×![]()

 All blog posts
All blog postsLabelbox•July 1, 2021
NASA’s Jet Propulsion Laboratory employs ML to find signs of life in our solar system

Does life exist beyond our planet? Throughout recorded history, human beings have studied the stars and wondered whether other creatures lived elsewhere in space. Today, the search for signs of life in our solar system has focused not on the stereotypical aliens of the human imagination — vaguely humanoid beings or otherworldly animals — but on the one element necessary to support every known form of life: water.
Water samples from Earth’s oceans contain billions of microbes — tiny organisms such as bacteria and protozoa. In recent years, researchers have discovered ice and water vapor on both Europa, a moon of Jupiter, and Enceladus, a moon of Saturn. To further study these moons for microscopic signs of life, the Ocean World Life Surveyor (OWLS) project at NASA’s Jet Propulsion Laboratory (JPL) is preparing for the possibility of sending a spacecraft to one of them. The craft will be equipped with a variety of instruments, including microscopes that will collect video data from water samples. If the footage captured contains evidence of microbes, NASA researchers will have effectively discovered extraterrestrial life.
Sending samples of microscopy data back to Earth for scientists to examine, however, is a complex task. The moons are so far from Earth that the energy cost of sending the data back, called downlinking, is (pardon the pun) astronomical. In fact, so little data can be returned compared to what’s gathered (<0.01%) that it’s comparable to summarizing the entire Lord of the Rings trilogy with 57 words. Traditional compression methods simply cannot accomplish the task; for example, downlinking the two compressed video samples shown below (40 MB in total) would take up a third of the organization's total science data return budget.
This is why the team in the Machine Learning Instrument Autonomy (MLIA) group set out to build an ML model that identifies microscopy videos most likely to contain signs of life-like motion, captures short clips of the potentially living creatures, and prioritizes them to downlink back to Earth along with an explanation of its decisions.
The ML challenge
The MLIA team had four primary requirements for the onboard science autonomy:
- It must fit onboard a spacecraft’s computer, which is about as powerful as a mobile processor
- It should find and track any moving particles
- It must distinguish life-like motion from drifting or jostling using ML
- It must be able to efficiently explain what it saw and how it made its decisions
Because the amount of compute power onboard a spacecraft is highly limited, and extracting explanations from deep learning models can be difficult, the team decided to use traditional ML methods such as decision trees and SVMs rather than building a deep learning model.
The recognition of life-like motion presented a complex challenge as well. “While human beings are really good at being able to tell whether or not something is alive by the way it moves, it’s a much more difficult task for a computer,” said Jake Lee, a Data Scientist in the MLIA group at the Jet Propulsion Laboratory. “Different species of microbes move differently according to their environment. There are also free-floating particles that may move randomly and seem organic to a computer.”


