
 All guides
All guidesAn introduction to model metrics
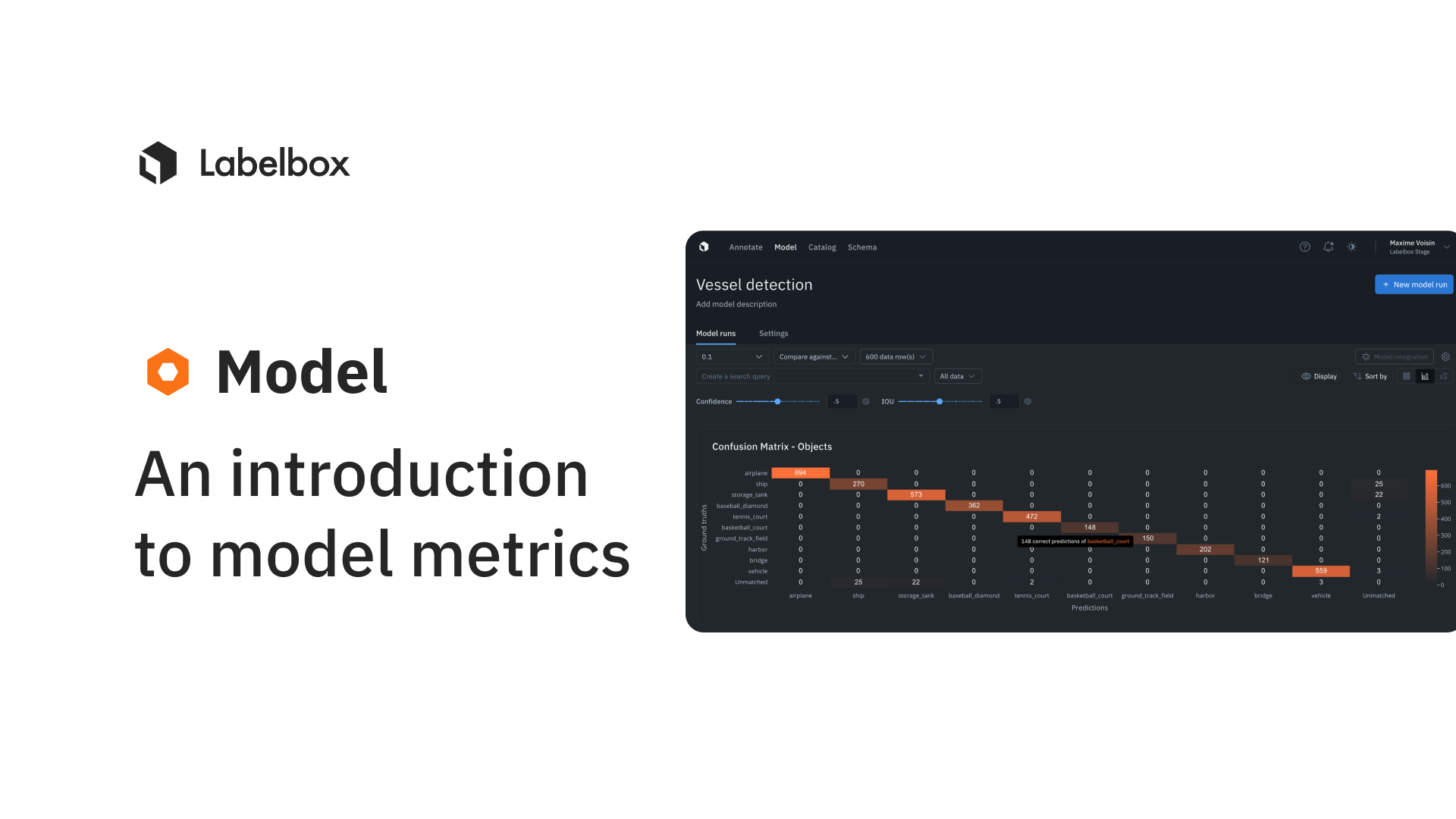
Model metrics help you evaluate the performance of a model and allows you to qualitatively compare different models. You can use model metrics to surface low-performing classes, find and fix labeling errors, and improve the overall performance of the model before it hits production on real-world data.
Why does model accuracy not give a complete picture of the model's performance?

Accuracy tells us the model's overall performance, but this metric doesn't provide all the information needed to accurately assess a model's performance. For a more holistic picture, we'll need to consider other metrics, based on the specific context that the model is used in.
Generally, accuracy tends to be high in situations where a class has a very low probability of occurring, so a model can achieve high accuracy by simply predicting the most common class. For instance, the probability of finding cancer in computed topography scans or of finding swimming pools from satellite images of homes is low, so the model's accuracy can be high even if the model's ability to detect true positives is very poor.
Precision

Precision metrics focus on consistency and agreement among labelers, which are primarily derived from Labelbox's built-in consensus capability. Labelbox uses and tests the effectiveness of over 15 similar metrics for a wide range of supported annotations.
