
 All blog posts
All blog postsLabelbox•January 31, 2023
Introducing natural language querying, a new navigation experience, and more
This month, we released several updates that help you explore and make sense of your data, better navigate our platform, and easily debug model errors. From introducing natural language querying to an updated navigation experience, we're focused on helping you solve your AI and data problems. Read on to learn more about the newest features and capabilities in Labelbox.
Explore and make sense of your data
Searching for and understanding data can be challenging for even the most advanced AI teams. You can leverage Labelbox Catalog to extract key insights from your data or to curate specific slices of data to improve or train you model.
ML use cases can be niche and often require training your model on specific data in order to improve model performance or inform critical next steps. With Catalog, you can search, visualize, and make sense of the right information.
In beta: Surface data in seconds with natural language querying
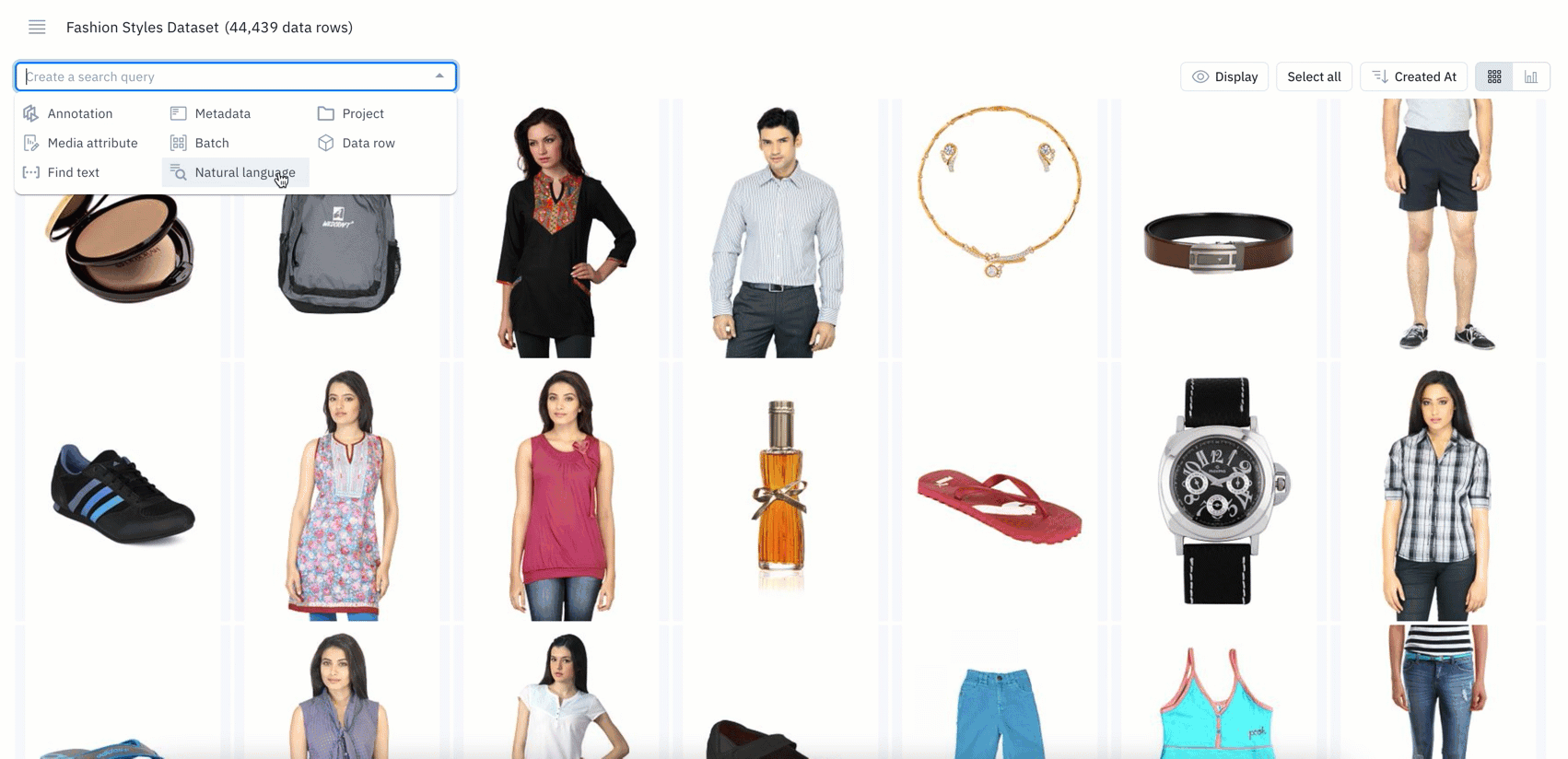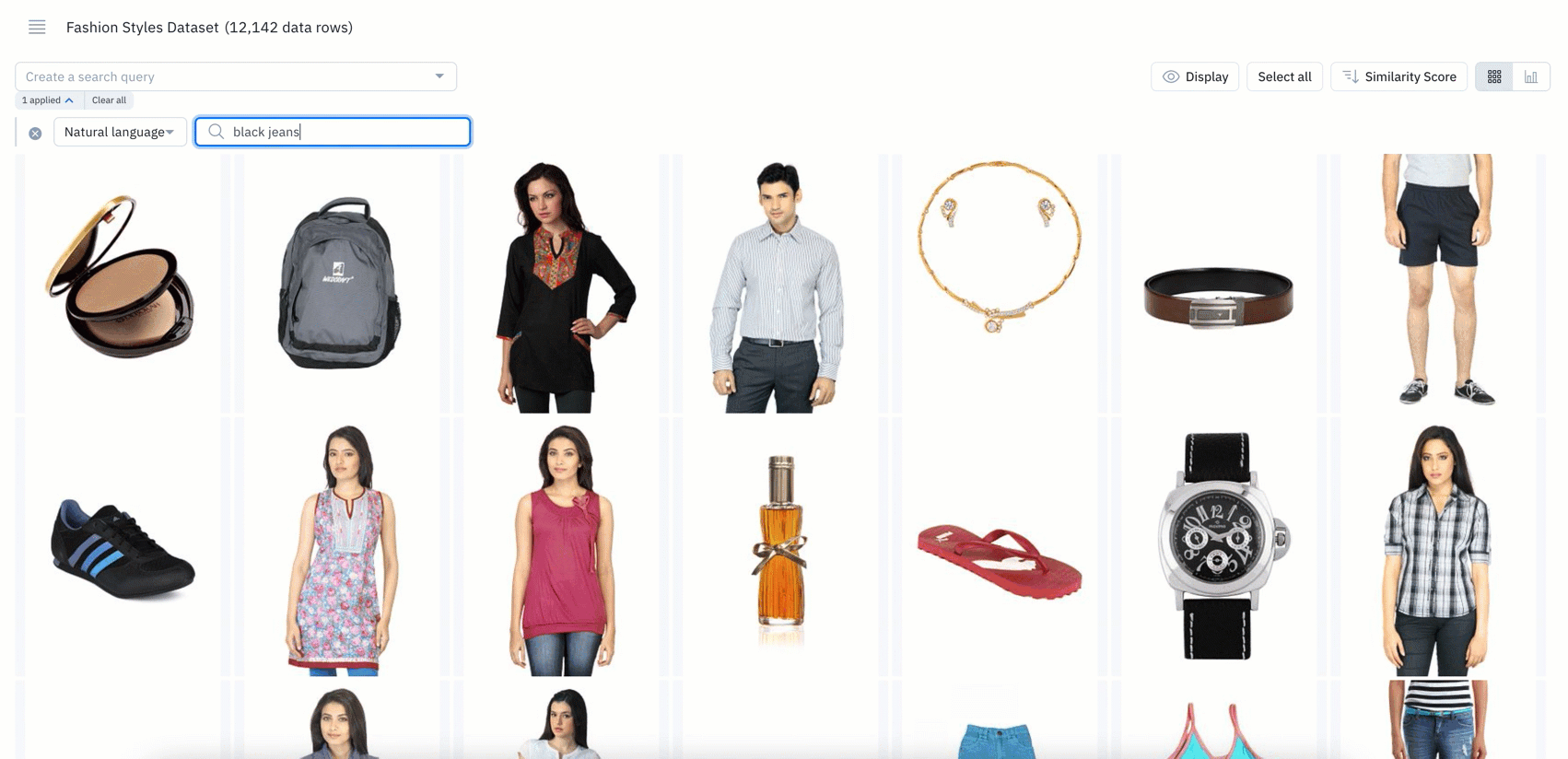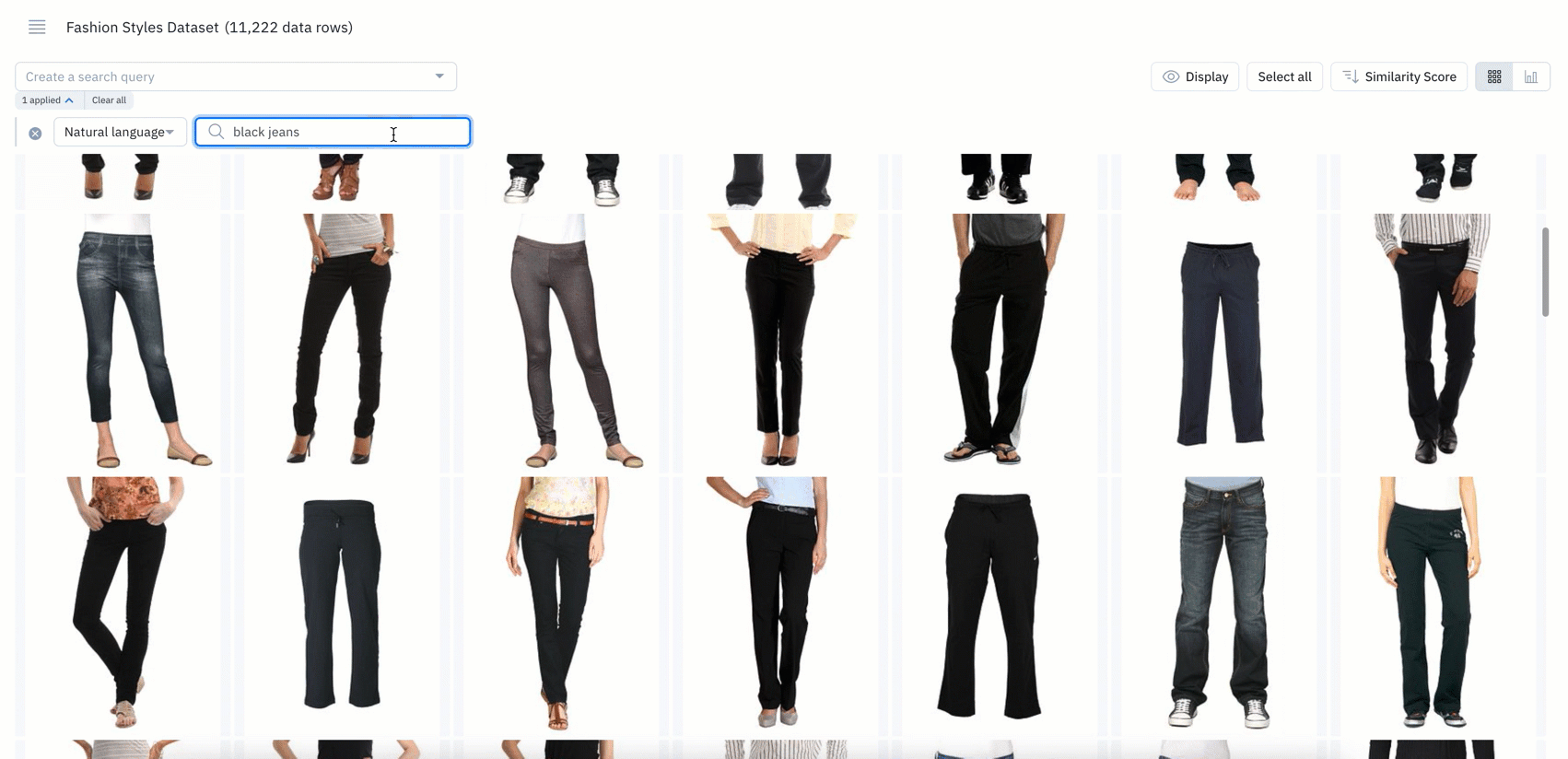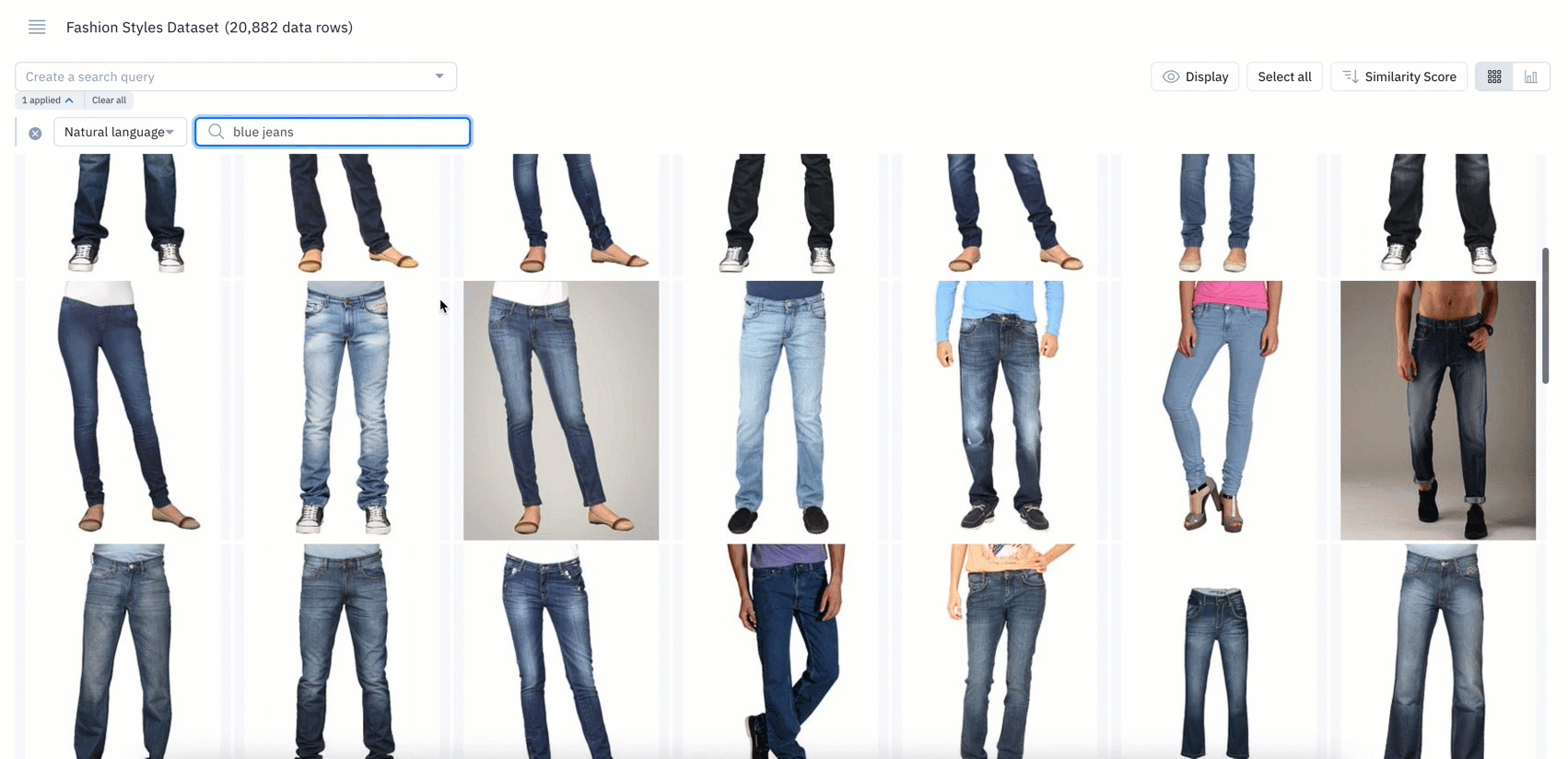
- Natural language search refers to using a natural language, such as English, to query a database with a phrase or word that describes the information you’re looking for
