×![]()

 All blog posts
All blog postsLabelbox•November 29, 2022
Leverage powerful embeddings to surface high-impact data in one click

You can now leverage new embeddings to more powerfully search and find high-impact data quickly. We've also made improvements to help you better upload and find data rows with a standardized asset import format and updates to global keys.
Instantly find similar data in one click
The most successful training datasets are carefully visualized, curated, and debugged to increase model performance at each iteration.
Machine learning (ML) teams mine data by looking for all examples of rare assets or edge cases that will dramatically improve model performance. Powerful similarity search capabilities can give your team an edge by helping find specific data points in an ocean of data. Building a similarity search engine that scales to hundreds of millions of data points and generates instant results is difficult for even the most advanced ML teams. To help teams find data easier and faster than ever, we’ve made major updates to our similarity search capabilities.
With similarity search, you can easily query and explore your unstructured data and develop a holistic understanding of your training data. Plus, it helps break down silos across datasets, so teams can focus on curating and labeling the data that will dramatically improve model performance.
Labelbox uses vector embeddings to power similarity search. Vector embeddings are a powerful way to represent, search, and explore your unlabeled and labeled data.
Labelbox automatically pre-computes embeddings for these data types:
We’ve made a host of improvements to our similarity search capabilities, allowing you to combine traditional search — on metadata, annotations, predictions, metrics, datasets, dates, etc. — with embedding-based similarity search to easily surface similar labeled and unlabeled data in one click.
To conduct a new similarity search query:
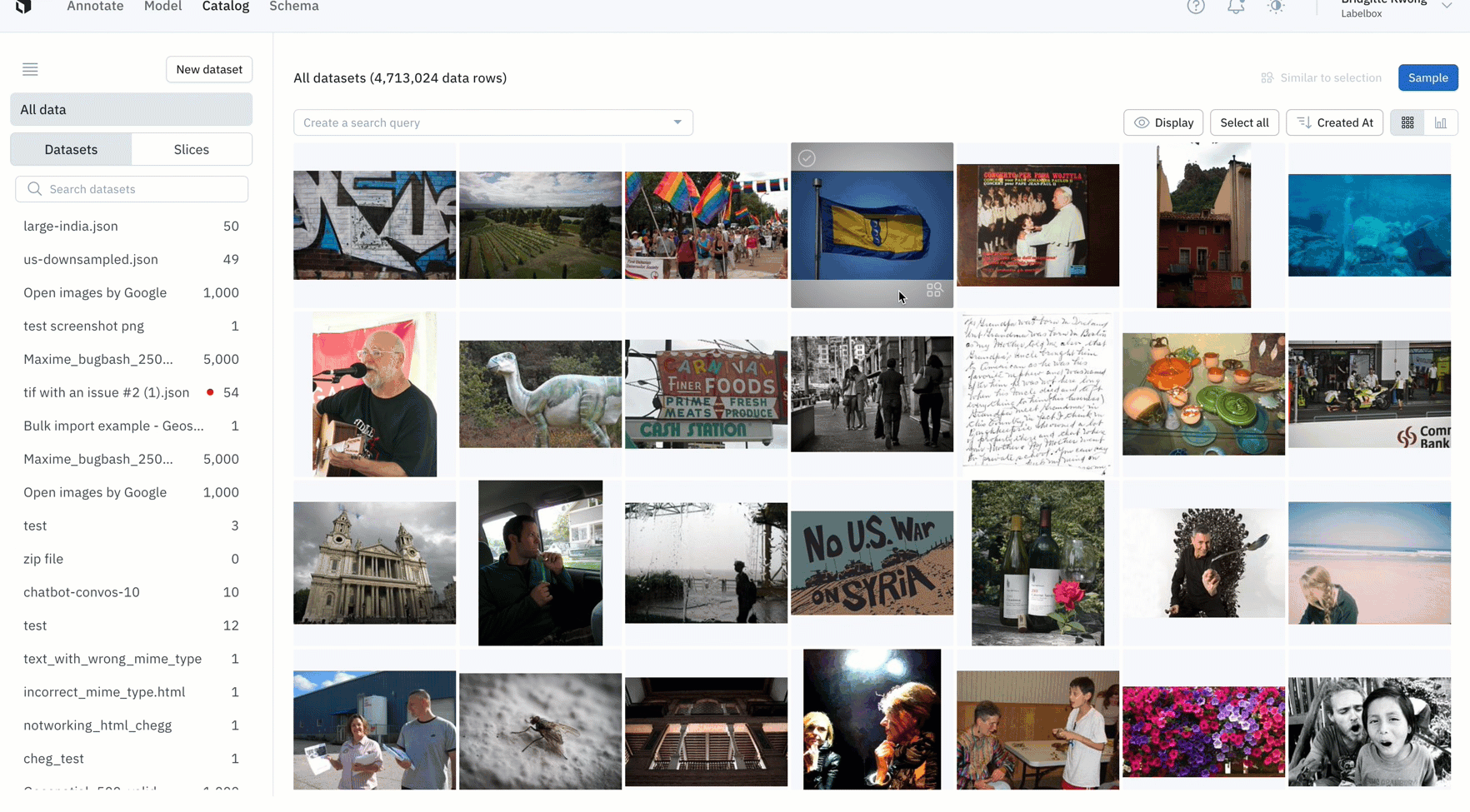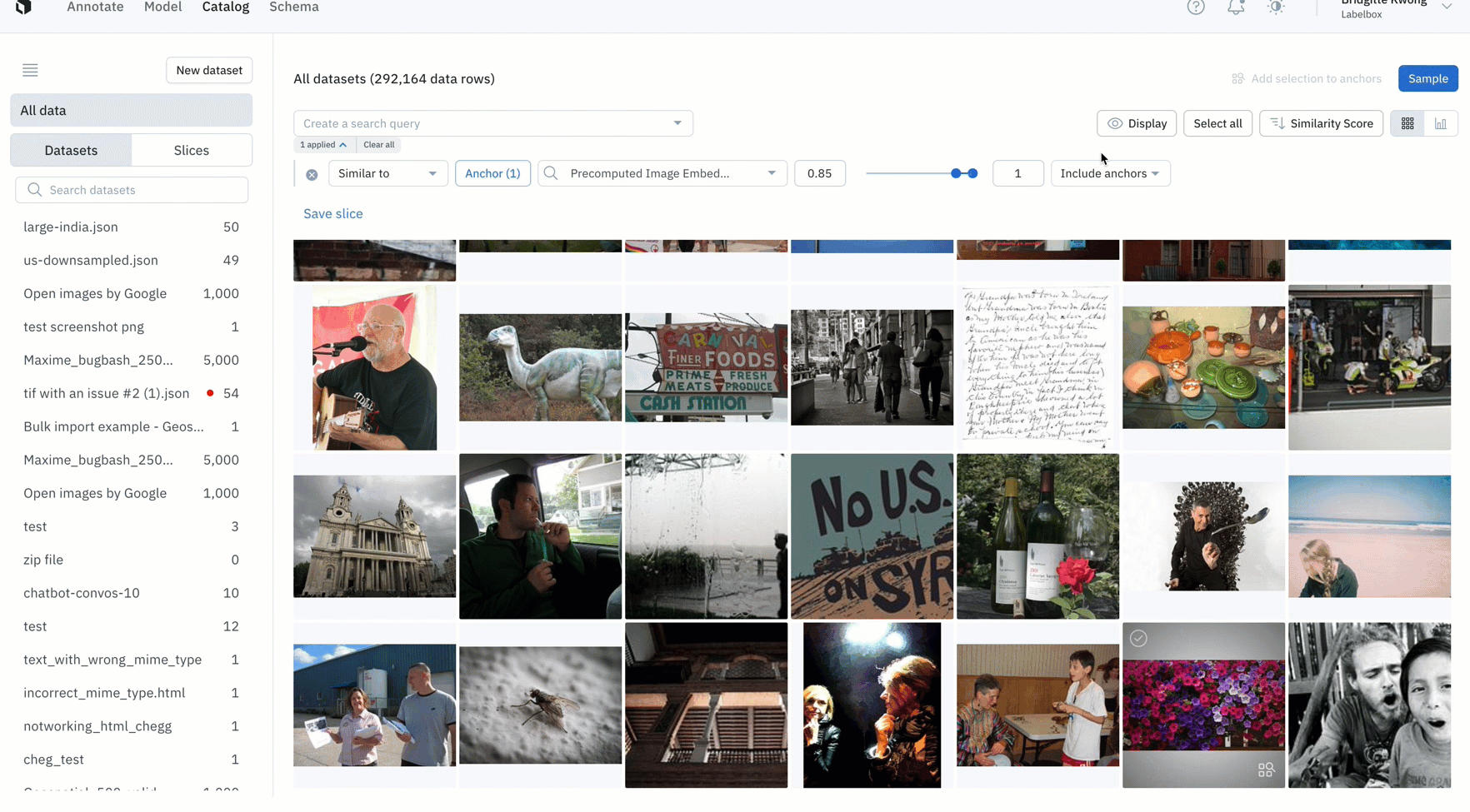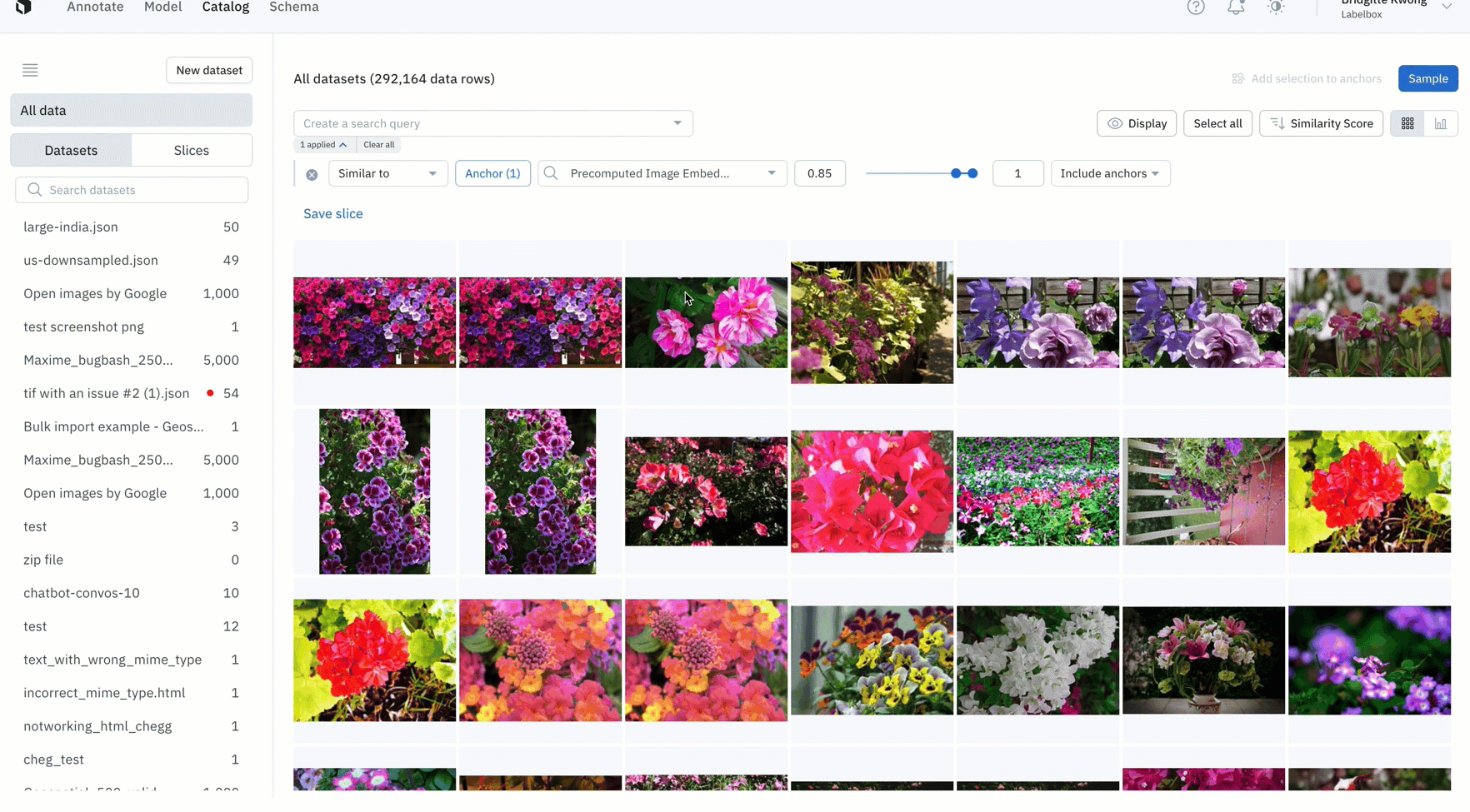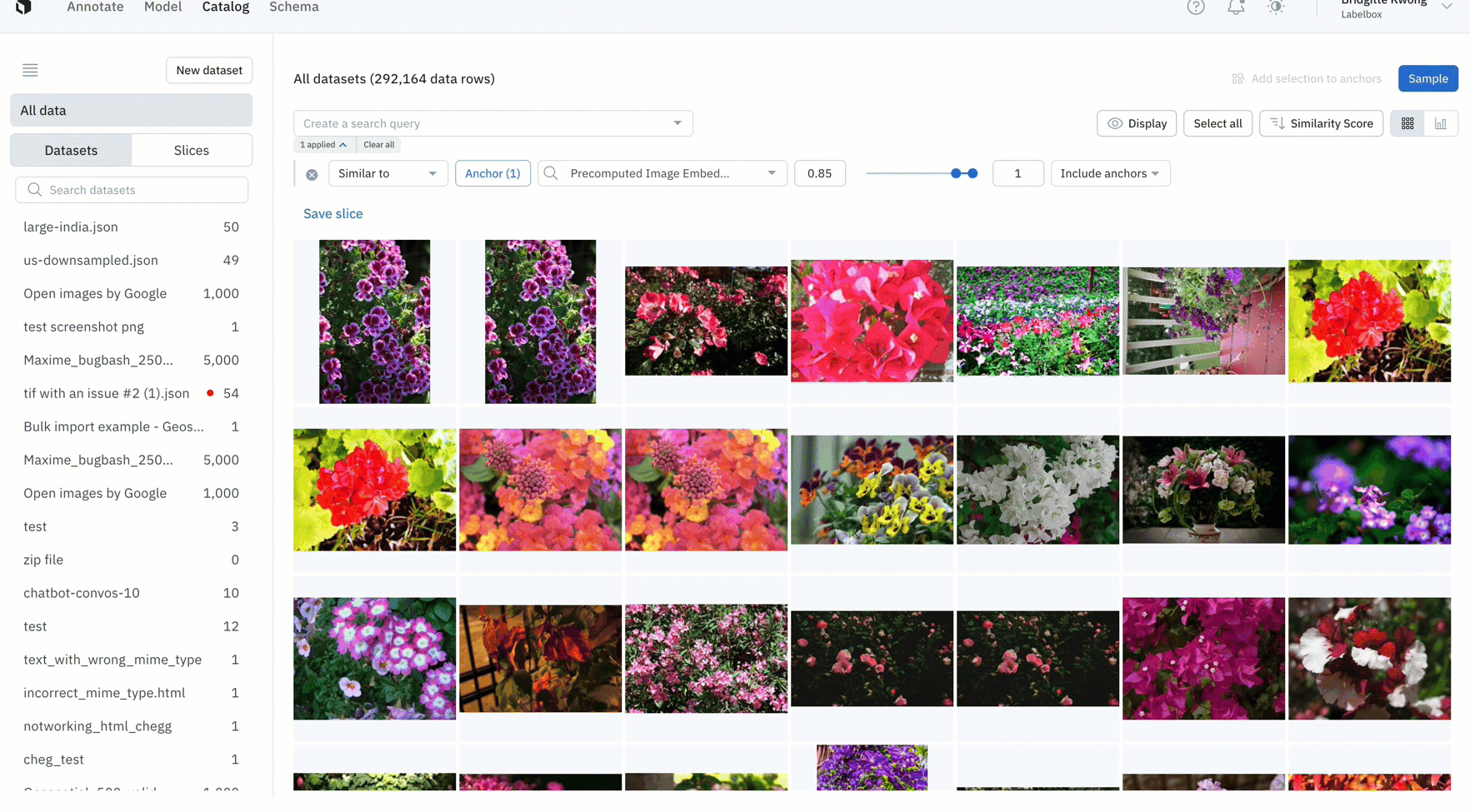
1) Hover and click on the bottom right icon of any data row OR select all data rows of interest and click "Similar to selection"
