
 All blog posts
All blog postsLabelbox•April 25, 2023
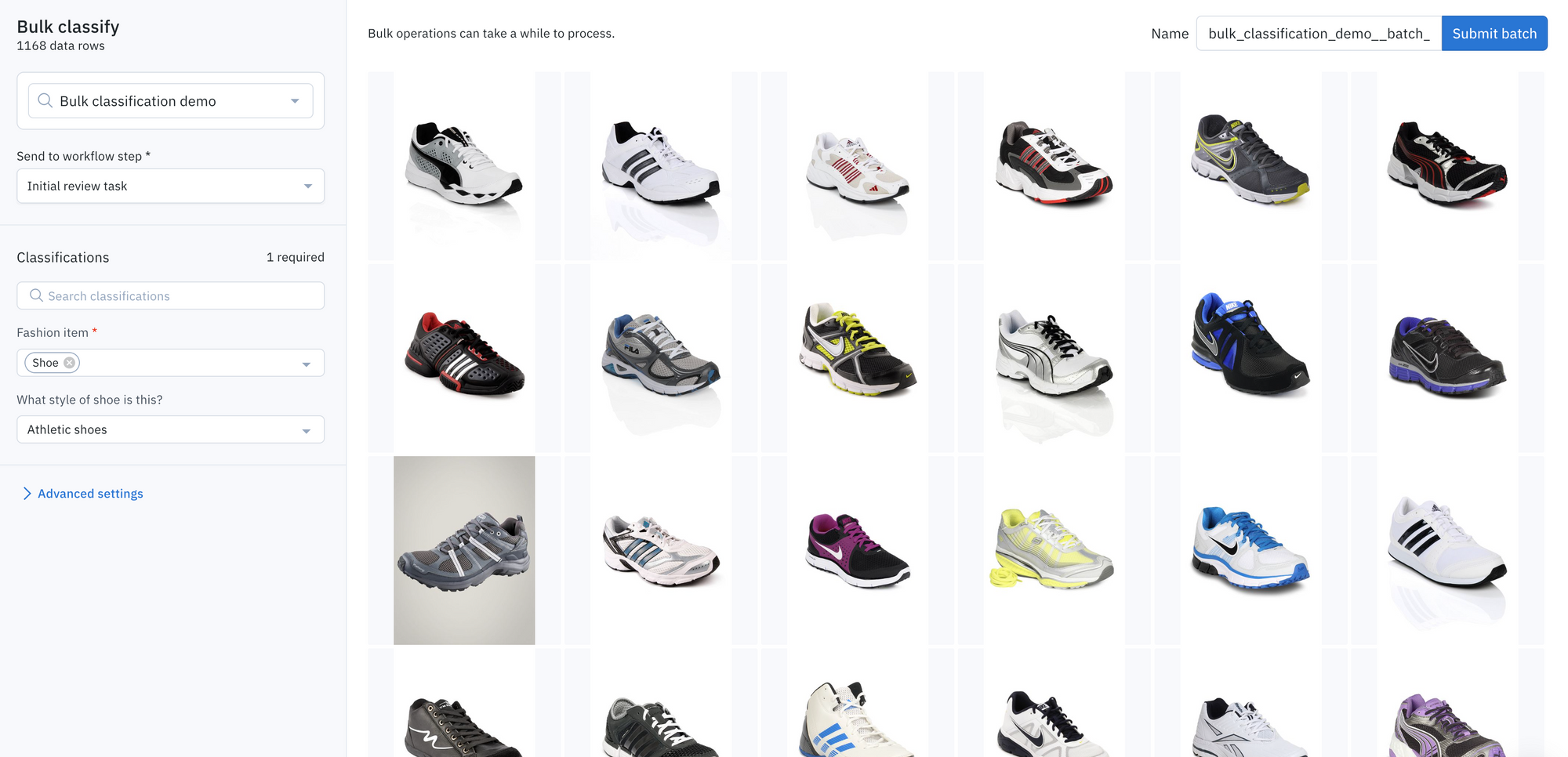
Pre-label and enrich data with bulk classifications
As the amount of unstructured data that businesses generate and accumulate continues to grow, finding effective ways to explore and derive meaning from that data becomes increasingly challenging. This is especially true when it comes to efficiently pre-labeling and enriching your data to deploy models quicker.