Building trust in ML
The team’s model also has to gain the trust of the scientists who might put it to use for their next mission to Europa or Enceladus. “At the end of the day, what matters is that we work with the scientists to help them trust the model,” said Lee. “They won’t trust it if it seems like a black box. So we are working closely with them throughout the process and showing them how we’re training the model. Our goal is that, when the model generates results in the end, the people using it know how it produced those results. They know what the algorithm is doing, and what its benefits and limitations are.”
To ensure that the model can best serve its primary users, scientists are integrated into the ML pipeline. The MLIA team coordinates with them to review model outputs and verify whether their model tracks the right objects, folding their expertise into their iterative cycles throughout the process.
Video annotation with Labelbox
To create their algorithm, the team set about labeling a large, diverse set of data sourced from a variety of field water samples and lab-grown specimens. While labeling itself was an easy task, creating and maintaining an in-house labeling solution became a challenging assignment for the small team. Because the research team develops multiple ML projects using small, competitive grants, they frequently have to build new labeling solutions for different labeling tasks as swiftly as possible. The team’s PhD ML researchers were painstakingly writing Java GUIs and manually sorting through data samples — a highly inefficient use of their time.
To address these difficulties, the MLIA team turned to Labelbox for both the training data platform and workforce. The team quickly uploaded video datasets collected from Digital Holographic Microscopes. With the intuitive video editor and basic training from the researchers, the labelers were easily able to track various objects’ movements over time and determine if it might be a live organism.
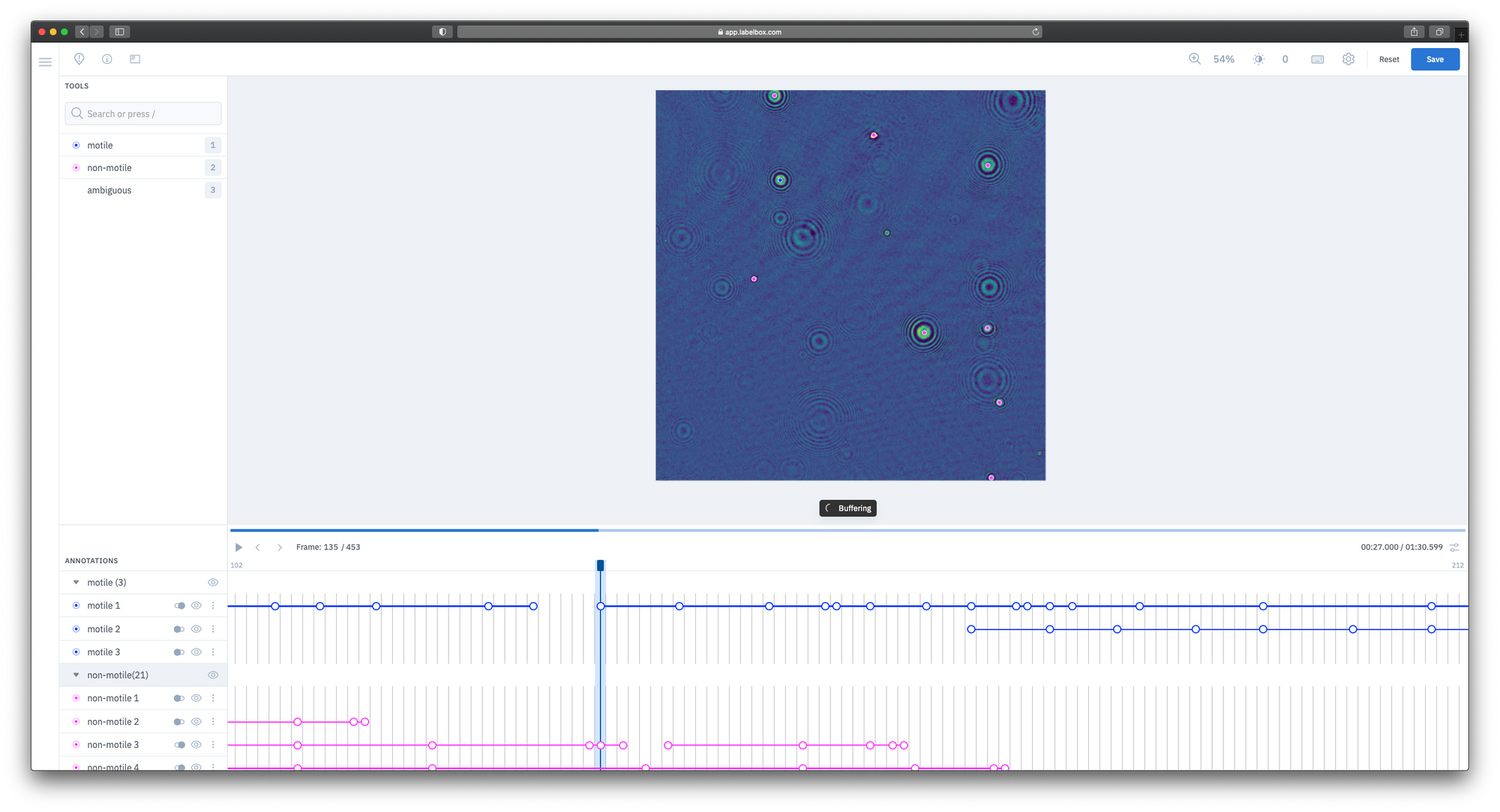
The Labelbox Workforce team annotated these assets quickly and enabled the MLIA team to spend their time on other tasks, moving the project forward much faster.
“Labelbox is so easy to use. The documentation is accessible, and the labeling pipeline is straightforward. We just had to upload our data, customize the editor to our exact requirements, and go. We had actually budgeted a week to get it set up, but we were done in a day.
In addition, Labelbox Boost has been a game-changer for us. We needed a workforce that could deliver fast turnaround with quality labels, and a powerful platform that we could use for years to come. Boost exceeded all of our expectations and helped us create significant improvements in our model.”
— Jake Lee, Data Scientist, Jet Propulsion Laboratory
Their current ML project is now on track to wrap up by the end of 2021, and will result in an ML-powered system created from scratch that can identify, track, and classify life-like movement directly from microscopy data. Today, the team is working to bring other ML teams at JPL to Labelbox as well, so that the training data platform can be a general solution for the entire lab. This ML project is just one step for researchers planning for future space excursions — launching a complete mission to either of these moons could require another decade of research and development!
You can learn more about the OWLS autonomy project on the JPL website. To discover how your ML team can benefit from a training data platform, watch this video.