Precision is a valuable metric when the negative cost of a false positive is high. For example, in spam detection models, a false positive would cause a vital email to be hidden and marked as spam when in fact, it is non-spam. A false positive in this case would negatively impact the user experience for seeing essential and urgent emails on time.
Popular precision metrics include:
- Krippendorff's Alpha is a popular metric used to assess the agreement among raters because it works well for two or more raters, can handle missing data, and supports nominal, ordinal, and ranking data types.
- Standard deviation measures the dispersion of a set of ratings from their mean (average) value. In the context of AI data quality, it quantifies how much variation or spread exists in the ratings given by different AI trainers for the same item or task.
- Percent agreement is a straightforward measure of inter-rater reliability that calculates the proportion of times different raters agree in their judgments. This is particularly useful in classification tasks (enums).
Recall

Recall is a helpful metric to use when the cost of false negative is high, and you want to minimize it. For example, in fraud detection models, a false negative would cause a fraudulent transaction to be successfully processed when it should have been flagged as fraudulent. This would obviously have a negative impact on the finances of the user. Recall is also helpful for most medical condition predictions, where you would minimize false negatives to increase recall.
F-1

In some cases with imbalanced data problems, both precision and recall are important – we can consider the F1 score as an evaluation metric. An F1 score helps in the detection of skewed datasets and rare classes. Generally, it is best to have high precision and recall so that your F1 score is high.
To demonstrate how accuracy only provides a partial assessment of a model's performance, we can compare the model metrics of two models below:
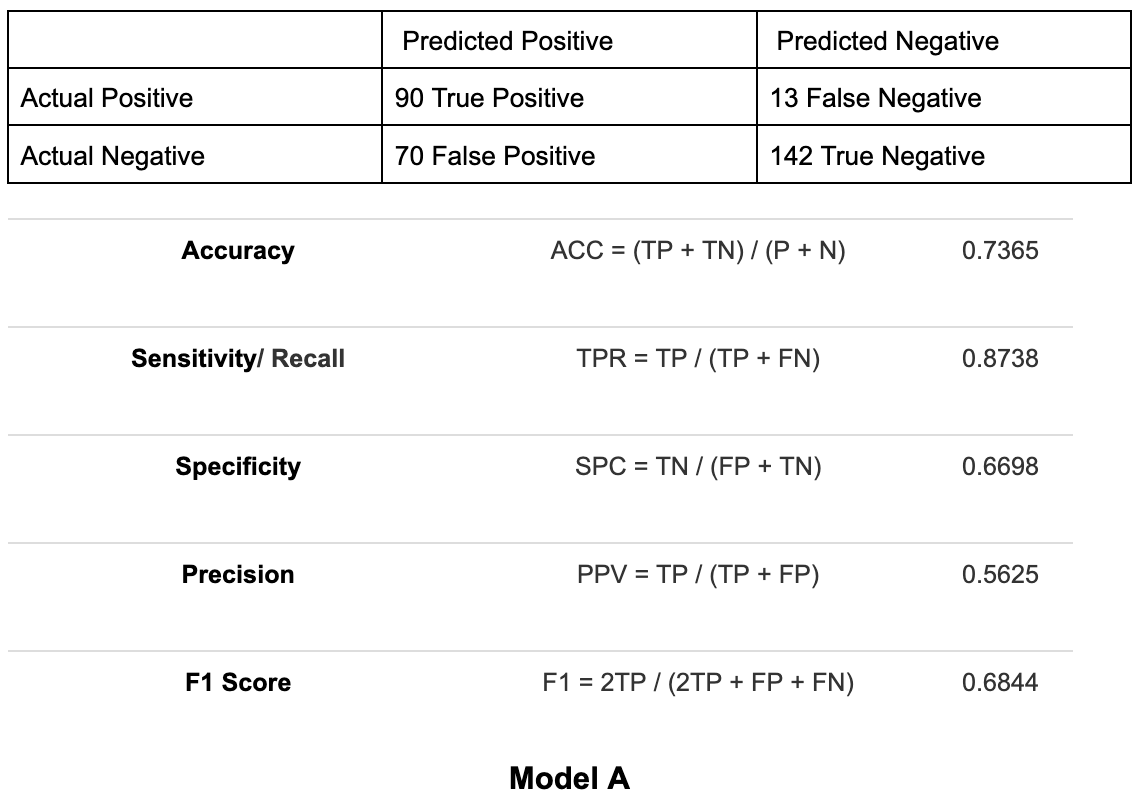
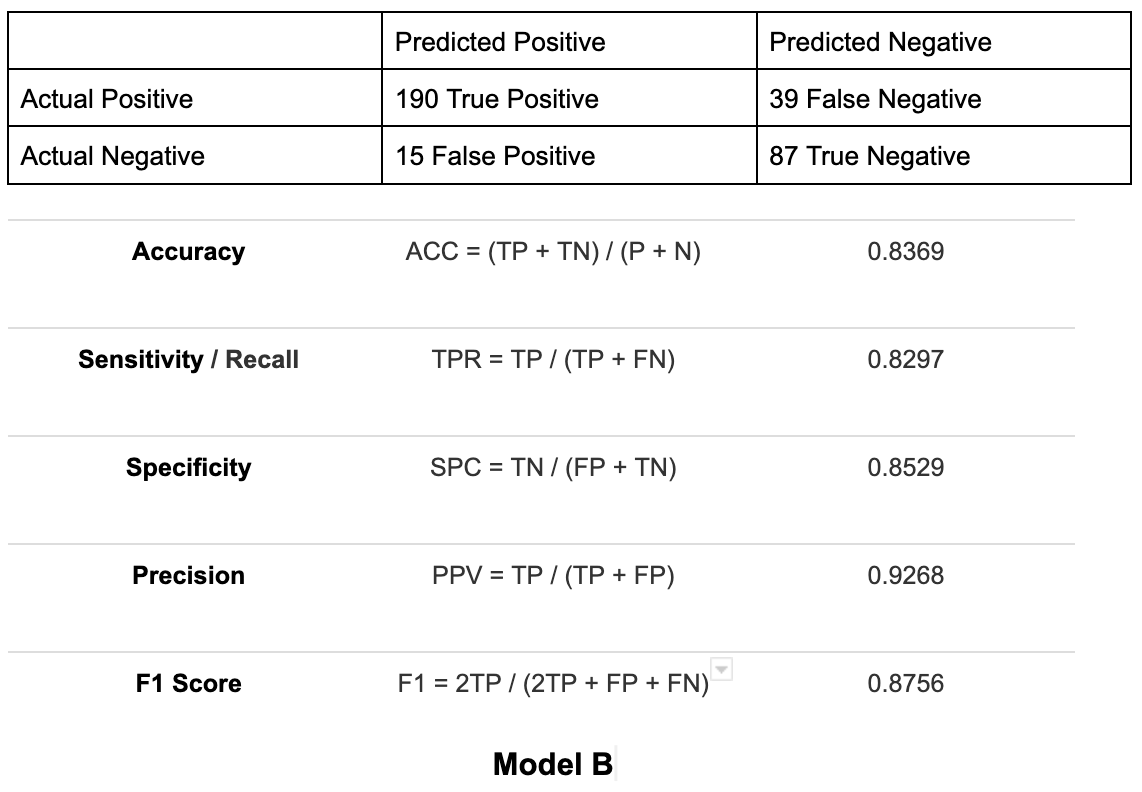
The accuracy in model A is 73.65%, and model B is 83.69%. Based on accuracy alone, model B seems to perform better. However, if you compare their recall scores, then model A has a better recall of 87.38% vs model B's 82.97% recall. Taking this into account, model A performs better since the cost of a false negative is high.
What do model metrics look like in Labelbox?
Rather than having you manually compute and upload metrics, Labelbox Model auto-computes metrics such as precision, recall, F-1, confusion matrix, etc. on individual predictions for you.
