All posts
All postsDetecting feature requests of 3rd-party developers via machine learning: A case study of the SAP Community
Summary: Researchers from the Technical University of Munich, University of Innsbruck and SAP Deutschland set out to test whether the use of supervised machine learning models can be an effective means for the identification of feature requests.
Challenge: The elicitation of requirements is central for the development of successful software products. While traditional requirement elicitation techniques such as user interviews are highly labor-intensive, data-driven elicitation techniques promise enhanced scalability through the exploitation of new data sources like app store reviews or social media posts. For enterprise software vendors, requirements elicitation remains challenging because app store reviews are scarce and vendors have no direct access to users. The researchers investigated whether enterprise software vendors can elicit requirements from their sponsored developer communities through data-driven techniques.
The researchers wanted to analyze whether it is possible to automatically detect feature requests in the questions of community members through a binary machine learning classifier. The motivation for such a classifier is that sponsored developer communities typically contain millions of posts, but only a few are relevant for the elicitation of requirements.
The potential of sponsored developer communities for data-driven requirements elicitation is a promising source of information. While developers outside of the enterprise software domain often rely on autonomous developer communities such as Stack Overflow or Stack Exchange, enterprise software vendors typically nurture their own, self-hosted developer communities such as the SAP Community, Salesforce’s Trailblazer Community or ServiceNow’s Now Community
To answer their research question, they collected data from the SAP Community and generated a manually labeled data set of 1,500 questions. Following the design science paradigm, they developed a supervised and binary machine learning classifier. They observed the highest prediction accuracy (0.8187) for the classifier when they extracted features with the pre-trained SBERT-Model and classified them with the Naïve Bayes algorithm.
Findings: Following the design science methodology, the researchers collected data from the SAP Community and developed a supervised machine learning classifier, which automatically detected feature requests of third-party developers. Based on a manually labeled data set of 1,500 questions, their classifier reached a high accuracy of 0.819 and revealed that supervised machine learning models are an effective means for the identification of feature requests.
Their study opens up two major avenues for future research. First, while they used sponsored developer communities to mine enterprise software requirements, future research can explore the elicitation of bugs to improve the maintenance of software products. Second, future research can also explore different types of feature requests in sponsored developer communities.
How Labelbox was used: The researchers used Labelbox to collect the assessments from their labelers. They used a managed-labeler approach to label our final sample of 1,500 questions. A key reason for this approach was that the assessment of whether a question contains a feature request requires solid knowledge about SAP’s products and their functionality. Labelers needed to be SAP experts to make an accurate assessment. Additionally, they wanted to have three labelers so that they can rely on the majority label when the assessments are discordant. Labeler one is part of the researchers and has worked for their case company SAP for multiple years and in varying roles. Labeler two and three were recruited via the freelancer platform Fiverr. Both have a university degree and several years of experience with SAP’s technology.
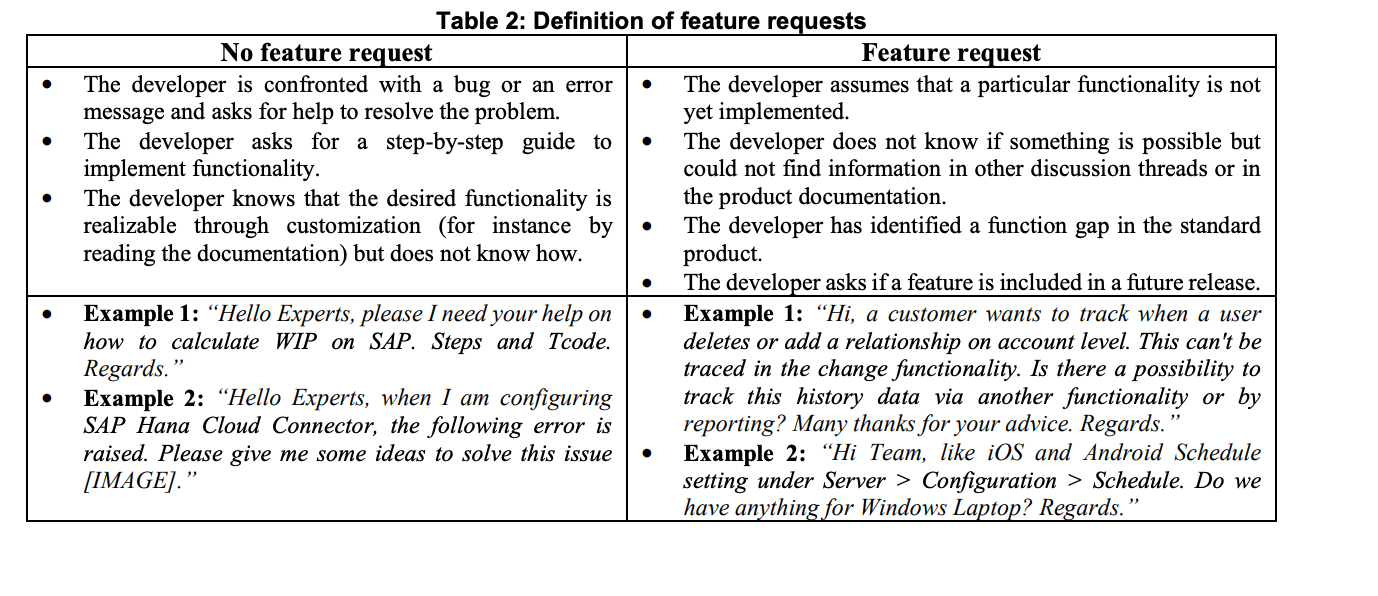
Moreover, the labeling task was a binary evaluation, meaning that our labelers were presented with a question and they had to assess whether the question contains a feature request or not. Existing answers and comments were not shown to the labelers as our goals was to train the classifier on the questions only. The inclusion of answers and comments
You can read the full PDF here.