2) This will automatically surface similar data rows – you can select multiple data rows as anchors to refine your similarity search
3) Combine similarity search with other filters and save these searches as slices. This will allow you to revisit all current and incoming data rows that match the specific search criteria.
With a more powerful similarity search, larger embeddings, and the ability to save searches as slices, you can:
Explore, visualize, and understand your data in one click
- Before you train your ML model, you can explore all of your data in Labelbox Catalog
- In just a few clicks, you can surface all examples of data rows of interest, and either save them as a slice of data of interest, or send them to a labeling project as a batch
- In the example above, we can filter all images of a single flower from almost five million data rows in Labelbox Catalog with just one click
Quickly mine edge cases or rare examples
- After training your model, you might find an edge case where your model is struggling
- You can use similarity search in Labelbox Catalog to easily confirm whether this is a pattern of model failures, or simply a one-off mistake
- In the above example, the model appears to struggle with images with many flowers, so we can quickly mine edge cases to find all images containing many flowers
Find all labeling mistakes in your project and send them to re-labeling
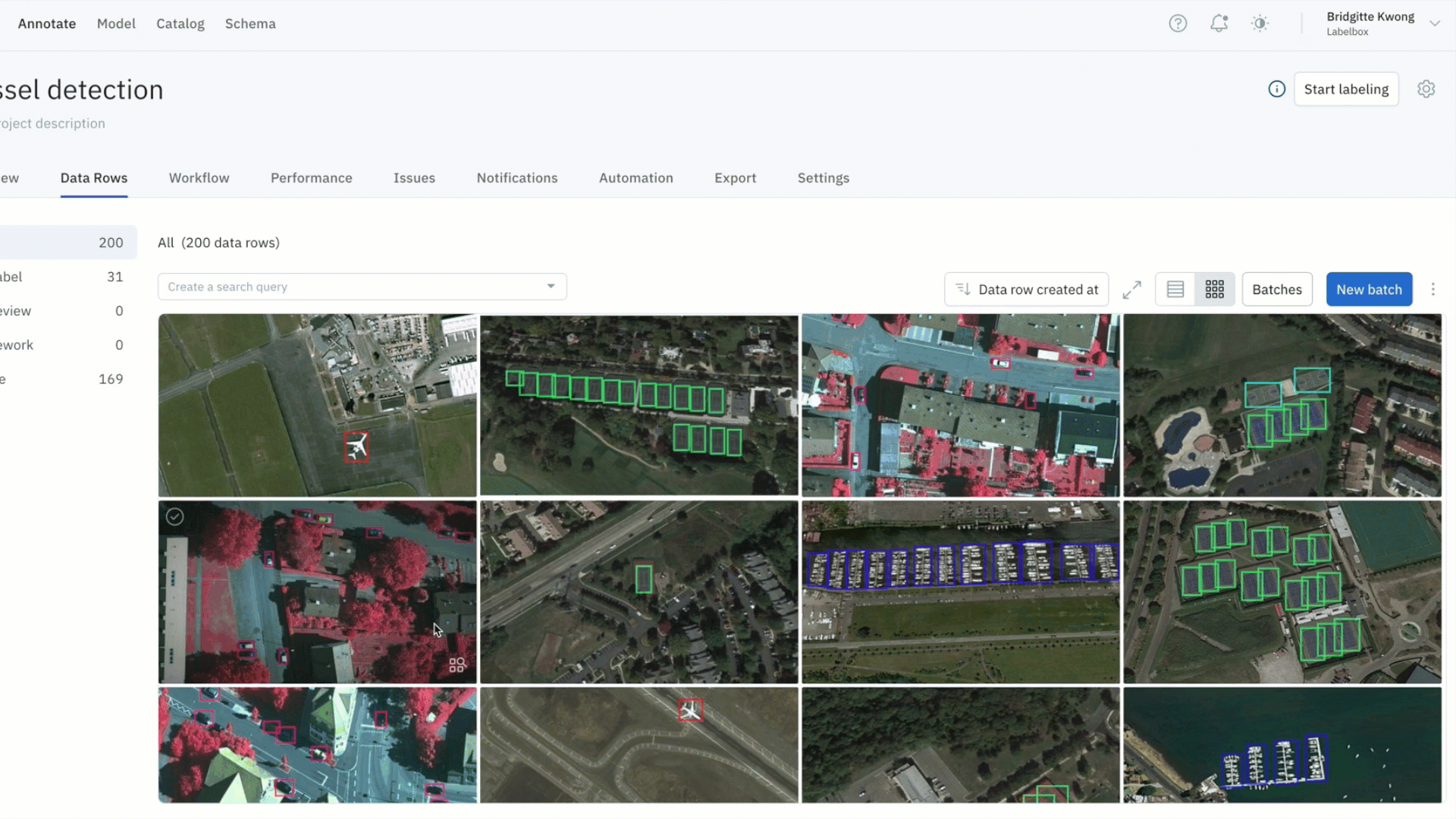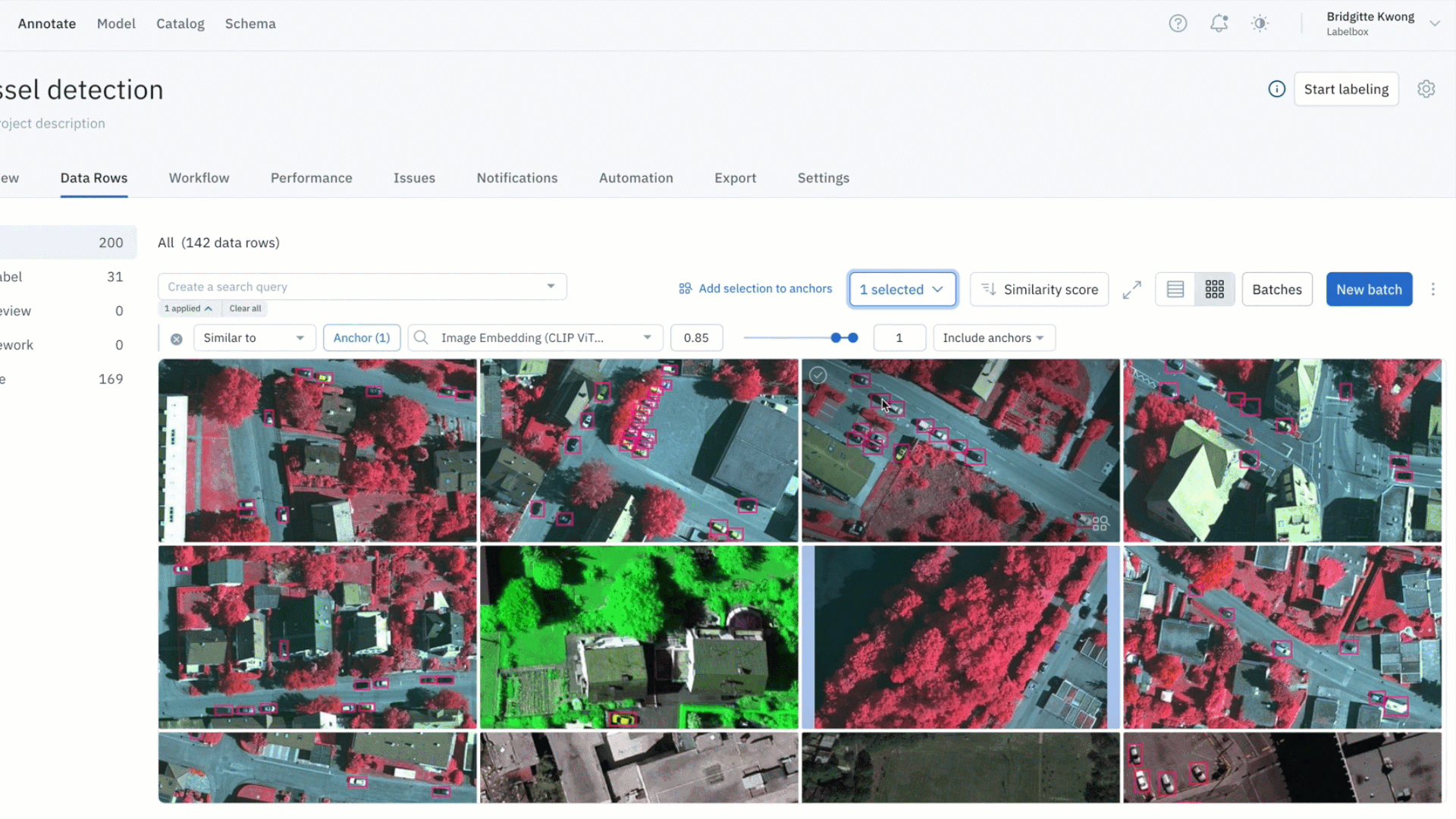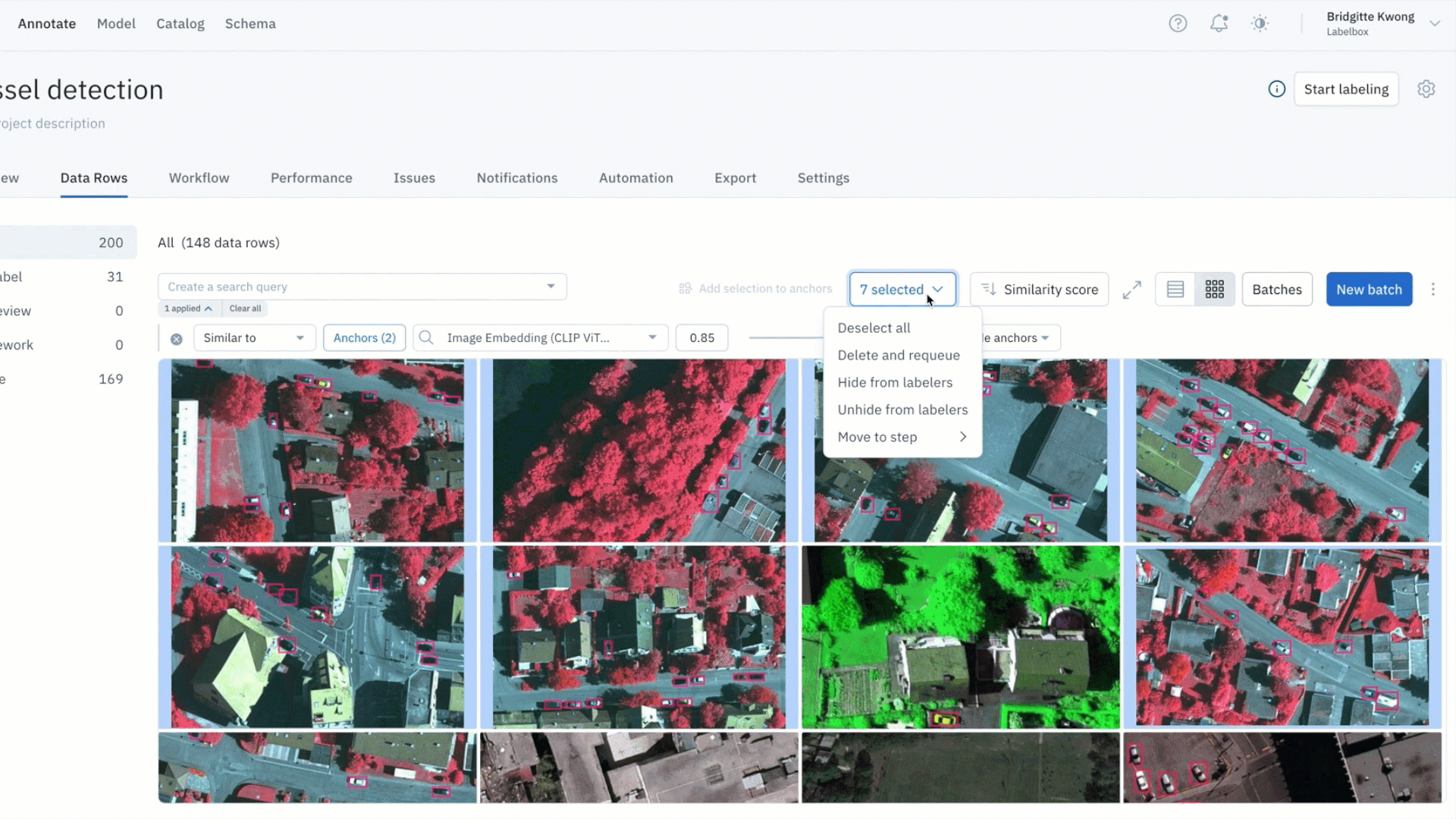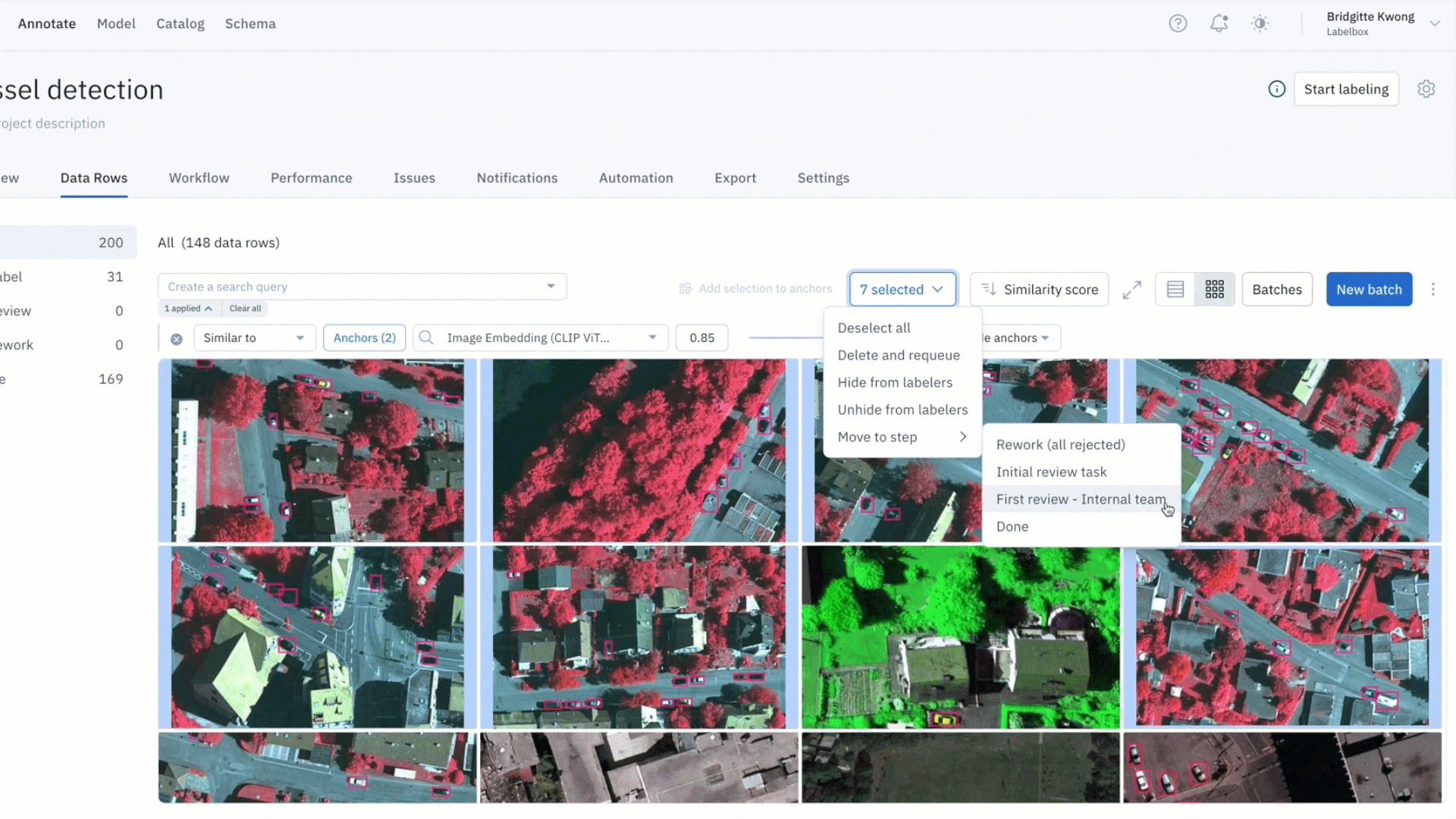
- Within a labeling project, you might identify data rows with problems – such as labeling quality issues or mislabeled data
- You can leverage similarity search to find all similar labeled data (which might contain labeling errors and need additional review) and submit them to a specific review step
Select even more high-impact data to label
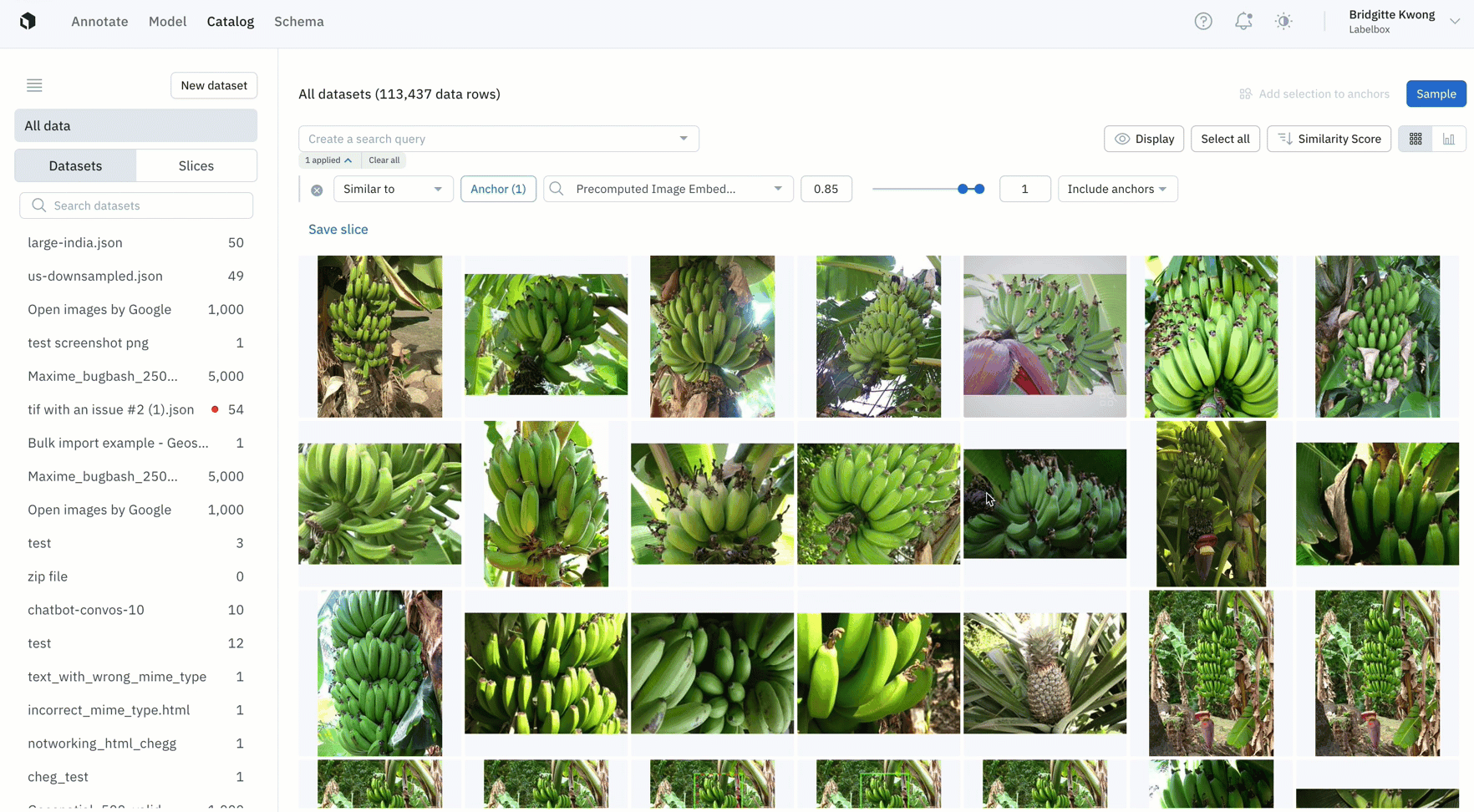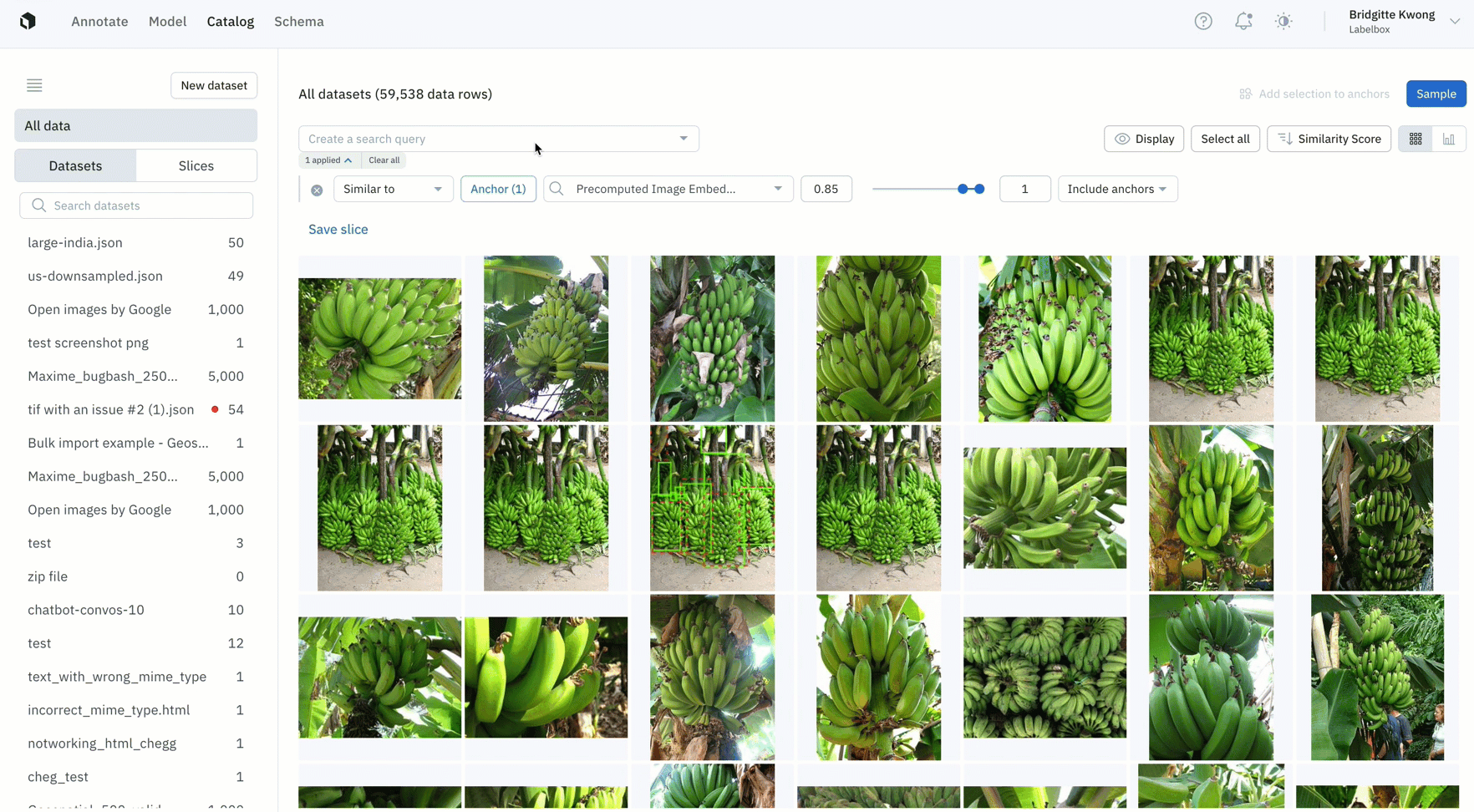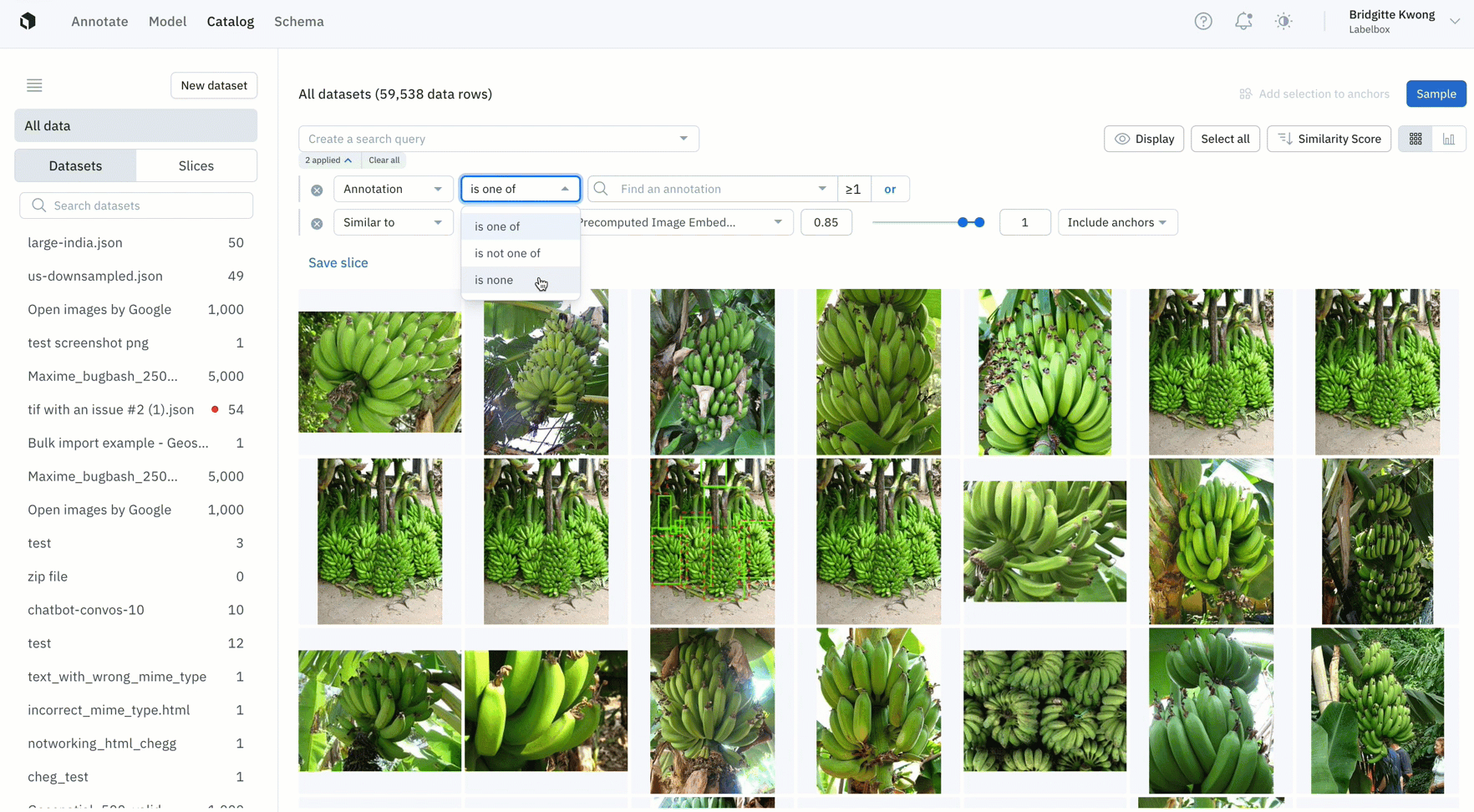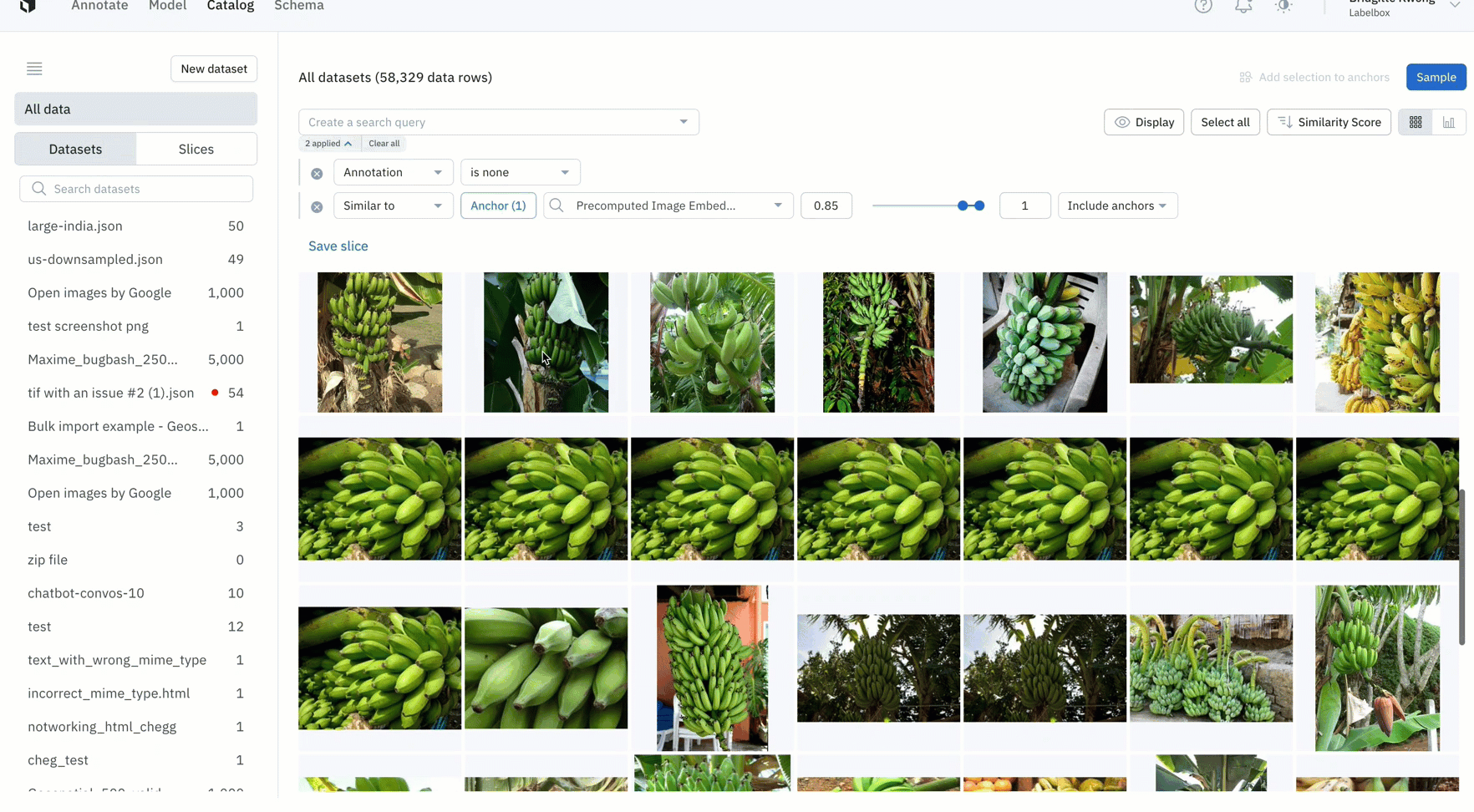