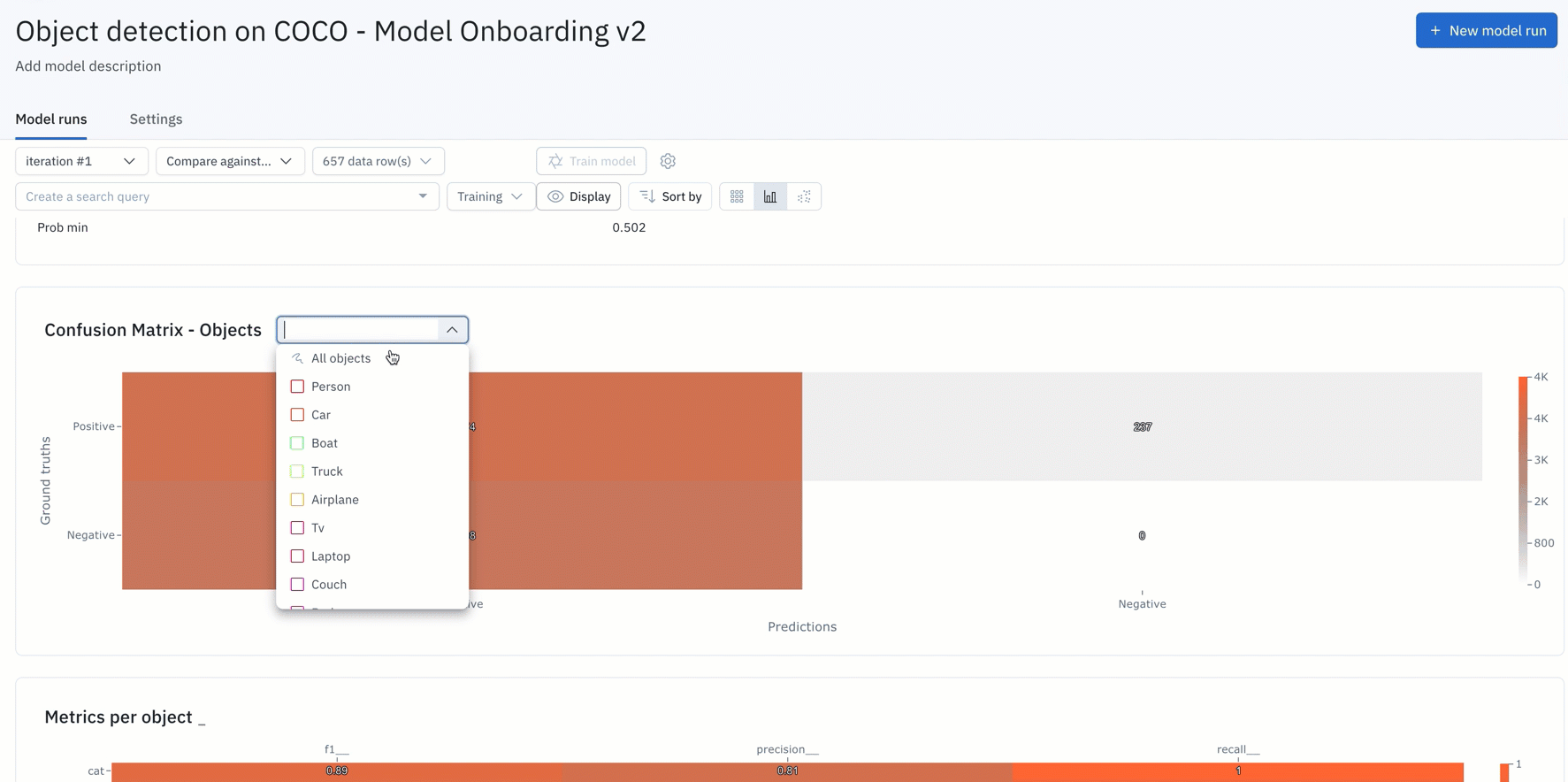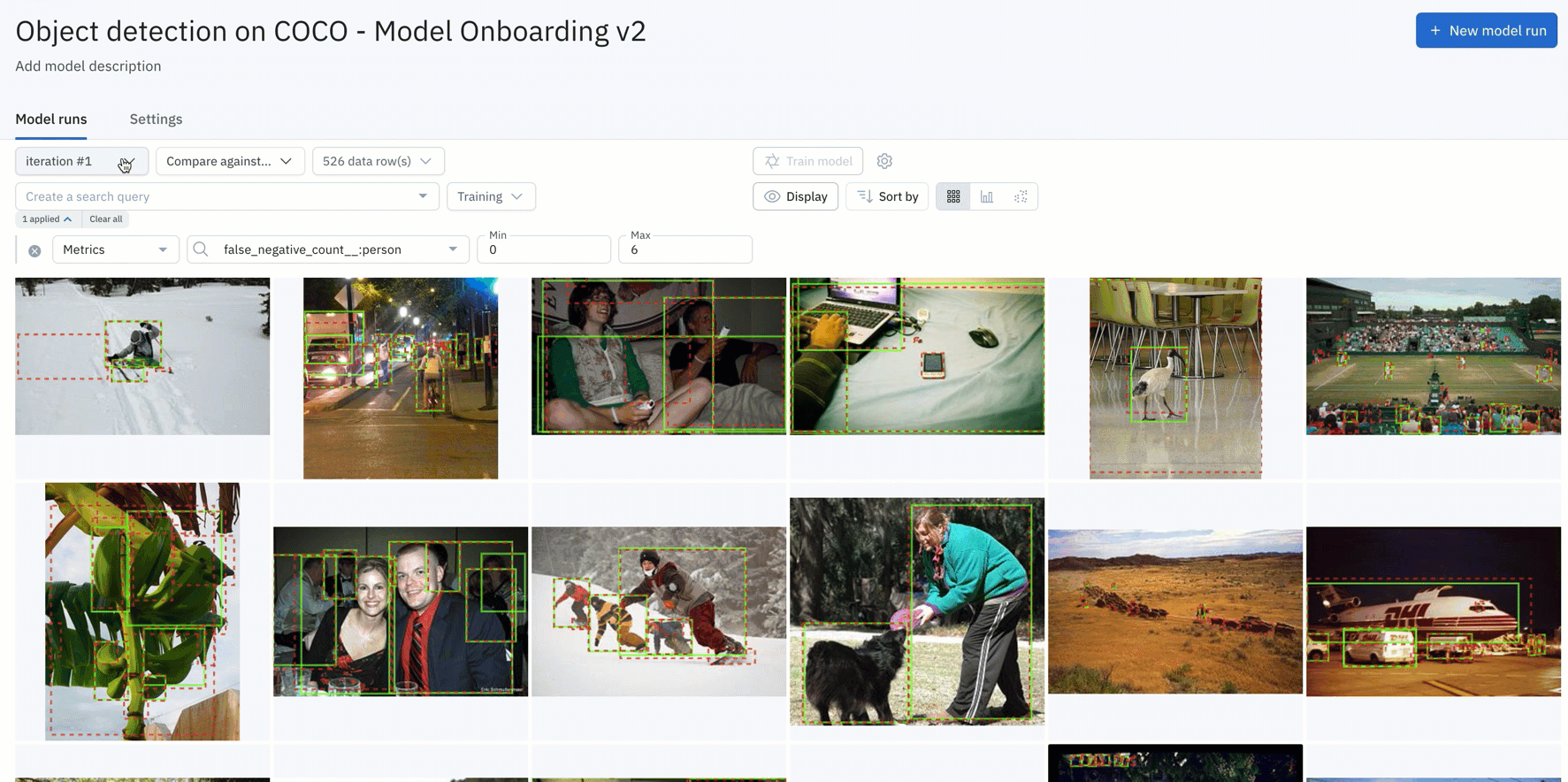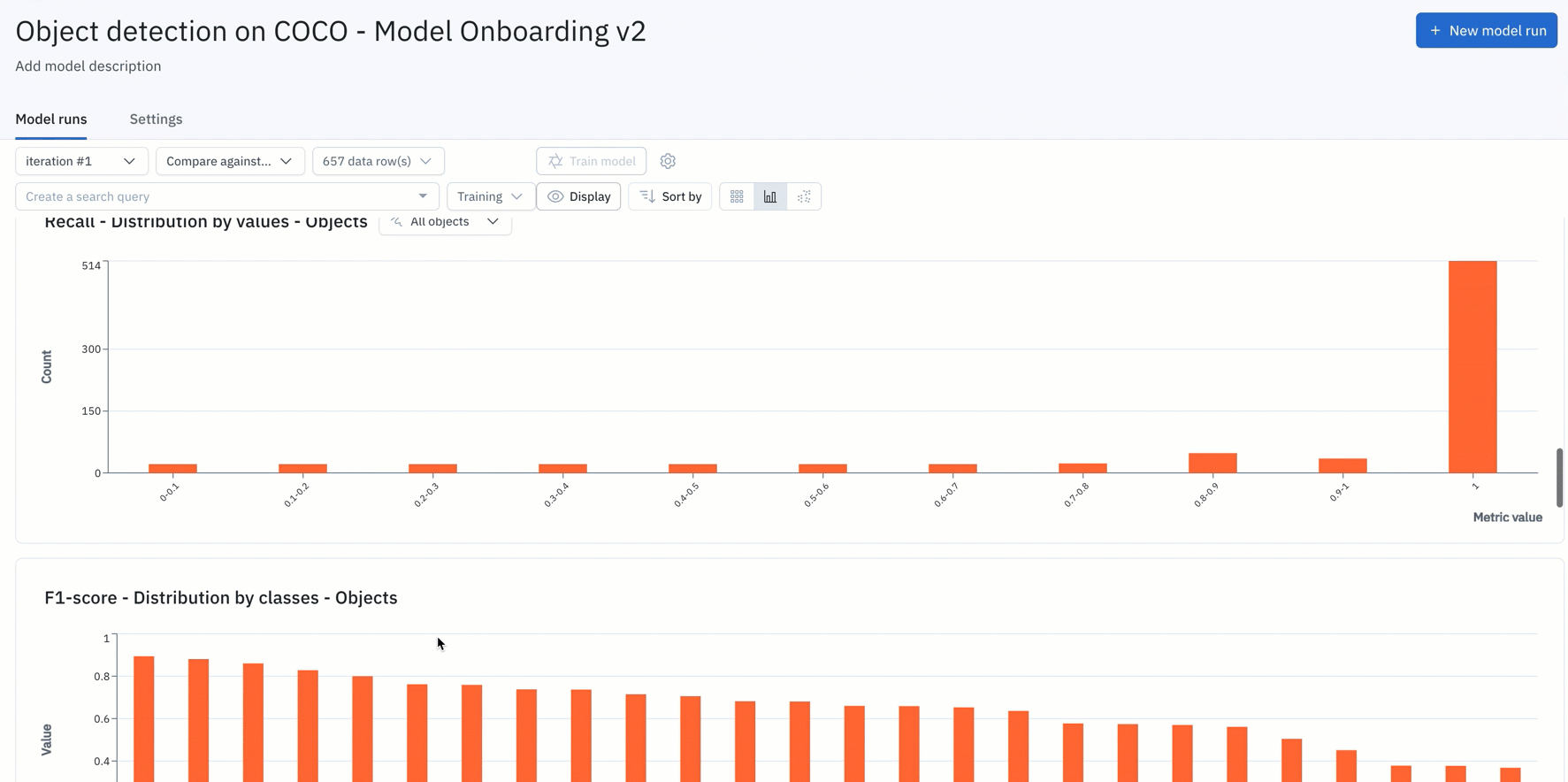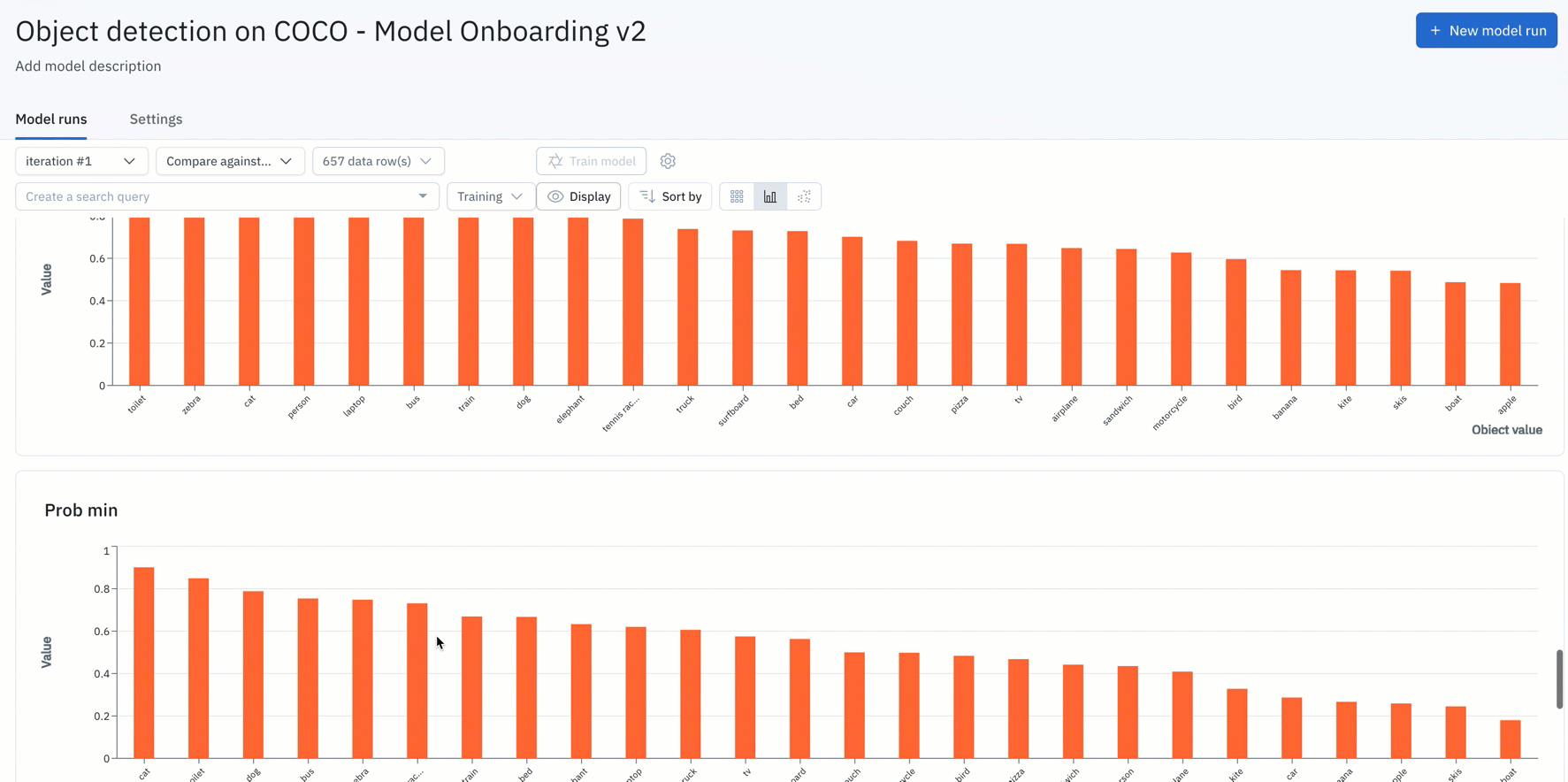
- You can simply upload your model predictions and ground truths to receive auto-generated metrics on model precision, recall, F1-score, TP/TN/FP/FN, and confusion matrix.
- If the auto-generated metrics aren’t sufficient for your use case, you can upload your own custom metrics as well.
- Visualize, filter, sort, and drill into your metrics, confidence scores, predictions, and annotations. This allows you to easily surface mispredictions, mislabeled data, and allows you to quickly identify improvements to your training data.
