
 All guides
All guidesLeveraging YOLO and Labelbox to make videos queryable by content

Video data can offer a wealth of information for AI use cases, but because of their dense and dynamic nature, manually extracting insights can be a tedious task. To accelerate this process, leading AI teams often use off-the-shelf, pre-trained models like YOLO (short for You Only Look Once) to take a quick first pass at detecting the contents of a video dataset.
YOLO is a real-time object detection model. Unlike traditional models, which scan an image multiple times at different scales, YOLO looks at the entire image only once, making it particularly well-suited for video object detection. It can detect various objects and provide a bounding box for each detected object. Using this model to enrich video data can make it easier for AI teams to understand their data.
However, the real magic lies in going a step further by organizing and categorizing this information, making the video content searchable. In this guide, we'll explore how to use YOLO and Labelbox Catalog together to make a dataset of unlabeled videos searchable.
How to make videos queryable
To make a video queryable, the first step is to run the YOLO model on the video to detect the objects in each frame. Once objects are detected, they are classified, and a bounding box is added to the objects in Labelbox. You can then search your video content based on these annotations with Catalog. Want to find all instances where a "bowl" appears in your video? Simply search for "bowl" in the Labelbox UI. Catalog will return all the videos that contain this annotation.
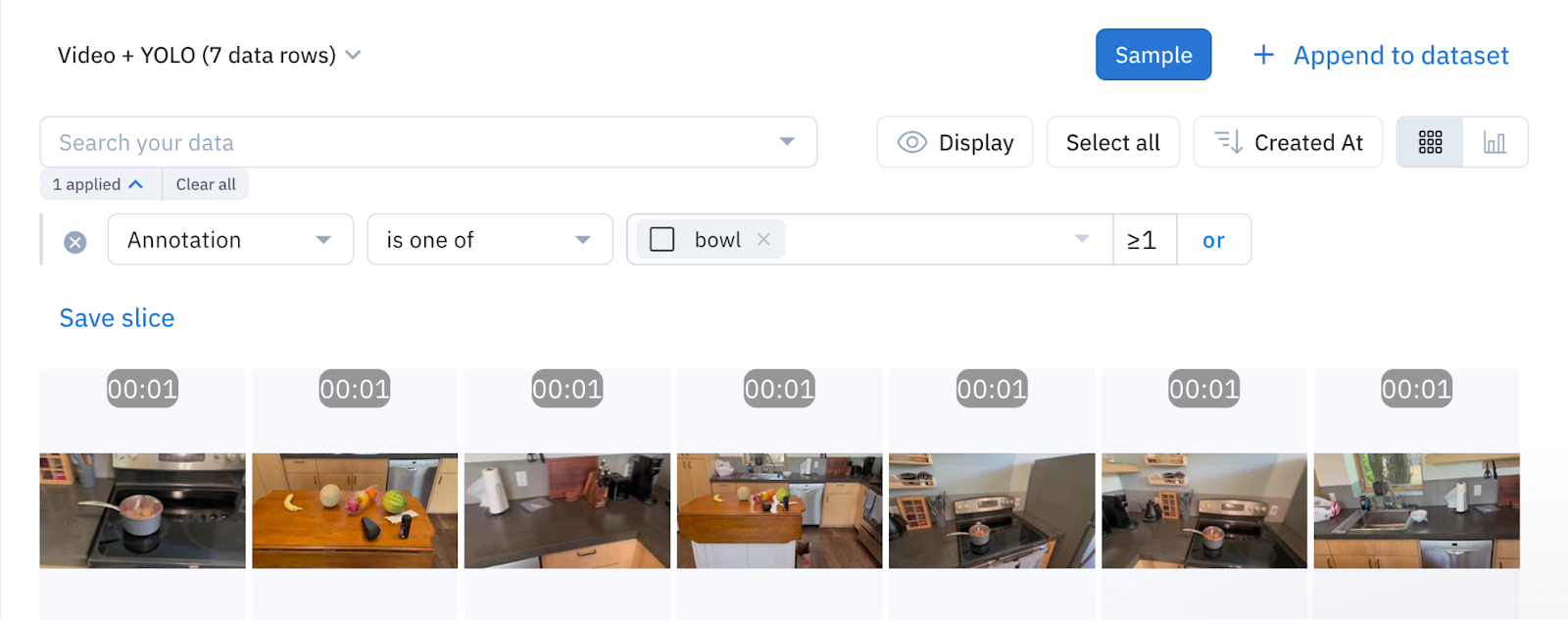
You can also create a custom workflow in Labelbox to create a bespoke review process, where you can create tasks that only have assets containing a specific annotation in the video, such as vehicles or other objects of interest. You can let YOLO take the first pass at labeling your video data, and then have human labelers review and/or add annotations in frames that contain specific objects of interest, reducing the time and costs required to label high-quality training data.
