling functions in the notebook. You'll see that roughly 46% of the text has been labeled as neutral, 36% percent is positive, 17% percent is negative. If you want to click into one of the specific classes, you can see the sentiment for negative and there's roughly 10,000 records. Similarly, if you wanted to observe what the metadata distribution looks like, you can see that for the phone numbers and for the hashtags.
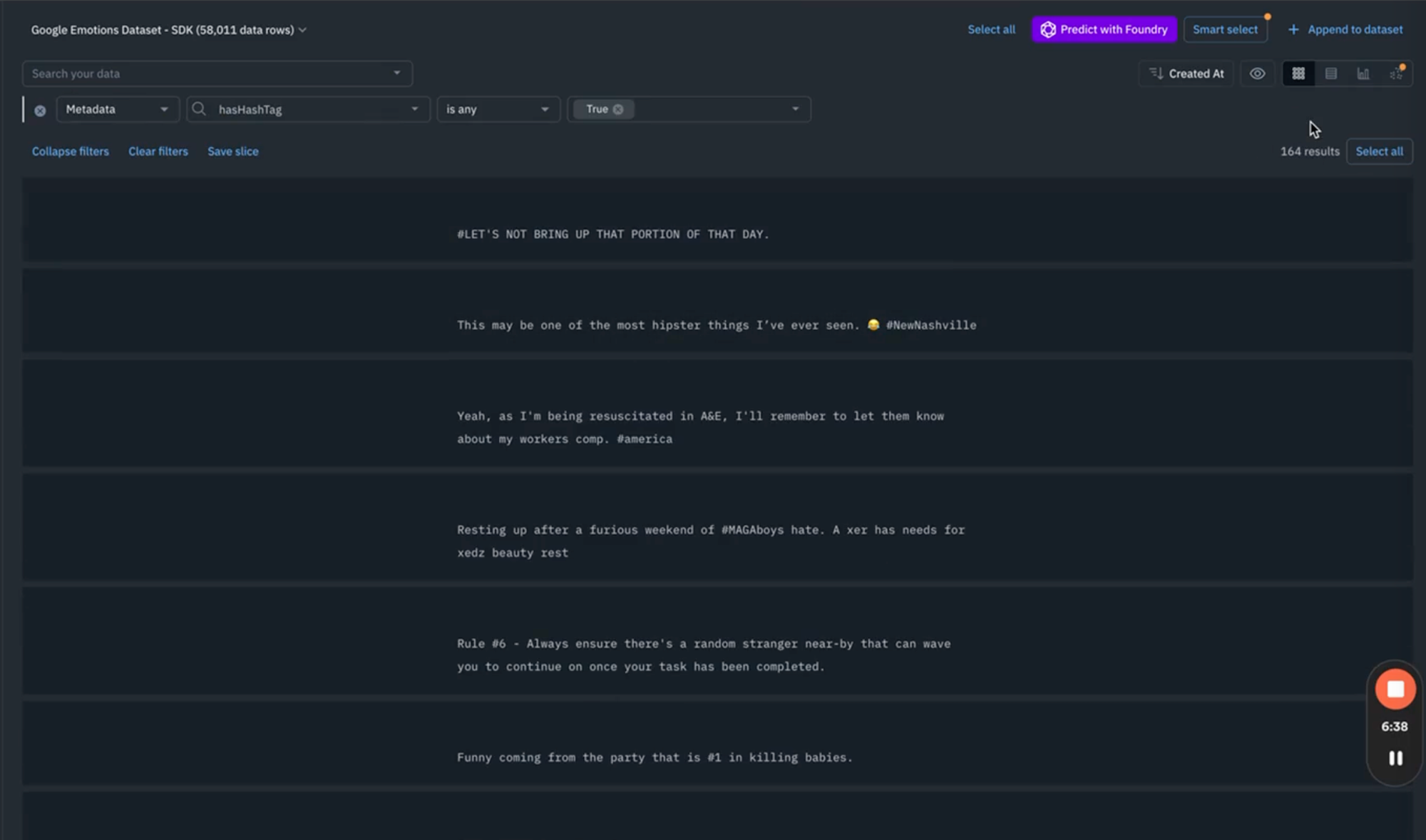
8) By selecting all the text that contains hashtags, you see around one hundred and sixty four results. This SDK-approach enables teams to quickly labels large datasets, saving time and effort. You can easily add, remove, or adjust rules as you discover new patterns in how sentiments are expressed, especially in instances where over time, you'll observe that there's variations in the way that vernacular or jargon or slang is being used across your text.