- Once you’ve identified data rows on which your model is struggling, you can find all similar unlabeled data in your datasets, label that data, and retrain the model to improve performance
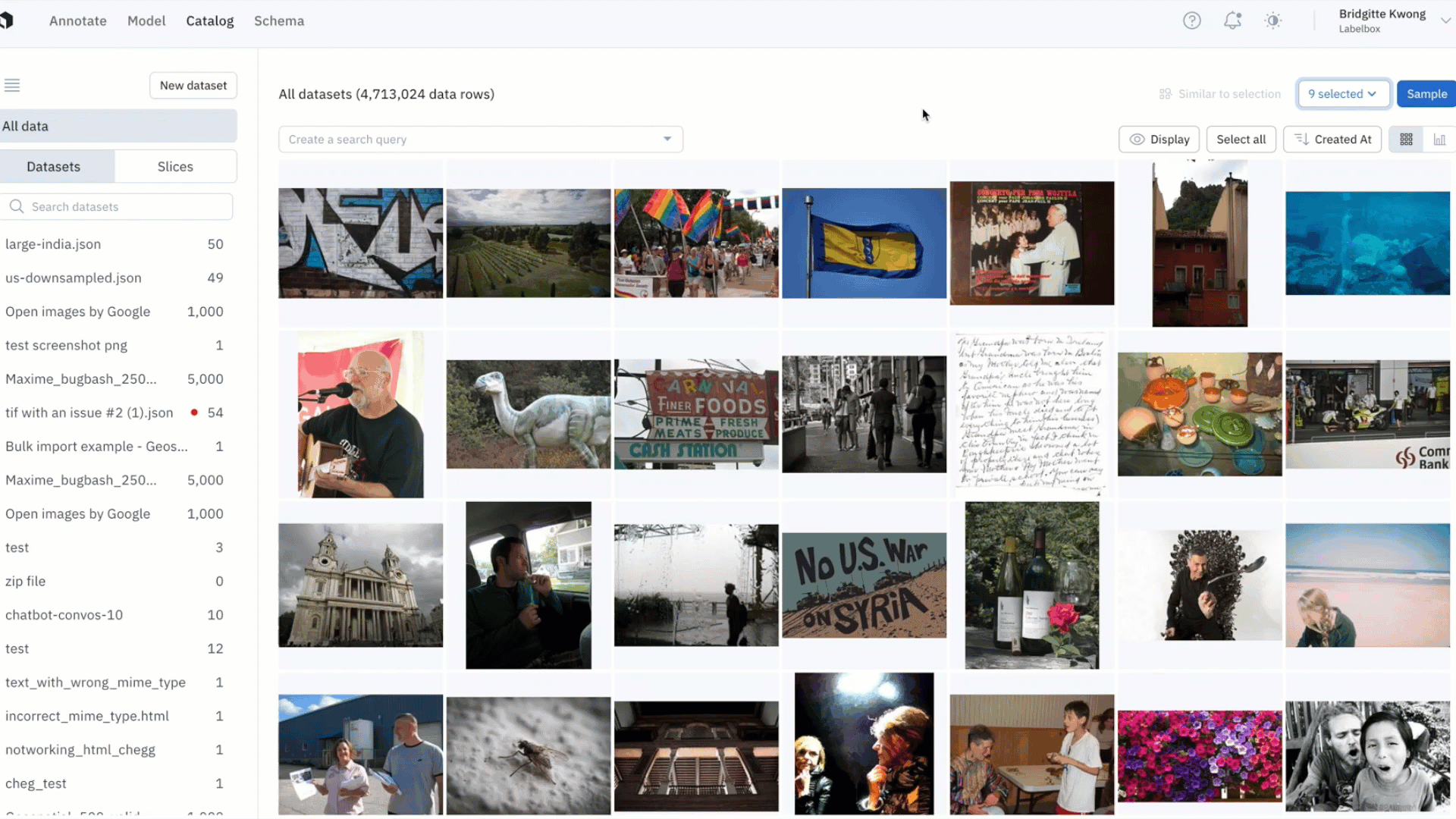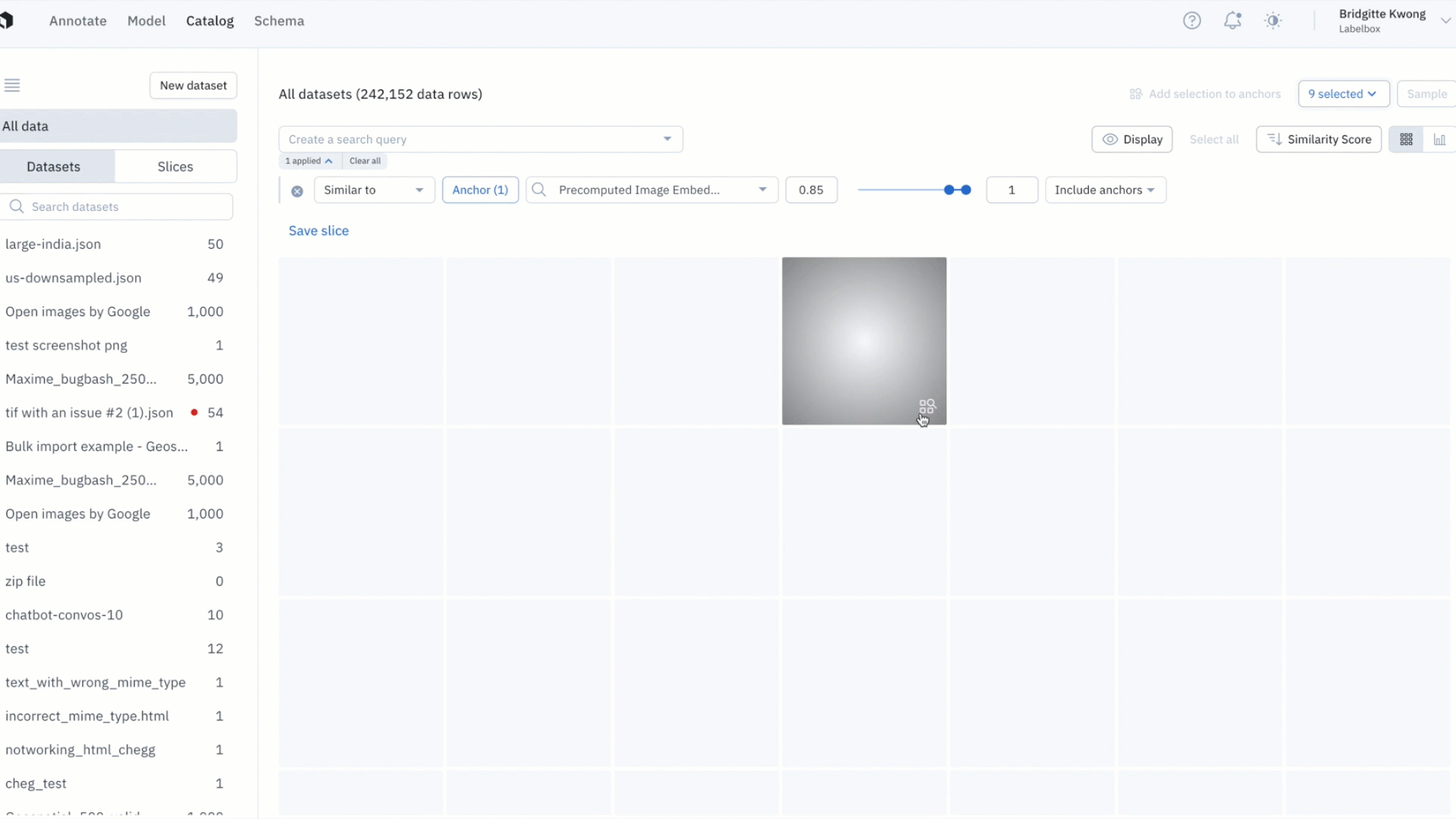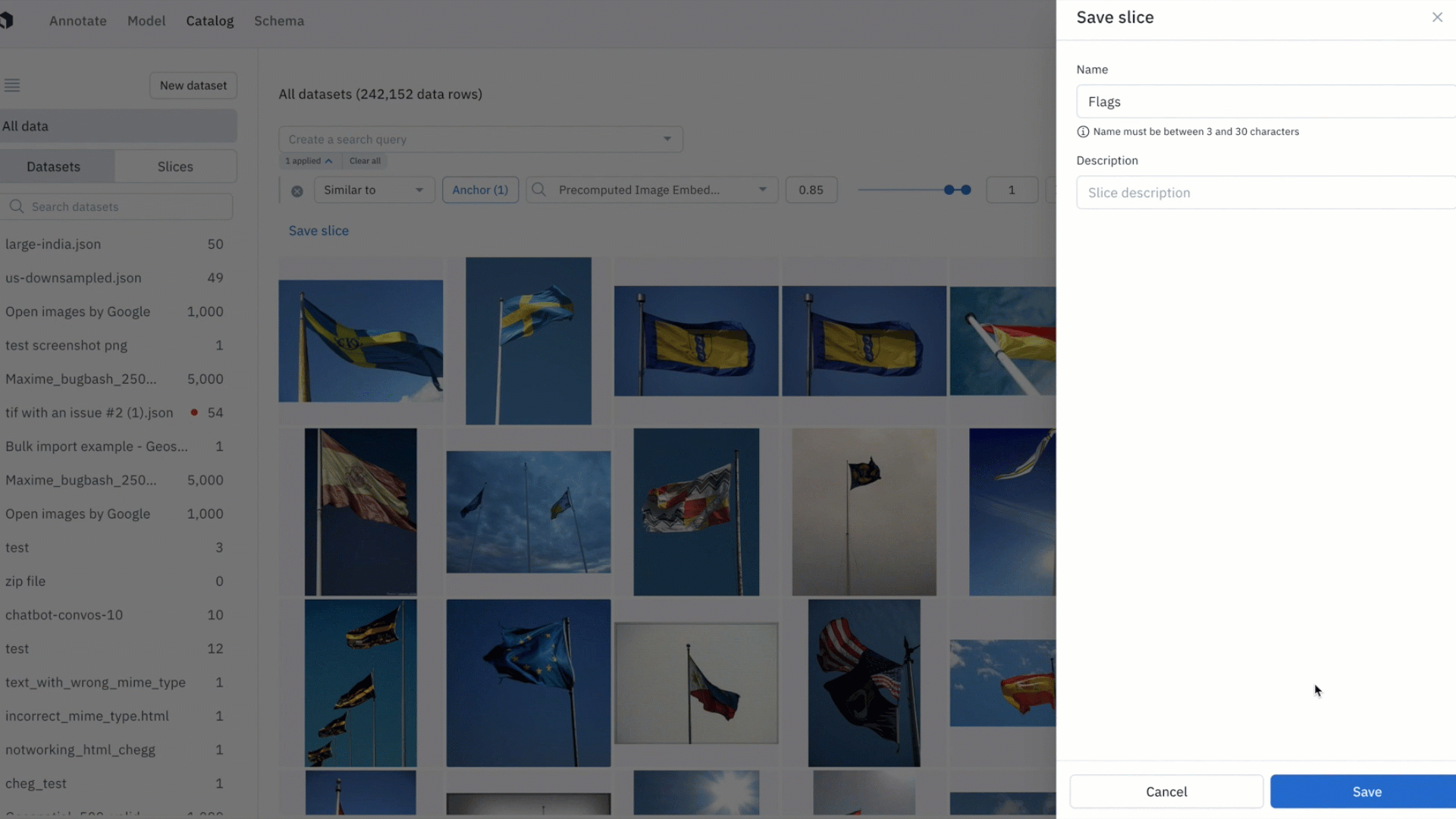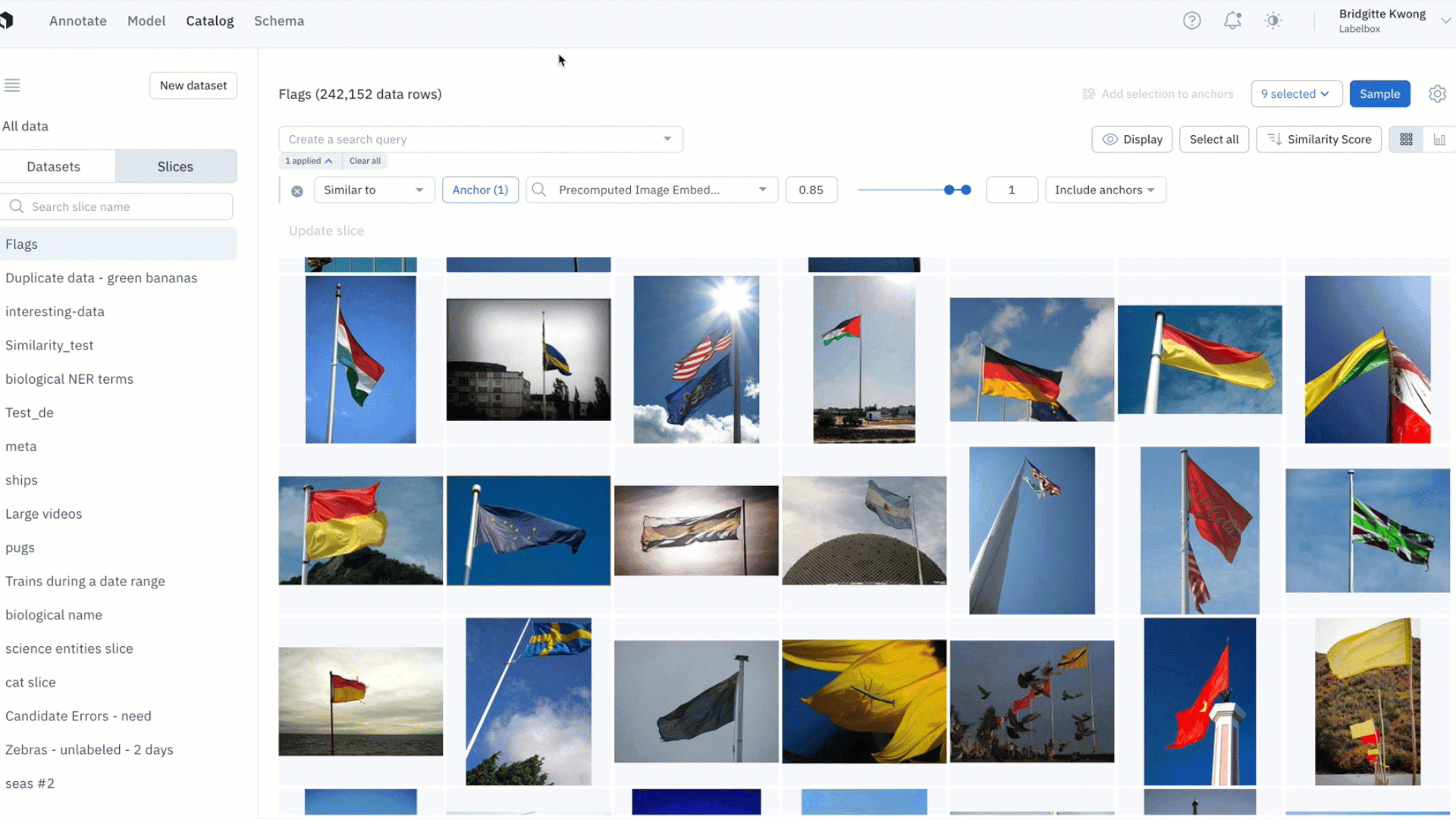
- In this example, the model has low confidence with green bananas, so we used a similarity search and filter to show only unlabeled images of green bananas — which can then be labeled and used to train the model
Automatically curate data
- By saving your similarity search as a slice, any new incoming data point uploaded to Labelbox — and that matches the similarity search — will show up in the slice
- With data curation pipelines that update even when you're offline, you can continuously upload data from production, and data points that look similar to data of interest will show up in the corresponding slice
Find duplicate data
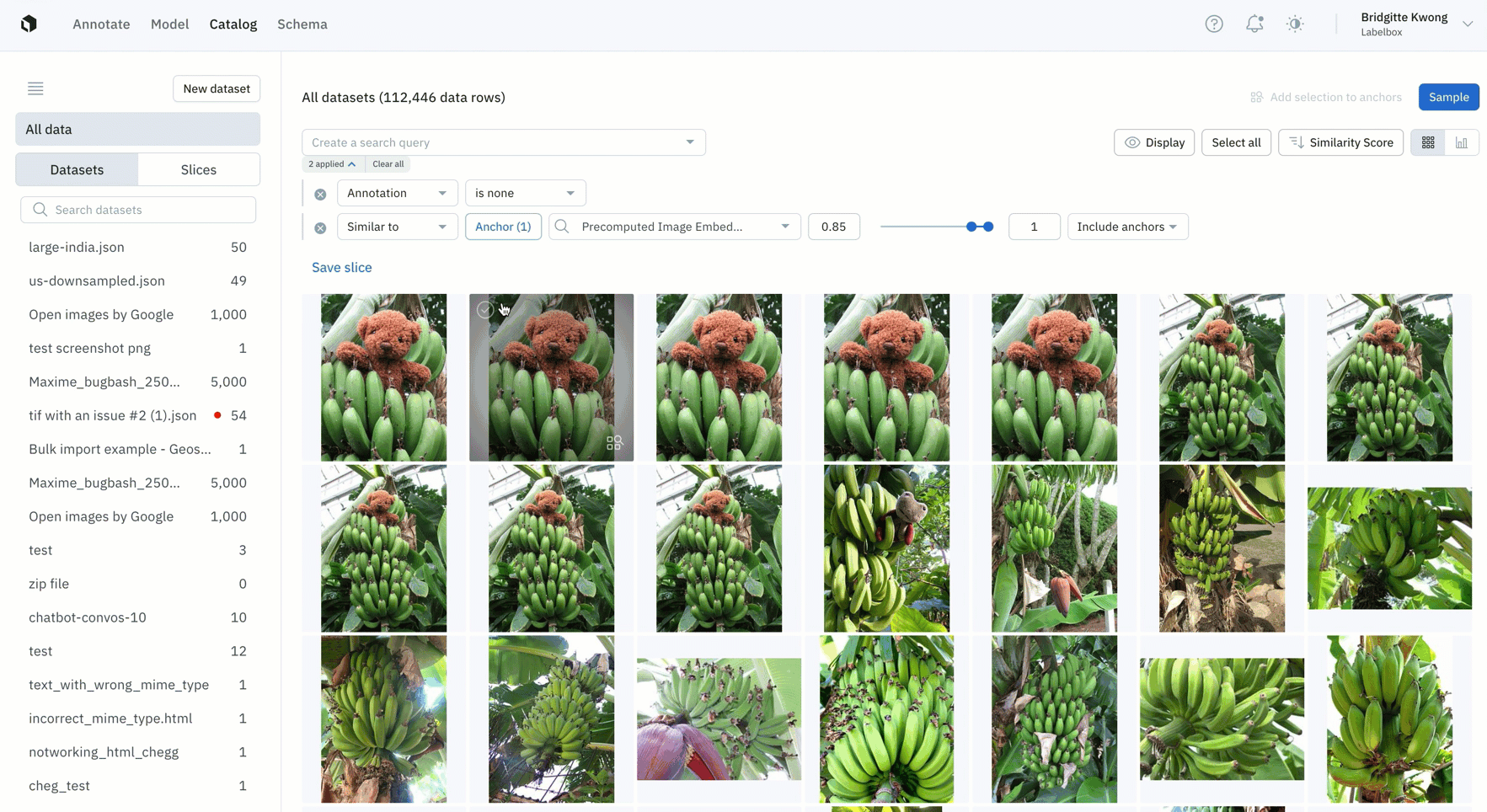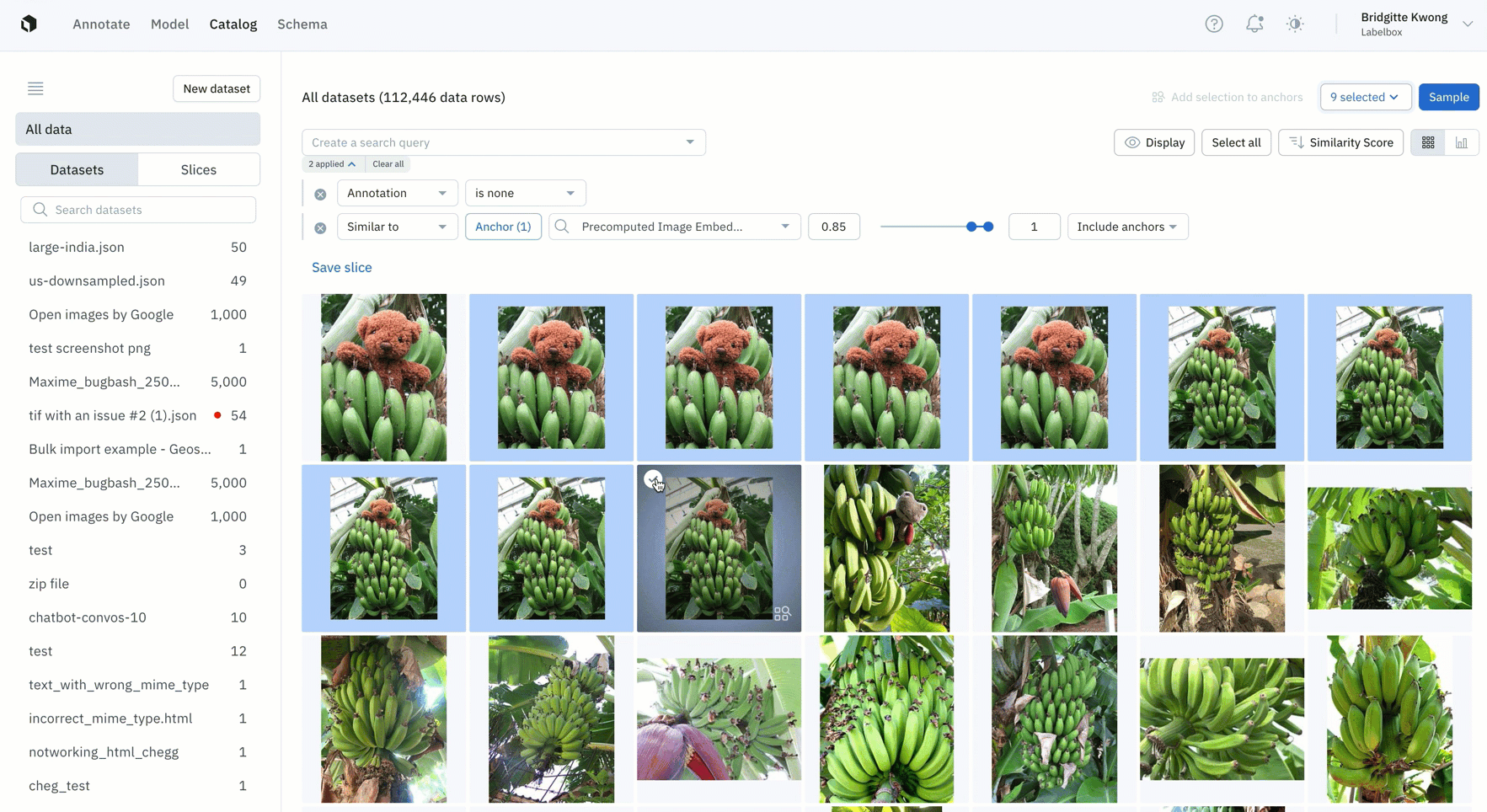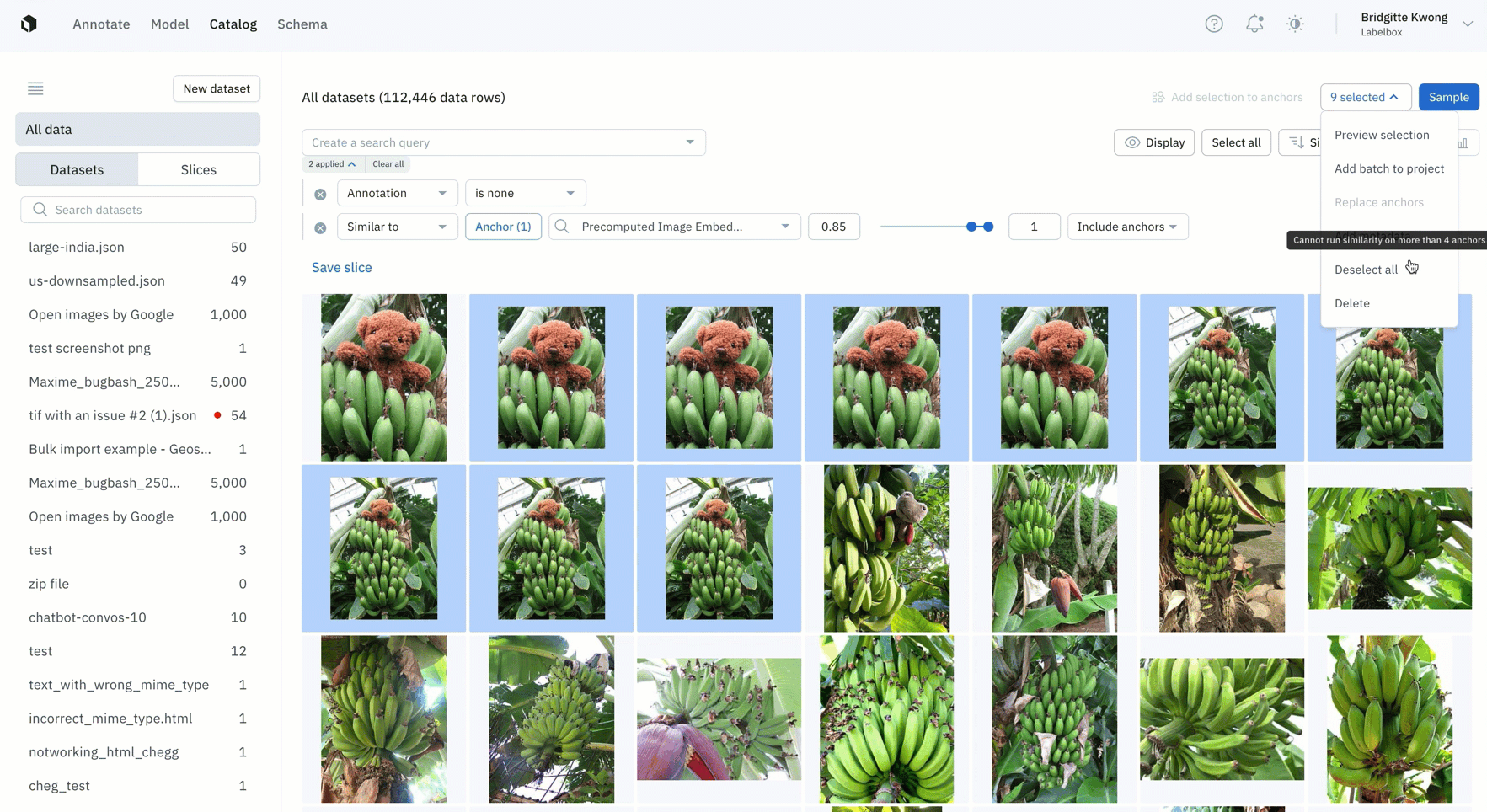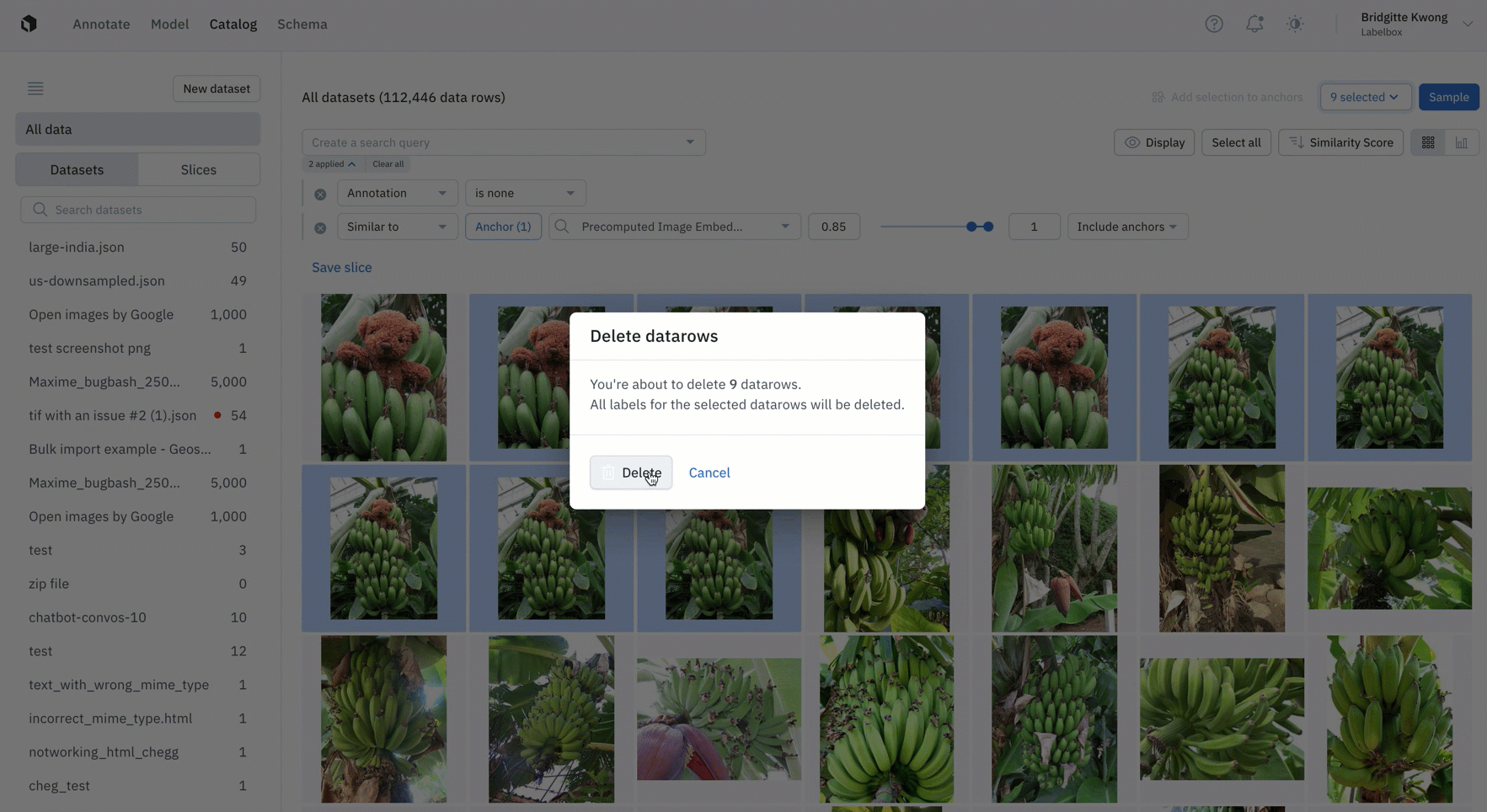
