
 All blog posts
All blog postsManu Sharma•April 3, 2023
Utilizing Few-shot and Zero-shot learning with OpenAI embeddings
Overview
Few-shot learning and zero-shot learning represents two exciting paradigms in machine learning that deal with the challenges of learning from limited labeled data. However, they differ in the amount of labeled data available for the target classes and the way they leverage supporting information. Before we dive into the specifics of how you can adopt these techniques, let's first take a look at how each term is defined and how/when they can be used.
Few-Shot Learning: In few-shot learning, a model is trained to recognize or classify new classes based on a very limited number of labeled examples (typically just a few) for each of those classes. The goal is to leverage prior knowledge learned from other tasks or classes to quickly adapt to the new classes with minimal labeled data.
Zero-Shot Learning or Zero-Shot Classification: Zero-shot classification is a type of machine learning approach that allows a model to recognize and classify new classes based on zero labeled examples of these classes. The model isn’t trained on any examples of the new target classes, but provided with a description of the new target classes at inference time instead.
Potential few-shot and zero-shot use cases
Next, let's walk through a few ways that machine learning teams, data analysts, data marketing, and labeling teams can all benefit from utilizing few-shot and zero-shot learning systems.
Few-shot and zero-shot use cases for machine learning teams
As a machine learning engineer, you might come across a few rare or challenging data points within your dataset. Leveraging few-shot learning to automatically identify all other instances of these edge cases can be highly advantageous. For instance, you could incorporate these data points into your training data, allowing for better model fine-tuning. Alternatively, you might include them in a test set to evaluate your neural network's performance in addressing these uncommon scenarios.
In more extreme scenarios, you might need to identify rare or challenging data points without any existing examples, such as finding all white watches with black dials. This is where zero-shot learning comes into play, enabling you to discover such data without any prior occurrences of it.
Few-shot and zero-shot use cases for data analysts
Data analysts frequently need to query their data—videos, images, text, documents, etc.—to address business questions. Typical inquiries might include: What percentage of our glasses from last year came in each color? Surface all our images of broken glasses. Do people who wear our glasses and post them on social media tend to be indoors or outdoors?
Both few-shot and zero-shot learning can empower data analysts to answer these questions in a few clicks, enhancing their ability to extract valuable insights from the available data.
For instance, simply describe blue glasses, and the data engine will surface all glasses from this color. Alternatively, choose a few images of broken glasses, and the data engine will identify all similar images featuring broken glasses. Additionally, describe indoor images and outdoor images to automatically find and count the number of images that are indoors versus outdoors.
Few-shot and zero-shot use cases for data marketing teams
Data marketing teams frequently face the challenge of locating specific content within vast databases of images, videos, documents, or text. Few-shot learning and zero-shot learning effectively address this needle-in-a-haystack problem. For instance, if you want to find all video clips of middle-aged people in an urban area wearing glasses for an ad campaign, simply provide this description, select a few representative clips, and let the data engine effortlessly identify all relevant occurrences for you.
Few-shot and zero-shot use cases for labeling teams
Labeling teams engaged in classification tasks typically annotate each asset individually, which is necessary for complex classifications. However, for simpler classifications, imagine being able to label everything in bulk. With zero-shot learning and few-shot learning, this becomes possible. Simply describe the classes you want to classify, provide a few examples of each, and let the data engine classify all data points for you. By leveraging zero-shot and few-shot learning, you can accelerate the labeling process and reduce associated costs.
Few-shot and zero-shot use cases for automatic data curation
You might wish to surface these data points within a fixed database. However, machine learning (ML) teams now also have the option to automatically identify these data points among new, incoming data that is continuously streamed from production.
In the rest of this tutorial, we want to show you how Labelbox empowers you to accomplish both: uncover intriguing data within your static datasets, and automatically discover interesting new, incoming occurrences that are flowing through your data pipelines. Establish data curation pipelines that automatically surface high-value data, even while you're not actively working (aka in your sleep!).
