×![]()

 All blog posts
All blog postsLabelbox•September 26, 2022
Prevent duplicate data uploads, save data slices, metadata metrics, and more
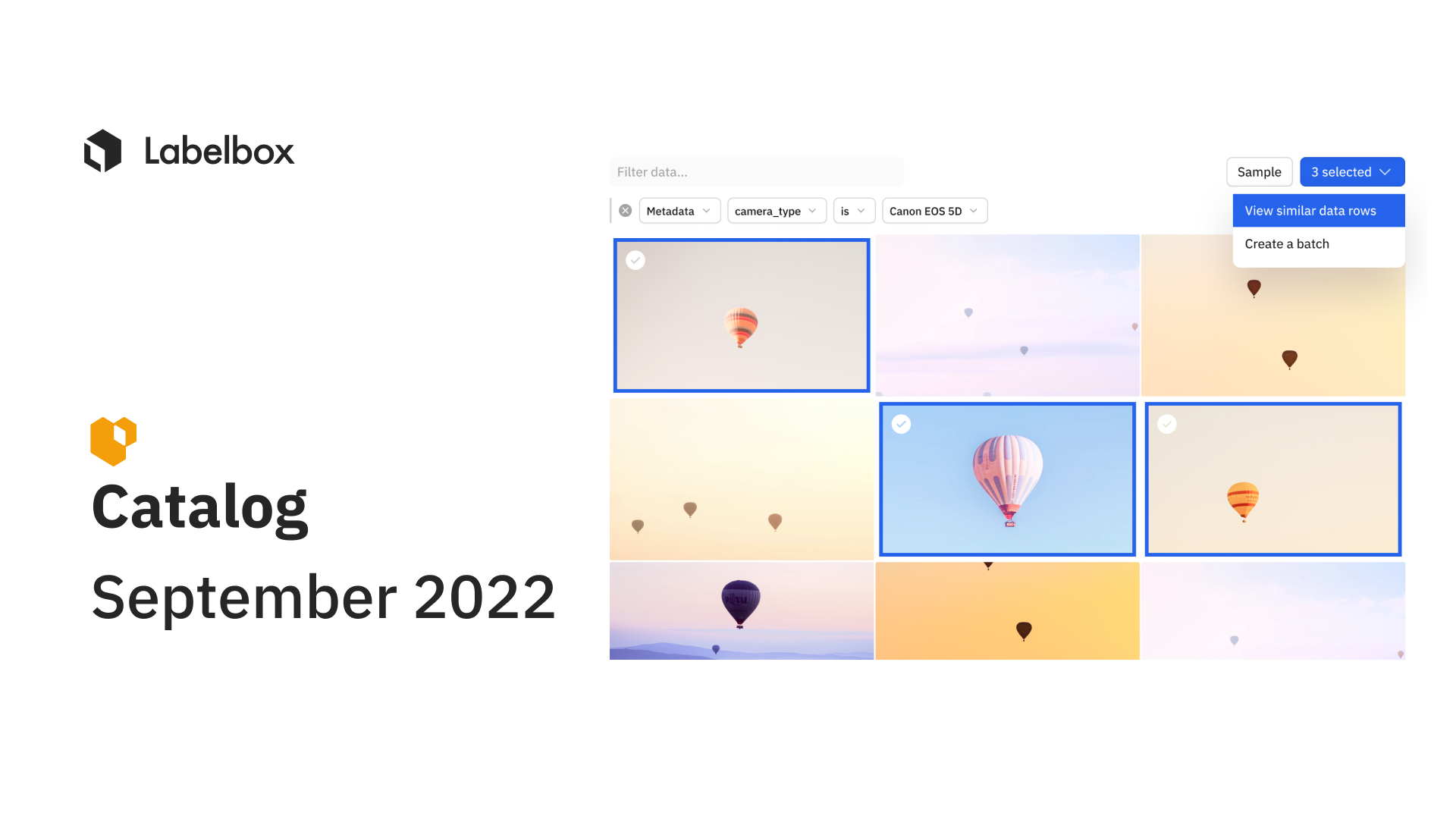
This month's improvements to Labelbox Catalog empowers teams to better query and understand their data – a critical step in unblocking AI initiatives. Catalog now includes a new system to identify data rows, allowing teams to query faster and prevent duplicate uploads. Also new are metadata analytics and a host of exciting improvements to embedding capabilities.
Prevent duplicate data uploads & query faster with global keys
Identify your data rows with global keys, new user-specified IDs for your data rows, which can be easily assigned either retroactively or upon creation.
