
 All blog posts
All blog postsLabelbox•August 9, 2023
How to unlock the full power of GPT-4 for enterprise AI
Labelbox's Model Foundry allows teams to leverage GPT-4 to automate data labeling workflows - learn more here.
In the ever-evolving landscape of machine learning, data continues to fuel the advancement of models. While the importance of high-quality data remains, labeling data from a cold start has remained a challenge for most AI teams. Advanced ML teams often adopt partially automated workflows to mitigate costs and accelerate model development. The process of manually annotating datasets from scratch not only requires valuable team time, but can also introduce the potential for human error or bias.
Pre-labeling, feeding unlabeled data through a model (whether off the shelf, a model built specifically for this purpose, or an early version of the model in training), has become a way for teams to start automating their labeling workflow to prevent starting from scratch. With the advent of foundation models, such as GPT-4, teams now have a way to automate and accelerate data labeling rather than starting from scratch. From text summarization to language translation, classification to question answering, GPT-4 offers a versatile toolkit to kickstart the labeling process.
Why is GPT-4 so powerful?
As a large multimodal model that has been trained and fine-tuned on a large corpus of text, GPT-4 has been shown to outperform crowd-sourced labeling on various tasks with high-accuracy. By combining the power of GPT-4 with human-in-the-loop review, you can accelerate your labeling operations.
But how can you effectively leverage GPT-4 for your machine learning or specific business use case? In machine learning, prompt engineering refers to the process of designing and crafting input prompts or instructions that guide a model’s behavior and output. Creating prompts are particularly relevant when working with large language models, such as GPT-4, and prompts can be modified or engineered to make the large language model deliver highly specific outputs. By carefully constructing prompts, you can influence the generated responses to align with your desired outcomes and use cases.
A well-crafted prompt effectively guides the large language model’s behavior to generate the desired output. Key components tend to include:
- A clear objective: Define a clear and specific objective for the model and clearly state the task or goal for the model to address.
- Context: Provide relevant context for the model to understand the situation or scenario.
- Explicit instructions: Guide the model with detailed instructions on what you expect it to generate. For example, for a summarization task, you could instruct the model to provide a concise one-sentence summary highlighting key points.
- Examples: Help the model understand the desired format, style, and content of its response by providing some examples related to the task at hand.
- Relevant constraints: Make sure to specify any constraints that the model should be aware of and adhere to. For example, you can ask the model to avoid outputs that include a certain word or phrase.
Oftentimes, you’ll want to experiment with different variations of prompts to evaluate and see which prompt yields the most accurate results. By taking these elements into consideration and tailoring your prompt to the desired task at hand, you can harness the power of GPT-4 to generate high-quality contextually relevant outputs that can be used as pre-labels.
How to leverage GPT-4 in Model Foundry

Labelbox’s upcoming Model Foundry provides access to a range of popular models, including third-party APIs and open source models. Categorized by their intended uses, you can quickly browse and select a model that is the best fit for your desired use case. After selecting a model, such as GPT-4, you can use our prompt-based interface to easily create effective prompts for generating accurate pre-labels.

Out-of-the-box prompt generation
Model Foundry simplifies the prompt engineering process by offering an out-of-the-box prompt template. To generate model predictions, simply define the ontology pertinent to the model task. Once you select an ontology, a prompt template will automatically populate in the ‘Prompt’ text box.
Easily preview predictions and modify prompts
Based on the generated preview predictions on a small subset of data, you can modify the prompt or add additional context before bulk submitting predictions to a model. Simply edit the text in the ‘Prompt’ text box or provide a custom prompt. For example, you can add more context in the prompt or provide an example in the ‘Examples’ section of the prompt template to help the model better understand the task at hand.
Compare and evaluate the effectiveness of different prompts
Comparing and evaluating the results of different prompts is essential to fine-tune your approach and improve the performance of your model. Not only can you compare how different models perform based on the same prompt, but you can also compare and evaluate how different prompts affect a model’s performance. You can also modify the hyperparameters of the chosen model if you don’t want to use the default hyperparameters.
See it in action:
Movie plot sentiment analysis and genre classification
To provide an enhanced user experience or to help with better catalog curation, a streaming company may want an AI-powered solution to help classify various movies into specific genres for a recommendation engine. You can easily harness GPT-4 in Model Foundry to help with automatic movie plot and genre classification.
Demo on how to use GPT-4 in Model Foundry for movie plot sentiment analysis and classification.
Select data of interest: After selecting a subset of text data, such as from the Kaggle Wikipedia Movie Plots dataset, select GPT-4 from available models in the Model Foundry.
Select an ontology and a prompt: As GPT-4 takes natural language as the Prompt input and provides flexibility in prediction classes, it requires a user-defined ontology. As we are interested in the classification and summarization of movie genres and plot, we can map this to my ontology containing ‘movie_genre’ and ‘summary’ classifications.
Providing an ontology will automatically populate the ‘Prompt’ box with a template according to your goal and will ask the model to return it in a structured format so that it can be integrated into a downstream workflow. If you wish to make modifications to the prompt, you can do so directly in the ‘Prompt’ text box.
Generate an example output: Clicking 'Generate example' will populate an example template that you can fill in to demonstrate the desired response and guide GPT-4.
Preview predictions: Click ‘Generate preview’ to understand how your current settings affect final predictions. You can generate previews to confirm your prompt and settings or make any necessary changes to improve desired performance and generate a new set of predictions.
Submit a model run: Once you’re happy with the preview predictions, you can name and submit the model run to view predictions on all selected data.