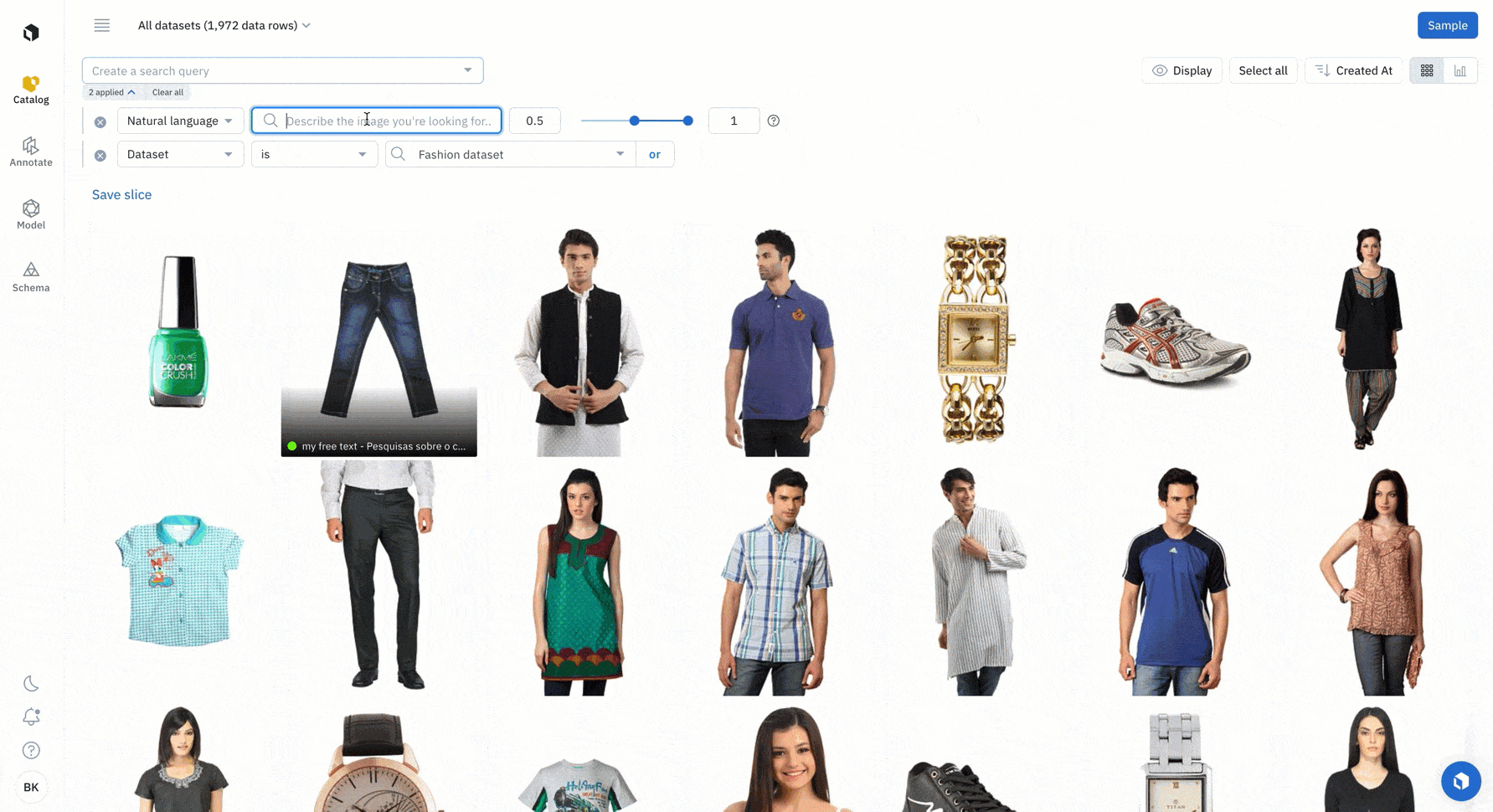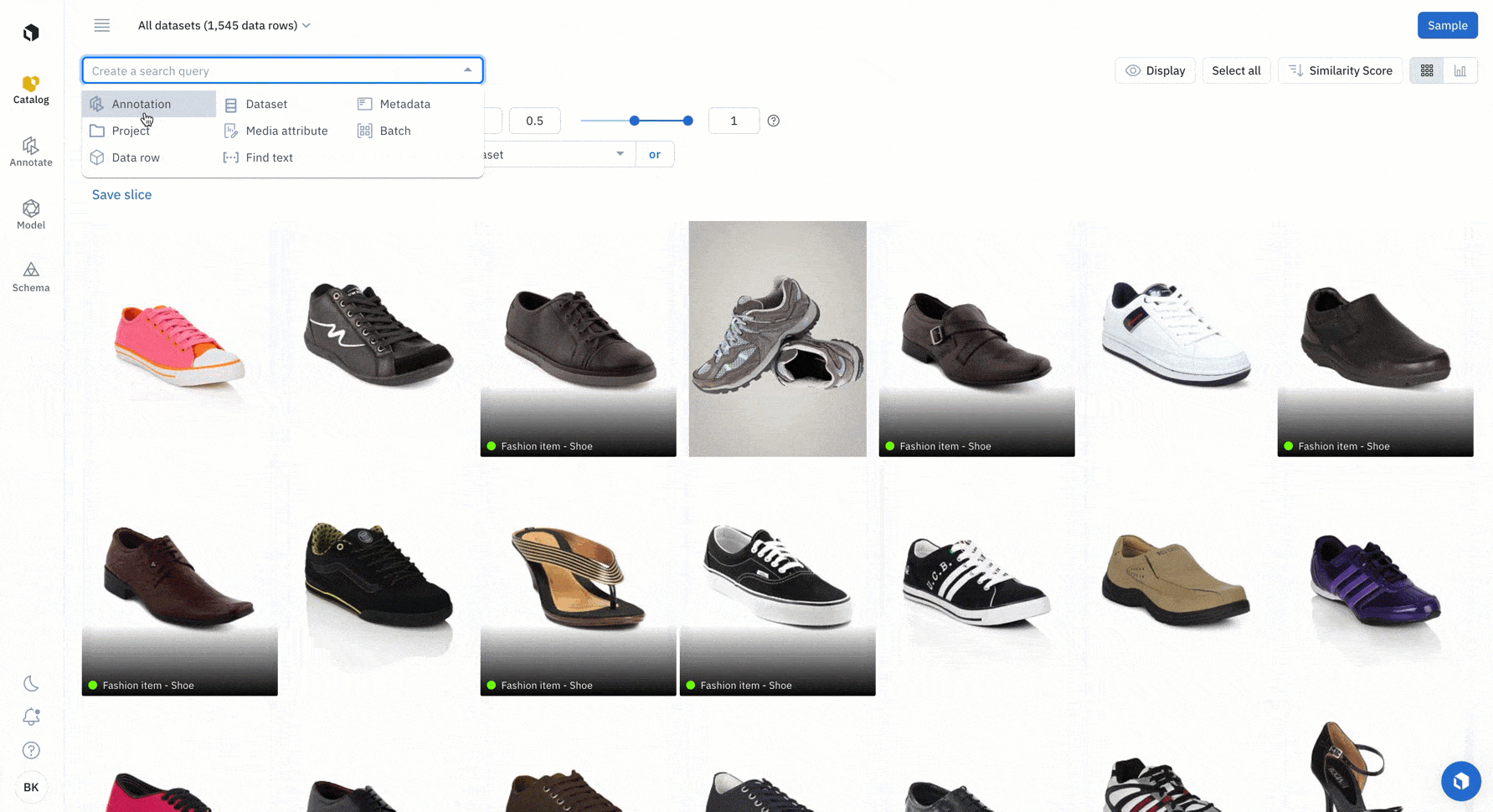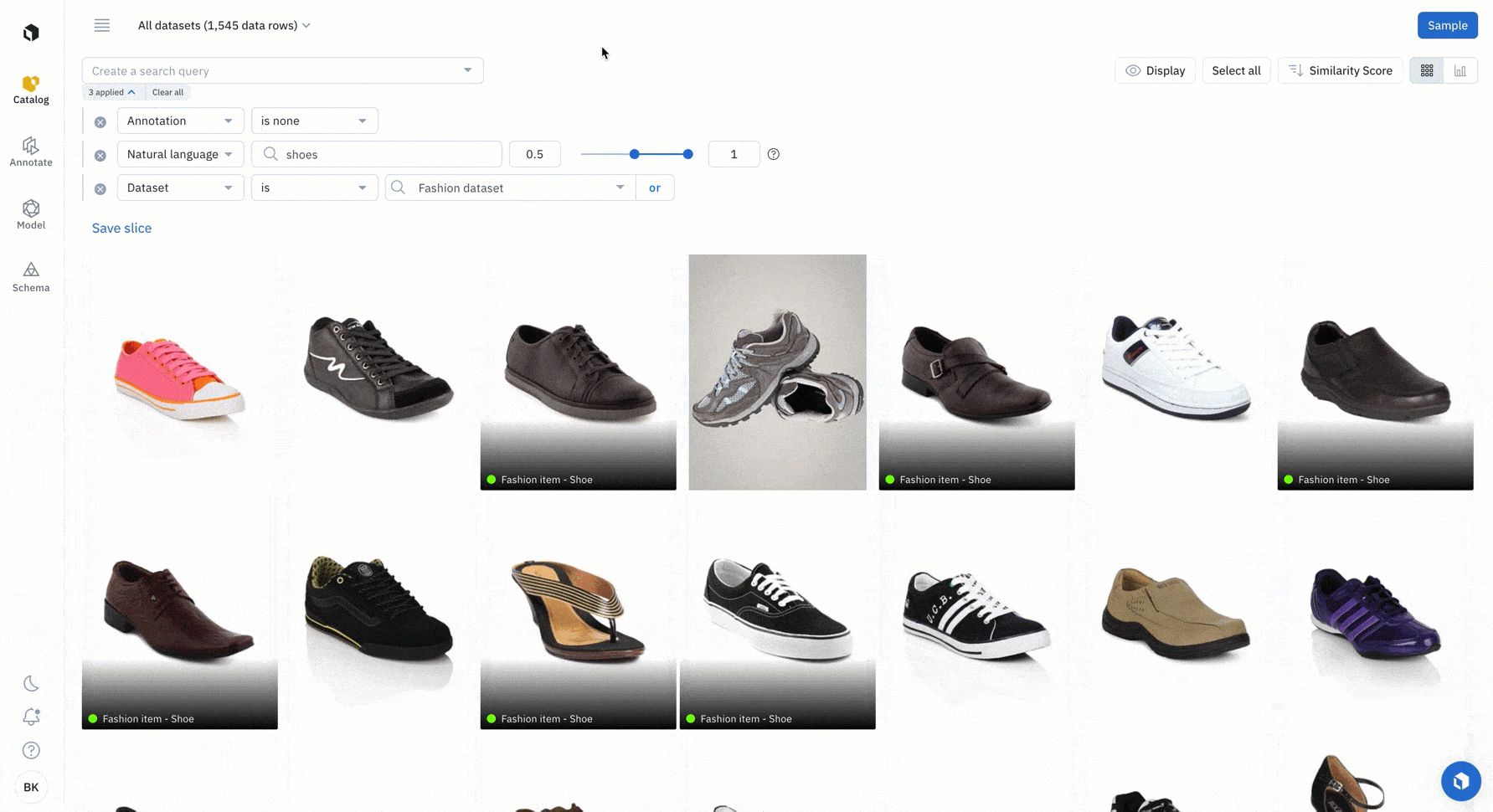