What you’ll learn in this few-shot and zero-shot tutorial
In this tutorial, we'll focus on how you can utilize both few-shot and zero shot image classifications using OpenAI's CLIP embeddings. To demonstrate a common use case in the e-commerce sector, we chose the Fashion Styles dataset obtained from Kaggle. However, this workflow is highly applicable to all industries where data categorization is useful.
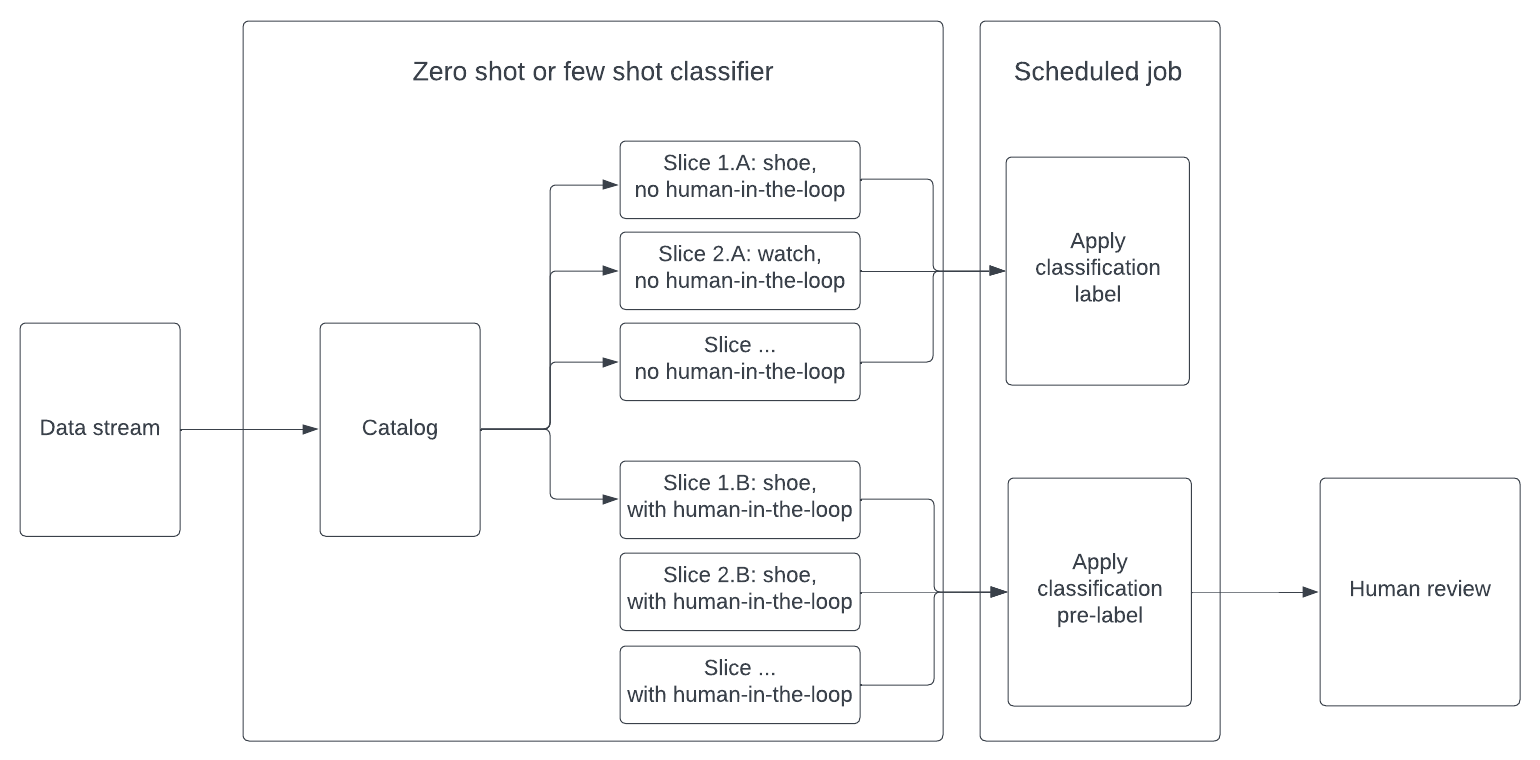
Below is the architecture of a zero-shot or few-shot classification system operating on a real-time data stream. Given zero-shot or few-shot classifications can be prone to errors, we also demonstrate a human-in-the-loop fallback system to ensure that labels are reviewed by a team of experts to better achieve near perfect system performance.