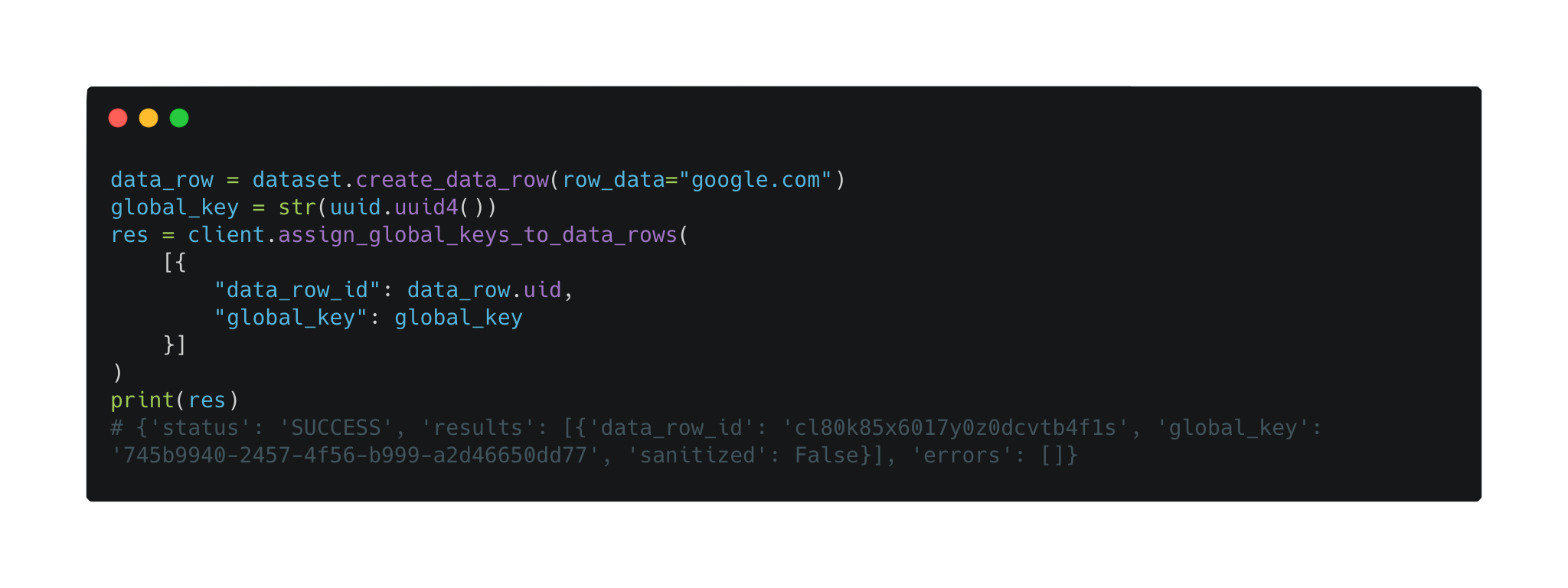
- A user-specified key: Teams have historically relied on External IDs to differentiate data rows. Global keys are a unique user-specified key that allows users to import, query, upsert, and delete data rows.
- Prevent duplicate data uploads: Each global key is unique at the Catalog / Organization level and will map to exactly one data row. This prevents duplicate data uploads, which can be crucial as projects scale to millions of data rows and become increasingly complex.