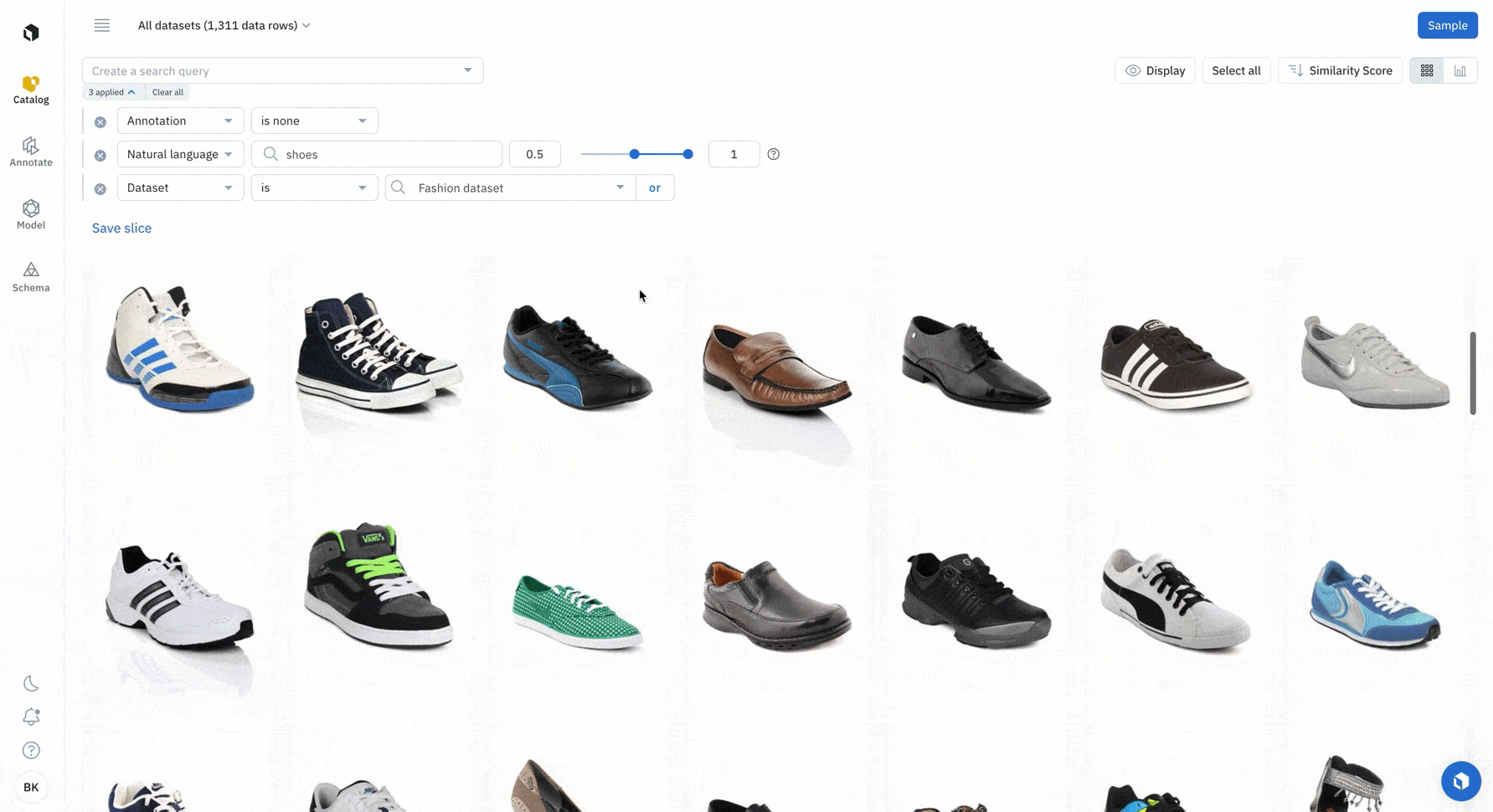
Labelbox Catalog enables you to search, explore, and enrich your data. Filter for specific data, such as with an embeddings search, natural language search, metadata, or projector embeddings, to quickly find all instances of similar data.
Surfacing this information is a key step to identifying high-value data, so how do you enrich this data for model training purposes?
Labelbox is introducing the ability to organize and automate your data labeling with bulk classifications. In some cases, the data that you surface in Catalog and Model can be classified all at once. With this new feature, you can now classify a large amount of unlabeled data in a few clicks directly from Catalog.
Automate your data labeling with bulk classifications
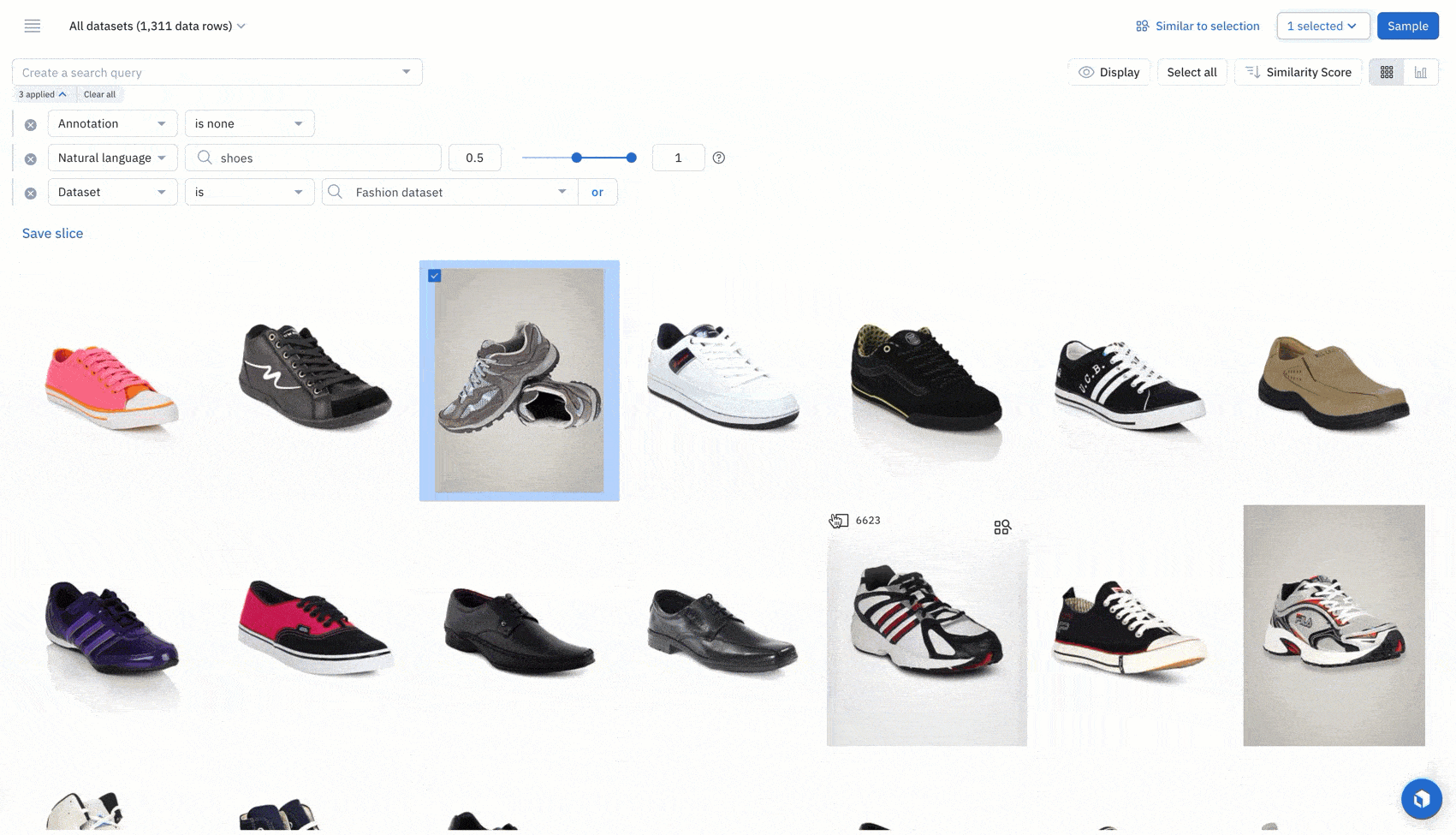