1) Initial setup
Import libraries and data
To mimic a data stream, for the sake of simplicity, we randomly sample a small portion of data from the original dataset. Every iteration will sample new data from the original dataset.
# labelbox
!pip install -q 'labelbox[data]'
import labelbox as lb
import labelbox.types as lb_types
!pip install -q wget
import random, wget, json, secrets, time
LB_API_KEY = ""
client = lb.Client(LB_API_KEY)
wget.download("https://storage.googleapis.com/labelbox-datasets/fashion-dataset/fashion.json")
with open('fashion.json', 'r') as json_file:
# Deserialize the JSON data into a Python object
data_rows = json.load(json_file)
sampled_rows = random.sample(data_rows, k=1000)
Create and configure a project to store classifications
To store classifications, create a project in Annotate. During project creation, an ontology must be created. We chose to classify data into 4 broad categories:
1. Glasses
2. Bags
3. Shoes
4. Watches
Now that the overall setup is complete, we are ready to set up zero-shot and few-shot classifiers within Labelbox Catalog.
2) Set up zero-shot or few-shot classifiers
Commonly, people perform zero-shot or few-shot classification tasks in notebooks or scripts. We’ve found this method to be difficult and unscalable. In real-world systems, it is essential to audit the system, visualize the data, and in some cases have an integrated human in the loop setup to review zero-shot or few-shot classifications.
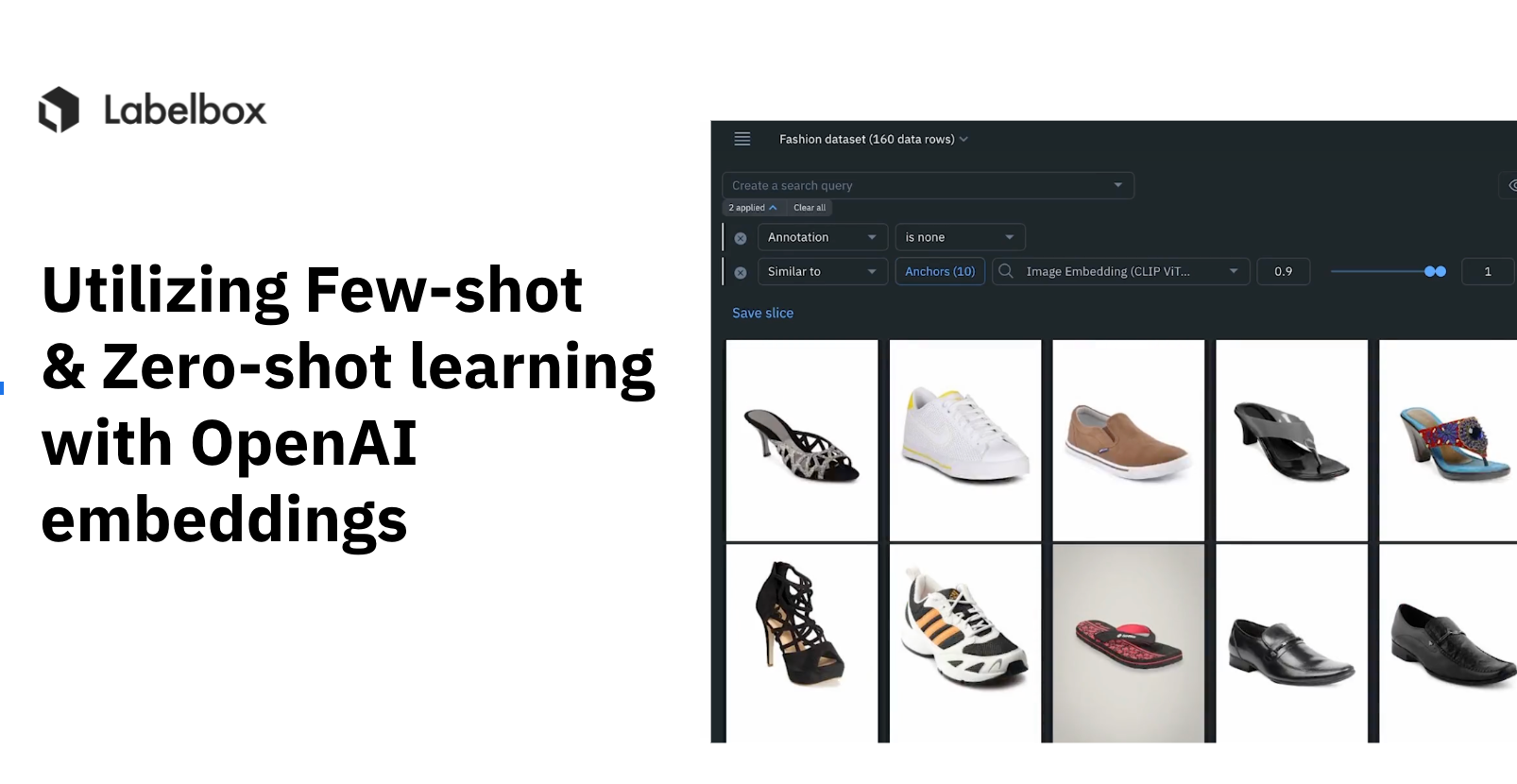
In Labelbox Catalog, there are two primary tools to perform zero shot or few shot classifications: Natural language and similarity search.
Natural language search allows you to query images with natural language and is powered by OpenAI CLIP. No labeling is required, it just works as the OpenAI CLIP model is trained on billions of image and text pairs found on the internet. The model has an underlying understanding of most concepts in the visual domain.
Similarity search enables users to find data rows closely resembling a few given positive examples, known as "anchor" data rows. By providing a few instances of the desired data, users can automatically surface all other occurrences within the dataset. The objective of similarity search is to identify items bearing the highest similarity to the query item, based on a specific distance metric.