- Enable faster querying: Unlike External IDs, which can be associated with multiple data rows, each global key maps to exactly one asset. This makes querying data rows through code a one-line process and can increase the speed for queries of large quantities by 10X.
Users can now create a data row with global keys, assign global keys to an existing data row, and query data rows by a global key.
Coming in a few weeks:
Upcoming updates will improve the visibility and searchability of global keys.
- Similar to how External IDs are viewable in “detailed view” and as a filter in both Catalog and the data rows tab, global keys will be visible and searchable through the Labelbox UI.
- While External IDs will still be supported, users are encouraged to create global keys to prevent duplicate data uploads and streamline querying.
You can learn more about global keys in our documentation.
In beta: Save and reuse filters as slices
Catalog is a place for teams to quickly visualize and search across both labeled and unlabeled data. Filters in Catalog are used to narrow in on a specific subset of data. Users can now save and re-use filters in Catalog as a ‘slice.’
- With this new update, teams can set up and save filters as slices in Catalog to surface high-impact data to prioritize in labeling.
- Slices are dynamic – any data that flows into Catalog will appear in the corresponding slice if it matches the filter’s criteria.
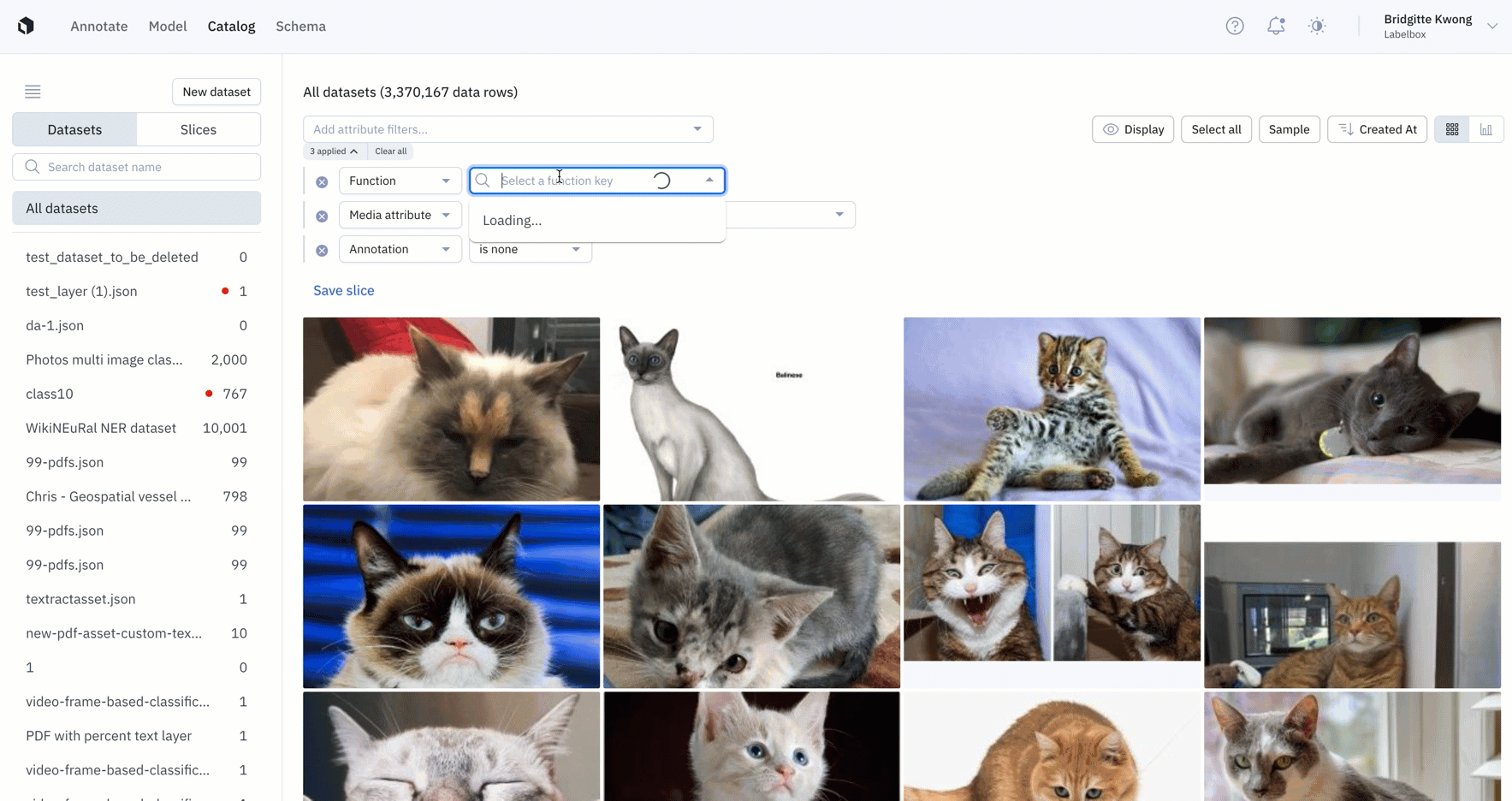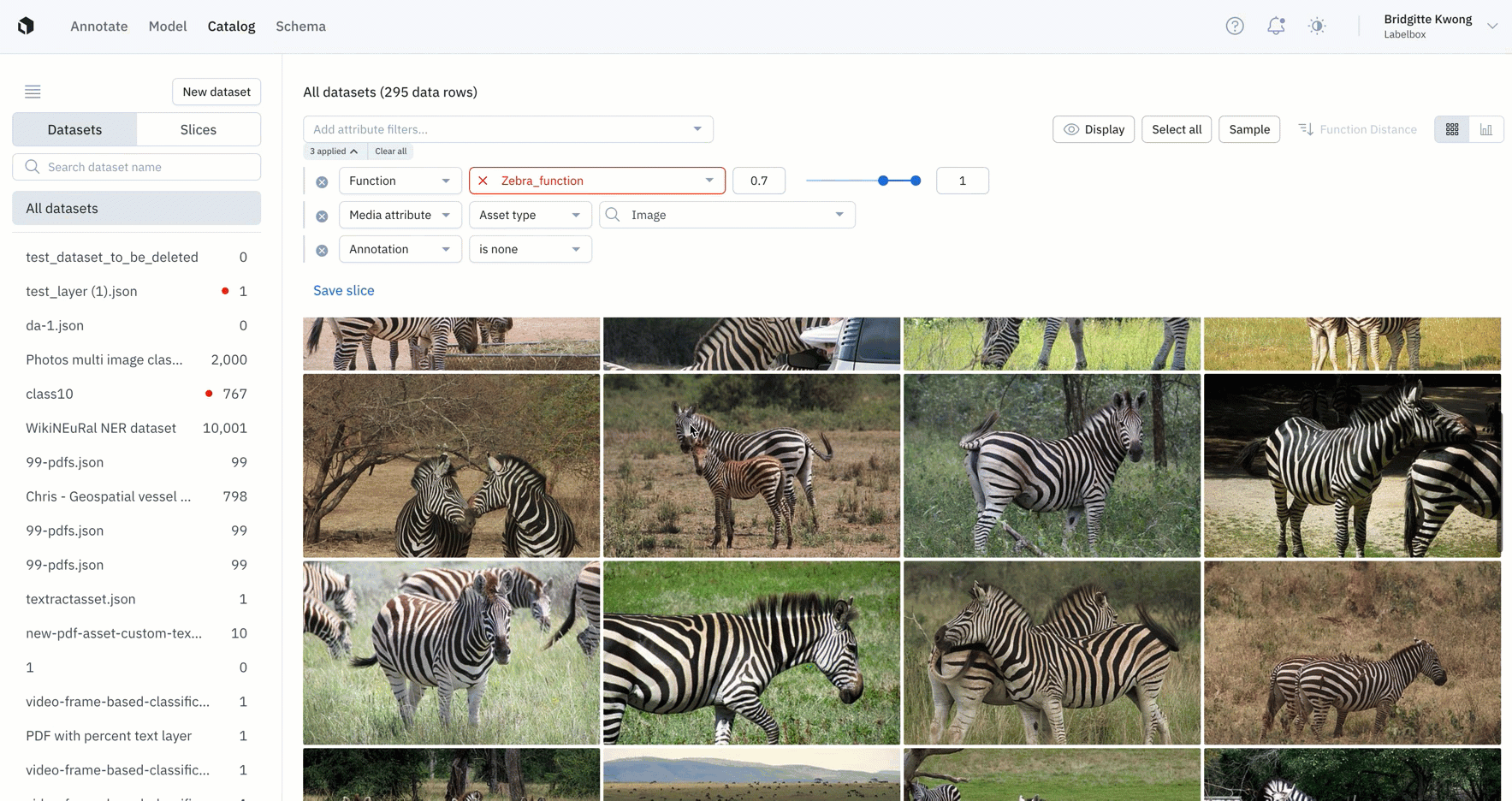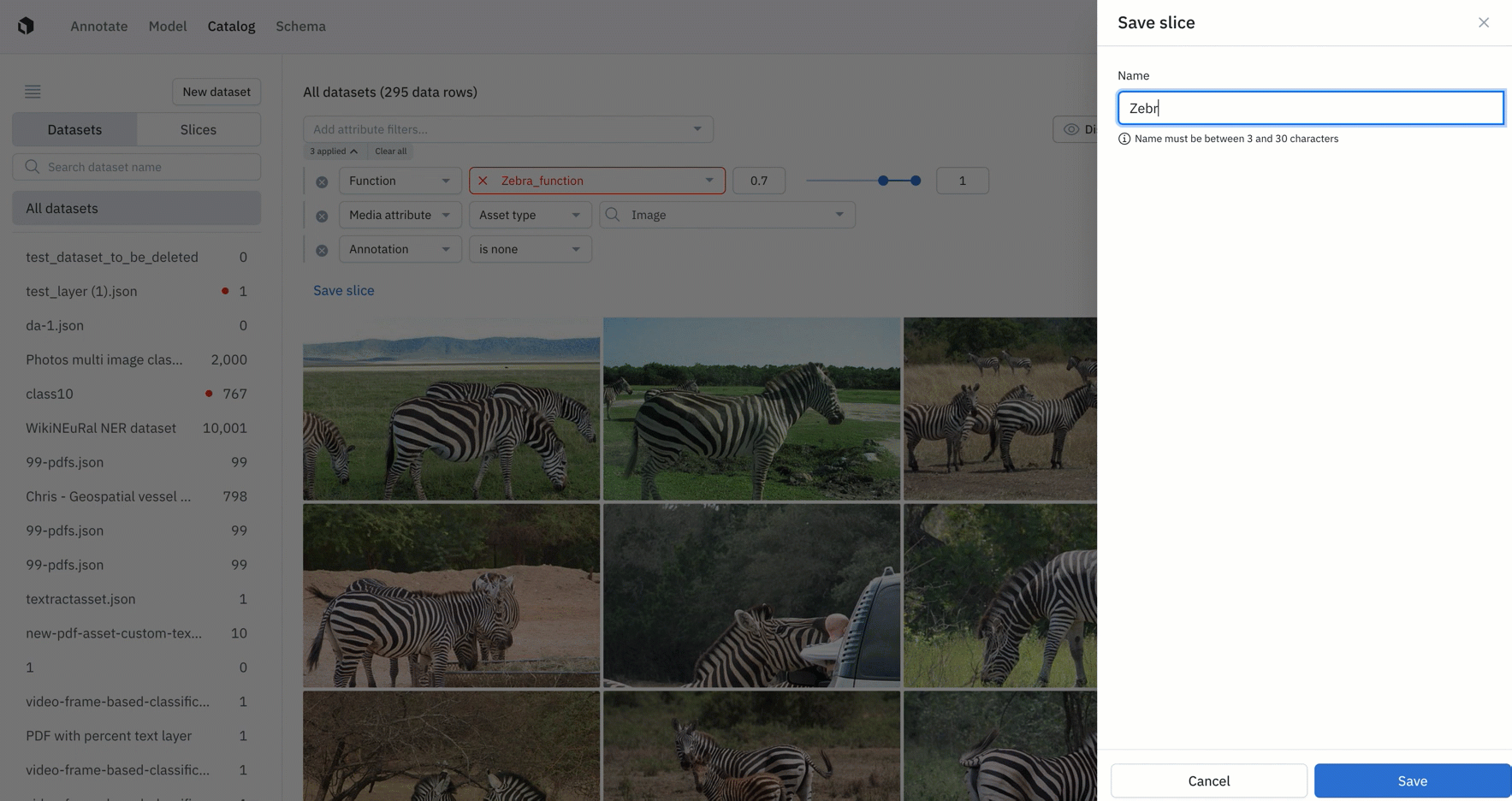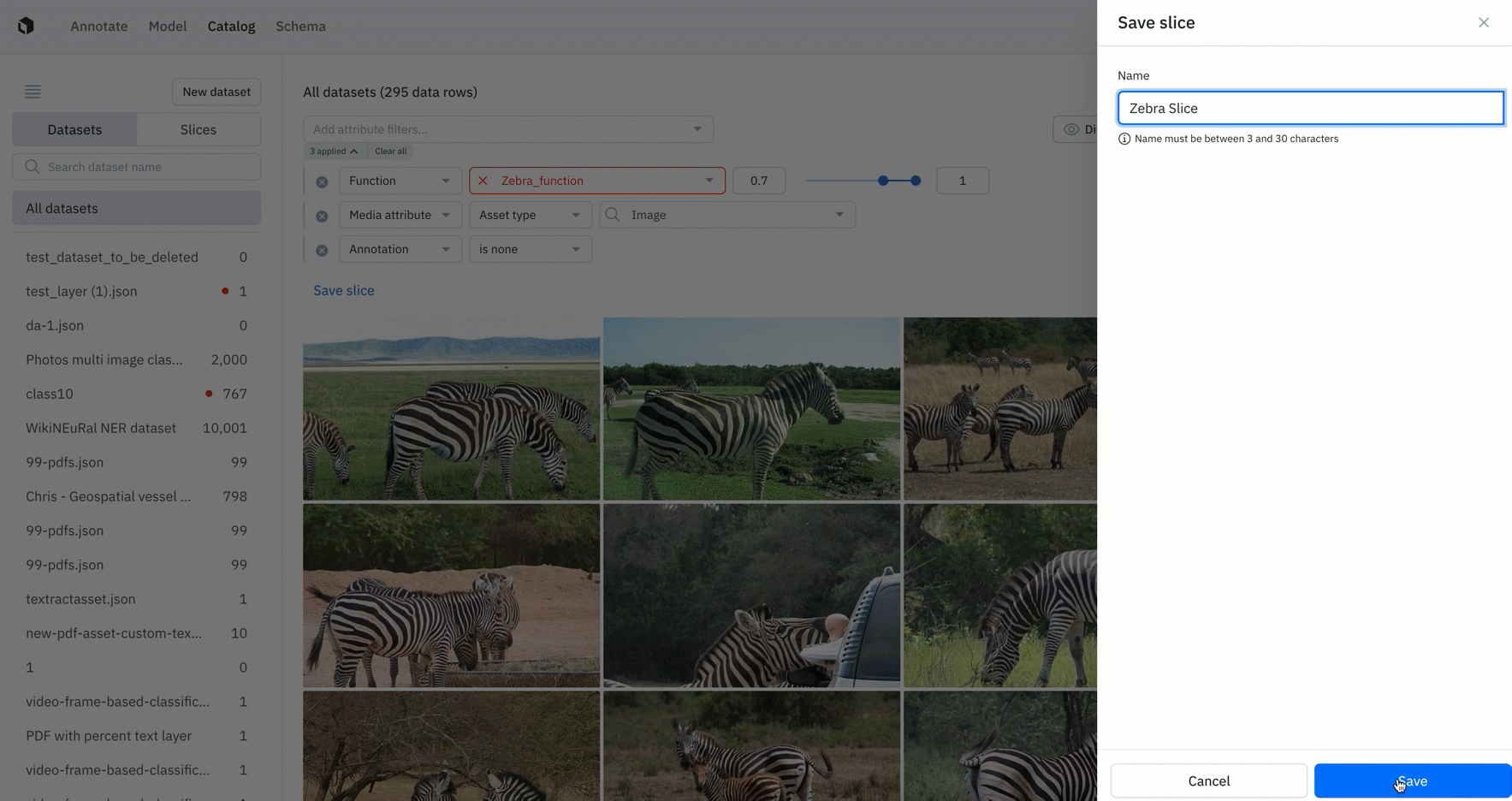
- For example, if a user is interested in surfacing all unlabeled images that look like a zebra, they could create a filter for that search and save it as a slice. From there, all images that come through Catalog and resembles a zebra will be added to the slice.