This wraps up the first part of the guide on how you can use labeling functions within the SDK for bulk labeling data and bring that into the Labelbox UI. In the next part, let's cover how you can perform rules-based processes within the Labelbox UI for faster annotation.
Part 2: Using the Labelbox UI to Create Labeling Functions
Now that you've seen how to leverage labeling functions by using the SDK to bulk label your data, let's walk through you can accomplish a similar workflow directly from the Labelbox UI.
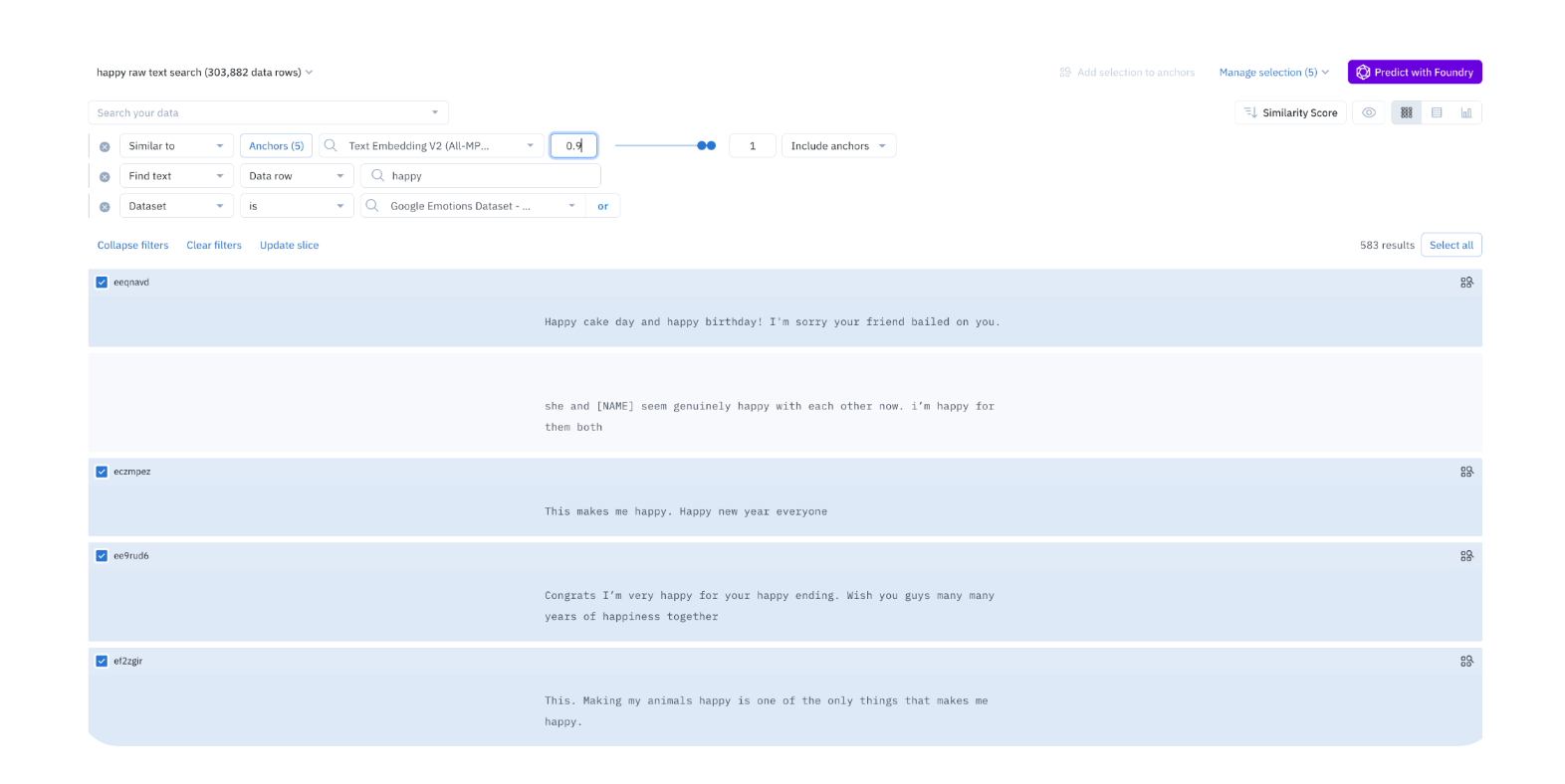
1) One of the first features you can take advantage of in Labelbox Catalog is the find text feature, which allows a Labelbox user to search raw text occurrences of a specific word or sequence of words across their data set.