Labelbox Catalog will automatically compute CLIP embeddings, and uses optimal distance metrics on these embeddings based on the type of query. If CLIP embeddings do not yield satisfactory results for a particular task, users have the option to import their own custom embeddings via the API.
In most cases, we are able to find positive results with natural language search alone, by simply typing bag, wallet, glasses and shoe. Classifying the results would be a practical application of zero-shot classification.
Having said that, natural language search is also a great starting point to find anchors and then perform similarity searches. We proceed by selecting a few anchors for similarity search. We add an “Project is none” filter to ensure that the results don’t include previously annotated data. This surfaces results for each class - based on just a few examples provided by humans.
Our goal is to save these results, and make sure that any new, incoming data point shows up in the relevant search query results. This is exactly what slices can achieve in Labelbox! A slice is a saved search query that is executed in Labelbox Catalog every time it is accessed in the UI or via API.
How it works: Bags example
How it works: Shoe example
3) Optimize with human in the loop
Since zero and few-shot classification can be error prone, it may contain false positives. To address this, you can create two slices for each target class.
First, we create a slice containing results where Catalog exhibits high confidence in its classification. In this case, human-in-the-loop intervention is unnecessary, and classifications can be directly assigned as labels.
Second, we create a slice containing results where Catalog demonstrates lower confidence in its classification. For these results, human-in-the-loop review is required before final classification, and we assign classifications as pre-labels. By utilizing few-shot classification for pre-labeling data, we can ensure that human review is both time-efficient and cost-effective.
4) Fetch slice data
In order to apply classification, we export data rows from the respective slices, and assign them labels (no human-in-the-loop) or pre-labels (human-in-the-loop). Given the slices are saved queries and update dynamically, the data rows will disappear from the slice results after pre-labels or labels are successfully added.
