
 All guides
All guidesUsing Meta’s Segment Anything (SAM) model with YOLOv8 to automatically classify masks

While YOLOv8 is no longer supported on Labelbox, this blog remains relevant if you are working with other object detection models. Alternatives such as OWL-ViT, Rekognition, GroundingDINO, and GroundingDINO + SAM are fully supported on the Labelbox platform.
In this guide, you will learn how to chain computer vision foundation models together to automatically populate pre-labels with class in Labelbox very quickly. We will be walking through a simple semantic segmentation task: drawing masks around all objects of a particular class in an image.
Leveraging chained foundation models in Labelbox will greatly reduce the time it takes you or your team to draw segmentation masks; by augmenting the recently-released SAM model with classifications, you will automate the task of assigning classes. Rather than performing a tedious labeling effort, you can focus your valuable efforts reviewing, verifying, and correcting labels drawn by AI models.
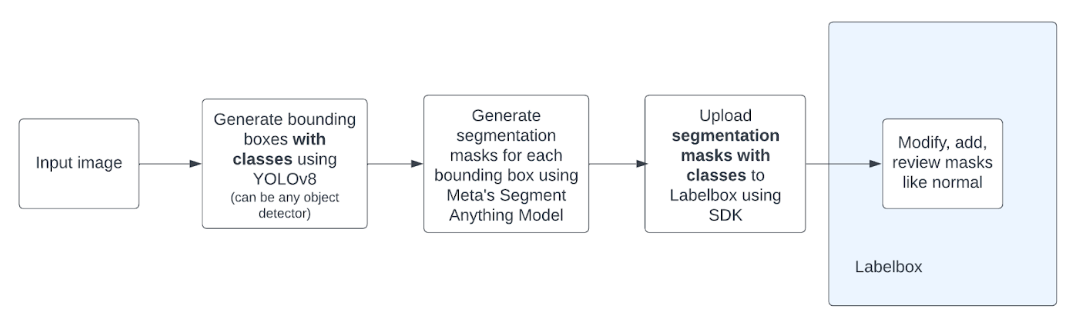
Here’s a high-level summary of the process that we will be walk through step-by-step below:
- Run an object detector on the image to generate bounding boxes with classifications for specified classes
- Feed the bounding boxes as inputs to Meta’s Segment Anything model which will produce segmentation masks for each one
- Upload the mask predictions onto Labelbox as pre-labels
- Open up image editor and review or modify the pre-labels as you usually do
You can run all of the above out-of-the-box on your image(s) using our Colab notebook. Simply load the images and automatically get segmented masks, with classes, in just a few minutes.
For this guide, we will use the following image of a lot of colorful chairs:

Step 1: Run YOLOv8 on the image
The latest iteration of the YOLO (You Only Look Once) family of models, YOLOv8 is an object detector that produces bounding boxes and classes around common objects. Known for its speed and accuracy, YOLOv8 boasts some impressive features – making it an invaluable tool for a wide range of applications. Here, we use YOLOv8 to automatically detect and localize all the chairs in the image.
# load the YOLOv8 model
model = YOLO(f'{HOME}/yolov8n.pt')
# run the model on the image
results = model.predict(source='chairs.jpg', conf=0.25)
predicted_boxes = results[0].boxes.xyxy
# read in the image for visualization
image_bgr = cv2.imread(IMAGE_PATH, cv2.IMREAD_COLOR)
# use cv2 to visualize the bounding boxes on the image
for box in predicted_boxes:
cv2.rectangle(image, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 255, 0), 2)
cv2.imshow("YOLOv8 predictions", image_bgr)
Step 2: Feed bounding boxes as inputs to Meta’s SAM model
SAM (Segment Anything Model) – recently released by Meta AI, is an advanced computer vision model designed to accurately segment images and videos into distinct objects. Using advanced deep learning techniques, SAM is able to identify and segment objects in images, making it a powerful tool for a wide range of applications. The SAM model is able to generate segmentation masks based on prompts, including bounding box prompts, which we will use in the code below.
To see an in-editor experience of SAM, please check out our blog post Auto-Segment 2.0 powered by Meta’s Segment Anything Model.