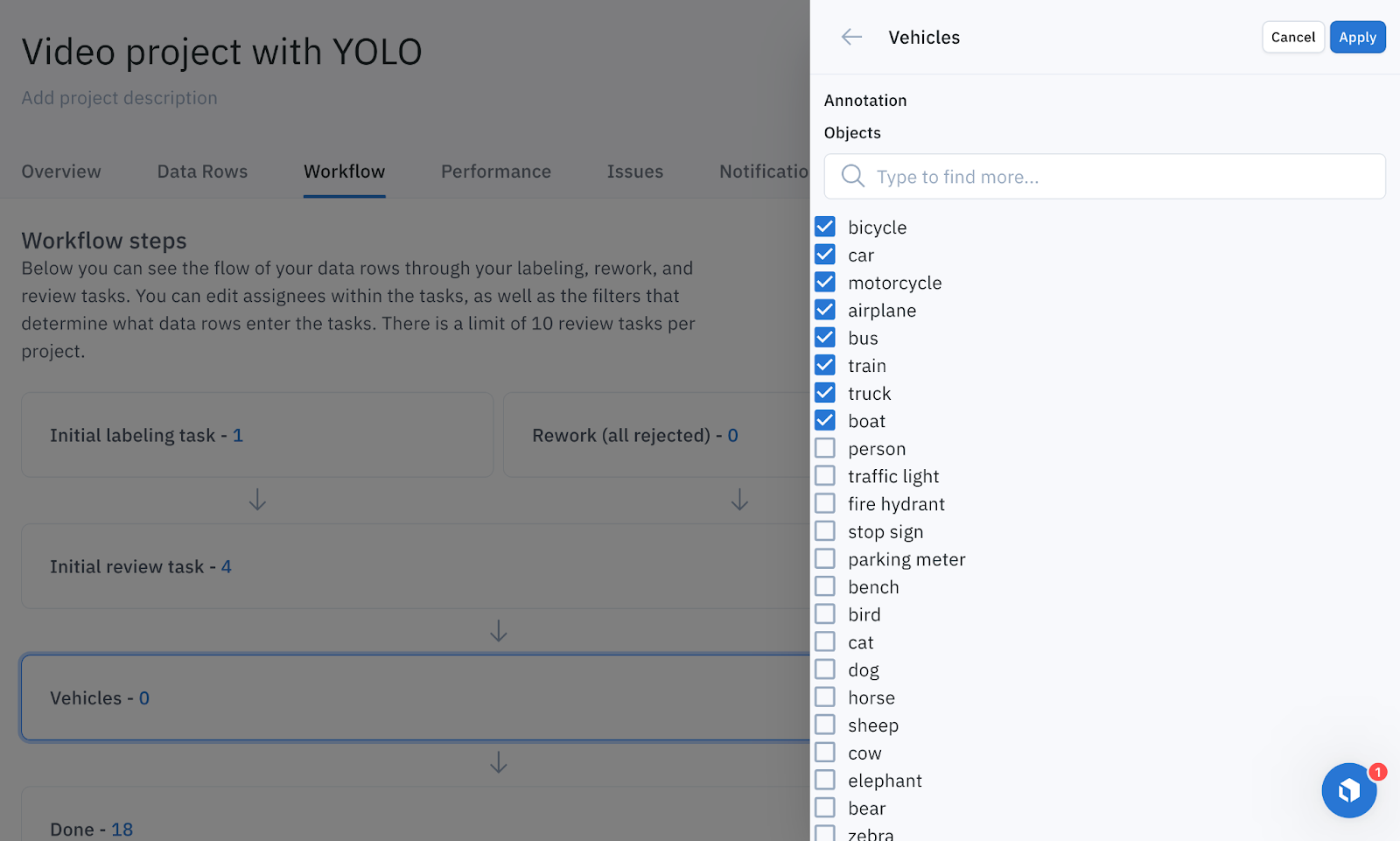
Read on for step-by-step instructions on using YOLO and Labelbox to make your videos queryable.