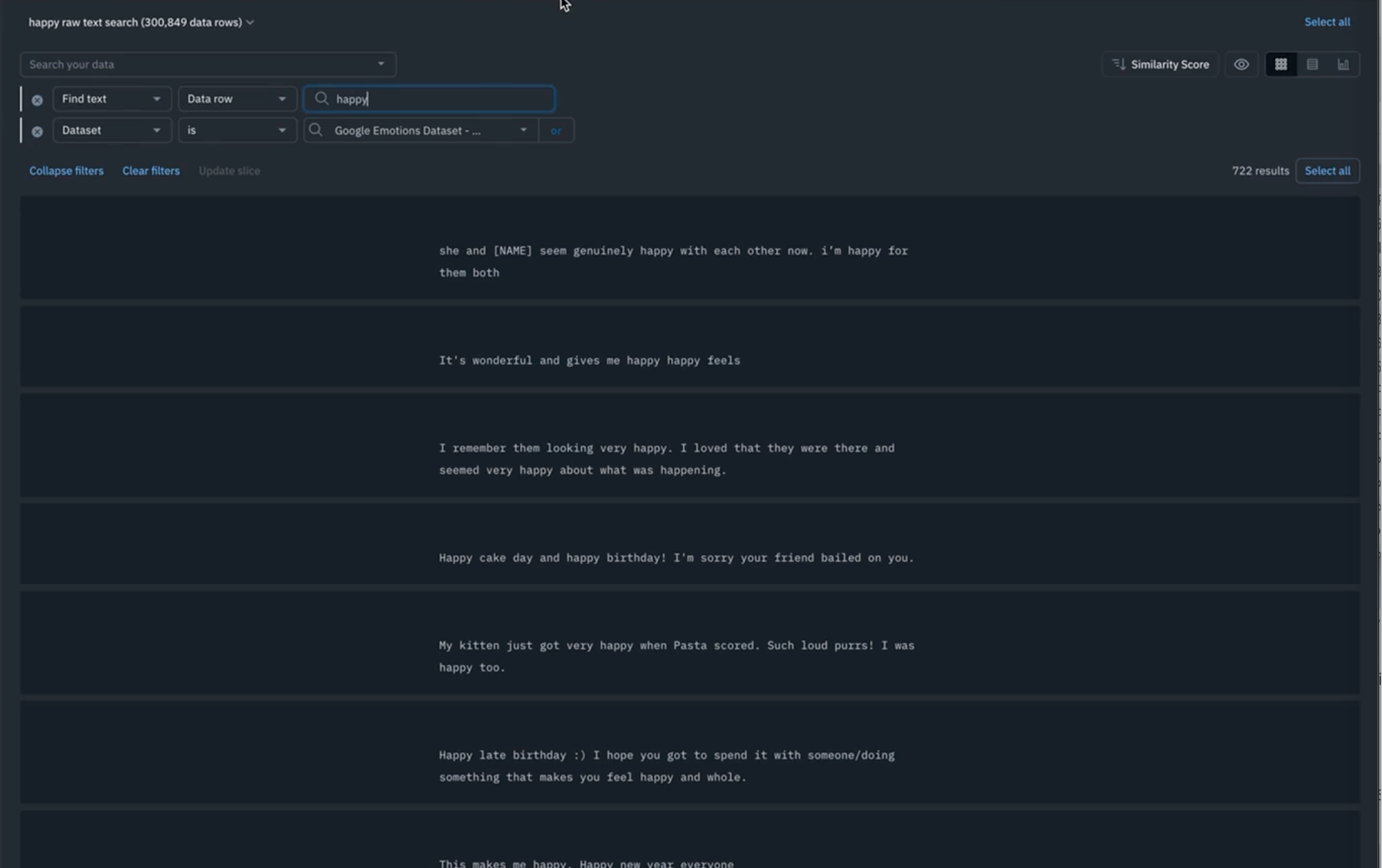
As an example, if you want to find all occurrences of the word "happy", you can use this feature to see all of your data rows that contain the words "happy". From here, you can save this as a slice and name this as a "happy" raw text search and hit save. Any time new data gets added that meets the filtering criteria, it will automatically get added to the slice. This is equivalent to writing a similar Python function that does a substring match or raw text search to match the specific word.