- If you’re a current Labelbox user, you can now use natural language to query and surface specific data rows
- Powered by CLIP embeddings, you can leverage natural language search on images, tiled imagery, and on the first page of PDF documents
- Simply type an English text query, such as “blue jeans" or "black jeans", to quickly bring up all instances of images that match the particular phrase or word
In beta: Search for specific phrases or words among your text data
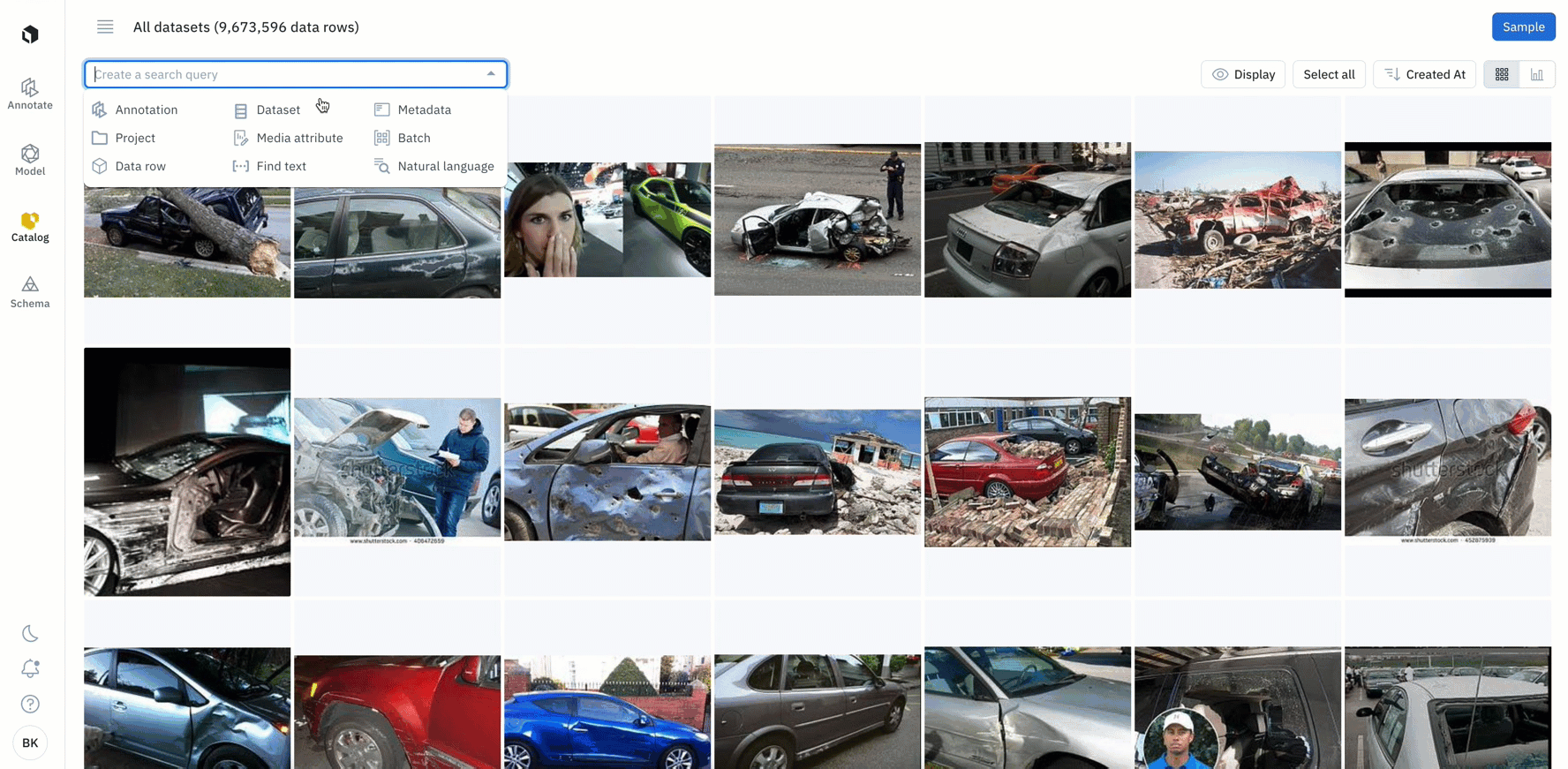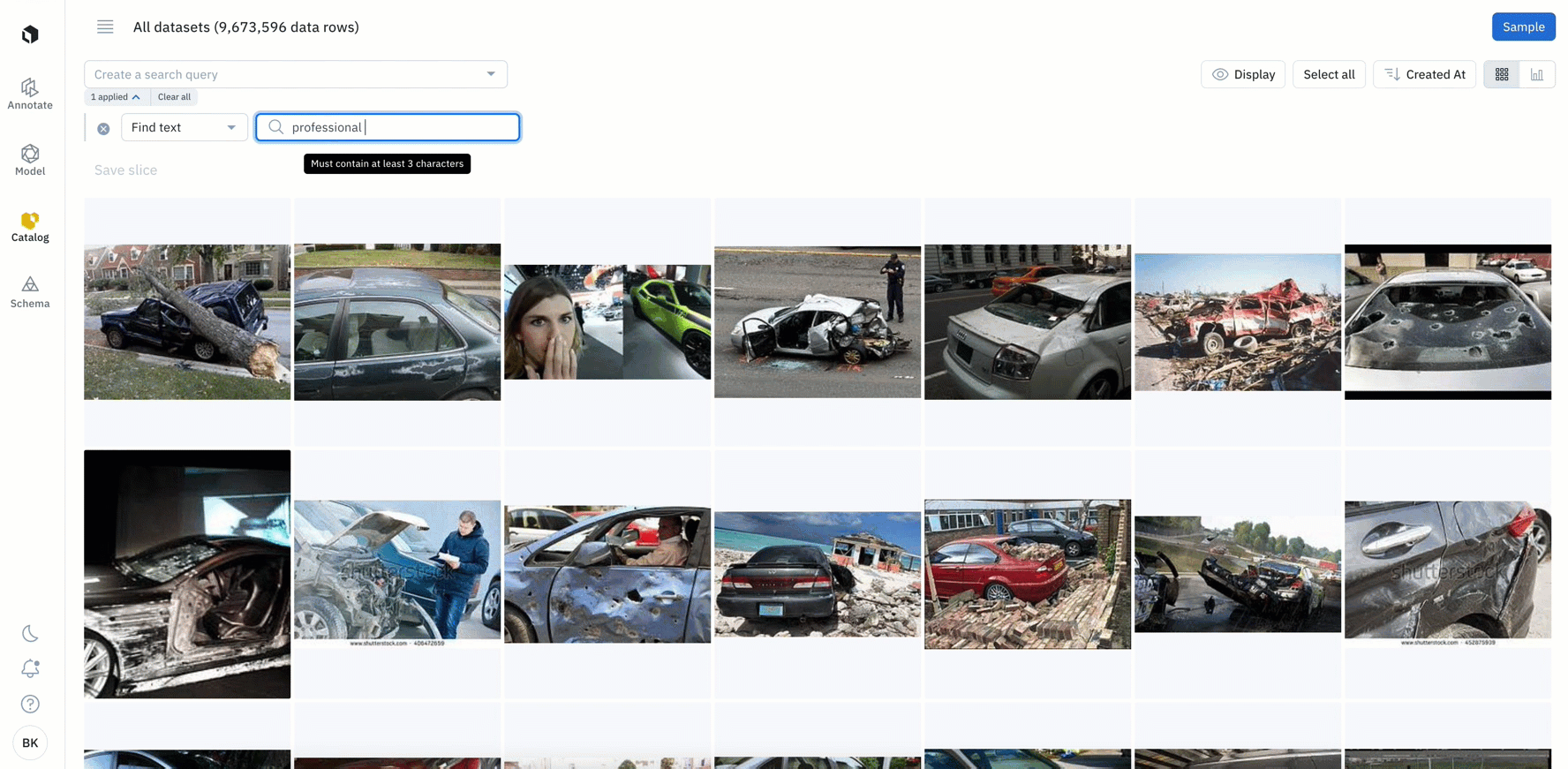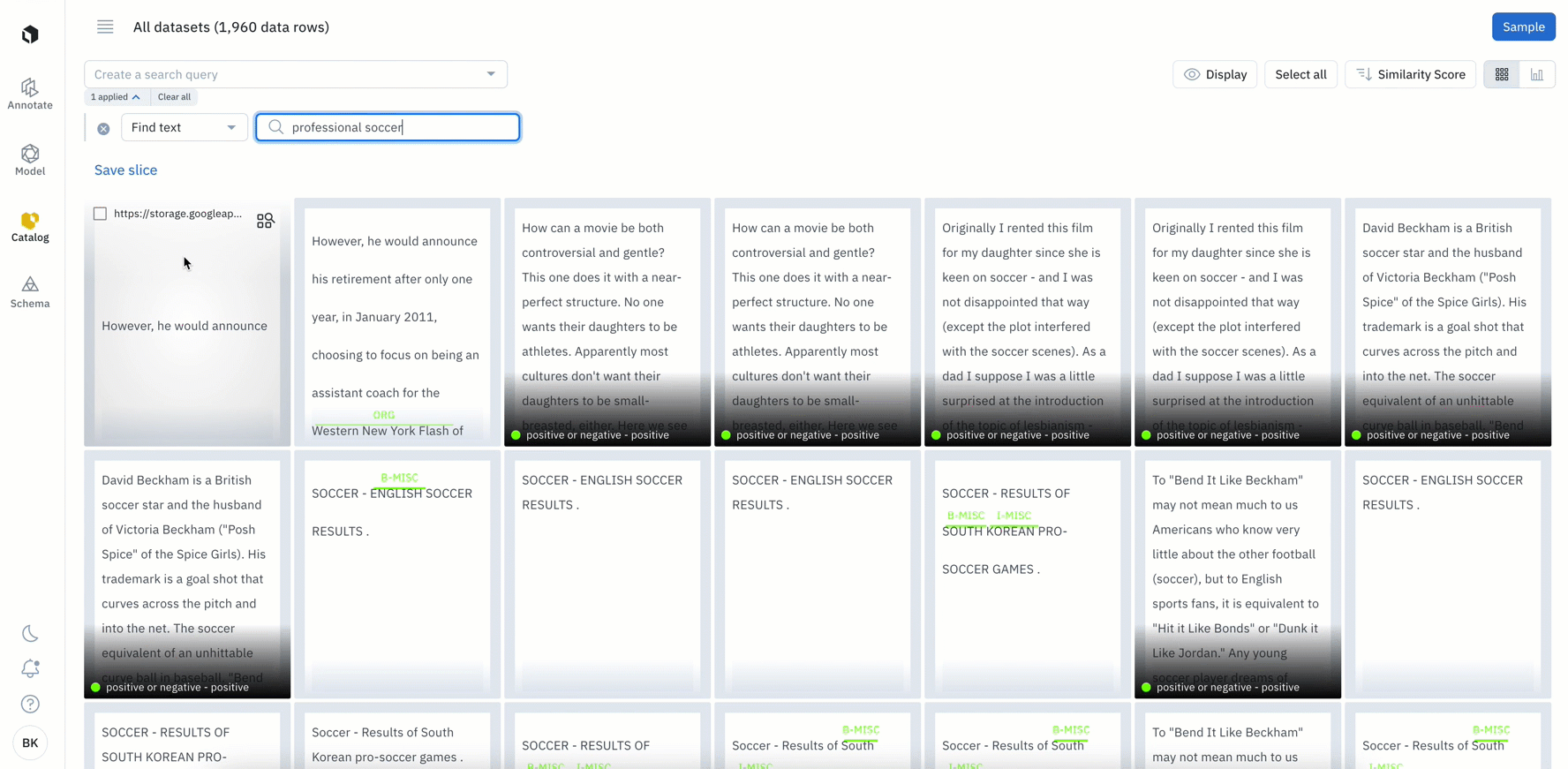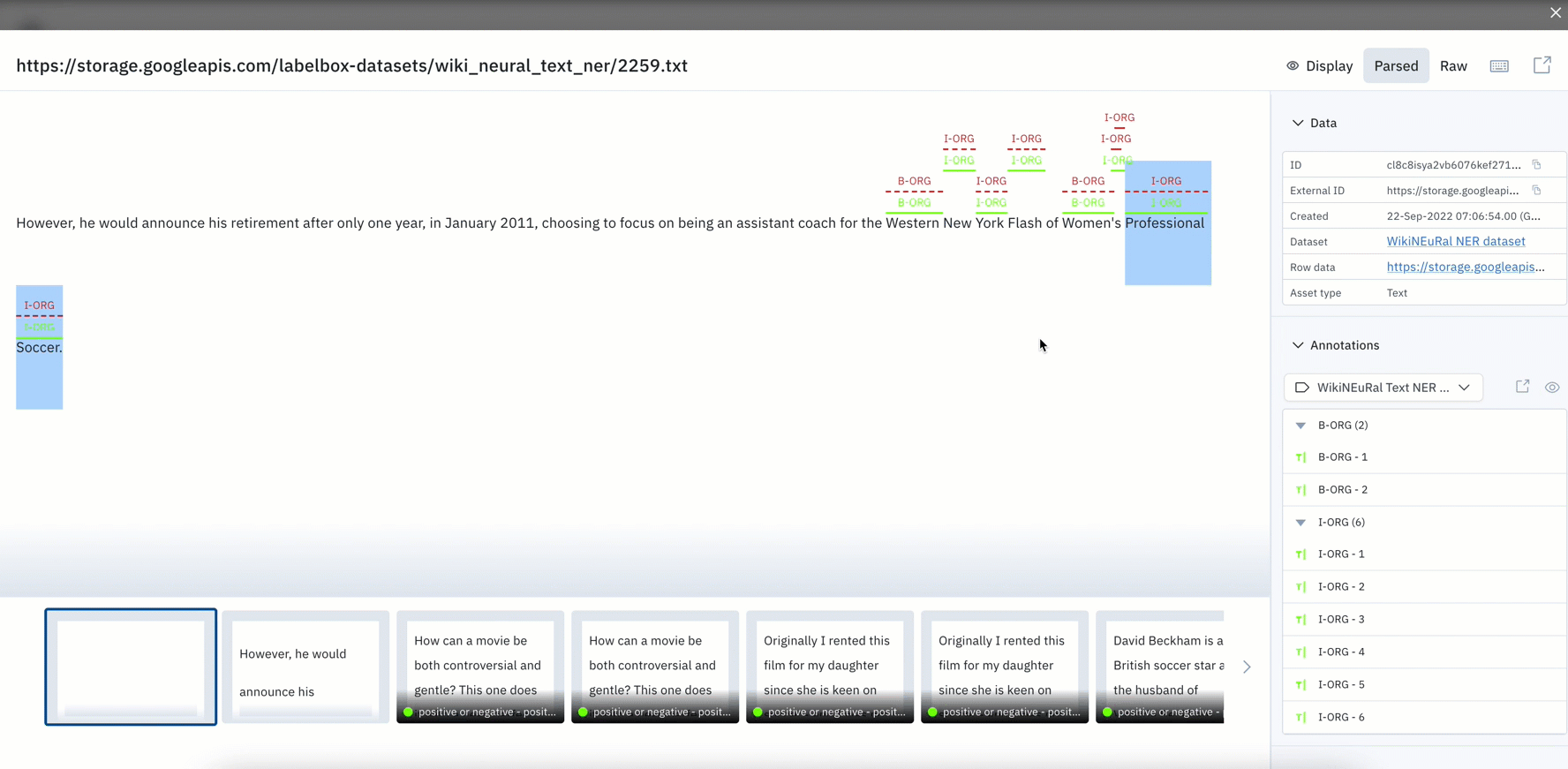
- If you have text data, you can leverage a new filter that surfaces both exact and partial matches to the inputted text
- With the ability to add text of up to 100 characters or 10 words, you can search for specific keywords within your text data
- While this is currently only supported for raw text files, we’ll be introducing support for HTML, conversational text data, and PDFs in the coming weeks
Combine multiple filters for more granular searches
Rather than searching for data with one filter or on one dimension, you can layer multiple filters to search across your database – learn more about all available filters in Catalog here.