Part 1: Create project and ontology
project = client.create_project(name="Video project with YOLO",
media_type=lb.MediaType.Video)
#connect ontology to your project
project.setup_editor(ontology)Part 2: Queue assets to project based on global keys
batch = project.create_batch(
"first-batch-video"+str(uuid.uuid4()), # Each batch in a project must have a unique name
global_keys= global_keys, # A paginated collection of data row objects, a list of data rows or global keys
priority=5 # priority between 1(Highest) - 5(lowest)
)
print("Batch: ", batch)Part 3: Load YOLO model
model = YOLO(f'{HOME}/yolov8n.pt')Part 4: Create predictions and upload them to Labelbox
# Export queued data rows from the project
queued_data_rows = project.export_queued_data_rows()
# Initialize an empty list to store labels
labels = []
# Loop over each data row. Here, it's only looping over the first data row.
for data_row in queued_data_rows[:1]:
# Extract the URL of the video from the data row.
video_url = data_row["rowData"]
# Extract the global key from the data row.
global_key = data_row["globalKey"]
# Make a GET request to the video URL.
response = requests.get(video_url)
# Open a file in write-binary mode and write the content of the response to it.
# This is downloading the video and saving it as 'sample_video.mp4'.
with open('sample_video.mp4', 'wb') as f:
f.write(response.content)
# Create a VideoCapture object to read frames from the downloaded video.
cap = cv2.VideoCapture("sample_video.mp4")
# Set up the VideoWriter for the output video. The 'mp4v' argument specifies the codec to be used.
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# Initialize a counter for the frame number.
frame_number = 0
# Start a loop to read frames from the video.
while True:
# Read the next frame from the video.
ret, frame = cap.read()
# If the frame could not be read (i.e., we're at the end of the video), break the loop.
if not ret:
break
# Increment the frame number.
frame_number += 1
# Use the model to predict objects in the current frame. The confidence threshold is set to 0.5.
results = model.predict(frame, conf=0.50)
# Loop over each predicted class.
for c in results[0].boxes.cls:
# Loop over each bounding box predicted for the current class.
for idx, box in enumerate(results[0].boxes.xyxy):
# Get the class number from the model's class names.
class_number = model.names[int(c)]
# Get the coordinates of the bounding box.
xmin, ymin, xmax, ymax = float(box[0]), float(box[1]), float(box[2]), float(box[3])
# Create an annotation for the bounding box.
bbox_annotation = [
lb_types.VideoObjectAnnotation(
name = class_number,
keyframe= True,
frame=frame_number,
segment_index=0,
# Define the bounding box as a rectangle with a start and end point.
value = lb_types.Rectangle(
start=lb_types.Point(x=xmin, y=ymin), # x = left, y = top
end=lb_types.Point(x= xmax, y=ymax)))] # x= left + width , y = top + height
# Append a new Label object to the labels list. Each Label represents one detected object in one frame.
labels.append(
Label(
data=lb_types.VideoData(global_key=global_key),
annotations = bbox_annotation
)
)
