×![]()

 All blog posts
All blog postsLabelbox•December 7, 2022
How to leverage the latest advances in automation when building AI products

Using an efficient, optimized data engine is key to successful AI development, regardless of AI maturity level. Building out the processes within and around the data engine, however, even with best-in-class solutions, can be a challenge when starting from scratch. How do you best leverage automation for your specific data engine requirements to achieve the AI results you need?
This post synthesizes some of the most effective automation strategies shared at Labelbox Accelerate 2022, during the session How to leverage automation when building AI products.
Create reproducible workflows
“Our goal at Nayya is to have reproducible pipelines as part of our MLOps,” says Ishan Babbar, Lead Data Scientist at Nayya. Nayya offers an AI-powered solution that helps individuals better understand and choose among their employer-provided benefit plans. With Nayya, users can take a ten-minute survey and get a plan recommendation that best suits their specific needs. To ensure that the plans recommended to customers are appropriate, the organization uses an automated feedback loop between their customer success team and benefit providers to evaluate and explain the model-generated recommendations.
Producing labeled data for both the offline model training and live prediction evaluation and verification by subject matter experts can be a challenge. However, by reusing both the labeling workflow they built with Labelbox and the resulting labeled data (via a feature store) for both tasks, the team kept up with their training data needs.
"The annotation workflow with Labelbox allows us to do this at scale and build a repeatable process for the data scientist as well as any subject matter experts that work with us,” says Babbar.
Build iteration loops for model diagnostics and active learning
CAPE Analytics creates AI solutions for property insurance and real estate companies using geospatial data. To improve iteration and develop better models quickly, the team created two separate automated data and training workflows with Labelbox as a central piece of their data engine. In the model diagnostic workflow, the team leverages Labelbox Model to find errors and biases, and then uses Labelbox Catalog to find similar data and discover edge cases. This data is then added to a labeling project and used to train the model again to correct errors.
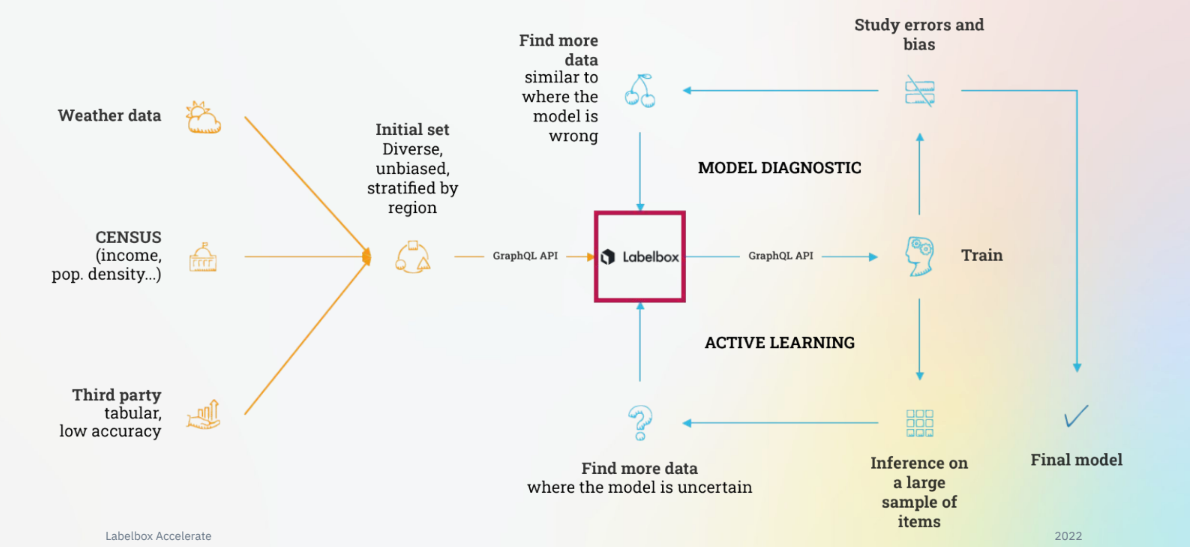
The automated active learning loop is used to identify areas of uncertainty in the model. The team queries for both epistemic uncertainty (uncertainty due to a gap in the model’s knowledge) and aleatoric uncertainty (randomly occurring issues). Once an area of uncertainty is identified, the team uses Labelbox Catalog to find relevant data, which is then added to a labeling project and used to correct the uncertainty.