Send predictions as pre-labels to a labeling project: From there, you can filter by the model run in Catalog and submit the model predictions as pre-labels to a labeling project (the labeling project must contain the same ontology as the model run).
Product categorization
As the amount of data available in retail and eCommerce continues to increase, GPT-4 and Model Foundry provide a means to quickly generate pre-labels across a product catalog. By generating a prompt that maps to identify key product categories and provide a short description of the product, you can effectively assign predictions as pre-labels and leverage it as a basis for building AI applications such as a product recommendation system.
Demo video on how to use GPT-4 in Model Foundry for a product categorization use case.
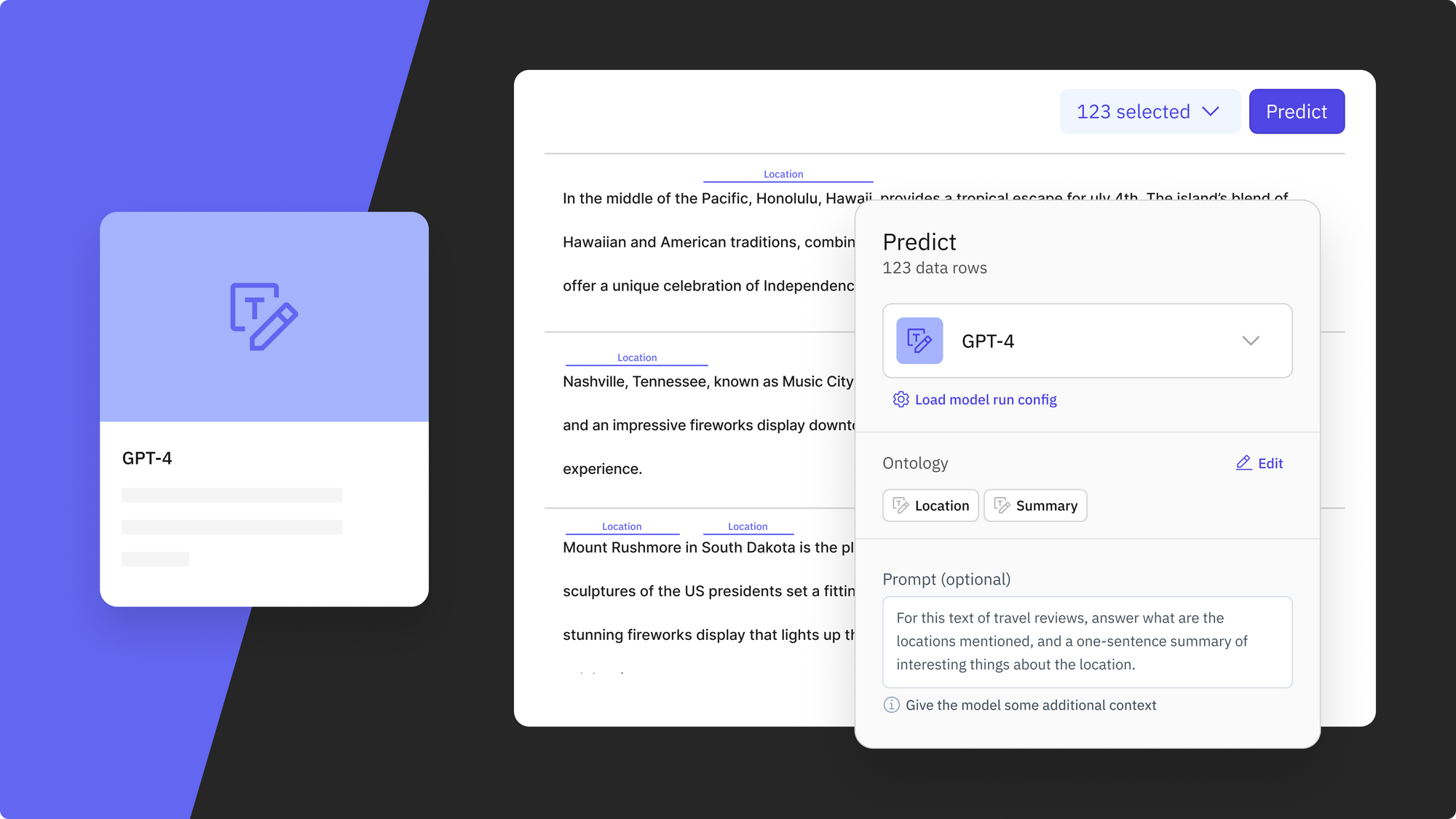
Travel review classification
Classifying travel reviews can be pivotal for businesses in the travel and hospitality industry. By prompting GPT-4 to help classify travel reviews into categories such as positive, negative, or neutral, and segmenting them based on accommodations or locations, businesses can gain actionable insights into customer experiences.
Demo video on how to use GPT-4 in Model Foundry to classify various travel reviews.
Tweet sentiment analysis
Analyzing the sentiment of tweets can hold immense value for companies to understand consumer behavior and insight. For example, media companies can effectively categorize tweet sentiments related to their content, news stories, or trending topics. By crafting prompts that guide the model to identify positive, negative, or neutral sentiments within tweet content, the team can efficiently categorize public reactions and leverage predictions as pre-labels in training their model.
Demo video on how to use GPT-4 in Model Foundry for sentiment analysis and categorization of tweets.
To learn more about how enterprise AI teams can leverage LLMs like GPT-4 to accelerate their AI development, read this post. Learn more about Model Foundry and sign up for the beta-release waitlist below.