# load the SAM model
sam = sam_model_registry["vit_h"](checkpoint="/sam_vit_h_4b8939.pth
").to(device=torch.device('cuda:0'))
mask_predictor = SamPredictor(sam)
# transform the YOLOv8 predicted boxes to match input format expected by SAM model
transformed_boxes = mask_predictor.transform.apply_boxes_torch(predicted_boxes, image_bgr.shape[:2])
# run SAM model on all the boxes
mask_predictor.set_image(image_bgr)
masks, scores, logits = mask_predictor.predict_torch(
boxes = transformed_boxes,
multimask_output=False,
point_coords=None,
point_labels=None
)
# combine all masks into one for easy visualization
final_mask = None
for i in range(len(masks) - 1):
if final_mask is None:
final_mask = np.bitwise_or(masks[i][0], masks[i+1][0])
else:
final_mask = np.bitwise_or(final_mask, masks[i+1][0])
# visualize the predicted masks
plt.figure(figsize=(10, 10))
plt.imshow(image_rgb)
plt.imshow(final_mask, cmap='gray', alpha=0.7)
plt.show()
Step 3: Upload the predicted masks as pre-labels onto Labelbox
The predicted masks can be easily and seamlessly integrated into Labelbox via our SDK. The upload is just a few lines of code that run in less than a minute.
class_names = []
for c in results[0].boxes.cls:
class_names.append(model.names[int(c)])
annotations = []
for mask in masks:
# convert a 2D array to 3D array
mask_data = lb_types.MaskData.from_2D_arr(np.asarray(mask[0], dtype="uint8"))