“There are many different ways to do active learning,” says Giacomo Vianello, Principal Data Scientist at CAPE Analytics. “You can try to find examples that will give you the largest reduction in errors in the model. Another strategy is to find examples that will make the most impact on your model.”
“We've found that some active learning techniques are more successful than others depending on the project at hand. Also, it’s not just always about performance, but also robustness. Active learning finds corner cases that may not move the needle for model performance, but improve robustness. This is important to our customers because we're making our models more reliable,” says Vianello.
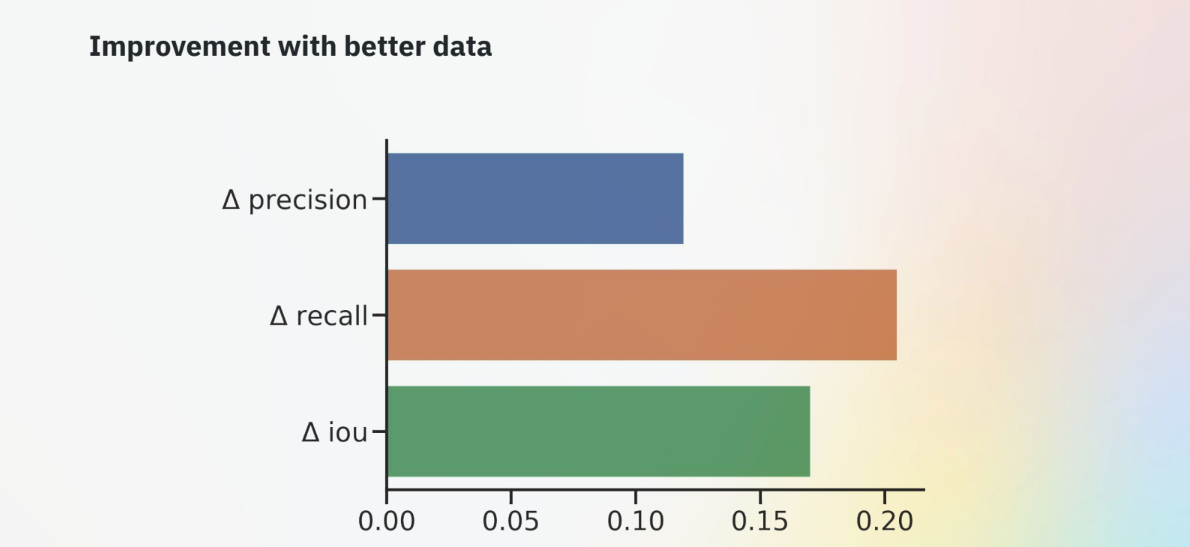
By incorporating both their automated model diagnostic and active learning loops, the data engine helped CAPE Analytics get significant results: 10% improvement in precision, almost 20% improvement in recall, and more than 50% in IoU for one model.
Interface with data programmatically via a simple SDK
The CAPE Analytics team uses the Python SDK to integrate Labelbox with their data sources and model training backend. These tools are used to automatically import data into Labelbox and export labeled datasets into their AI training workflow and model diagnostics and active learning loops. The team also uses the Python SDK to automate labeling project creation and ontology creation for their labeling projects — a process that would otherwise be slow and complex, as their ontologies can include up to 20 questions and segmentation rules.
The AI team at Nayya also relies on an automated, SDK-driven approach to give their actuaries (SMEs) insight into how the model will generate predictions and evaluate these predictions. “We use the Python SDK almost religiously at Labelbox. Part of the main value we get from the platform is being able to interact with how labeling is going, performance quality metrics, and loop that information back to our actuaries and subject matter experts,” says Babbar.
To learn more about how CAPE Analytics and Nayya uses automation in their AI data engines, watch the 45-minute session from Labelbox Accelerate 2022: How to leverage automation when building AI products.