2) You can also take advantage of Similarity Search and select a subset of these data rows and click "similar to selection". Labelbox leverages built-in embeddings that get automatically generated. Instead of looking just for the raw text of "happy", you can look for text that has the overall theme or structure of happiness. You can select all of these data rows and toggle by confidence level to filter by an even finer granularity.
3) Next, you can add a pre label or metadata. As an example, let's add metadata by selecting that option, and selecting the emotion category for "happy" and hit save. This will apply that metadata to all of my data rows in bulk. Similarly, if you wanted to add additional classifications, you could do that as well.
Use Aggregation Functions to Group Weak Labels into a Strong Label
One of the other things shown in Part 1 of the SDK demo was how to leverage aggregation functions to group together several weaker labels into a strong label. Let's cover how you can do this all directly within the Labelbox UI.
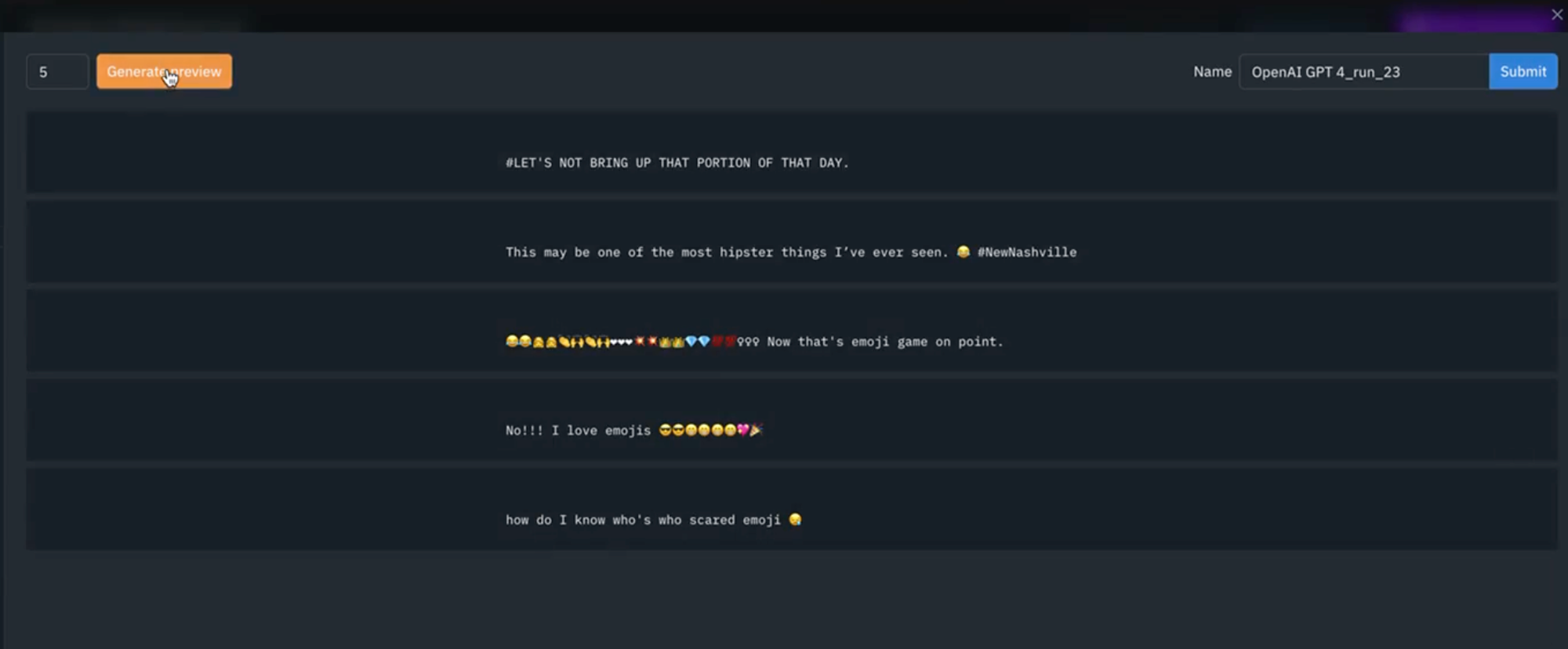
1) First, curate a subset of text records that contain hashtags and emojis with the goal of getting labels for whether or not each of these text records contain hashtags and emojis. Select all of these data rows and hit "Predict with Foundry".