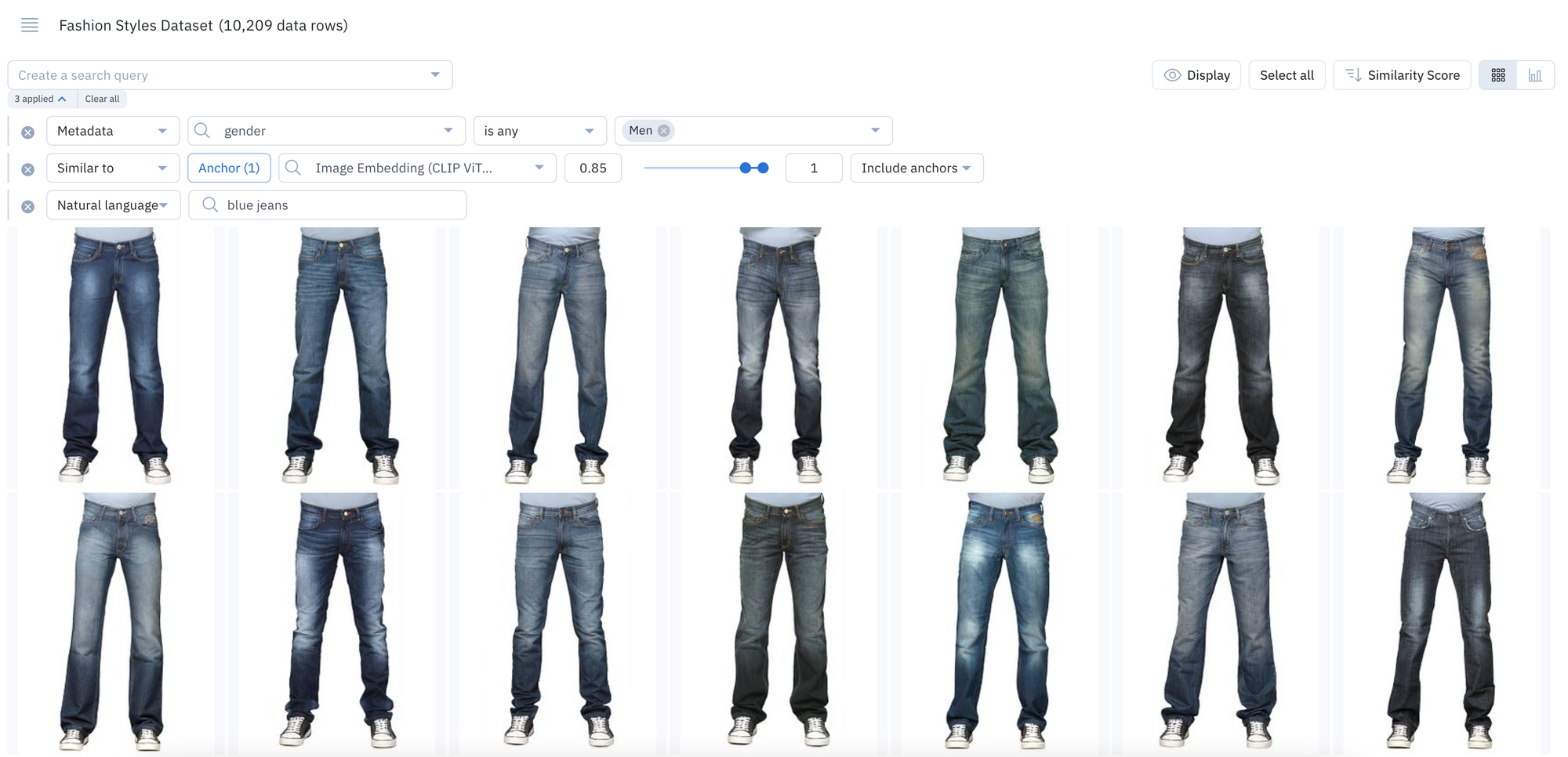
- For teams with millions of data rows across numerous projects, these filtering capabilities (natural language search, metadata, similarity search, etc.) provide a precise method of narrowing and refining your unstructured data at scale
- For example, you can conduct a natural language search, find all instances of similar data, search for a specific metadata tag, and more in one single query
Save and revisit searches
Once you’ve surfaced specific data through a query using filters or with similarity search, you can save your search as a slice. This allows you to easily revisit all current and incoming data that match the saved search criteria.
If you’re a current Labelbox user, you can conduct complex searches in Catalog by leveraging natural language querying, text search, and more. If you don’t yet have data uploaded in Labelbox, get started by uploading your first dataset.
Navigate Labelbox with less friction
A faster navigation experience and improved notifications layout
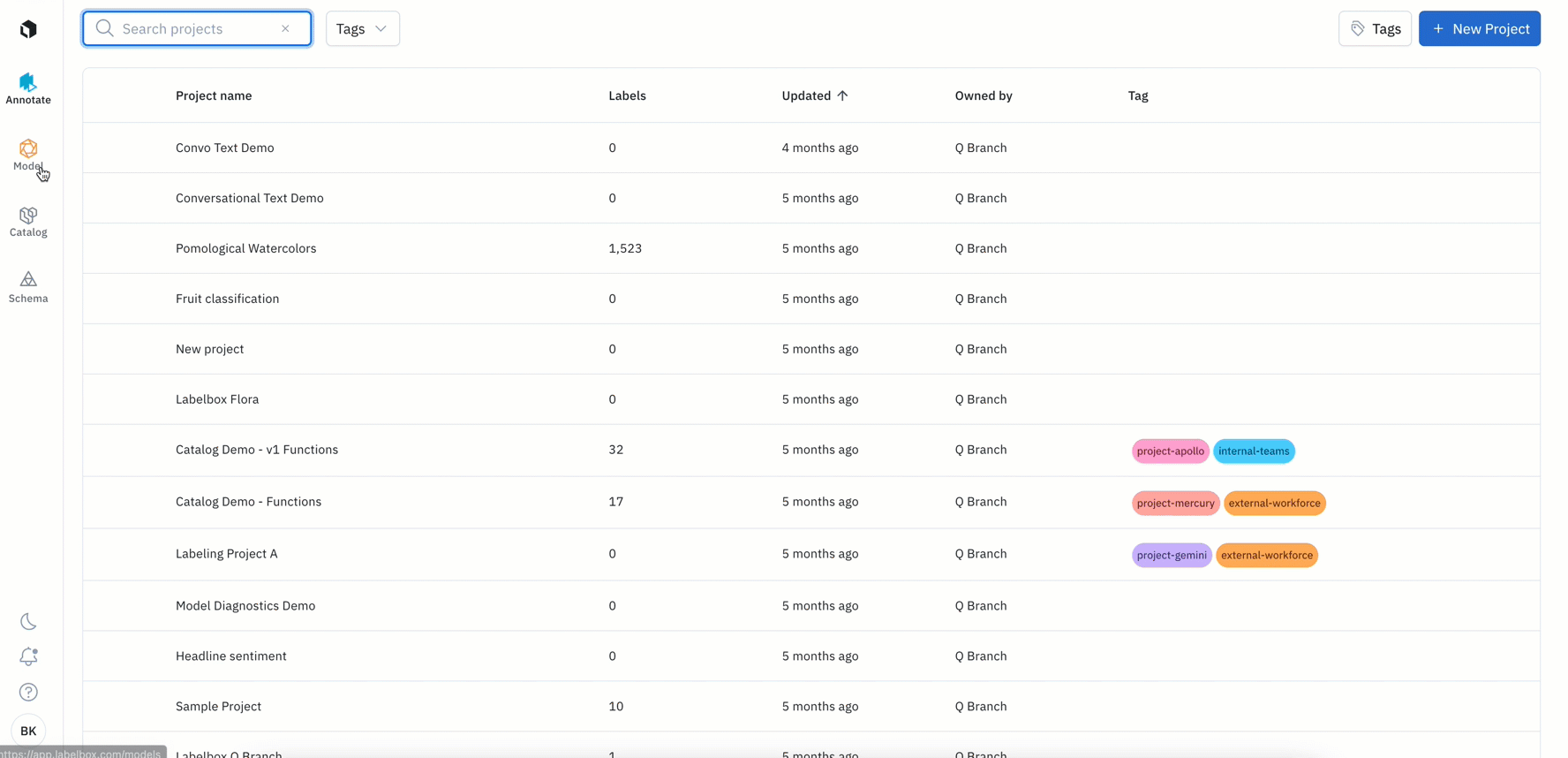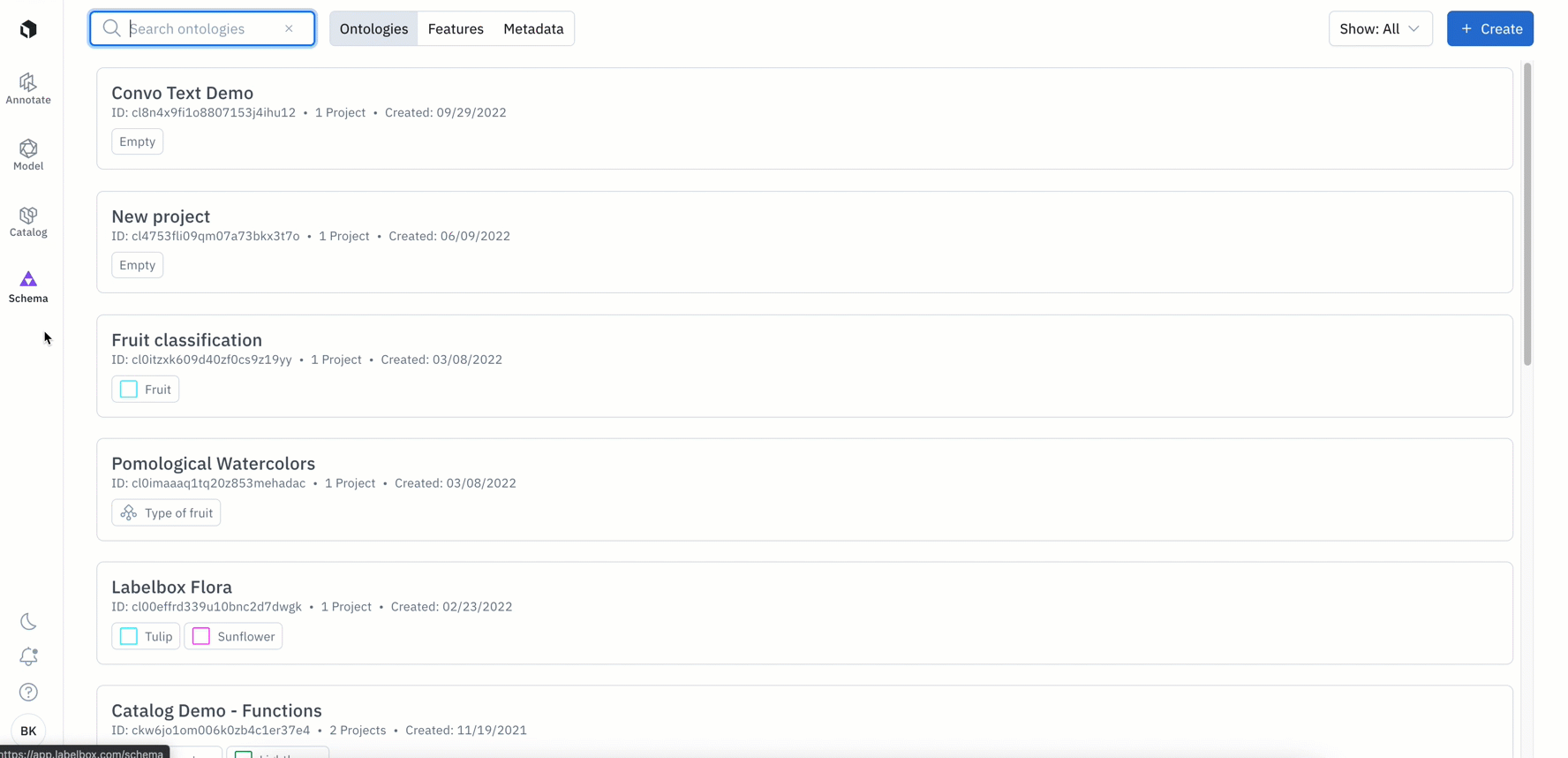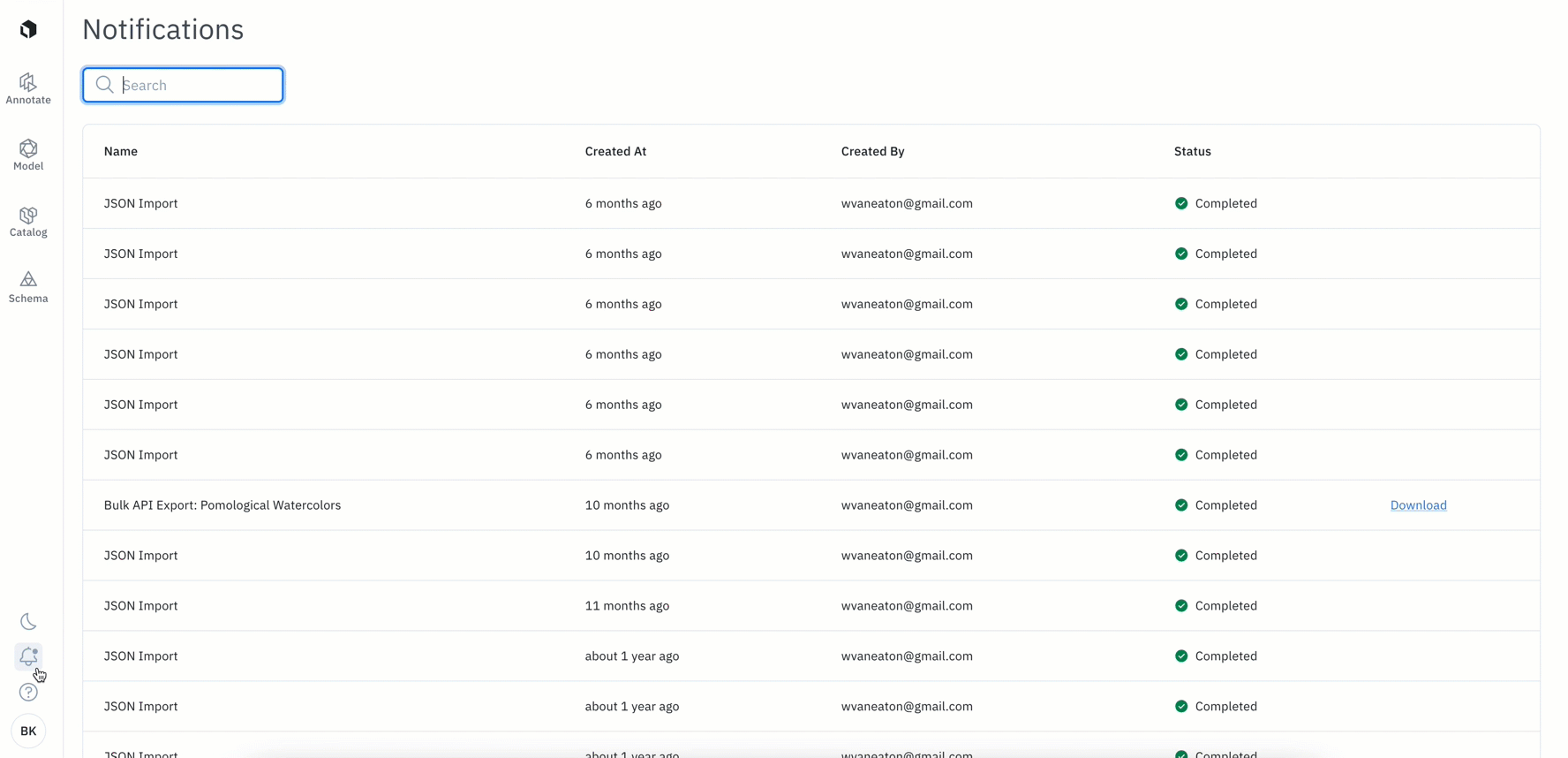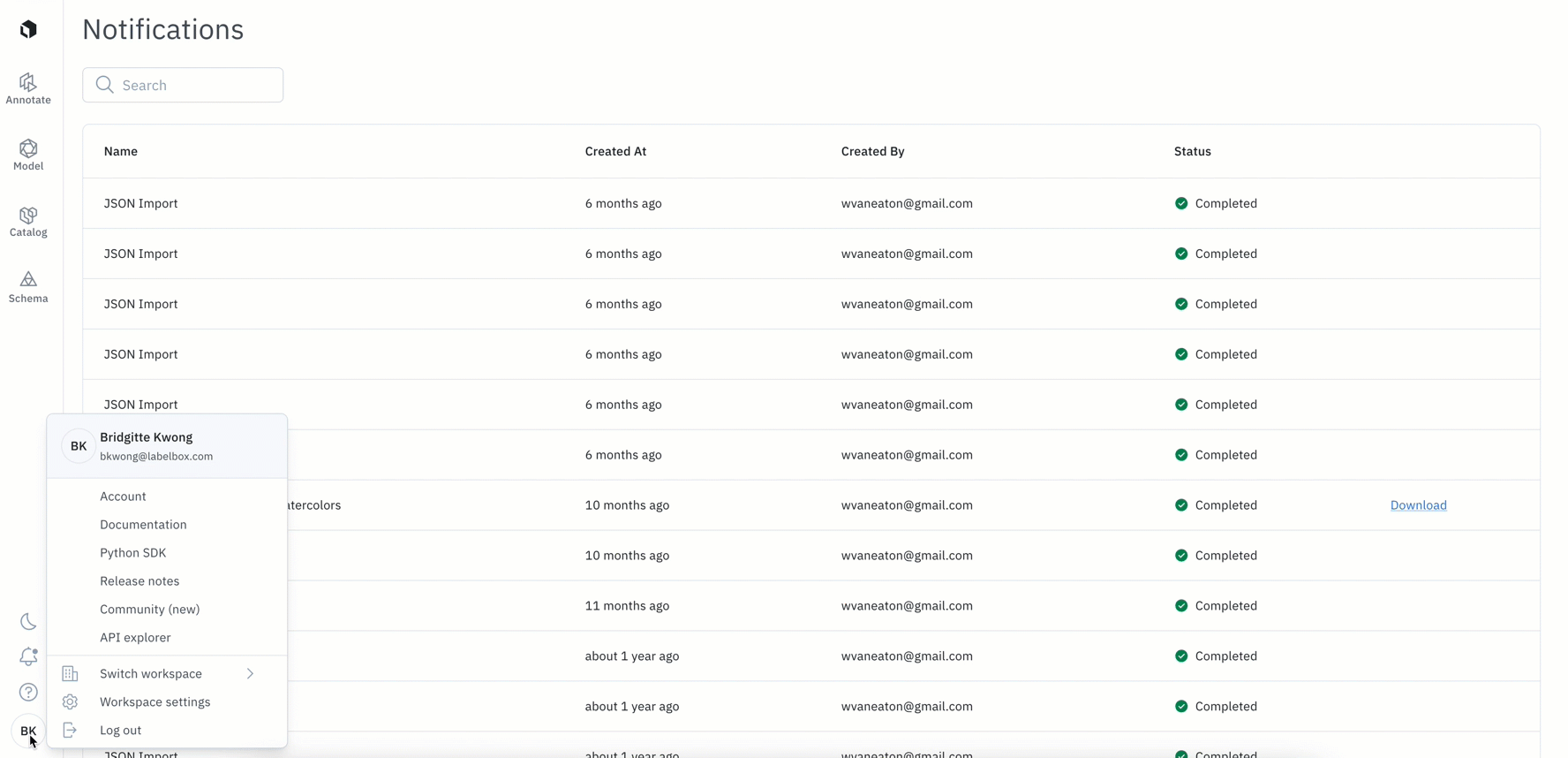
Introducing a refreshed Labelbox app experience with the navigation panel moving to left side of the screen:
- Scan vertically to navigate and quickly access different parts of the Labelbox app, including: the Annotate, Model, Catalog, and Schema tabs, as well as dark mode, notifications, the help center, and your account settings
- With this new vertical layout, you can better visualize your data rows and projects with more screen real-estate