- You can interact and click into the NxN confusion matrix or click into the IOU / Precision / Recall histograms to surface and view specific data rows in “gallery view.” For instance, you can understand where your model is not performing well, where your labels are off, or where your model is the least confident.
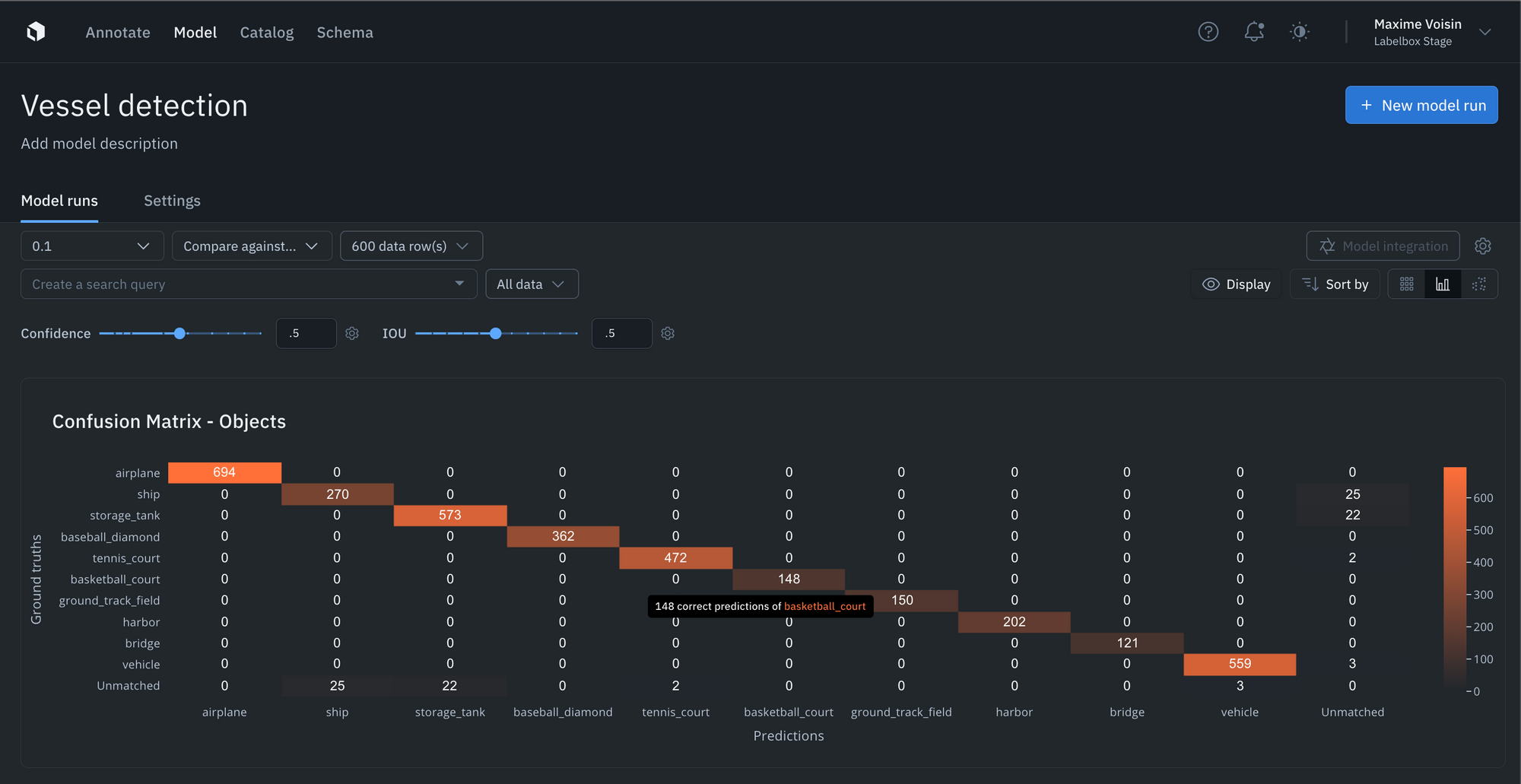
- Upload confidence scores alongside every prediction and tune the confidence and IOU thresholds in the Labelbox Model UI to see how model metrics change as the thresholds change.