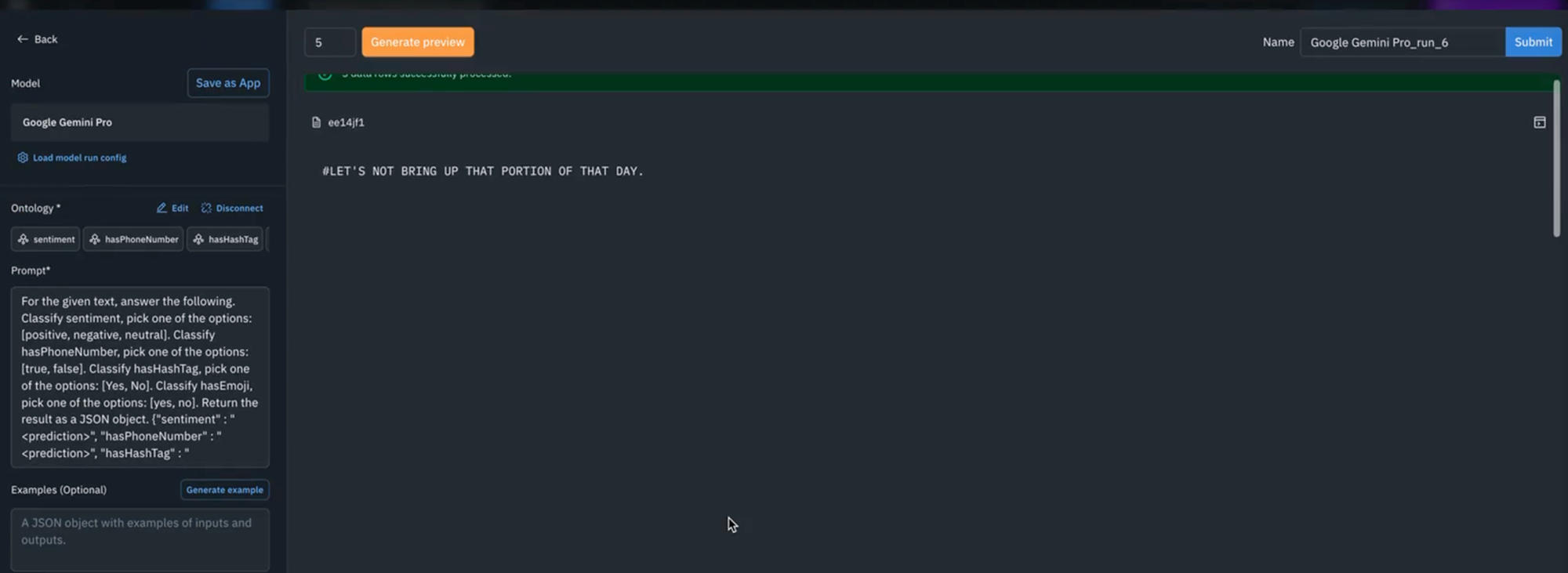
2) Next, choose a foundation model of choice (e.g., GPT-4 in this case) and connect that to an ontology, and hit generate preview. Once this is done, GPT-4 will come back with predictions on whether or not the text contains hashtags and emojis. This approach will work with many advanced foundation models including Google Gemini so let's compare, and you will see that Gemini also has returned with a different set of predictions.