- This automatic way of filtering and sorting data that enters Catalog is a great way for teams to automatically surface high-impact data to save time.
Better understand the distribution of your data
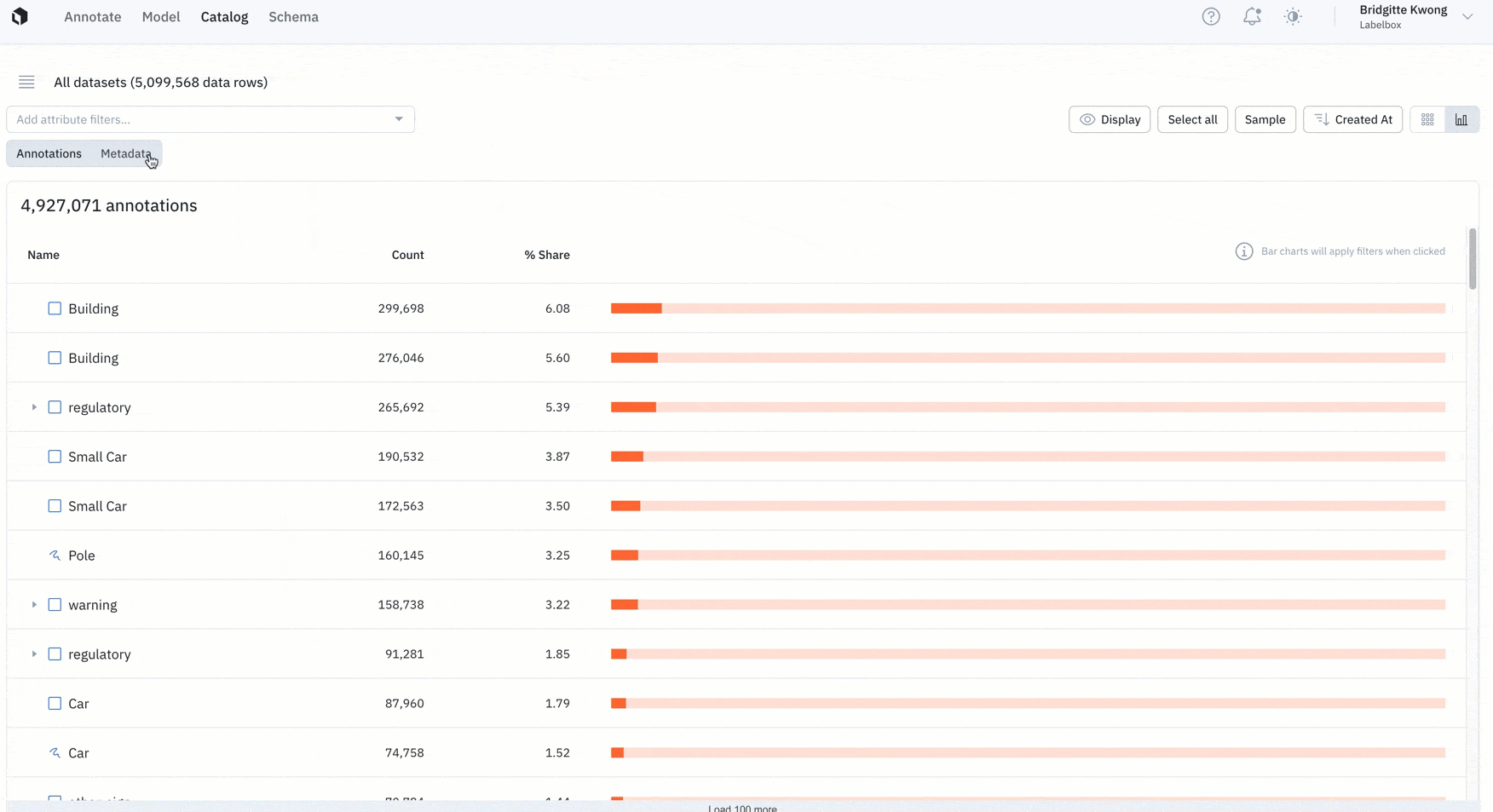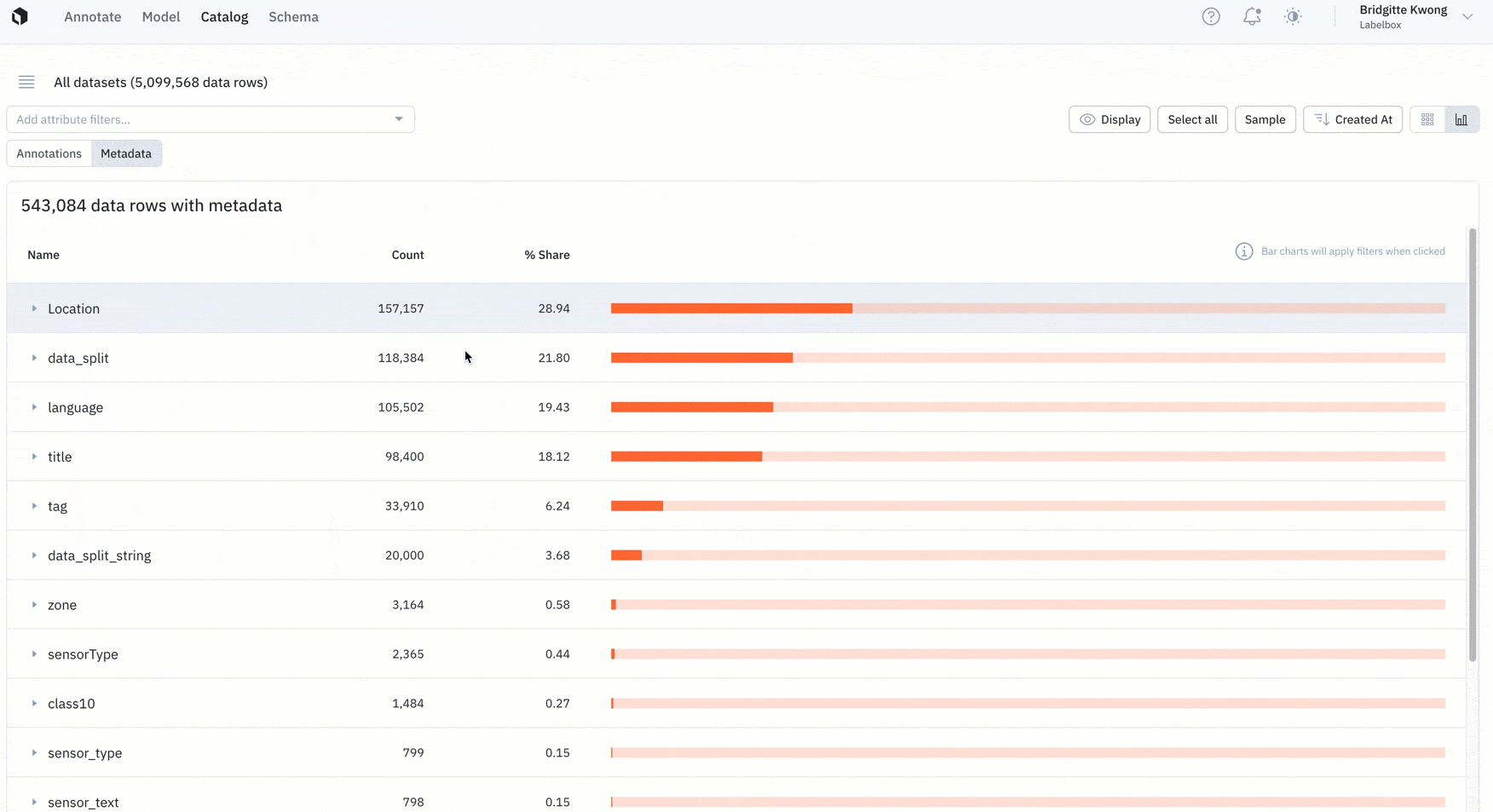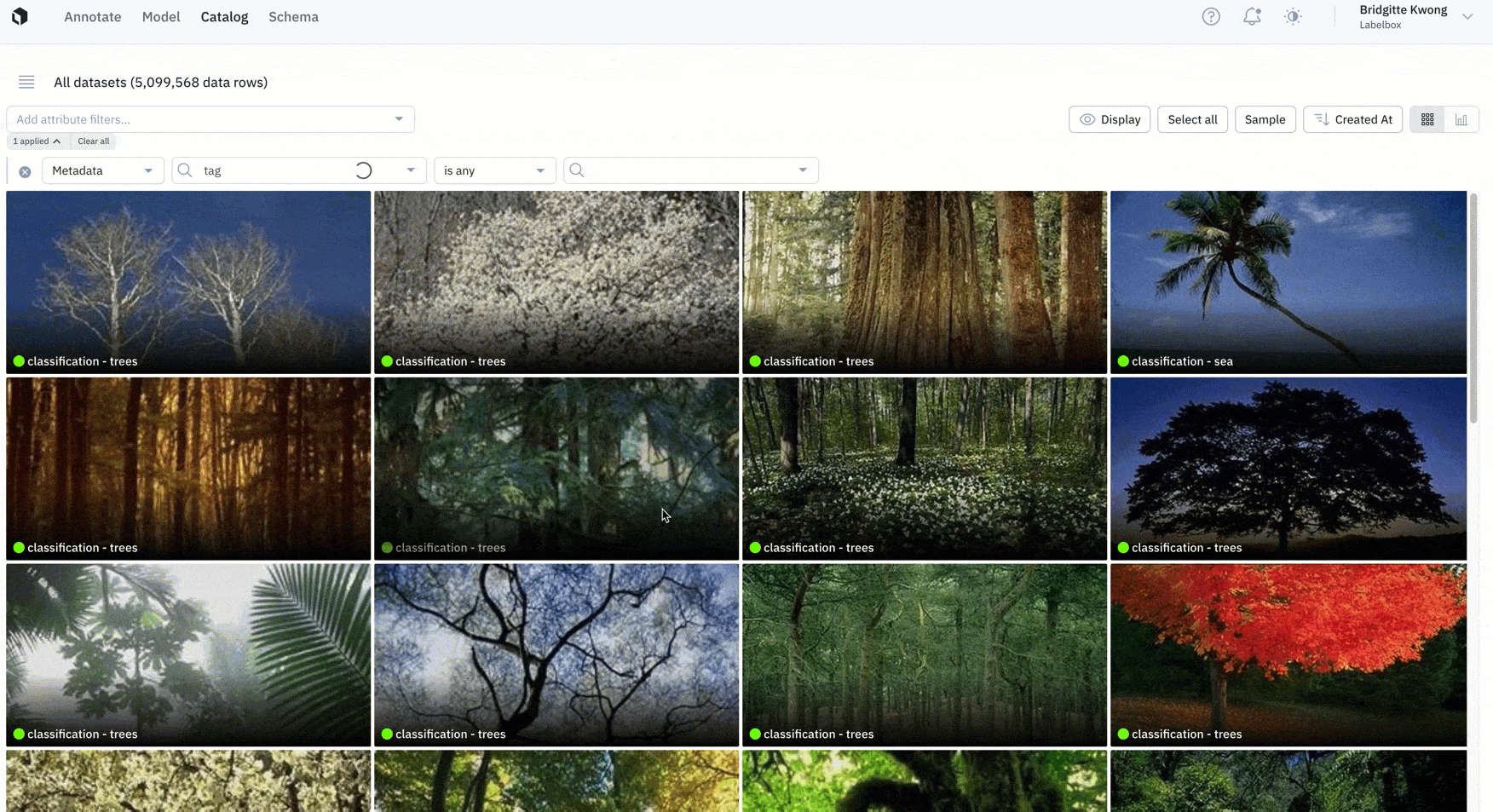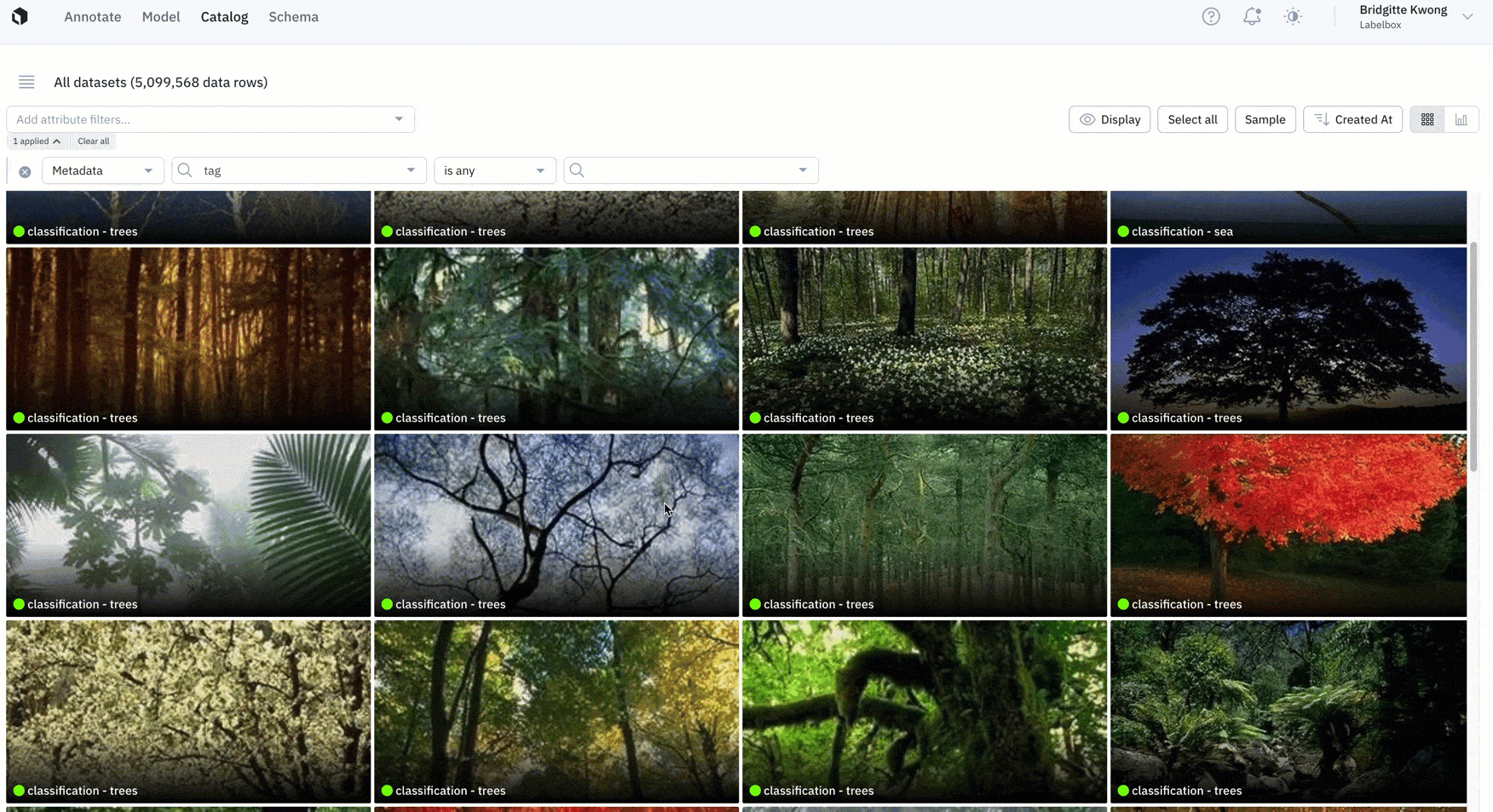
Analyzing data with the right metrics is a key component of prioritizing the right data to label.
