
 All guides
All guidesHow to uncover model errors with Labelbox Model
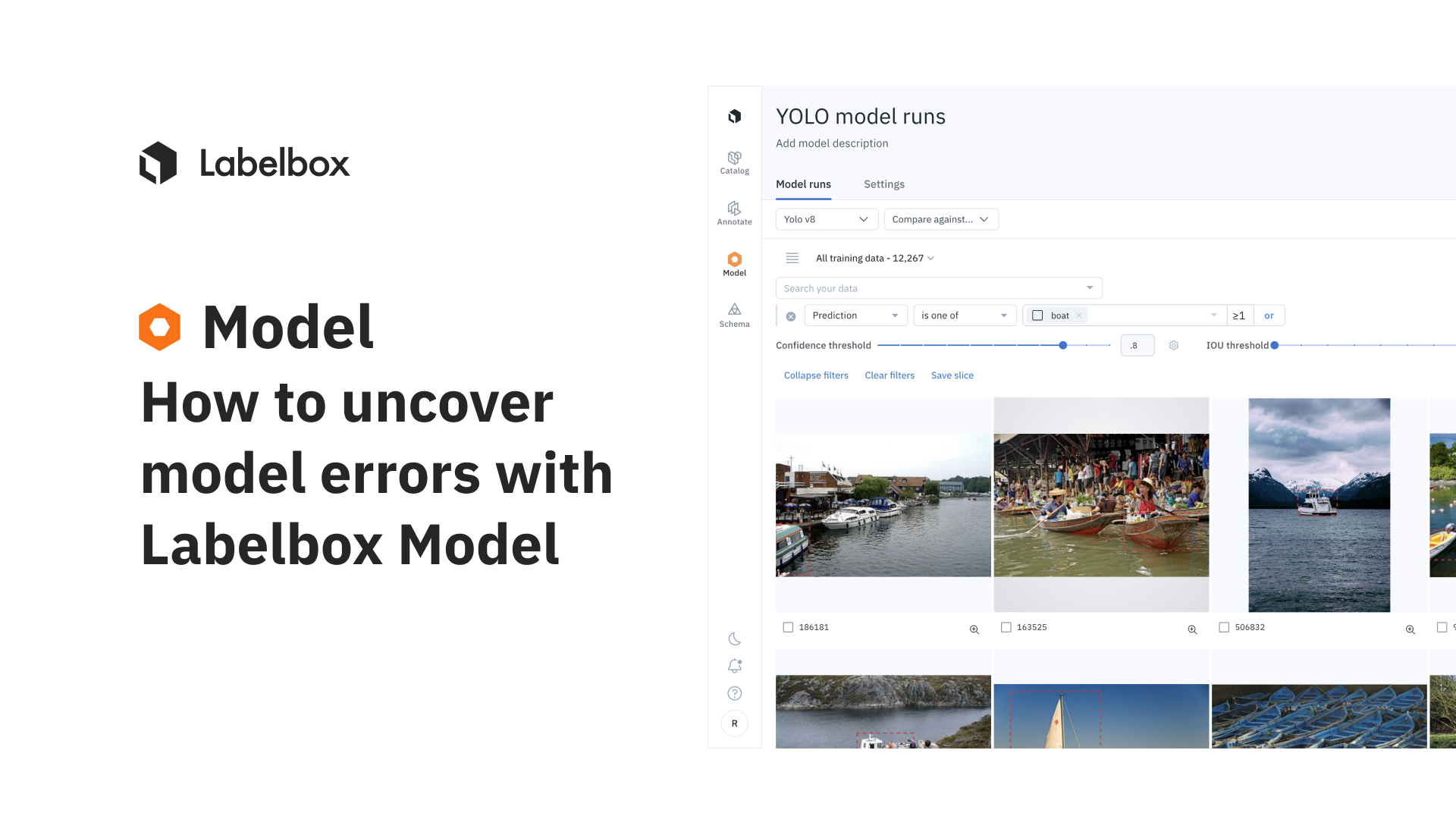
Machine learning models are only as good as the quality of their predictions. But how do you ensure that your model is making accurate predictions, and more importantly, how do you identify and address the errors your model might be making? In this guide, we will be exploring how to perform model error analysis using Labelbox, with a specific focus on utilizing the Gallery View and Model Metrics.
In the examples below, we’ll start by uploading predictions from YOLOv8 along with confidence scores to Labelbox model run. We’ll also use an open source dataset to provide a diverse dataset for testing the model. You can get instructions on how to upload model inferences to Labelbox here.
Gallery View: Identifying disagreements
Gallery View is a powerful tool for identifying disagreements between model predictions and ground truth labels. Here's how to use it for error analysis:
1) Go to the Gallery View within a model run. You may choose to focus on the Validation or Test split if you prefer.
2) Apply a Metrics filter to identify images with metrics that could indicate disagreements between model predictions and ground truth annotations. Users can sort the assets based on any combination of IOU, confidence, recall, false negative, and false positive etc.
3) Sort the data rows either by increasing metrics or increasing order of confidence. This can help surface rows where the model is least confident or is likely to be erroneous.
4) Inspect the surfaced data rows in detail to identify patterns of edge cases where the model is struggling. This may involve manually inspecting hundreds of data rows.
The video below shows an uncertainty sampling based on a low-confidence example.
The video below shows how to find model errors for a particular class by sorting in ascending order for IOU.
Identifying incorrect model prediction based on low intersection over union
Model Metrics: Identifying struggling classes
The Metrics View provides a comprehensive overview of how your model is performing. You can leverage this view to quickly identify classes that your model might be struggling with by:
- Inspecting the metrics in the Metrics View. In this example, we’re finding predictions that are false negatives and have recall value for a person between .2 to .3.
- Clicking on the recall value for person between .2 to .3 will open the Gallery View, which will have filtering and sorting activated to show assets associated with the particular class.
Fix model errors
Once you have identified a pattern of incorrect model predictions, you can find similar assets that the model will also struggle with and send them to be labeled before retraining your model.
- Select data rows on which your model is struggling.
- Open the selected data rows in Catalog by clicking on [n] selected > View in Catalog. You will then be redirected to a filtered view of your Catalog showing only the previously selected data rows.
- Use similarity search to surface data similar to this pattern of model failures among all of the data in your Catalog. Optionally, you could create a slice that will automatically collect any similar data uploaded in the future.
- Next, you could filter on Annotation > is none to surface only unlabeled data rows. Labeling this high-impact data and then re-training your model is a powerful way to boost model performance. Create a batch and send it to a labeling project.
Labelbox offers powerful tools and workflows to not only uncover model errors but also to improve the performance of your machine learning models over time. By leveraging the Gallery View, Model Metrics, and Projector View, you can identify where model might be struggling. Additionally, with the ability to fix these errors through data-centric iterations, you can ensure that your model becomes more accurate and reliable with each iteration.