- You can now view all notifications in a table format, providing you with all the information you need around current and historic long running tasks (e.g import and exports)
- Surface key product information in our documentation, guides, and release notes directly through the app’s helpdesk. If you’re currently on our Free plan, you’ll also see the option to upgrade your plan, which you can do at any time
Create and reuse ontologies for your desired media type
An ontology is a critical part of a labeling team and project’s infrastructure. It is vital that ontologies are well-defined for the labeling task at hand and they should be created and managed with the goals of proper labeling, efficiency, and reusability in mind.
We’re making updates to the ontology creation process in order to help you better create and easily reuse ontologies across projects with the same data type.
How does this affect new ontology and project creation?
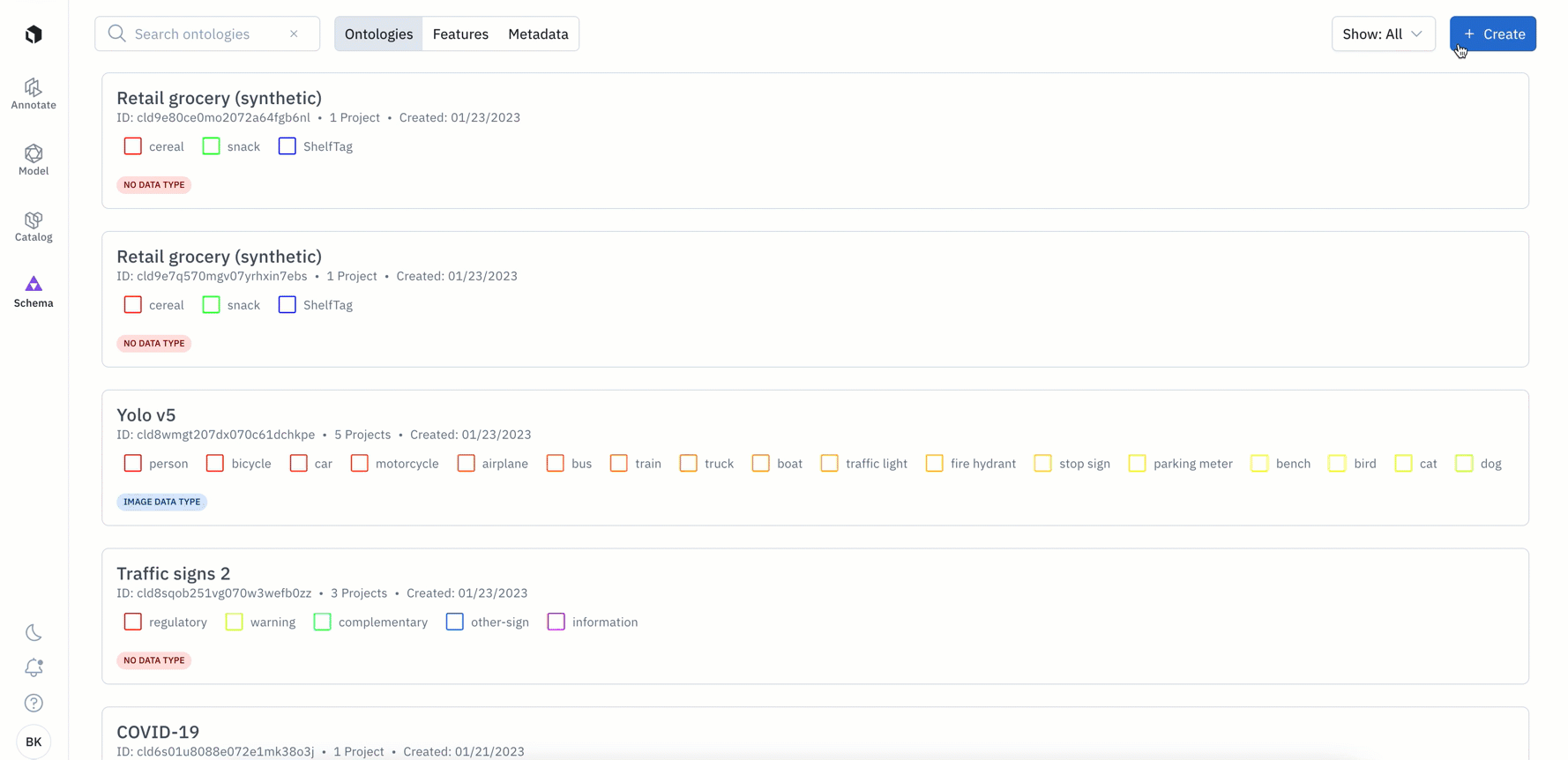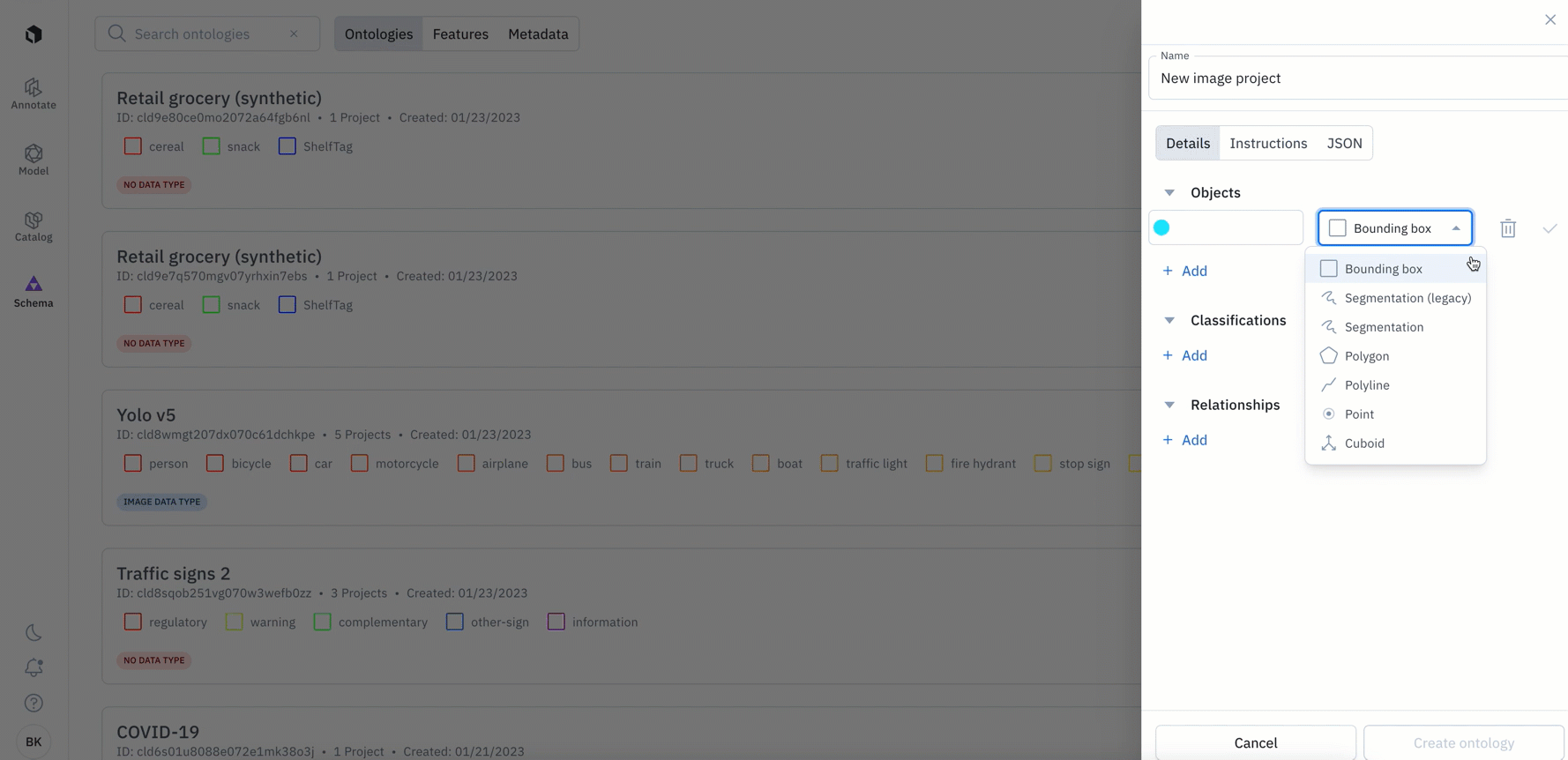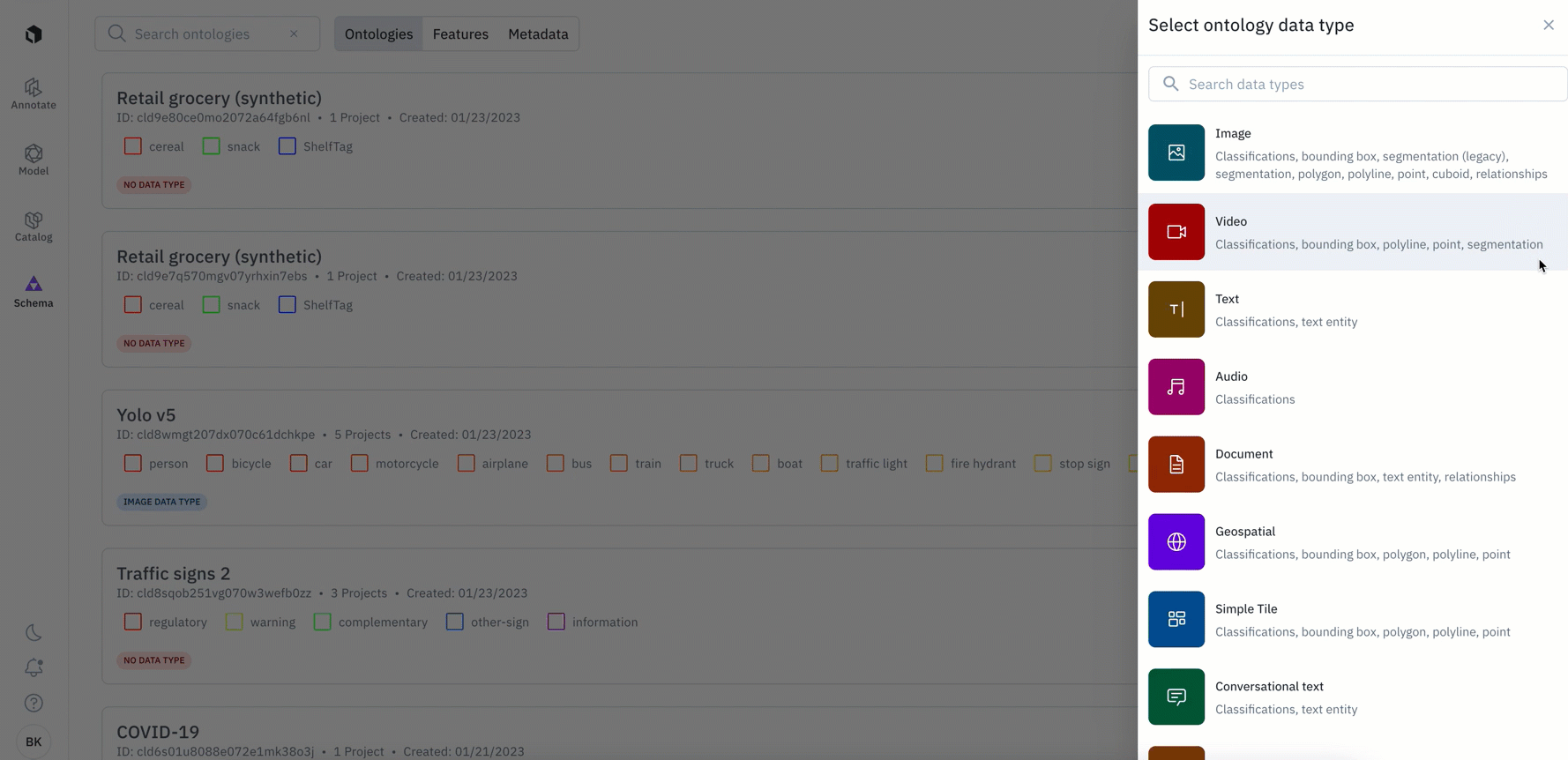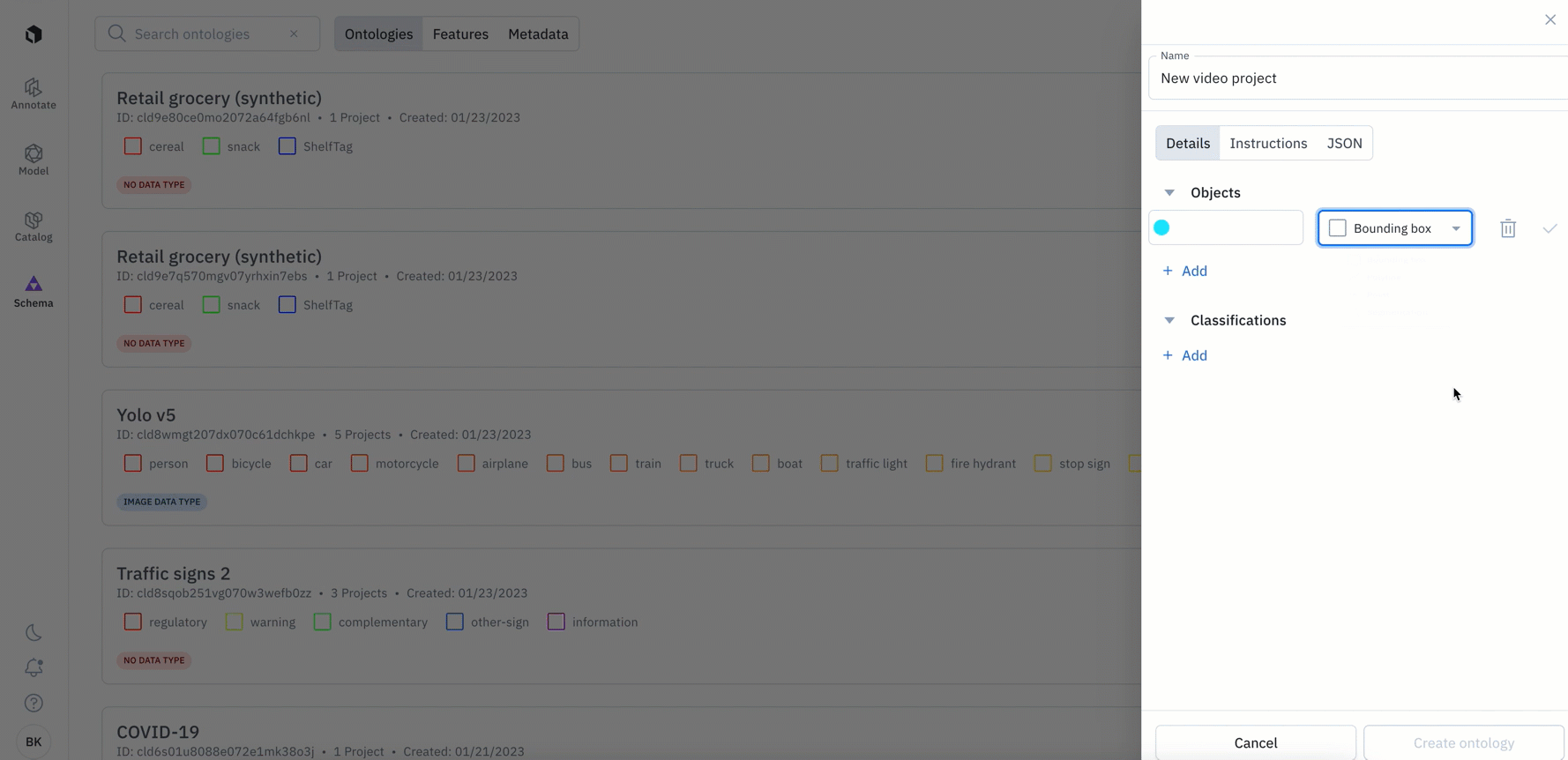
The changes below only apply to new ontologies created after January 24th:
- You’ll now be required to specify a media type when creating a new ontology through both the UI and SDK
- You’ll now only be able to view and add objects to your ontology that are available for your chosen media type (data type). For example, if you select ‘video’ as your chosen media type, you will only be see the option to add: classification, bounding box, polyline, point, and segmentation object types