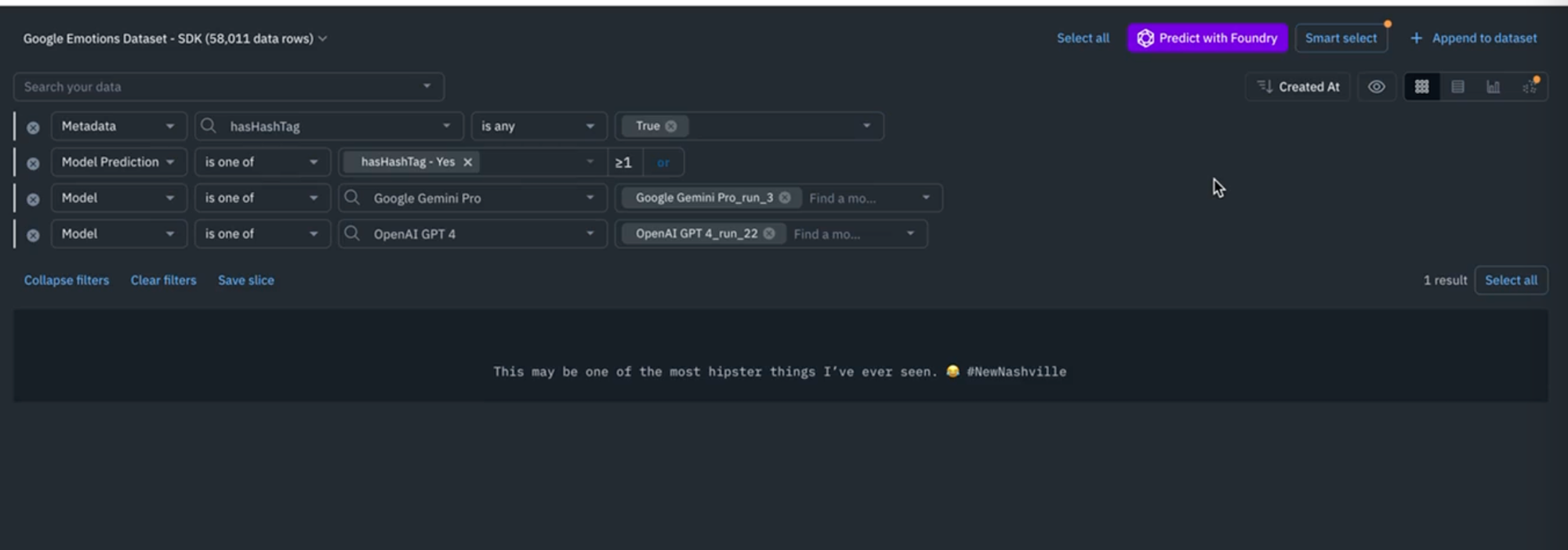
3) Finally, navigate over to your data set and deselect all of your data rows, and select the different models that you just ran (GPT-4, Gemini, etc). If either of these two models have predicted that it contains hashtag as true. If Gemini has said yes and a GPT four has said yes, and if you notice that your metadata value that was imported earlier from the SDK, also says that it has a hashtag, then you'll have 3 different signals that are telling us this contains a hashtag. By providing 3 different weak labels that you feel pretty confident about, you are now able to aggregate that to be your strong label and use these signals to improve your overall data annotation process. To complete the project, go ahead and select your data, hit classification, choose your project, and set the "has hashtag" as "yes" and then hit "Submit". To wrap up, this approach shows how you can leverage weak labels and weak supervision to come up with a strong label for your data directly by using the Labelbox UI.
Conclusion
In this guide, we walked through two approaches for creating labeling functions with Labelbox for speeding up data labeling and annotation. By embracing programmatic labeling approaches through the utilization of labeling functions, teams can enhance the efficiency of their overall labeling operations for a variety of verticals especially in domains such as retail/e-commerce, media and internet, and more. Give the solution a try using the notebook provided, and we'd love to hear your feedback or ideas on how we can help you improve your data annotation workflows via labeling functions.