- Easily find all instances of duplicate data that you don't want to appear in your labeling project by leveraging similarity search
- Once you've found all similar duplicate data, you can save this search as a slice and this will automatically filter and all similar images, including past and incoming data that gets added to Labelbox Catalog
- You can then take action on duplicate data, such as deleting them from your Labelbox instance
Automatically label data from Labelbox Catalog

- Leverage similarity search and metadata to automatically identify and label data in bulk without sending data to a labeling project
- Save search criteria for a cluster of similar data as a data slice, so that all new and old data that matches that criteria will automatically get added to that slice
- You can then select data rows of interest within the slice, or select the entire slice and tag these data rows with metadata
- In the above example, we surfaced a cluster of data rows containing green stamps using similarity search, selected the data rows of interest, and added a metadata tag called 'green stamps'
Learn more about our updates to similarity search and embeddings in our documentation.
Search for data rows with global keys
Global keys provide a way for you to identify data rows with a unique user-specified key. Mapping only to one asset, this enables faster querying and prevents duplicate data uploads.

- You can now view and search for global keys across our UI in Annotate, Catalog and Model. With feature parity to external IDs, we highly recommend using global keys as a preferred user-specified ID for data rows
- You can view global keys in "detailed view" across Catalog, Annotate, and Model, filter for global keys in Catalog and Model, and view global keys in Annotate's Data Rows tab and queue view as a column to display and view your data
A standardized asset data row import format
Uploading data to Labelbox Catalog is a fundamental prerequisite to search, visualize, curate, and explore your data. We’ve simplified the asset import format for uploading a JSON file through both the UI and SDK.
With this standardized snake case format, you can upload data with parity across both upload methods. This won't create any breaking changes, but instead will support additional capabilities such as:
- Labelbox UI: upload metadata fields and attachment uploads
- Python SDK: upload raw text, document assets with text layers, and geospatial assets with parameters
Click through the following pages to see the standardized import format for each asset type: Image | Video | Text | Geospatial | Documents | Conversational | Audio | DICOM | HTML
SDK updates
We recently released a new version of our Python SDK (see changelog here). It includes the following major update:
- We standardized our asset import payloads to make the format more consistent across the asset types:
`create_data_rows`, `create_data_rows_sync`, `create_data_row`, and `update_data_rows` all accept the new data row input format for `row_data`
`create_data_row` now accepts an attachment parameter to be consistent with `create_data_rows`
Please use `pip install –upgrade labelbox` to upgrade to the latest version of the SDK.
Latest guides on data curation
Check out the latest tutorials & walkthroughs on how to better curate and manage your data in Labelbox:


