×![]()

 All blog posts
All blog postsLabelbox•September 29, 2021
Labelbox lands in London: The key to a performant ML model lies within your training data
Just last month, we opened our Labelbox European office to better serve our EMEA (Europe, Middle East, Africa) customer base.
“We’re seeing exceptional growth in Europe – more than a quarter of our business. The innovation cycles in Europe are leading the world in many industries and we’re excited to be involved and now have a specialist team in Europe closer to those customers to help them be successful faster.” - Manu Sharma, Labelbox CEO and co-founder
We hosted our first in-person event in London at the historic Churchill War Rooms earlier this month and received a warm welcome from the ML community. Our team presented several strategies for getting to production AI faster to our audience of data scientists and machine learning engineers.
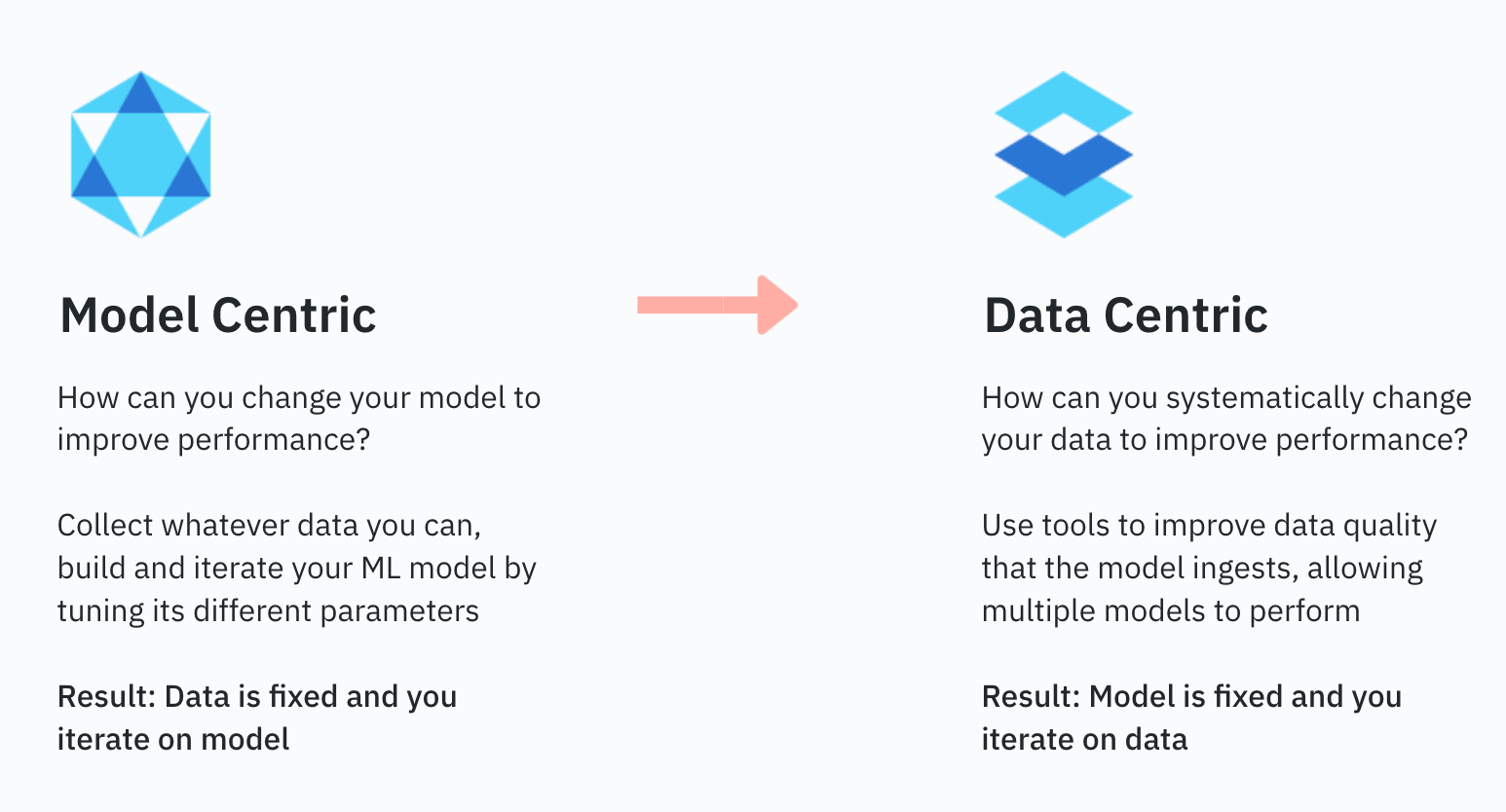
Moving from model-centric to data-centric
Mark Ghannam, a machine learning engineer from the Labelbox EMEA team, highlighted the importance of moving from a model-centric approach to a data-centric approach to machine learning:
“The AI environment has shifted drastically. We’ve moved from a model-centric approach to a data-centric approach. As we all know, AI models and ML methodologies have been around since the 1990s. What’s changed is the computational power and the way we ingest data. That has pushed the industry forward. Now that we have the knowledge to build advanced AI models, the importance has moved towards data. Not only how we provide our models with the right data today, but how we can iterate on that data in the best ways, so our models in production can consistently perform in the future.”
Avoiding bottlenecks on your ML journey
In a data-centric approach to machine learning, no element is more essential in your ML endeavors than creating and maintaining high-quality training data. Inadequate, inaccurate, or irrelevant data can poison the well when it comes to building production AI models.
Many ML teams fail due to two common but critical mistakes. The amount of work that goes into gathering, labeling, and prepping training data can be overwhelming without a solid plan and processes in place. This will frequently result in a compromise on the quality or quantity of training data and will inevitably cause serious issues down the line.
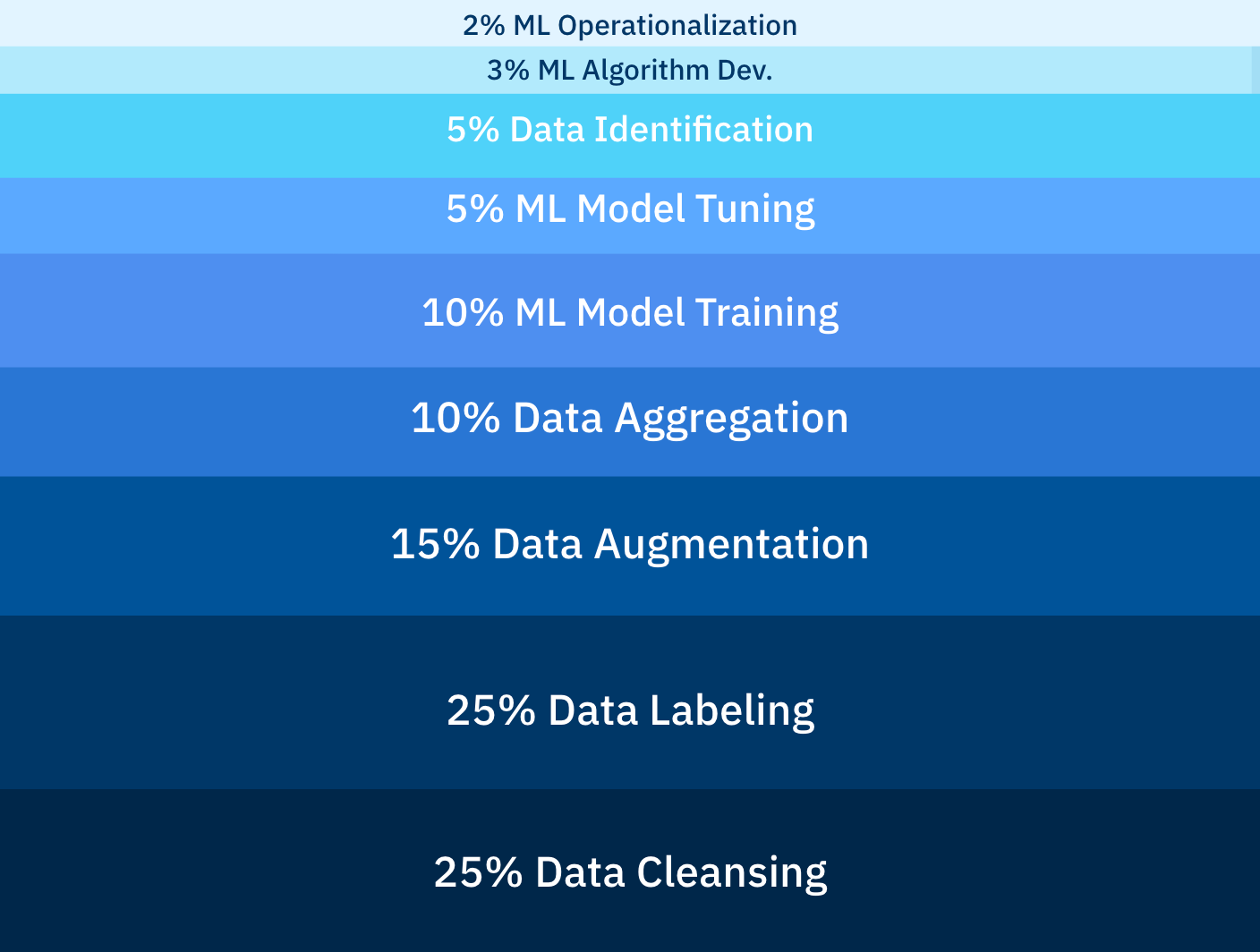
Secondly, many ML teams spend an enormous amount of time building out an infrastructure for the training data that doesn’t work and leads to disjointed development efforts. According to research firm Cognilytica, ML teams spend up to 80% of their time building and maintaining training data infrastructure.
Optimizing your ML operations
If training data is the key to success for any ML model, how can you safeguard that your algorithm is consuming high-quality datasets? How can you spend less time developing infrastructure?
With the right blend of experts, proven processes, and technology that suits your goals, you can avoid the time-sinks mentioned above and optimize your time where it counts.
Simply put, operational excellence looks like this – you need seamless collaboration between your workforce, your ML team, and your labeling technology.
Until recently, it was difficult to find technology that offered a collaborative space for ML teams and labeling workforces to come together and manage all of their training data. The field of machine learning has evolved very quickly in the past few years, while the development of tools to support ML teams have been slow to match their needs. In the past, most ML teams had to either build their own labeling tools or stitch together a workflow with open-source tools and labeling services.
Hence the creation of a new solution for ML operations: the training data platform (TDP). TDPs are purpose-built for ML teams — to combine data, people, and processes into one seamless experience, enabling ML teams to produce performant models quicker and more efficiently.
Streamlining your ML processes
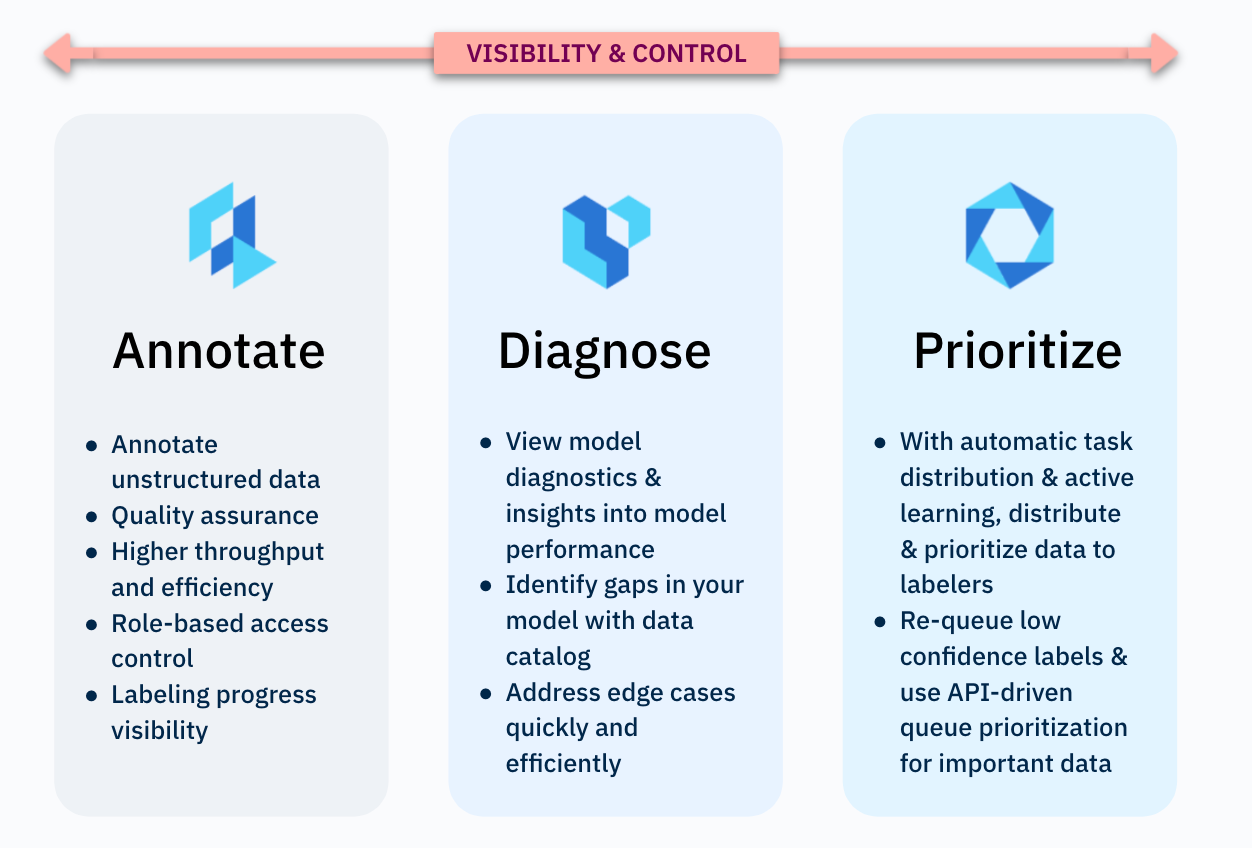
Successful ML deployments start with collecting data, project planning and defining custom ontology using a training data platform.
Afterward, labelers create the training data according to the defined ontology to train the model. Your training data platform should allow for efficient collaboration between ML teams and labeling teams.
Your TDP should also provide you with transparency into the label workforce and labeling performance metrics.
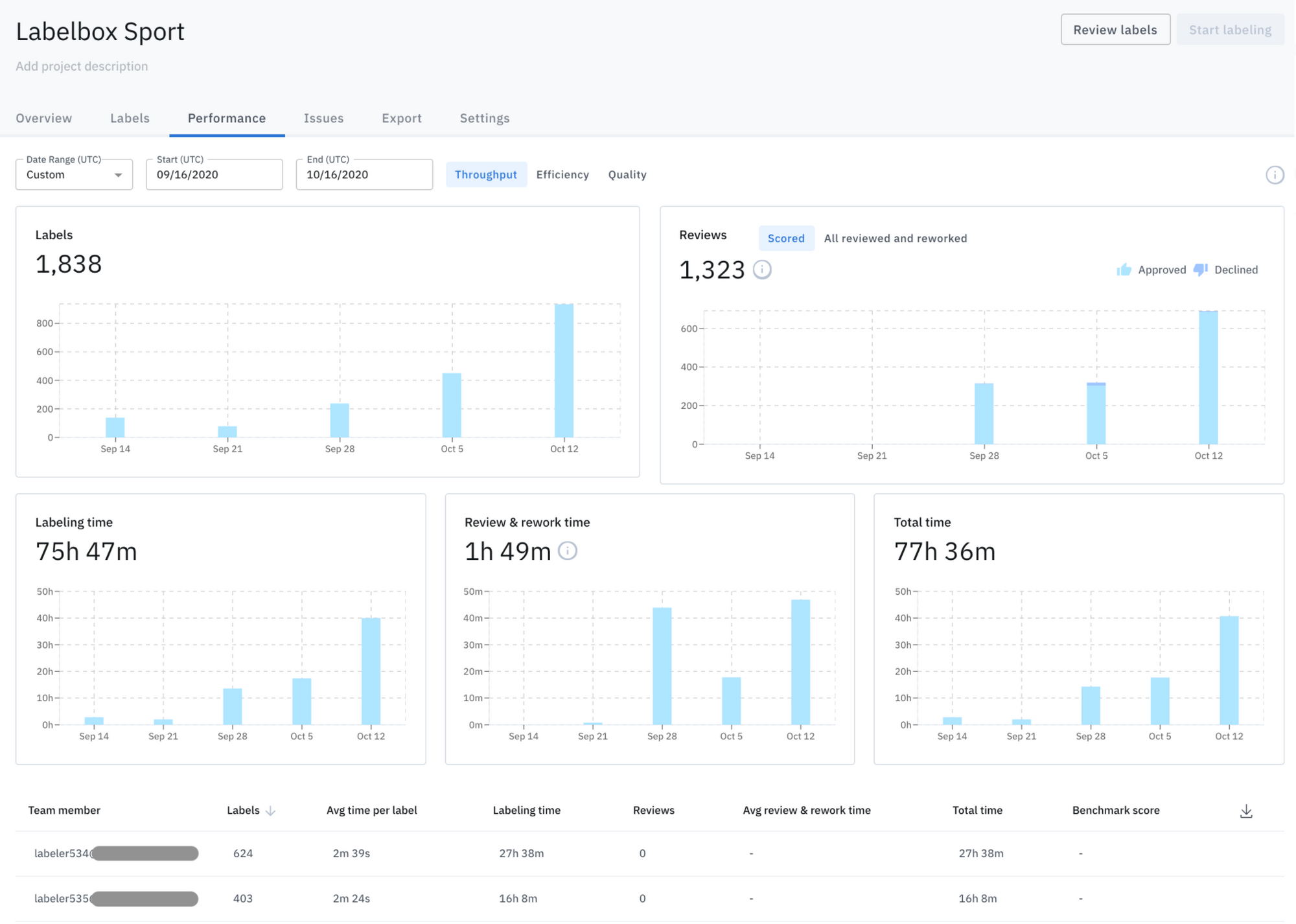