- Last month, we introduced Catalog analytics to help teams better understand the distribution of their annotations.
- Catalog now also supports distributions for both annotations and metadata.
- Users can click into any histogram to drill into specific annotations or metrics for further review.
Find and fix model & label errors for text data
Teams can now dramatically improve NER model performance by finding and fixing labeling errors within text training data.
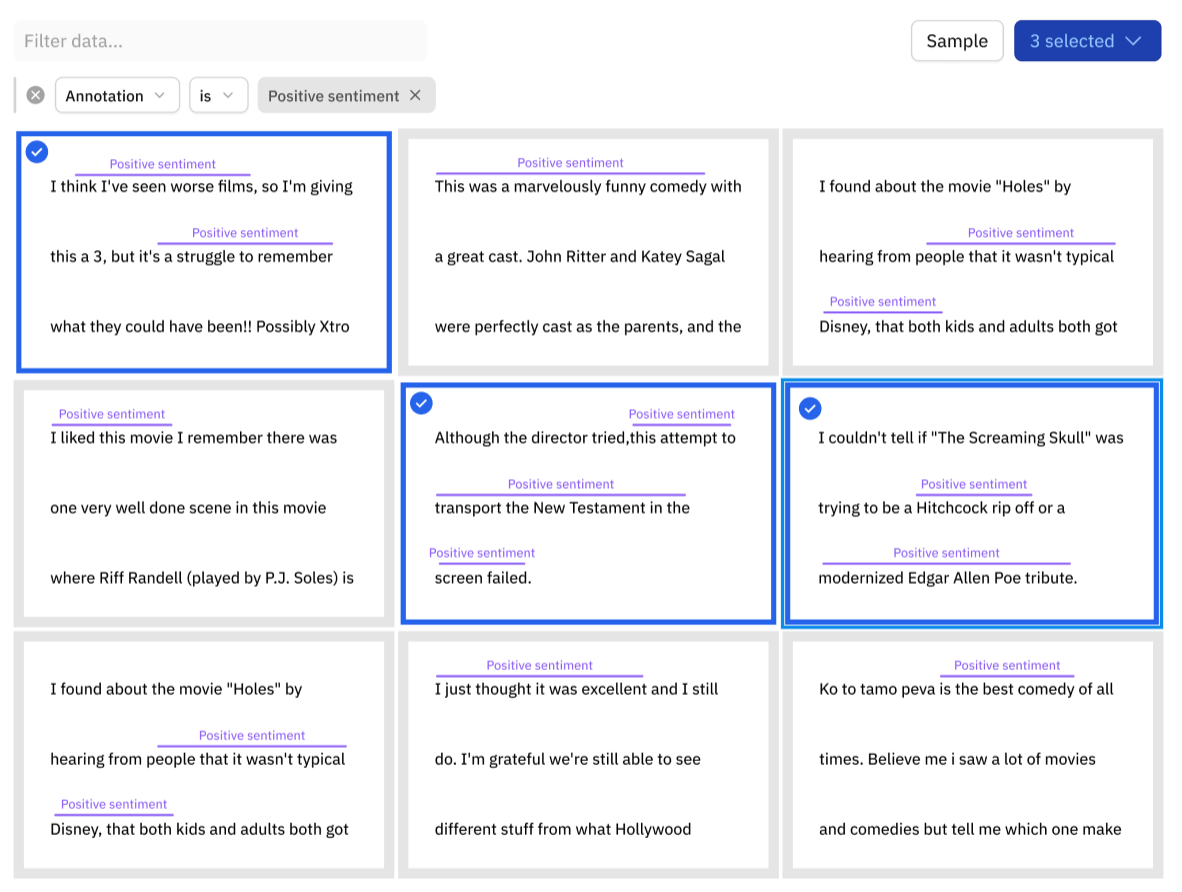
- Visualize ground truth and model predictions for NER data in both Catalog and Model
- Unlock active learning workflows to quickly surface labeling mistakes, understand how your model is performing against ground truth, and prioritize what data to label next
Coming in a few weeks: Support for up to 500 million Data Rows per workspace

Vector embeddings are a powerful way to quickly search and explore your unlabeled and labeled data. Using them can help you break down silos across datasets so you can focus on curating and labeling the data that will most improve model performance.
- Catalog will soon support up to 500 million data rows per workspace and organization. This includes embedding vector search capabilities to make search faster, more accurate, and more scalable.
- Larger and more powerful off-the-shelf embeddings will improve both similarity search and the embeddings projector.
To learn more about the importance of embeddings in creating high-quality training data, read this blog post.