- Your chosen media type cannot be edited retroactively after the ontology or project has been created
- When you create a new project, you’ll only be shown existing ontologies that match your media type. This enables you to more easily find and re-use ontologies across projects where the same type of data is being annotated
If you create an ontology through the UI:
- You can create an ontology through the UI either via the Schema tab or after selecting a media type when creating a new project
- Once you select a media type, you can create a new ontology or select an existing ontology from project settings. You will only be able to view and select the object types that are available for your media type. Similarly, you’ll only be able to add an existing ontology that matches your selected media type
- Refer to our documentation to learn more about how to create an ontology through our UI and for a list of supported media and object types
If you create an ontology through the SDK:
- Selecting a media_type will be a required field during project setup when creating a new project from the SDK starting March 31st
- Until then, to ease into this transition, we released a new version of the Python SDK on January 24th where media_type is an optional field
- If you’re creating a new ontology through the SDK, we recommend adding the media_type field to all instances where you use ‘create_ontology()’ to programmatically create ontologies via the Python SDK. After March 31st, the media_type field will be required for all new ontologies
- If you’re attaching an existing ontology to a new project through the SDK, you can query for the ontology using the name or schema ID
- Refer to our documentation to learn more about how to create an ontology through the SDK and to learn more about supported media types
What does this mean for existing or legacy ontologies?
- You will not need to update existing or legacy ontologies as the above changes will only apply to new ontologies created after January 24th
- If you wish to edit an ontology that was created before January 24th, you can still do so and add features with no limitations
If you have any questions related to this change, feel free to contact our support team.
Investigate data quality and model errors
One way to quickly improve model performance is to surface data quality issues within your existing data, including labeling mistakes or model errors. With Labelbox Model, you can discover specific subsets of data that contain these errors, and label targeted data to improve your models.
In beta: Analyze and compare model performance on metadata values
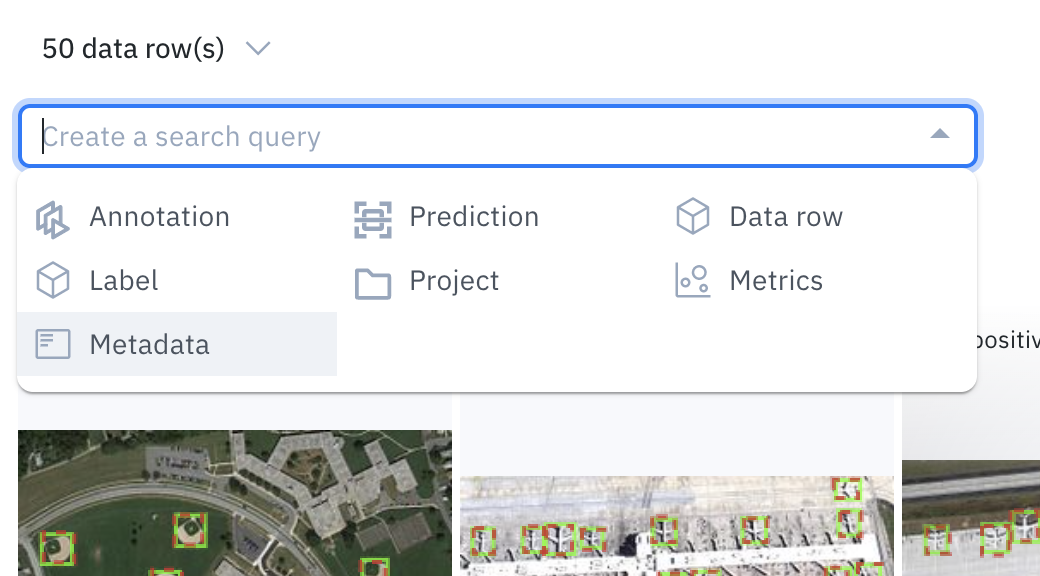
- Metadata is non-annotation information about the asset. It can be used to search and filter across your data rows in Labelbox
- You can filter by metadata in Model to analyze and compare your model performance on metadata values
In beta: Save specific data rows as slices
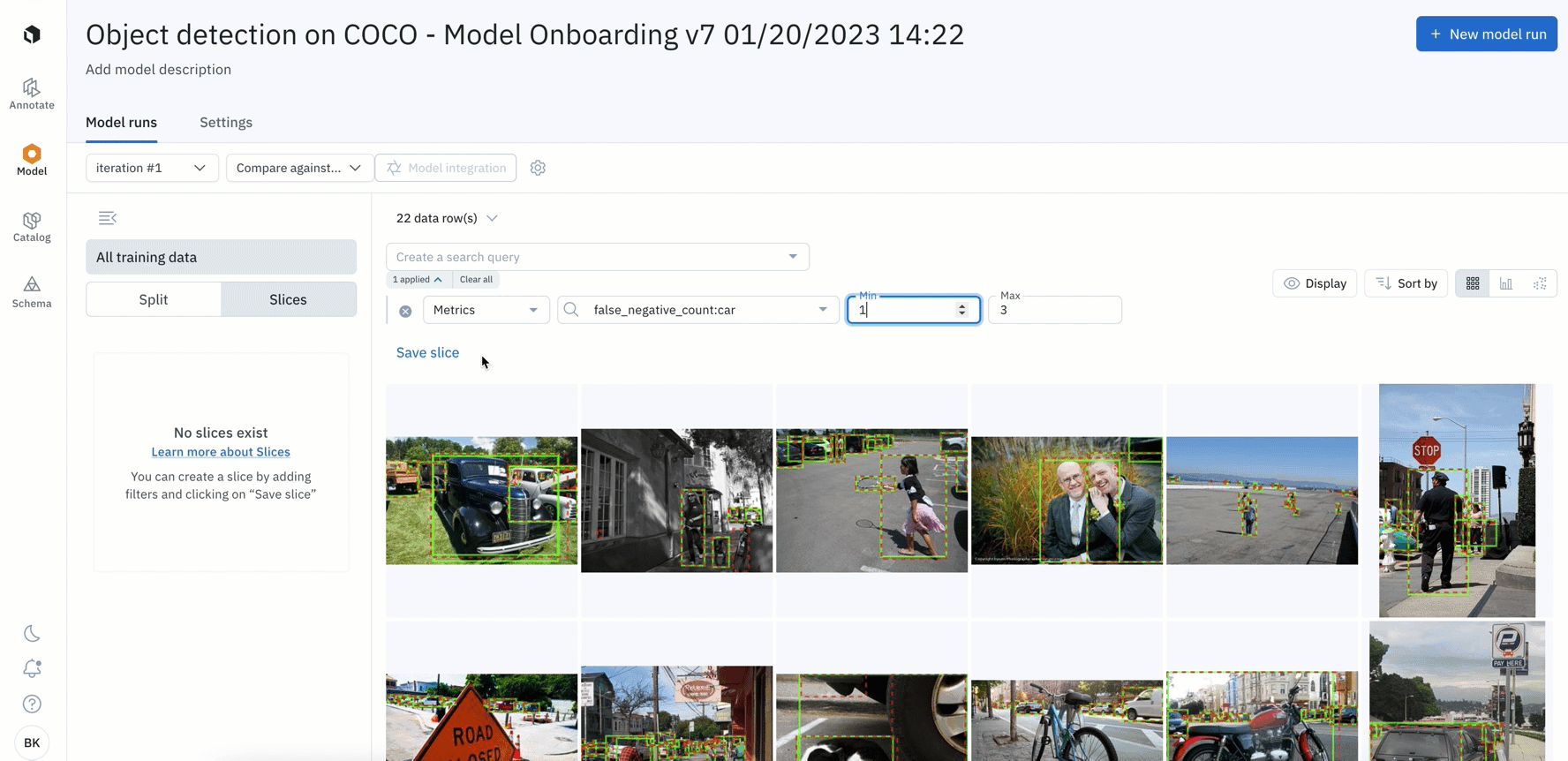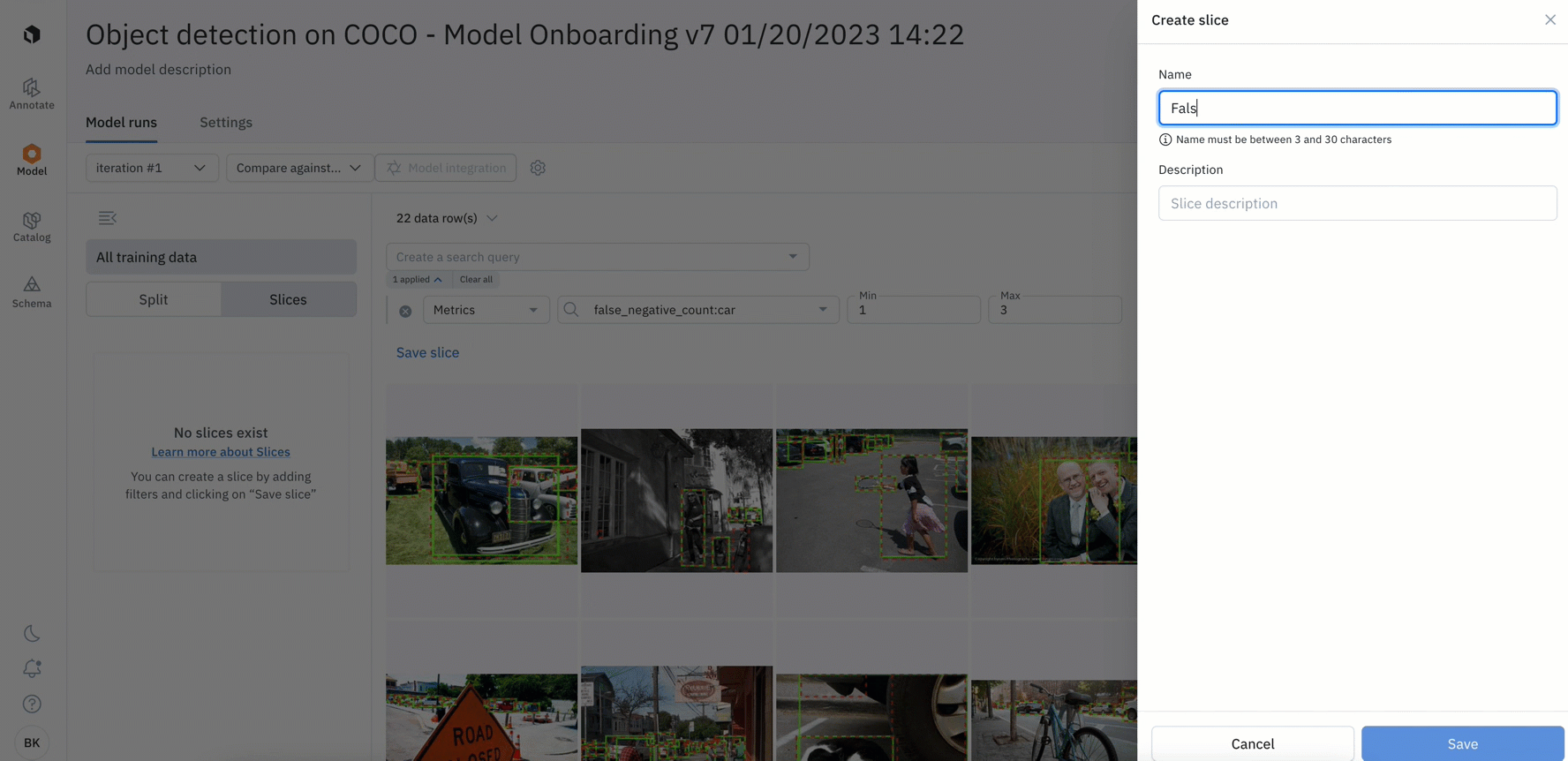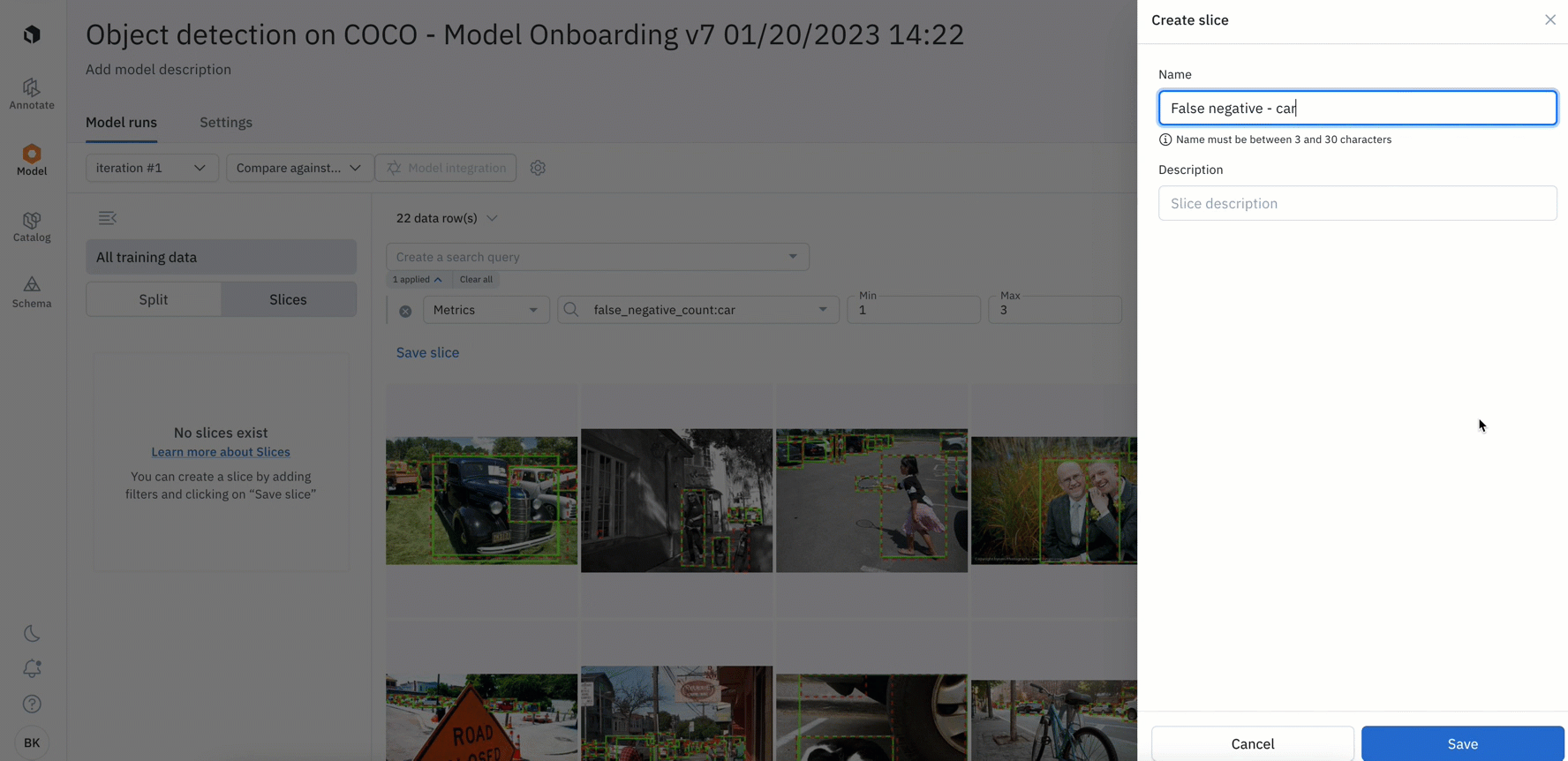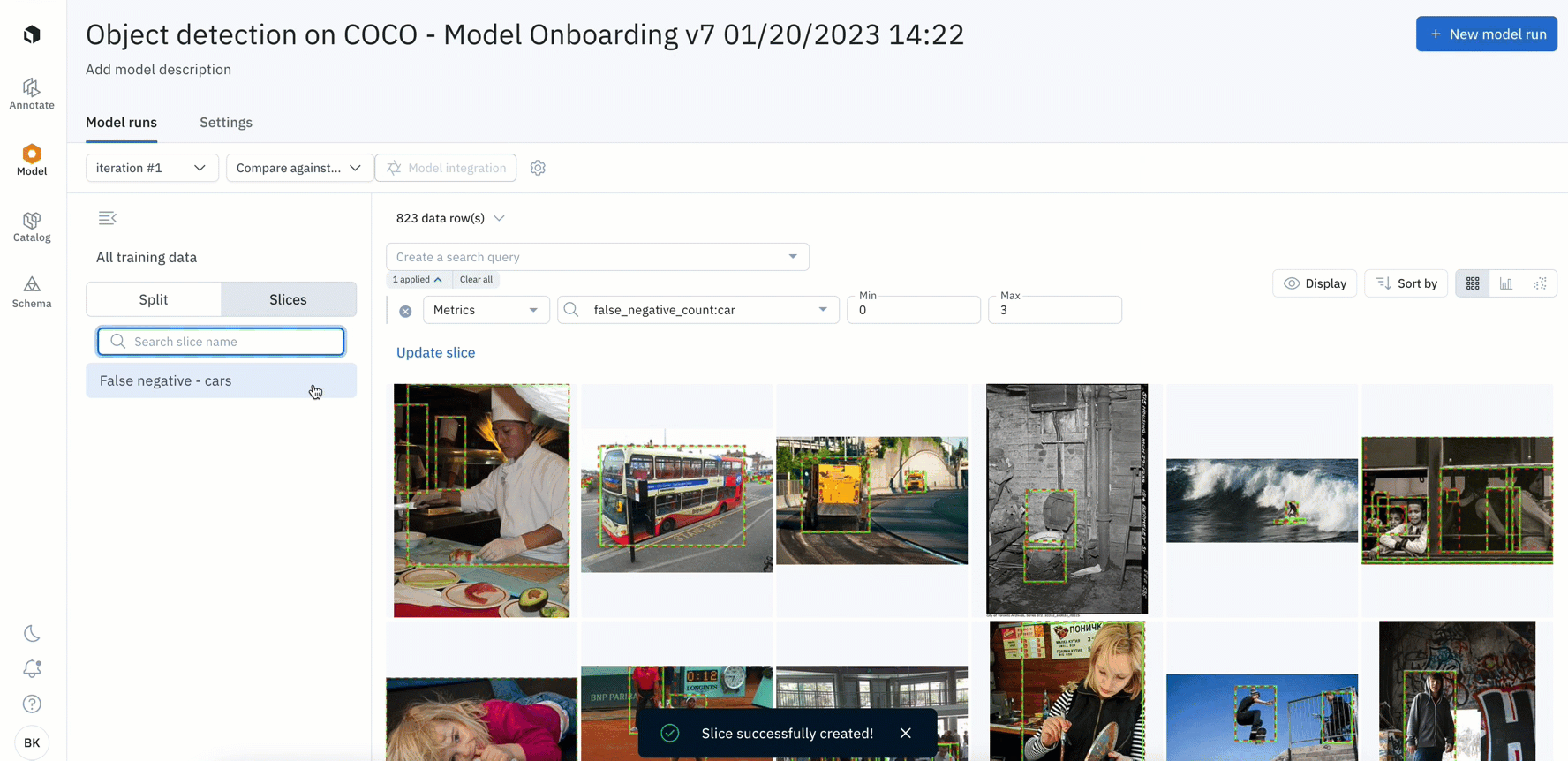