mask_annotation = lb_types.ObjectAnnotation(
name = class_names[idx], # assign class from Step 1
value=lb_types.Mask(mask=mask_data, color=color),
)
annotations.append(mask_annotation)
labels = [
lb_types.Label(data=lb_types.ImageData(global_key="image_name"),annotations=annotations)
]
upload_job = lb.MALPredictionImport.create_from_objects(
client=client,
project_id=project.uid,
name="mal_job" + str(uuid.uuid4()),
predictions=labels
)
upload_job.wait_until_done()
print(f"Errors: {upload_job.errors}", )
print(f"Status of uploads: {upload_job.statuses}")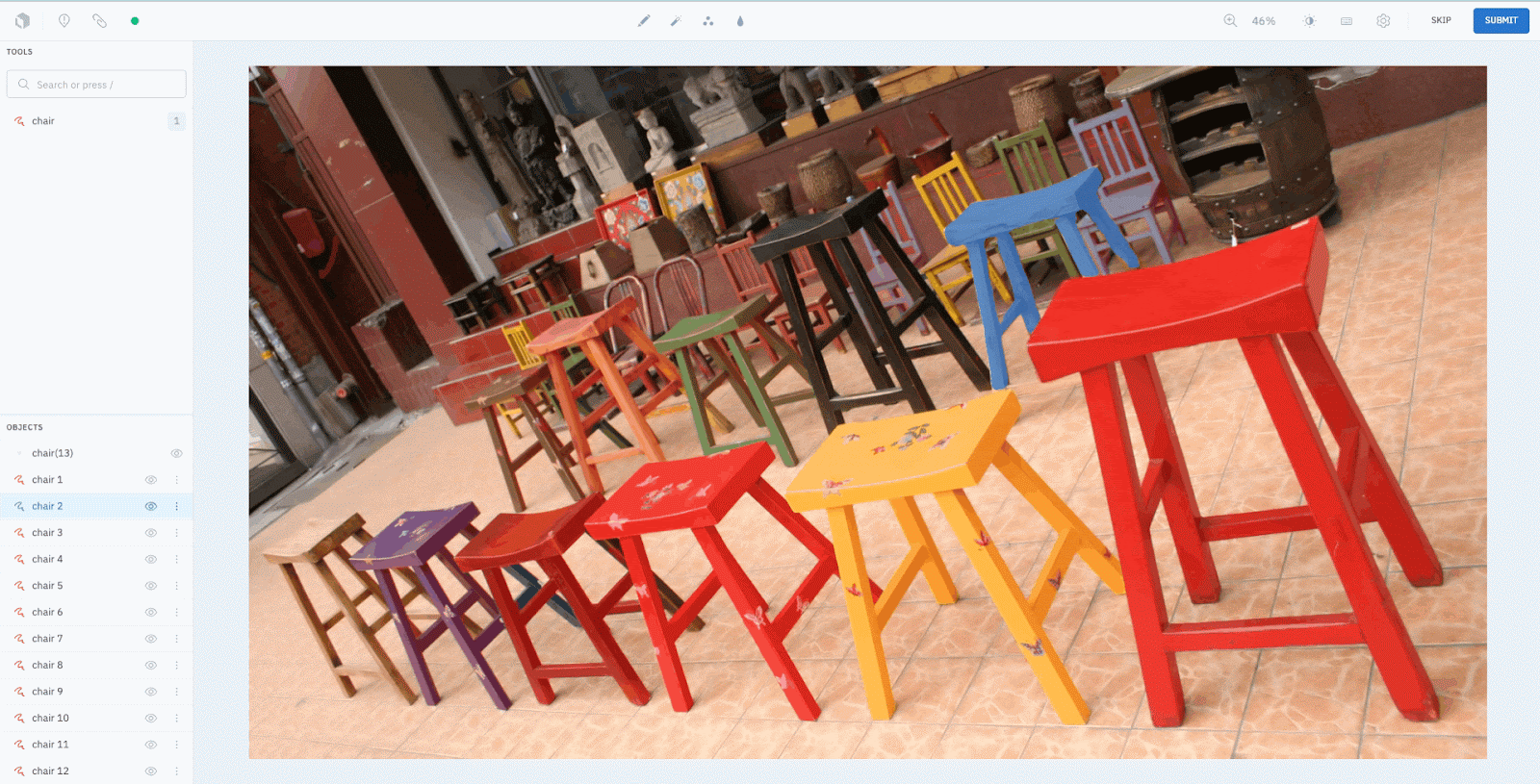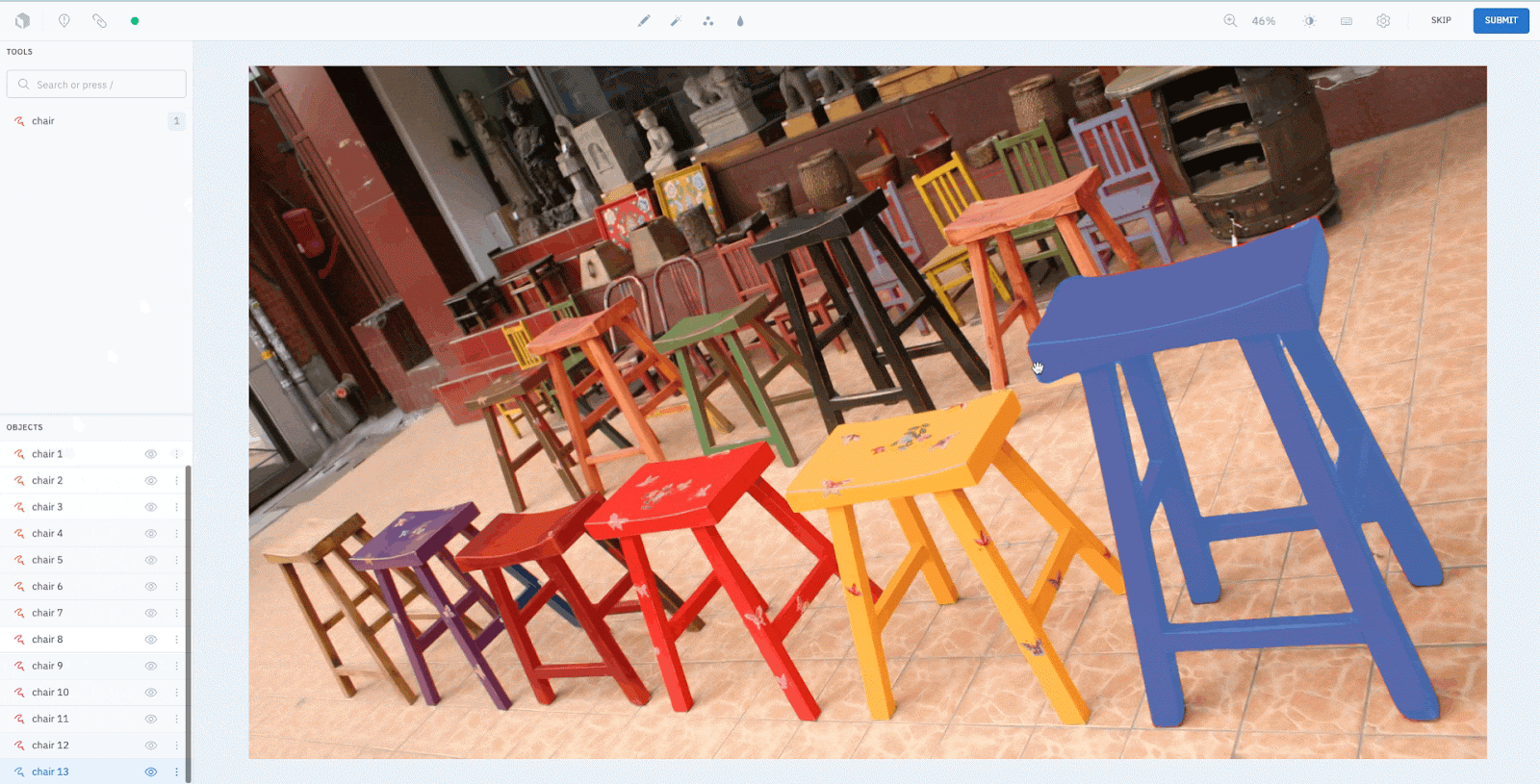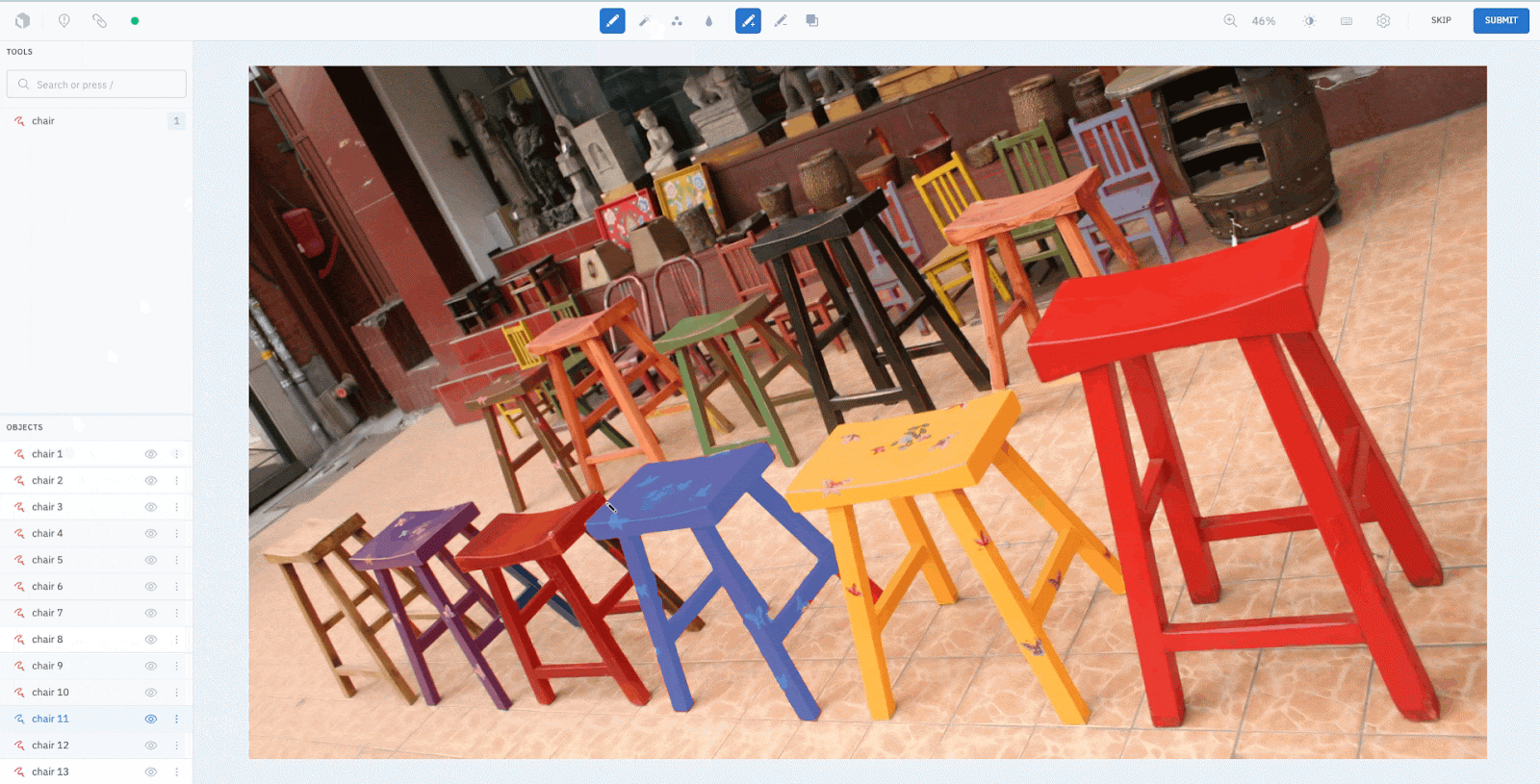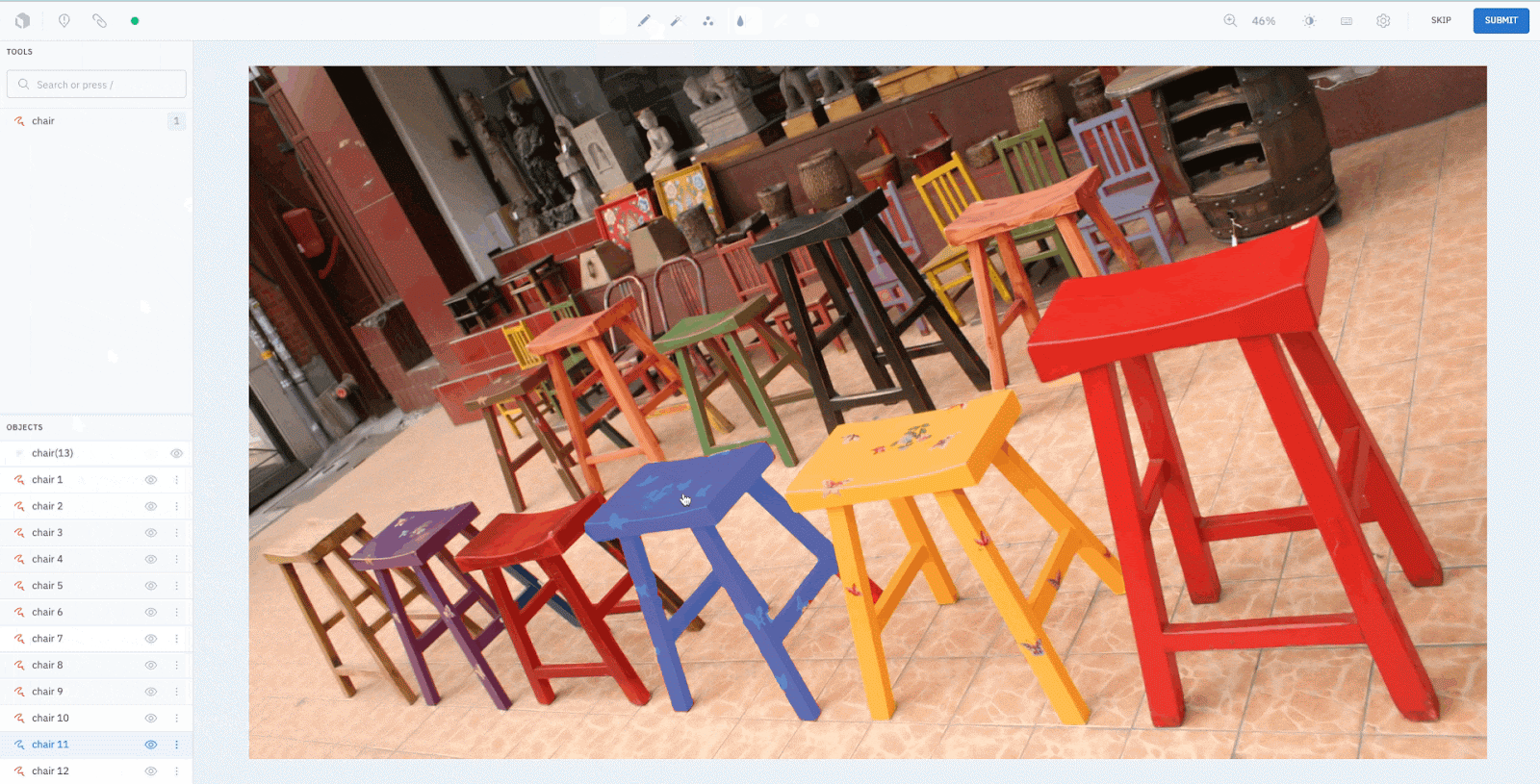
Final thoughts on using Meta’s SAM model with YOLOv8 to automatically classify masks
While Meta’s AI's SAM is really powerful at segmentation, it leaves out the crucial task of classification. In this guide, we demonstrated how you can use YOLOv8 (or another object detector) to generate bounding boxes with classes and then automatically apply those classes to the masks generated by SAM. We also showed how this seamlessly integrates with the Labelbox Model Assisted Labeling SDK.
If you are interested in applying SAM on images through our image editor, you can sign up for a Labelbox account and give it a try today.