With a consistent process for delivering high-quality training data, you can more easily scale the quantity of data needed to train the model, test it, and then deploy it into production.
Just as importantly, the greatest boosts to model performance come through iteration. Your training data isn’t static and should be refined throughout the AI development lifecycle. Your initial data may lose accuracy as real-world conditions change, but by updating your training data, your model can be retrained to be confident in its predictions and decisions.
This is where technology can support you as well. A TDP can provide you with the ability to access powerful analytics, review outputs against benchmarks, actively learn, and utilize automation to maximize improvement with each iteration.
You can download our Training Data Platform 101 guide to learn more about how you can accelerate your AI model to production!
Powering up production: How Move.ai leverages Labelbox
From film & television, video games, music videos, sporting events, social media, to live broadcasts, there is a wide demand for motion capture. For decades, motion capture has been done in the same way. Expensive and resource-intensive, subjects wear Lycra suits covered in markers to record motion.
But now, a London-based company called Move.ai is changing the way motion capture is done through computer vision and artificial intelligence. For the first time, no restrictive suits are needed, allowing for much more natural movement and more realistic motion capture. You can imagine the difference this can make in a martial arts scene, for example.
This markerless motion capture allows for far more data points with significantly less equipment. Previous motion capture allowed for about a dozen data points, but Move.ai can capture hundreds of thousands of data points on a person with finger-level detail.
Video credit: Move.ai