- You can analyze, test, and compare your models on specific scenarios – such as on a subset of data based on annotations, predictions, metrics, or by data row ID
- Once surfaced, you can save the subset of data rows as a slice for further analysis or to easily revisit all current and incoming data that matches the slice
Visually inspect and interpret model failures
Receive auto-generated metrics
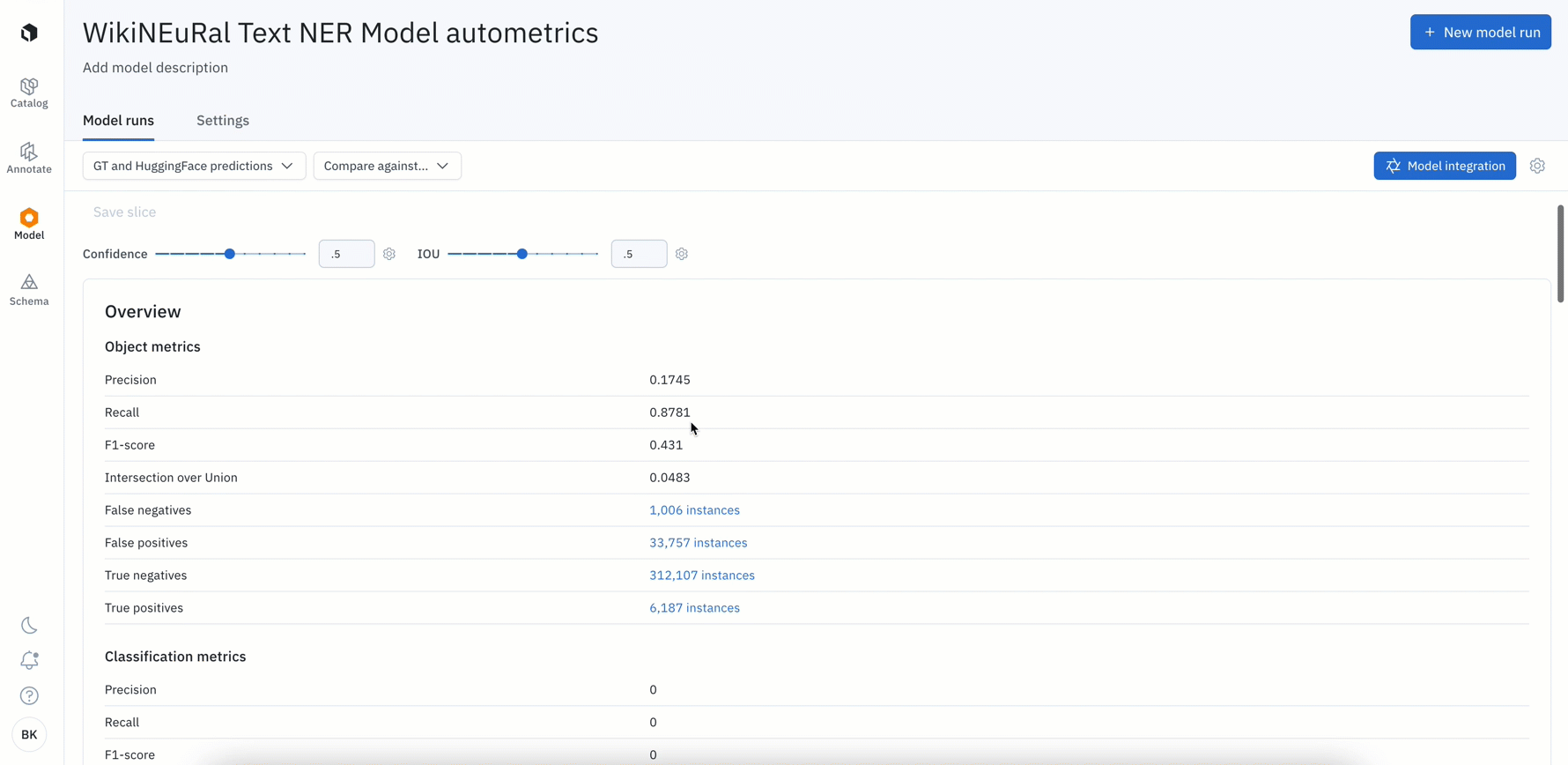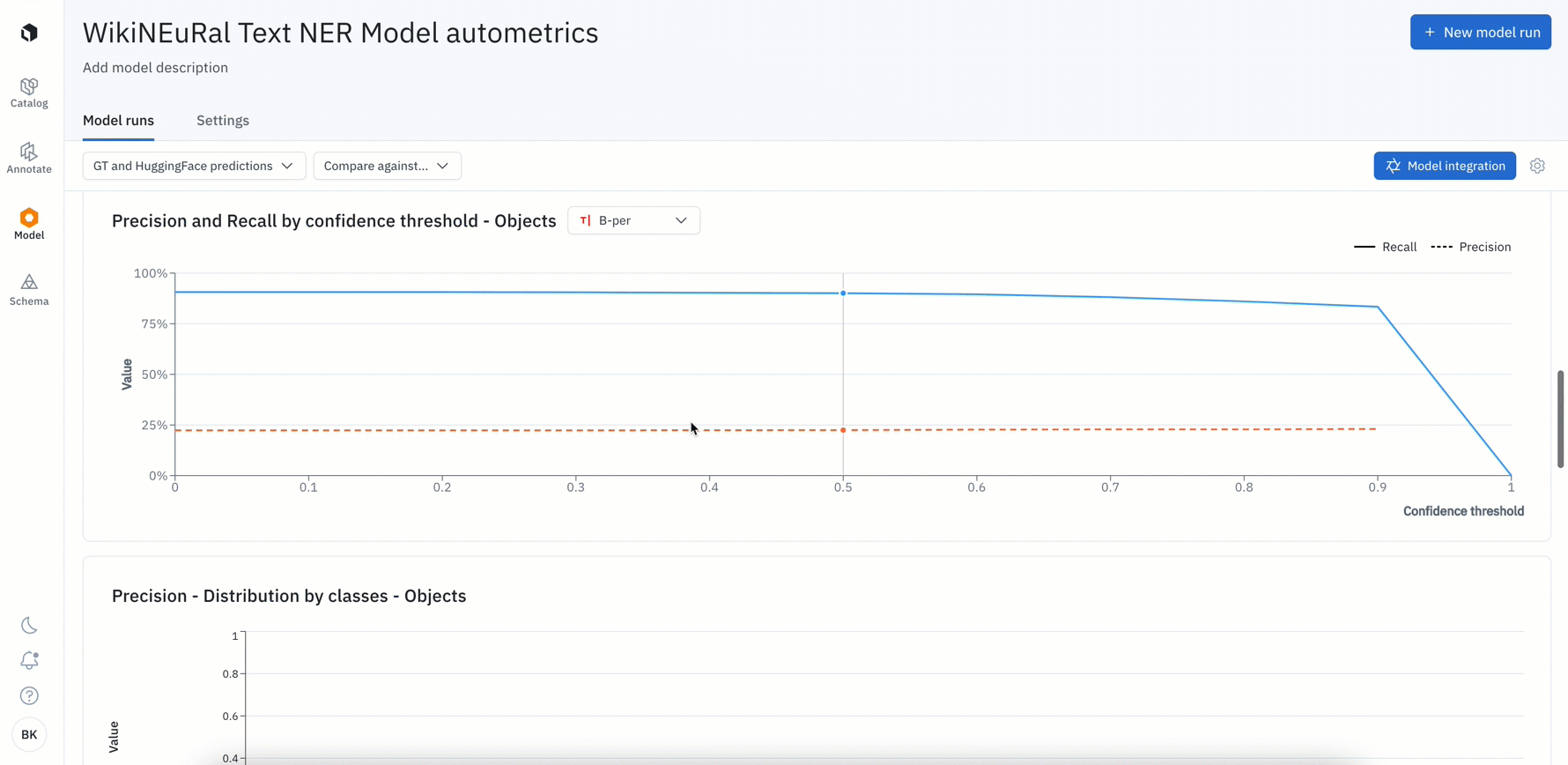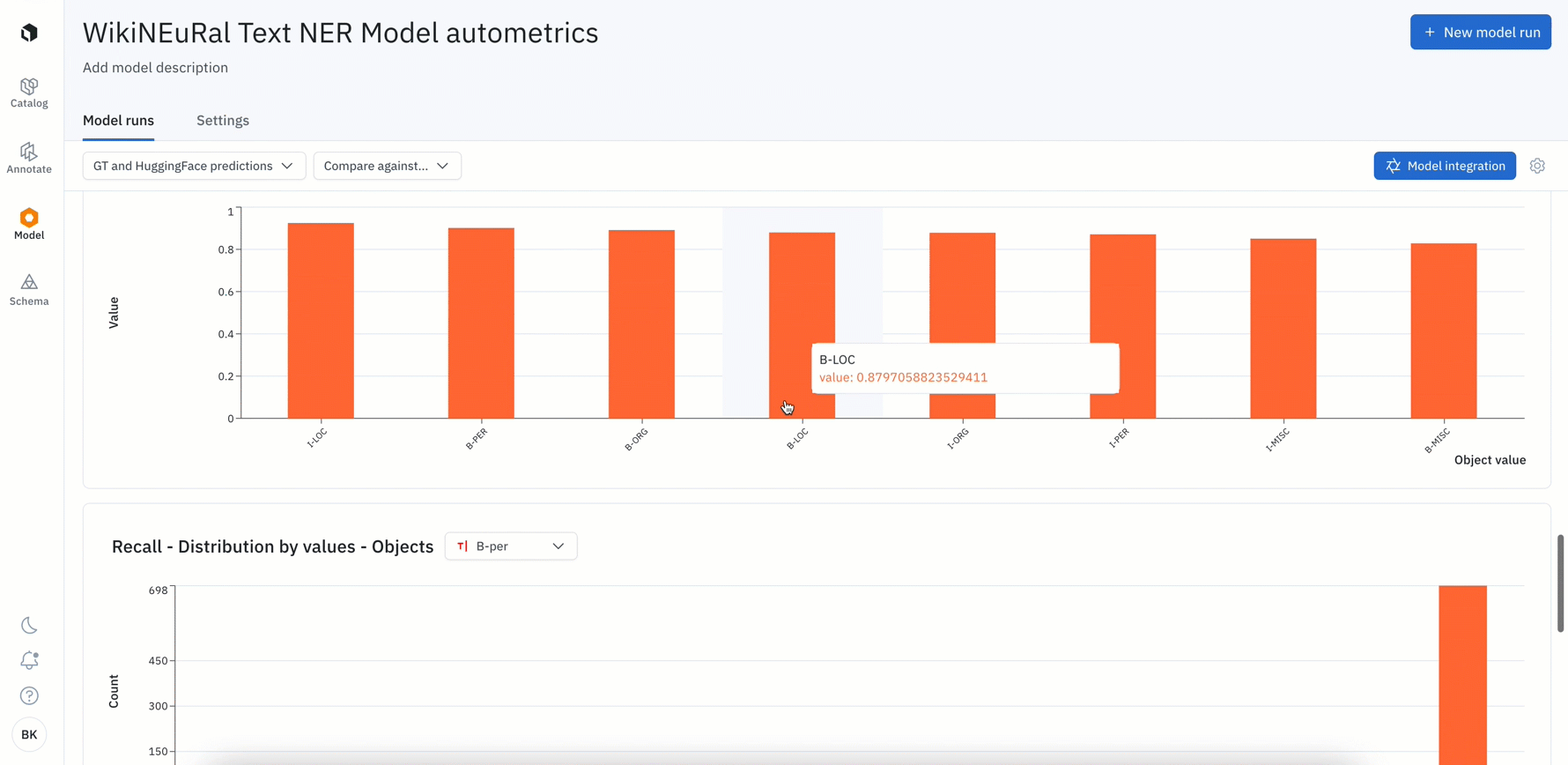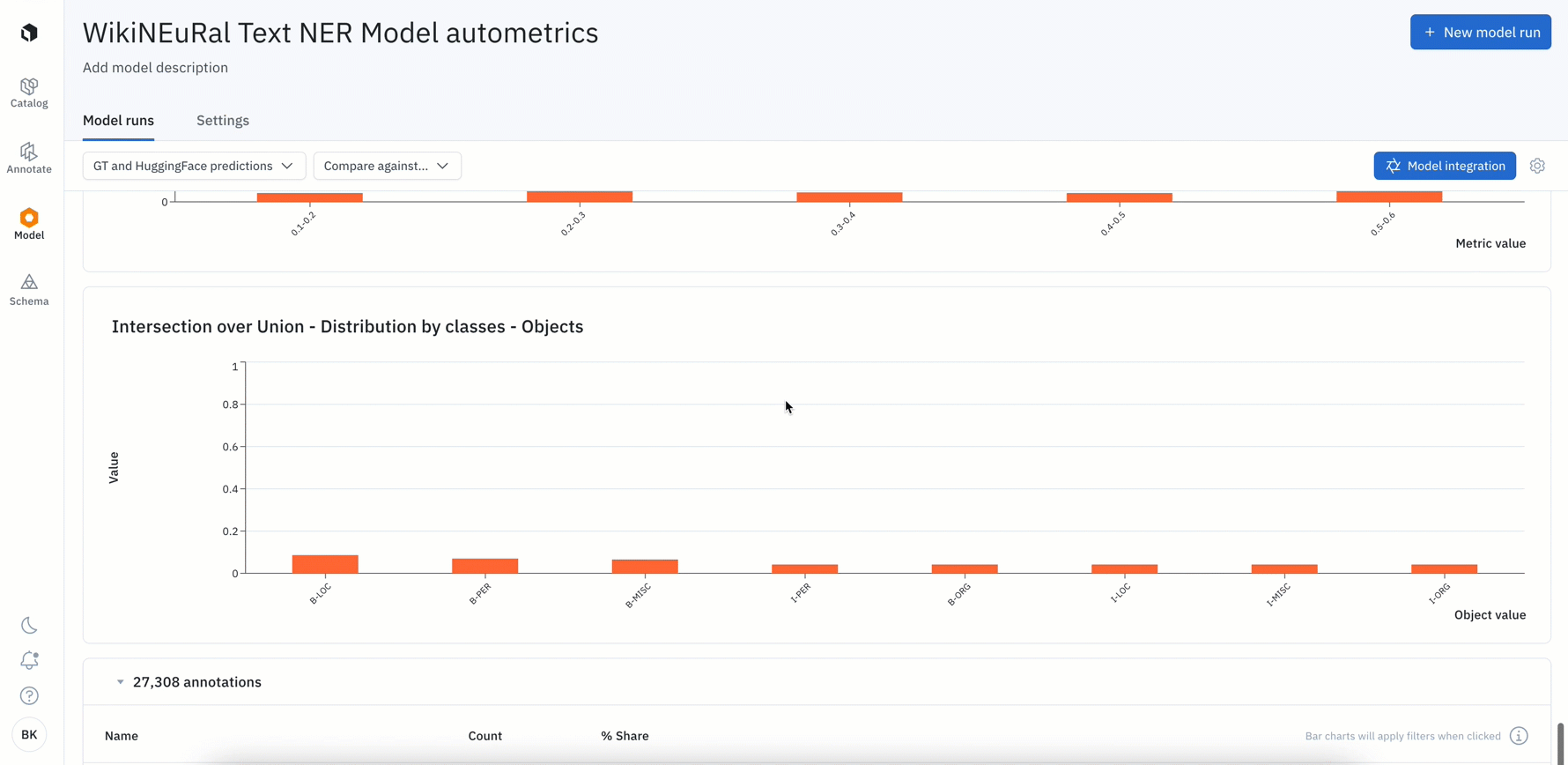
- All Labelbox users can now leverage auto-generated metrics to visualize disagreements between model ground truths and predictions.
- Rather than computing these metrics on your own, simply uploading your model predictions will automatically calculate metrics such as precision, recall, f1 score, TP / FP / TN / FN, IoU, etc. for your model run
- Visualize, filter, and click into metrics to surface label quality issues or model failures such as mispredictions or mislabeled data
Curate better datasets with annotation distribution metrics
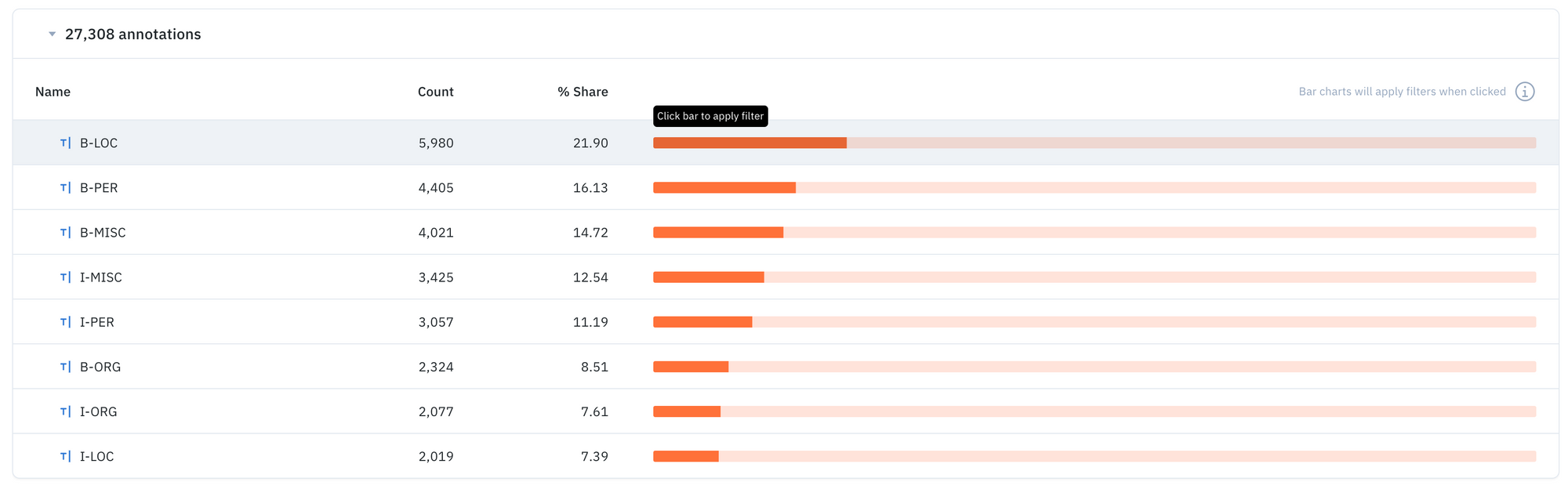
- Leverage annotation distribution metrics to make a more informed decision about what data to prioritize
- You can use annotation distribution metrics to find the most predicted or least-predicted class, as well as surface classes represented in training data, but that are rarely predicted by the model
Uncover patterns in your data with the embedding projector
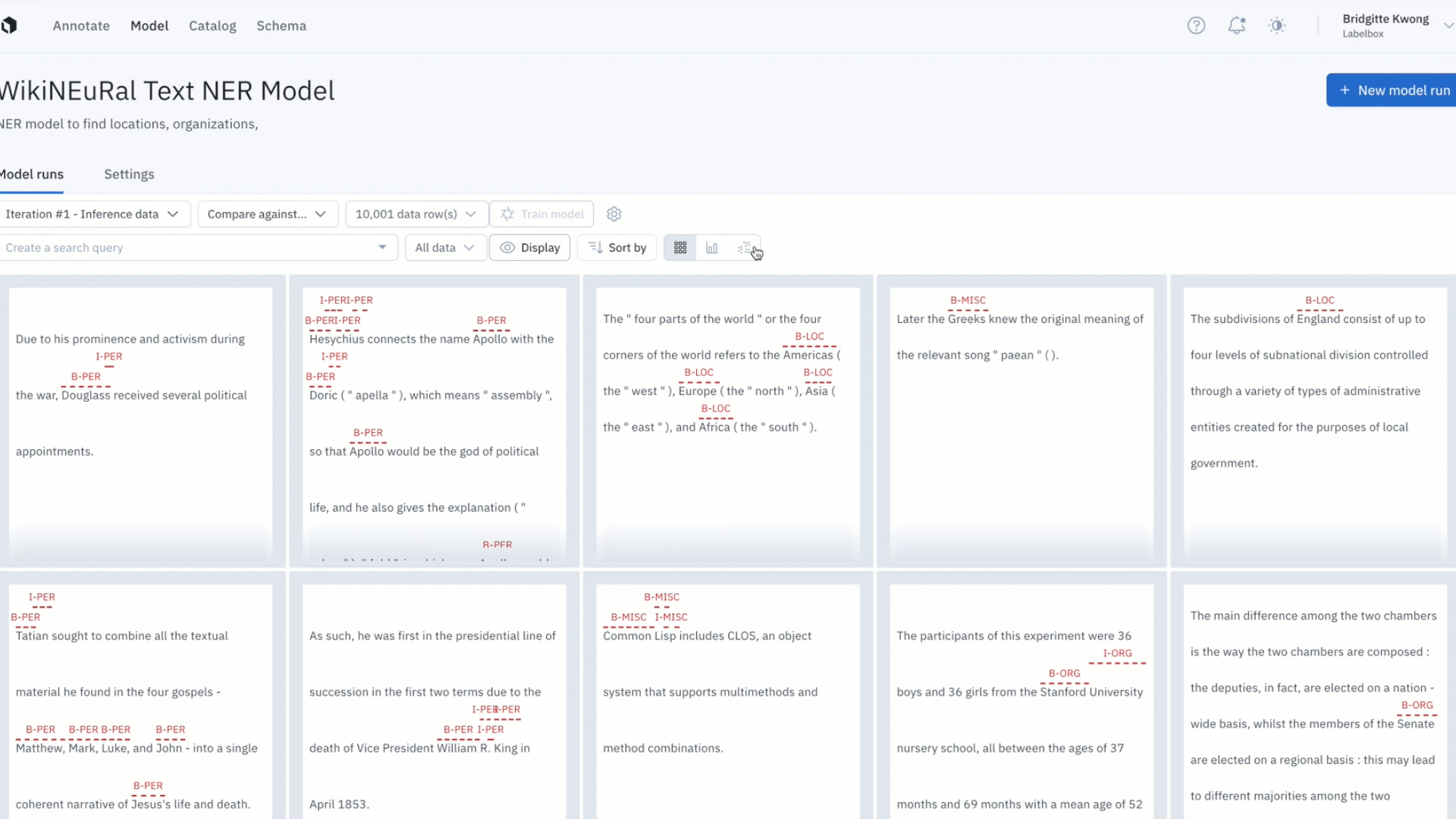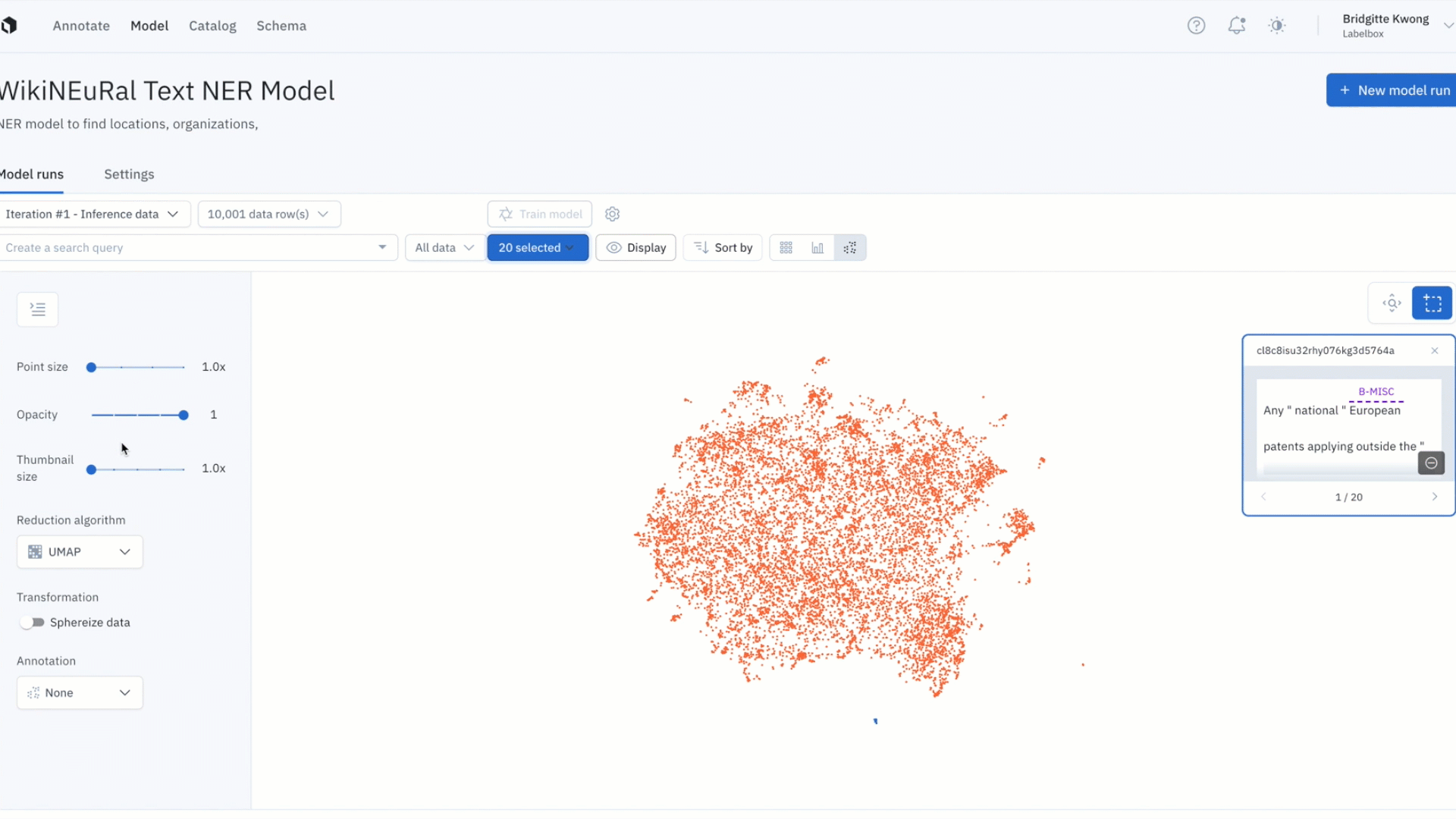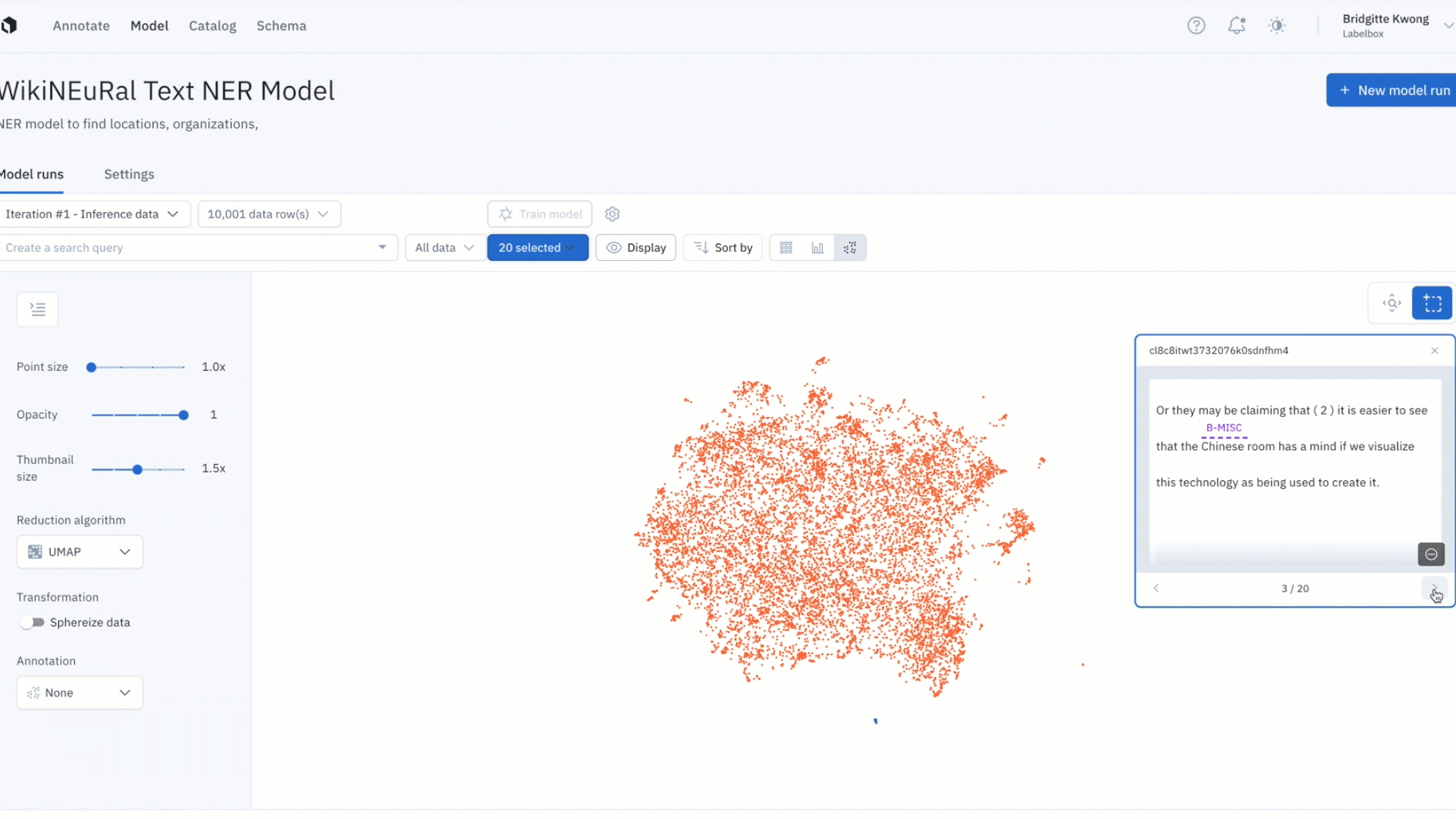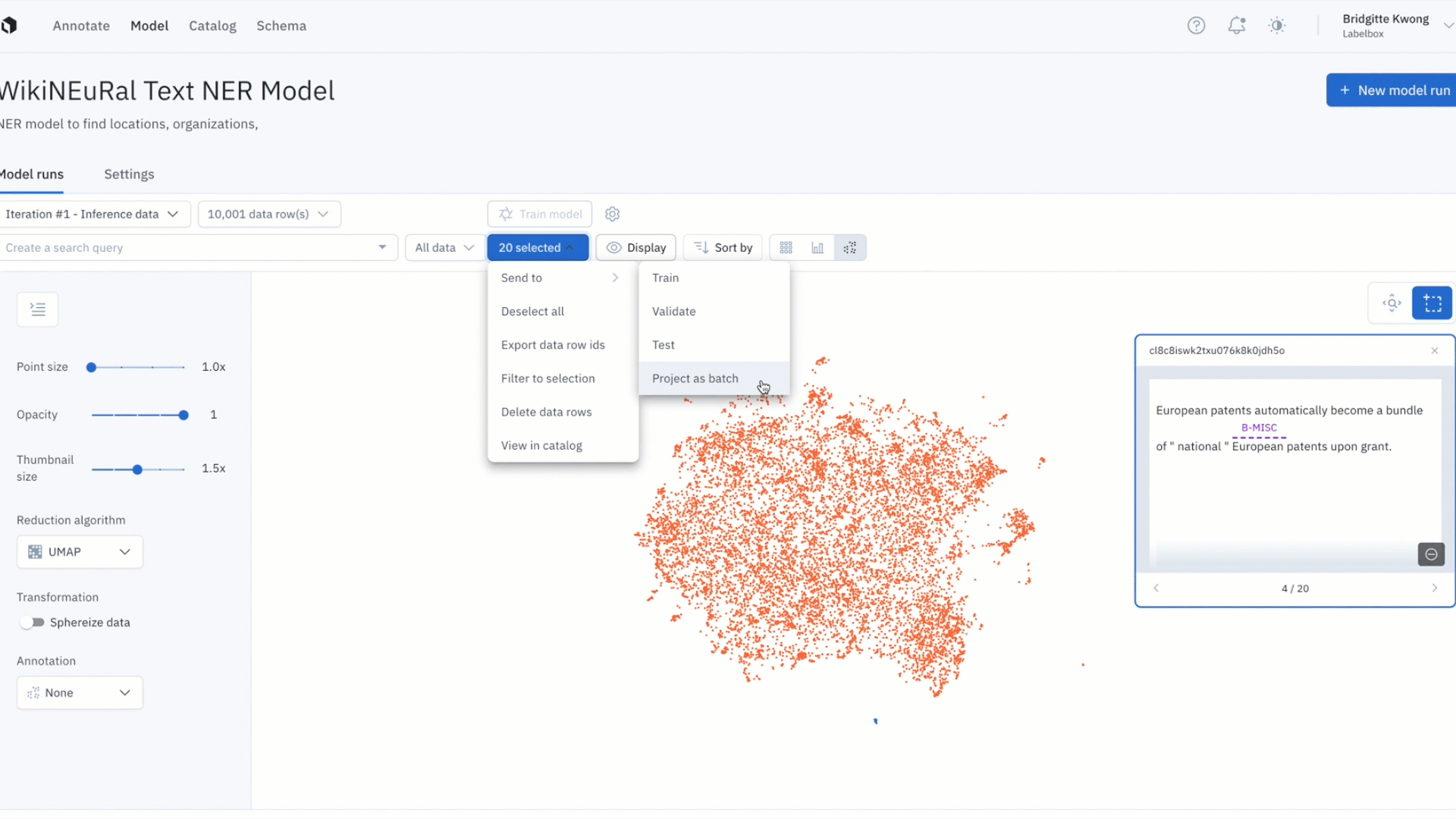