# shoes
SHOE_SLICE_HITL_ID = "clfy451i60jfa070d2i1tfbia"
SHOE_SLICE_NO_HITL_ID = "clfy7bfpk19p807y609j33tiv"
# glasses
GLASS_SLICE_HITL_ID = "clfy7fyiq0iic07xwef9j1o22"
GLASS_SLICE_NO_HITL_ID = "clfy7dahn0fpt070i6nw61zs2"
# watches
WATCH_SLICE_HITL_ID = "clfy7zcoc194l070d1pscdukv"
WATCH_SLICE_NO_HITL_ID = "clfy7yuk70rre07zl22d3h8qg"
# bags
BAG_SLICE_HITL_ID = "clfy7xb8g0qpt071qgzqifxuv"
BAG_SLICE_NO_HITL_ID = "clfy7x1dc08tg07xufwd0gj3n"
# utils: get global keys of the results of each slice
def export_slice(slice_id):
slice = client.get_catalog_slice(slice_id)
task = slice.export_v2(params={"label_details": True})
task.wait_till_done() # wait until export is done
global_keys = [ result['data_row']['global_key'] for result in task.result ]
return global_keys
# shoes
shoe_global_keys_hitl = export_slice(SHOE_SLICE_HITL_ID)
shoe_global_keys_no_hitl = export_slice(SHOE_SLICE_NO_HITL_ID)
# glasses
glass_global_keys_hitl = export_slice(GLASS_SLICE_HITL_ID)
glass_global_keys_no_hitl = export_slice(GLASS_SLICE_NO_HITL_ID)
# watches
watch_global_keys_hitl = export_slice(WATCH_SLICE_HITL_ID)
watch_global_keys_no_hitl = export_slice(WATCH_SLICE_NO_HITL_ID)
# bags
bag_global_keys_hitl = export_slice(BAG_SLICE_HITL_ID)
bag_global_keys_no_hitl = export_slice(BAG_SLICE_NO_HITL_ID)5) Apply classifications
We already created a project with the aforementioned four classes. Next, let's opt for a checklist classification because there may be images that may contain a person wearing all these items.
First, we prepare the payload with the classifications.
# Utils: send images to project
def send_images_to_project(global_keys):
batch = project.create_batch(
name= secrets.token_hex(6), # Each batch in a project must have a unique name
global_keys = global_keys, # global keys of selected data rows
)
return batch
# Utils: prepare payload to upload classification as pre-labels
shoe_prediction= lb_types.ClassificationAnnotation(
name="Fashion item",
value=lb_types.Checklist(
answer = [lb_types.ClassificationAnswer(name = "Shoe")]
)
)
def prepare_payload(global_keys):
payload = []
for global_key in global_keys:
# Submit predictions as a pre-label in the project
payload.append(
lb_types.Label(
data=lb_types.ImageData(global_key=global_key),
annotations = [shoe_prediction]
)
)
return payload
Then, we upload classifications as pre-labels or labels.
6) Create an automated scheduled job
Finally, let’s automate this pipeline. To do so, we recommend using Databricks to schedule notebook jobs and schedule the job to run every few minutes.
Final thoughts on few-short and zero-shot learnings
Whether you're an ML engineer, data analyst, marketer, etc, you'll commonly encounter rare or challenging data points in your dataset that you'll want to better understand and prioritize.
In these cases, leveraging the latest advances in few-shot or zero-shot learning can be highly useful for training your model to recognize or classify new classes based on a very limited number of labeled examples. This will likely save you countless hours by tapping into platforms such as Labelbox Catalog, in combination with Databricks.
We hope this post inspires a few future use cases and walks you through how you can leverage few-shot and zero-shot learning, using OpenAI CLIP embeddings as an example. The workflow we shared should be applicable to a wide breadth of industries where data categorization is useful, and we'd love to hear your feedback and ideas on how you can utilize this for your upcoming projects.
-- Illustrated in the video above: The completed example of fashion categorization (shoes, watches, bags) using OpenAI CLIP embeddings within Labelbox Catalog. --