Find the distribution of annotations and predictions in every model run via histograms
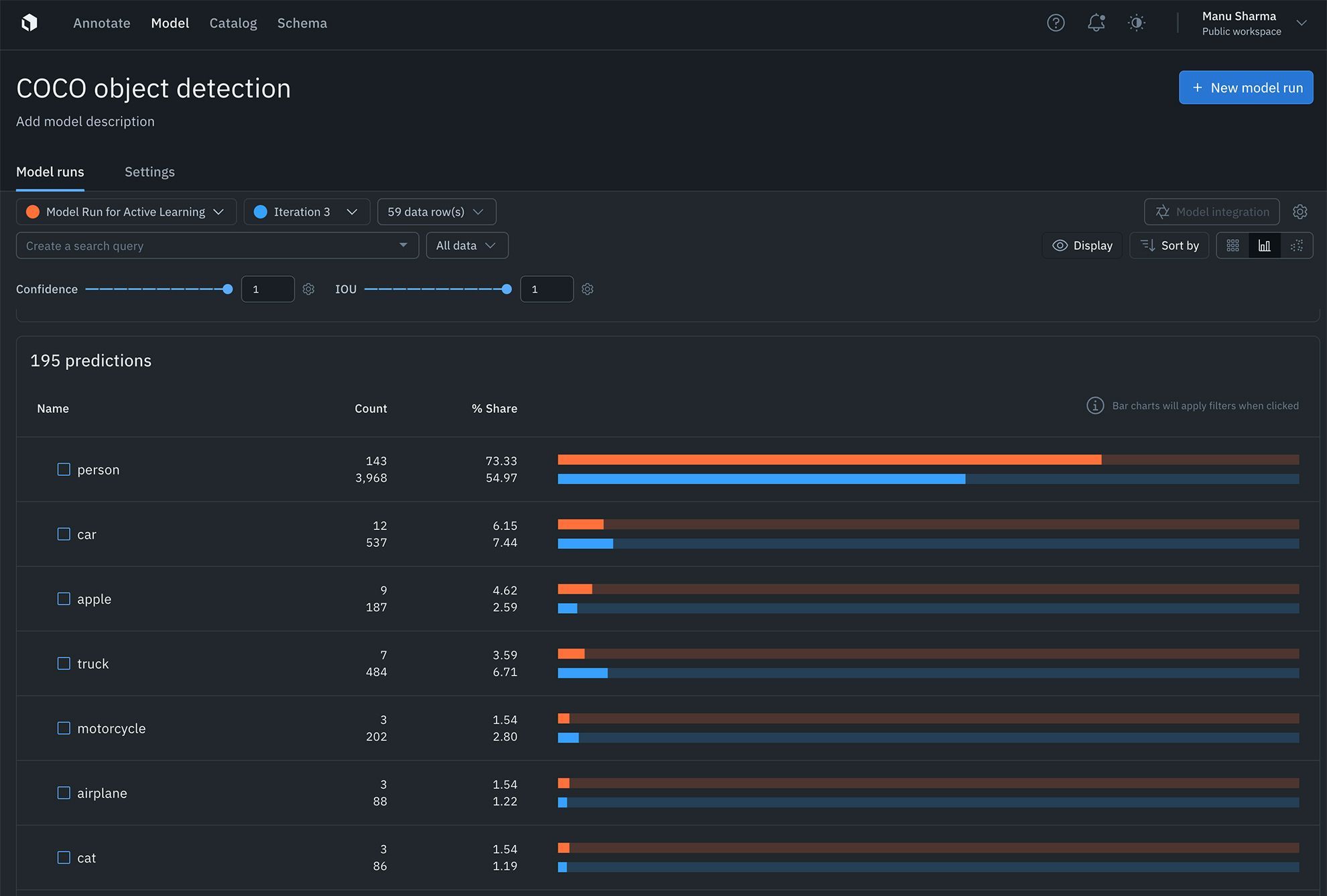
In addition, you can easily understand the distribution of your annotations and predictions via histograms. This makes curating datasets for labeling and analyzing model performance easier than ever. You can now use distributions to find the most predicted or least-predicted class and surface classes represented in training data, but rarely predicted by the model.
Labelbox leaderboards: A new era of evaluation for generative AI
In the rapidly evolving landscape of artificial intelligence, traditional benchmarks are no longer sufficient to capture the full capabilities of AI models. As AI grows increasingly complex, challenges like data contamination, overfitting to public benchmarks, scalability issues, and the absence of standardized evaluation criteria necessitate a more advanced approach to model metrics.
The Labelbox leaderboards are the first to tackle these challenges by conducting structured evaluations on subjective AI model outputs using human experts and a scientific process that provides detailed feature-level metrics and multiple ratings. Leaderboards are available for Image Generation, Speech Generation, and Video Generation.
By combining expert human evaluations with our Alignerr workforce, reliable methodology, and continuous updates, Labelbox is redefining AI evaluation. Our approach complements traditional leaderboards by offering a comprehensive and human-based assessment of AI models.
Read more about Labelbox leaderboards on our blog here.
Get started today
Labelbox offers a robust platform coupled with expert human evaluation services to efficiently generate and visualize these metrics, empowering you to make informed decisions and improve your models.
You can learn more about Labelbox auto-metrics in our documentation or by reviewing how to upload image predictions in Labelbox.
If you're interested in implementing this evaluation approach or leveraging Labelbox's tools for your model evaluation, sign up for a free Labelbox account to try it out, or contact us to learn more.