When the team at Move.ai received a project from a client with a quick turnaround required, six weeks from build to launch, they knew they wanted to enlist help. The team turned to Labelbox.
Leveraging both Labelbox’s training data platform and Labelbox’s dedicated workforce team, the team at Move.ai was able to streamline their labeling pipeline with the rest of their ML operations very quickly without sacrificing quality.
“Labelbox stuck out to us because the platform was so intuitive. It gave us the ability to label a lot of different types of data since we have lots of use cases. The Labelbox team was also very responsive to our deadline. Crucially for us, the Labelbox workforce was able to turn around the first batch of labels, nearly 30,000 labels, within a week. It allowed us to rapidly iterate and meet our deadline.” — Niall Hendry, Head of Product at Move.ai
Read more about Move.ai’s journey with Labelbox and follow the Move.ai team’s breakthroughs in motion capture with machine learning.
Transforming how you build production AI
Alongside Move.ai, we have clients in more than a dozen countries in Europe. Ireland-based Cainthus uses computer vision to monitor livestock herds around the clock alerting farmers to changing conditions so they can feed more cattle more efficiently.
U.K.-based Winnow Solutions uses computer vision and AI to track and analyze food waste in industrial kitchens.
Netherlands-based Xarvio Digital Farming Solutions uses smartphone, drone, and satellite imagery to build AI-powered products that advise farmers on how to maximize productivity.
If you’re experiencing bottlenecks in your training data pipeline, let us become an extension of your team. We are not here just to provide you with software, but we have the knowledge and expertise to help diagnose issues within your ML processes and help you get to production AI faster. Want to see a demo? We can’t wait to meet you and your team.