# Release the VideoCapture object.
cap.release()
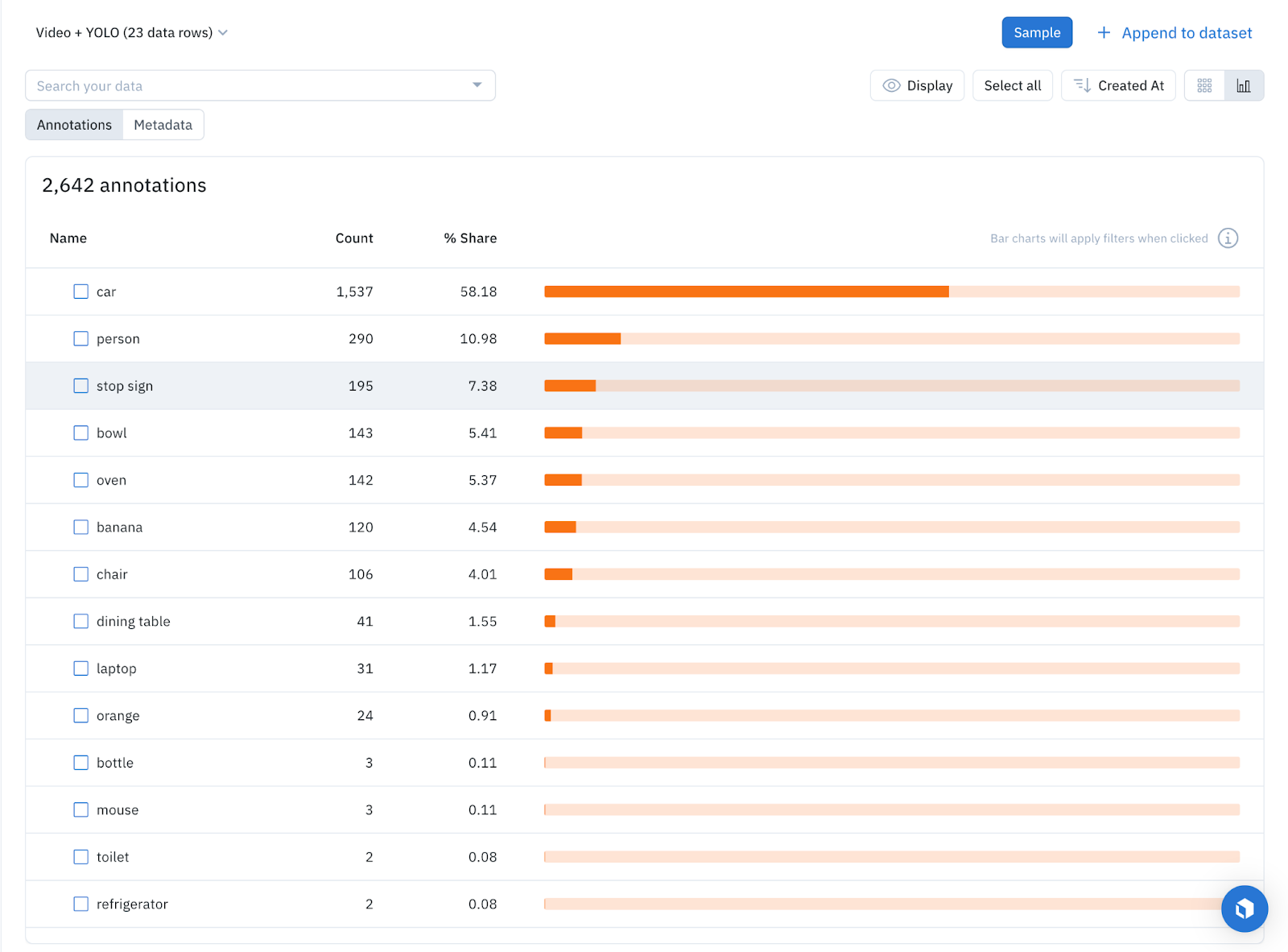
Conclusion
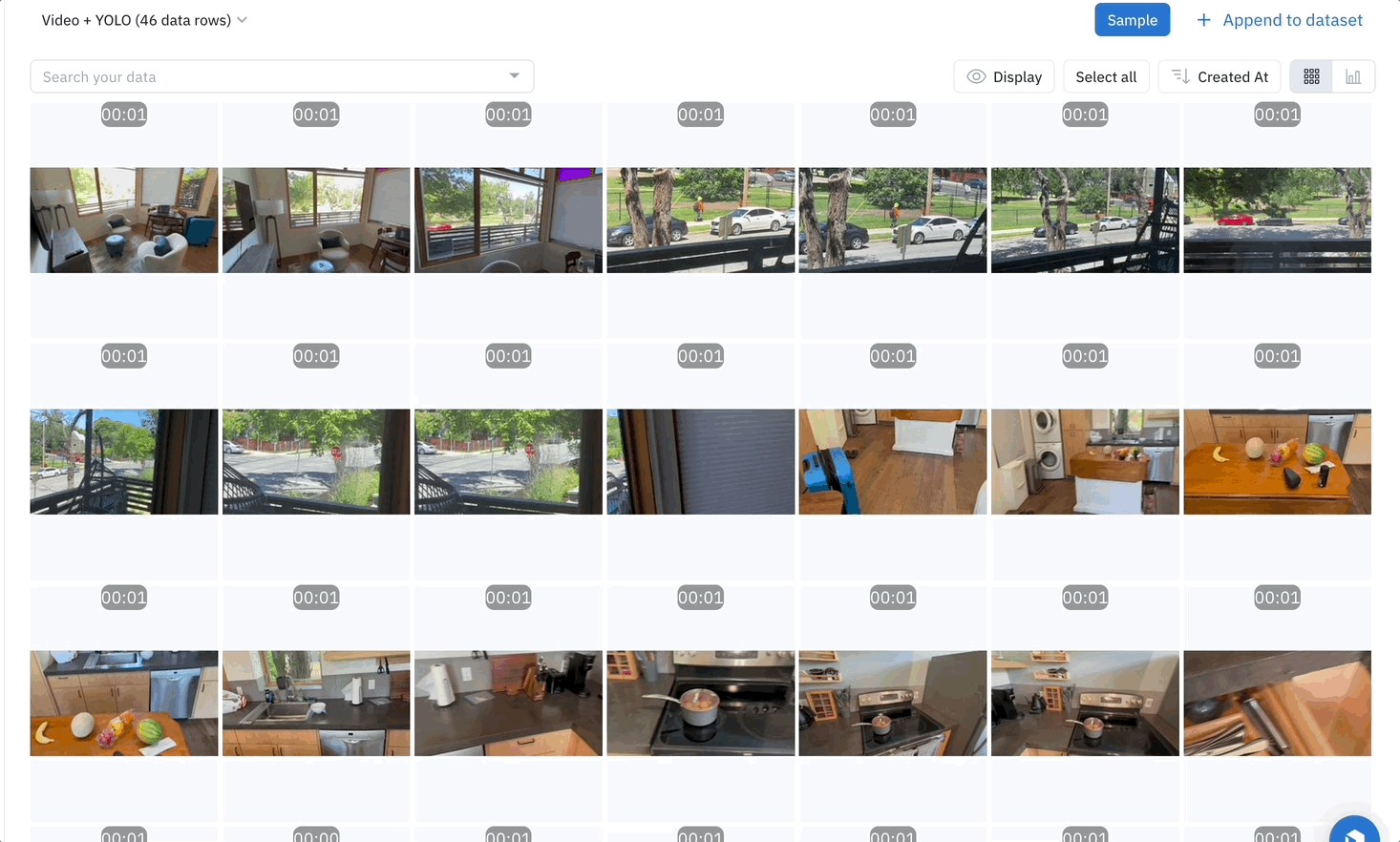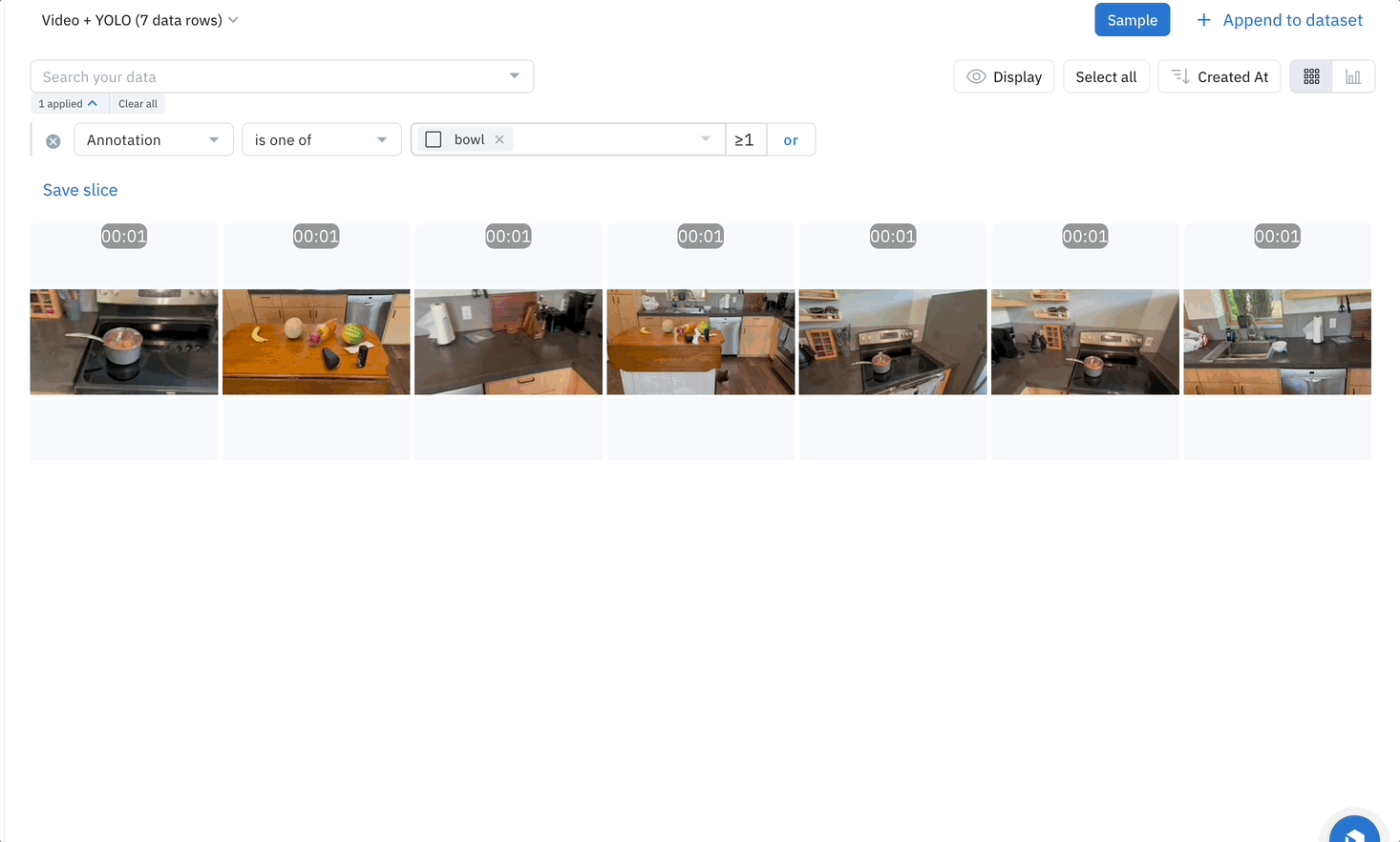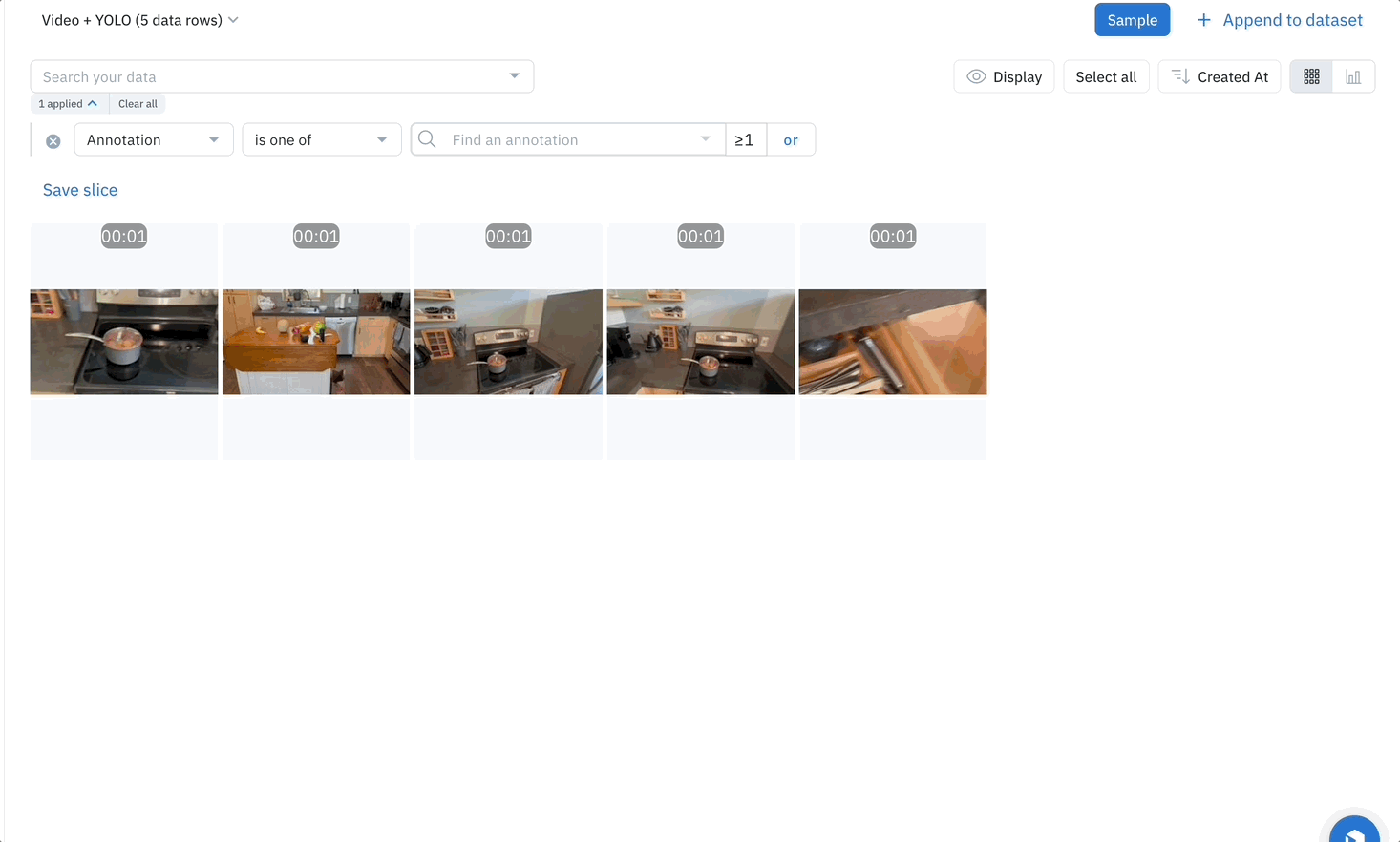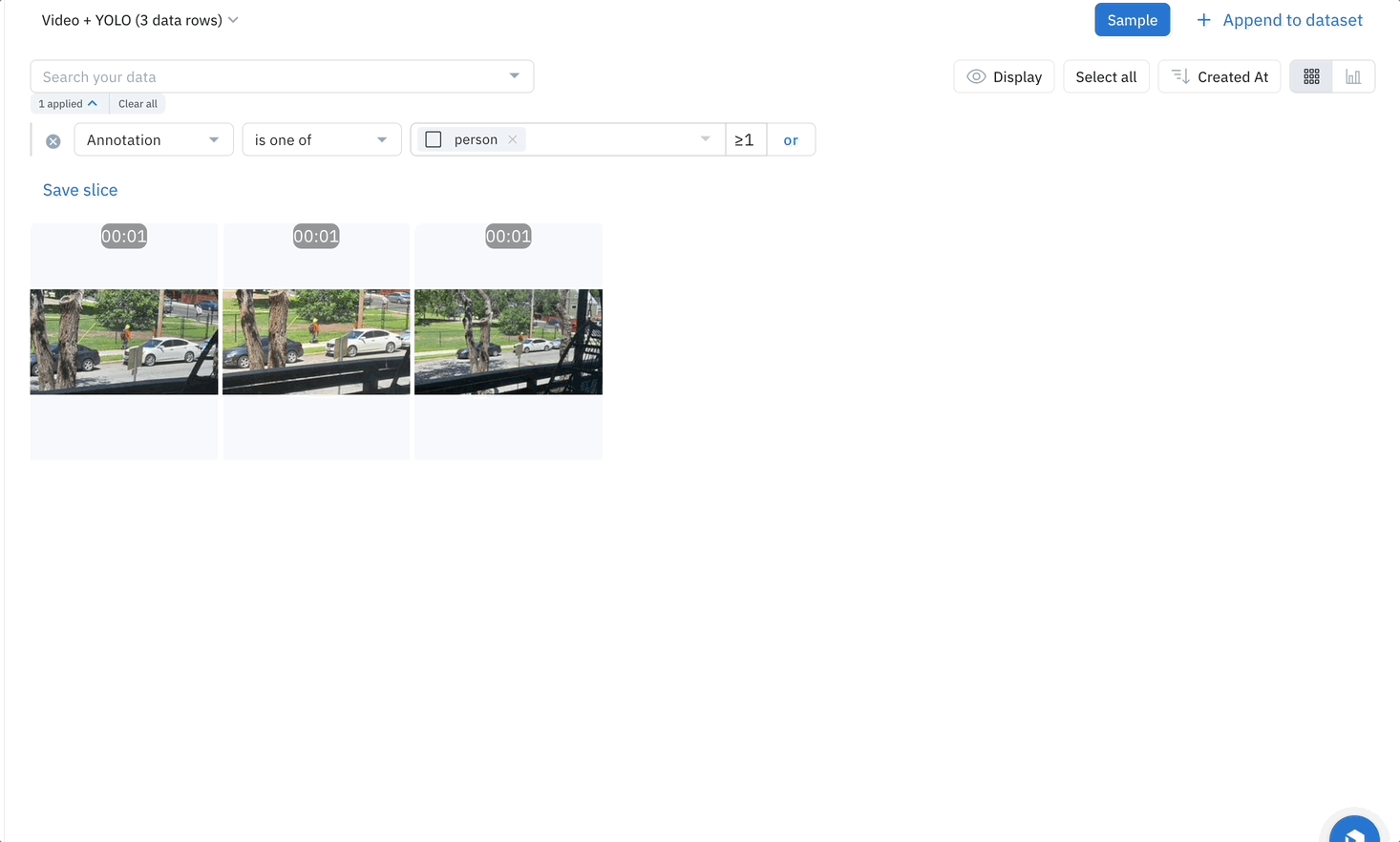
Combining the power of the YOLO — or any off-the-shelf AI model that suits your needs — with Labelbox opens up exciting possibilities for video content. It not only makes the video content queryable, but also helps bring a new level of understanding to what's inside the videos. This combination can be especially beneficial for use cases like surveillance, content creation, content moderation, and advertising, where insights from video content are crucial.
Using an AI model as a first pass enables users to search videos based on their content, enabling AI teams to learn how many annotations of each object exist within their dataset and what types of annotations the training dataset might lack. This further reduces friction when it comes to finding the next set of assets that will improve the model's performance by doing active learning. Try enriching your videos using YOLO or any other AI model using this script to discover exactly what content already exists in your troves of unstructured videos and find specific videos quickly and easily.