- It can be difficult uncovering patterns and finding outliers in unstructured data
- The embedding projector is a powerful tool for error analysis – uncover patterns in unstructured data that can be used to diagnose systemic model and labeling errors
- Zoom into your data points and use the selection tool to isolate and inspect clusters of data rows – visualize predictions and ground truths on specific data rows to uncover patterns and identify areas food model and data improvements
Get started in Labelbox Model today: How to get started in Labelbox Model: How to train, evaluate, and improve your ML models
And more…
Distinguish where specific video annotations appear with a color-coded timeline
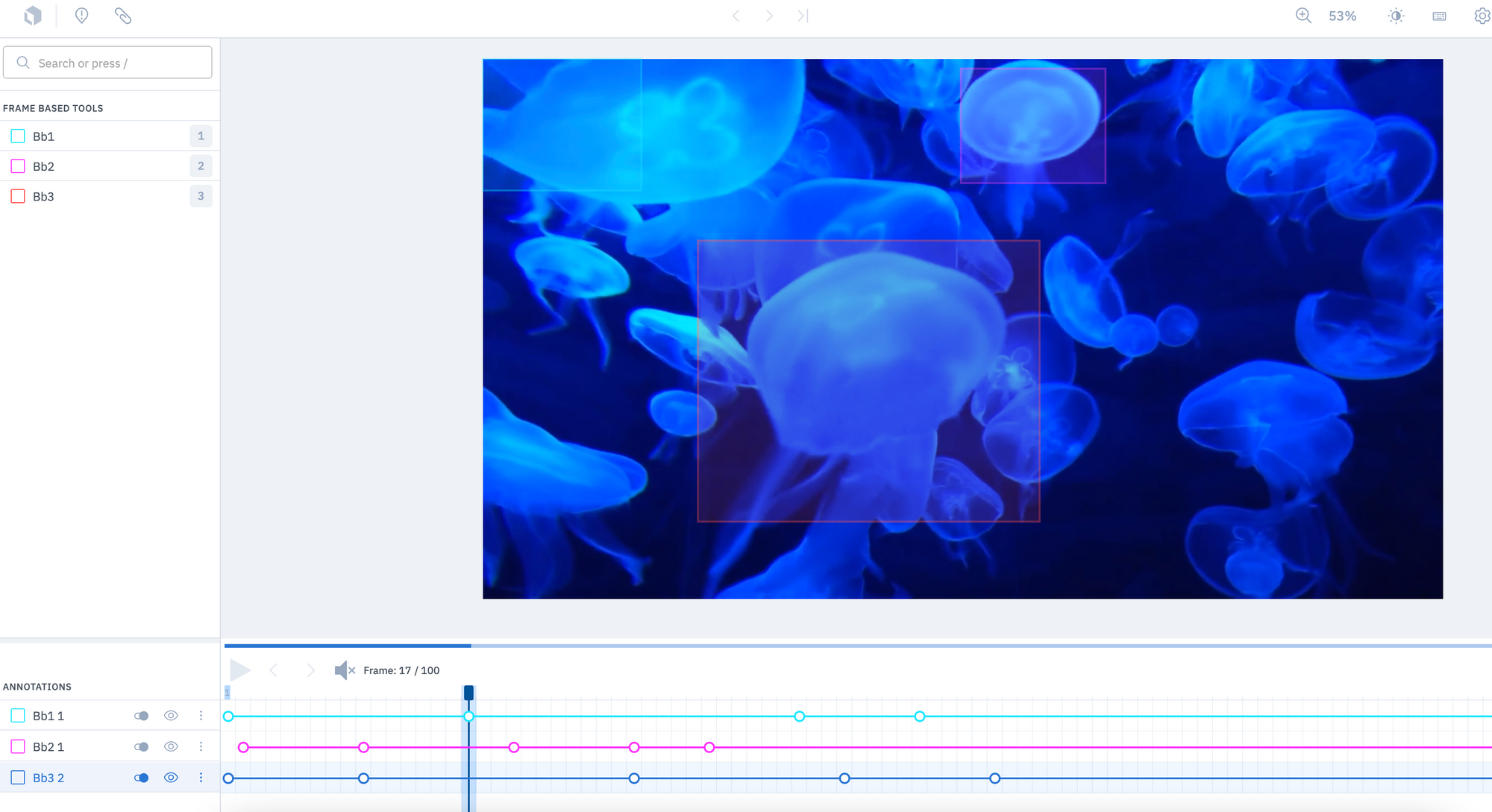
- The color of the timeline in the video editor now corresponds with the color of an annotation in your video
- If you have multiple annotations on a single video, you can now easily distinguish where specific annotations appear throughout the video
- This can help increase the speed at which you’re able to identify annotations and adjust any labeling errors, all at a glance through the timeline
Check out our latest product guides on…
Labeling operations
- How to kickstart and scale your data labeling efforts
- How to define a task for your data labeling project
- How to define your data labeling project's success criteria
- How to create a quality strategy for your data labeling project
- How to scale up your labeling operations while maintaining quality
- How to evaluate and optimize your data labeling project's results