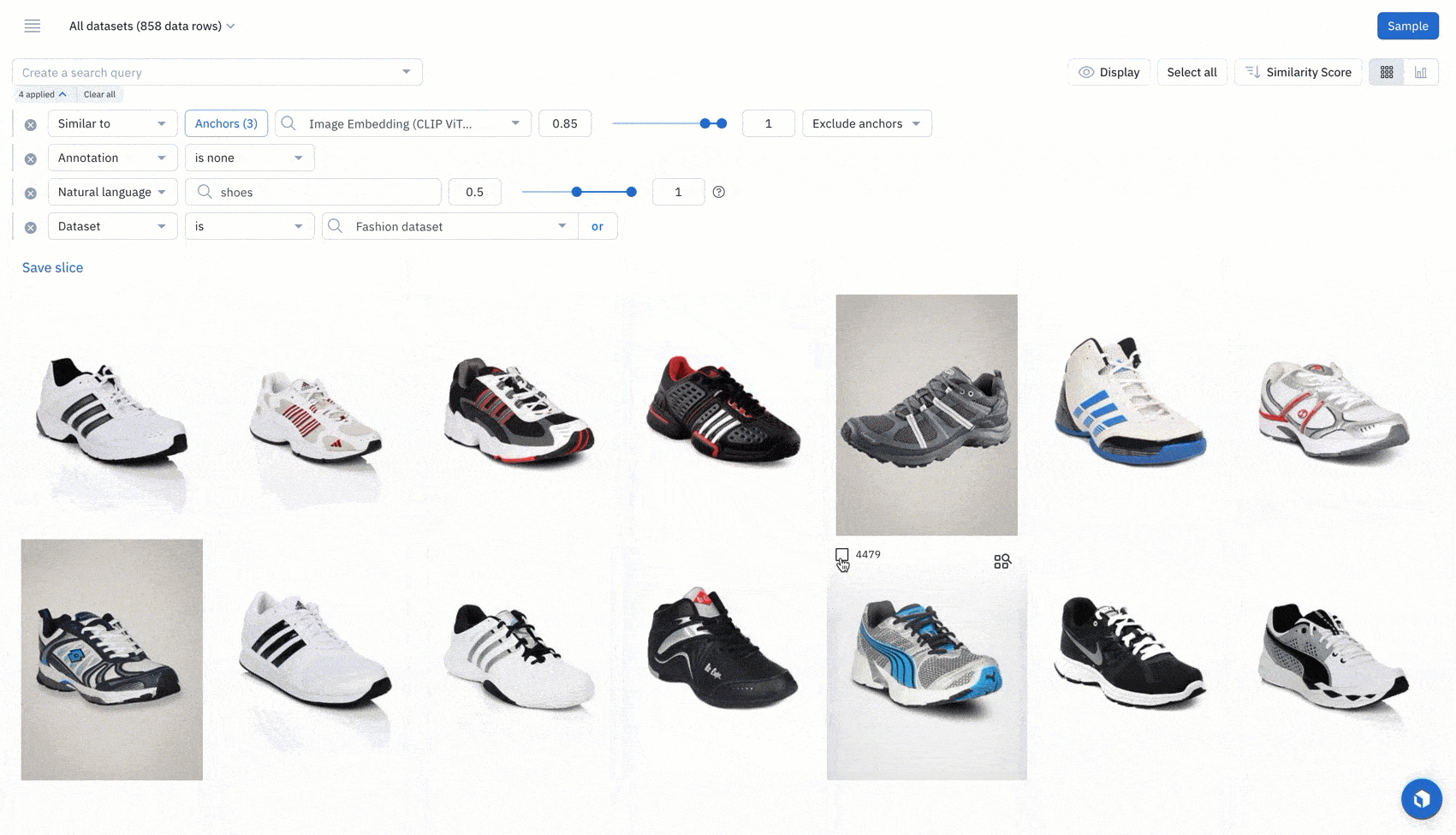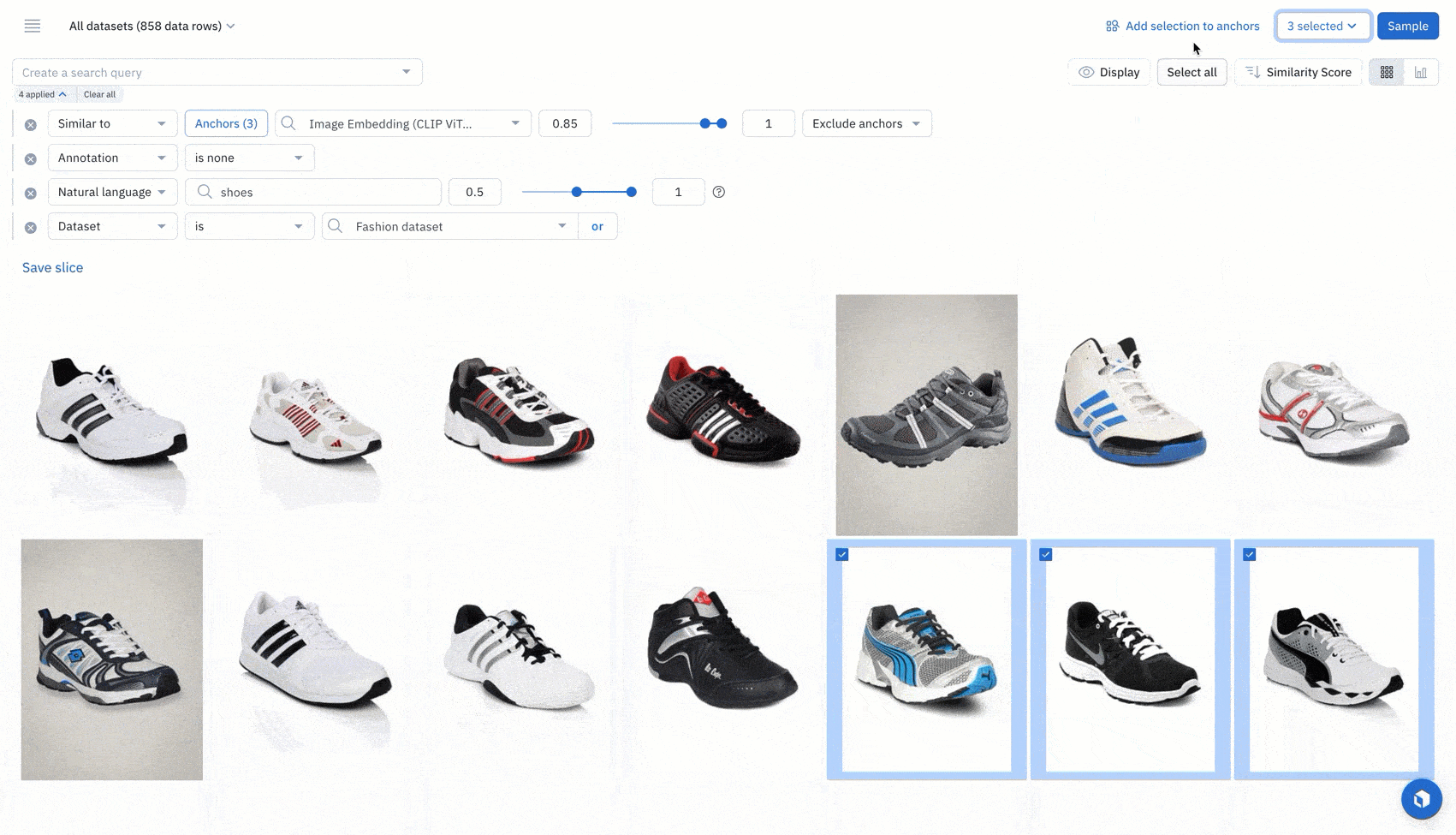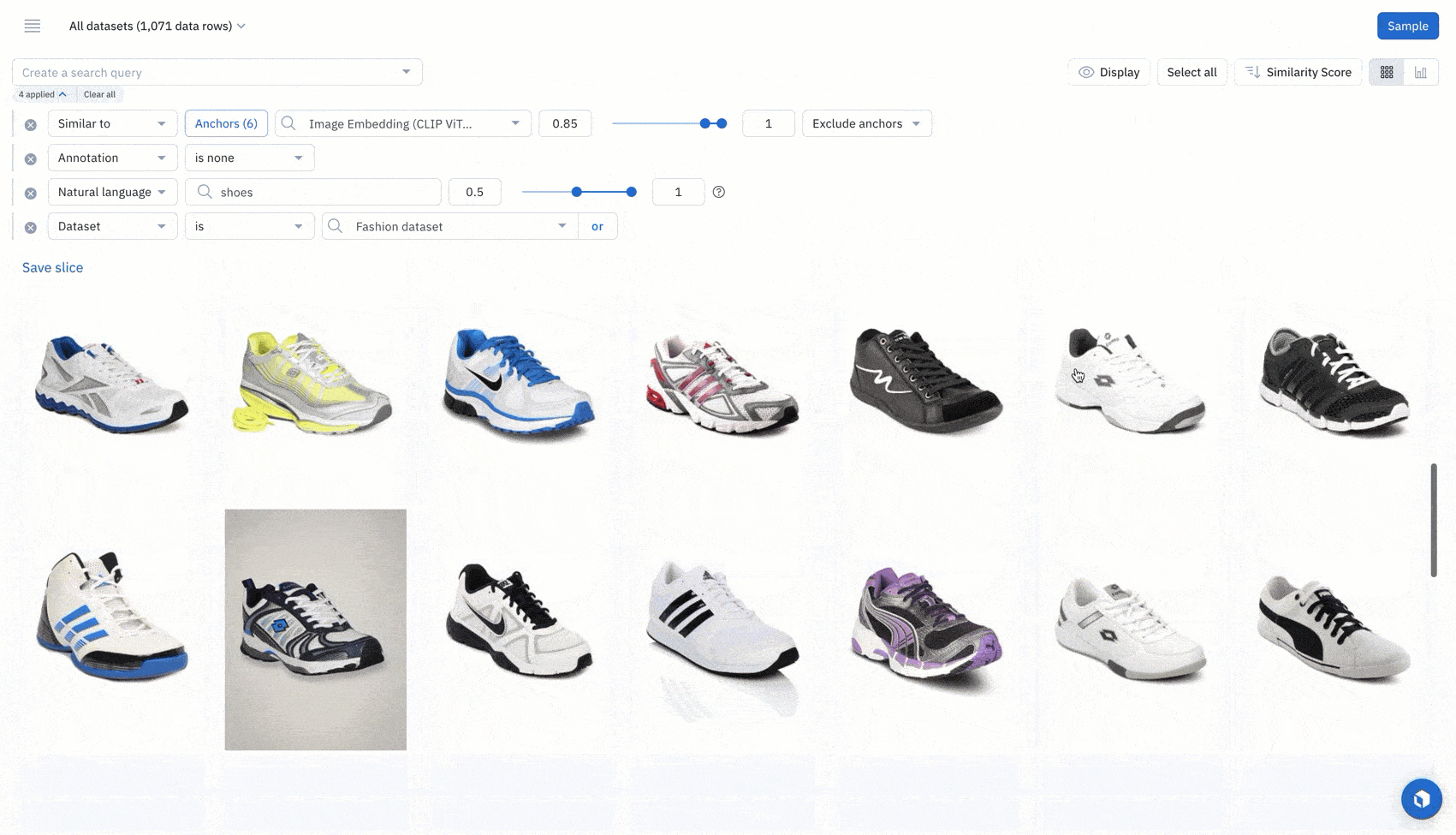
Find a subset of data with common characteristics
Leverage powerful search capabilities in Labelbox to select and curate a subset of data:
Search for data using a natural language search (embeddings)
Find all examples of similar data with a similarity search. You can leverage any off-the-shelf-model to quickly identify similar data
Examine a cluster of data from the projector view in a model run
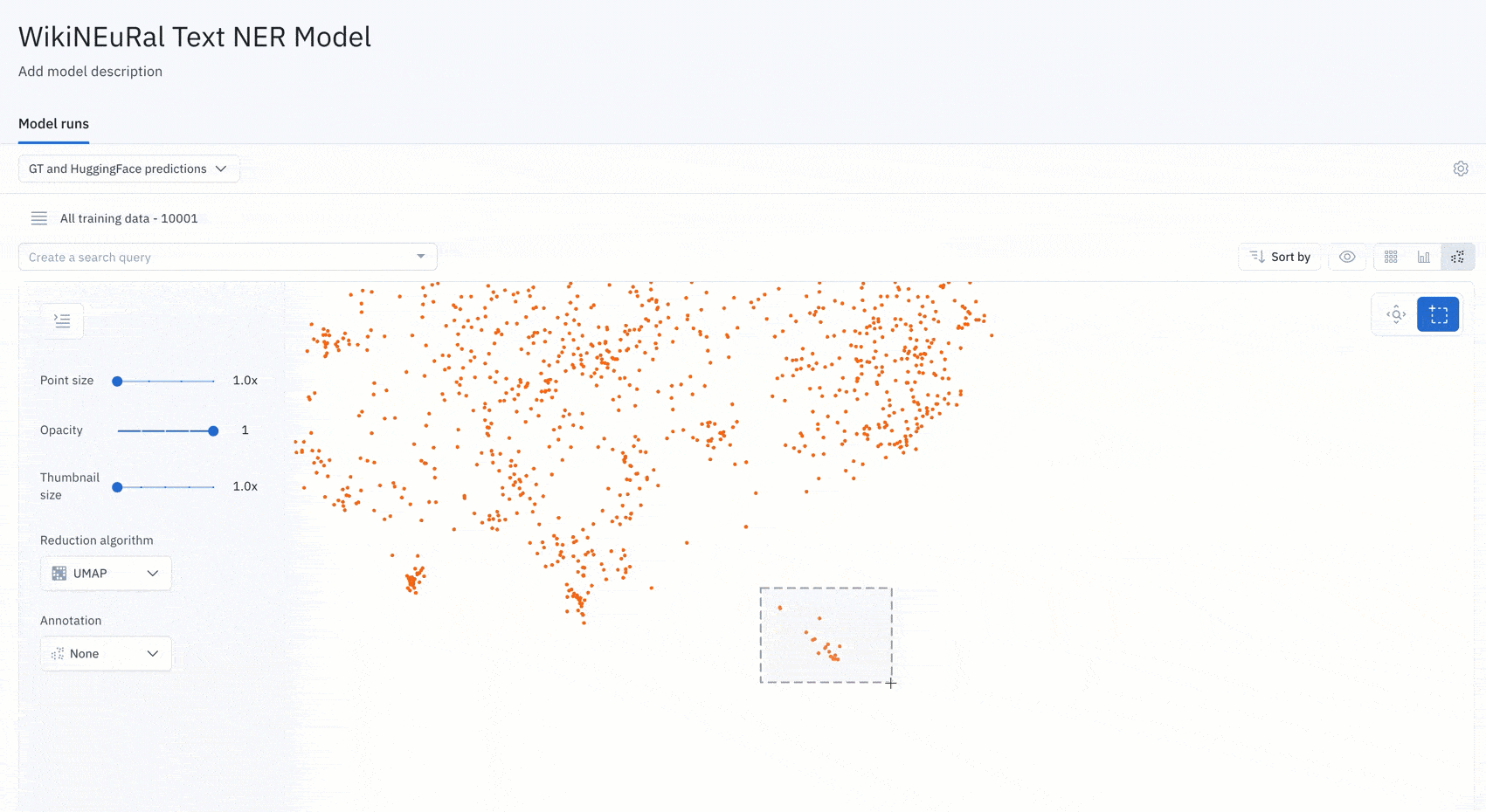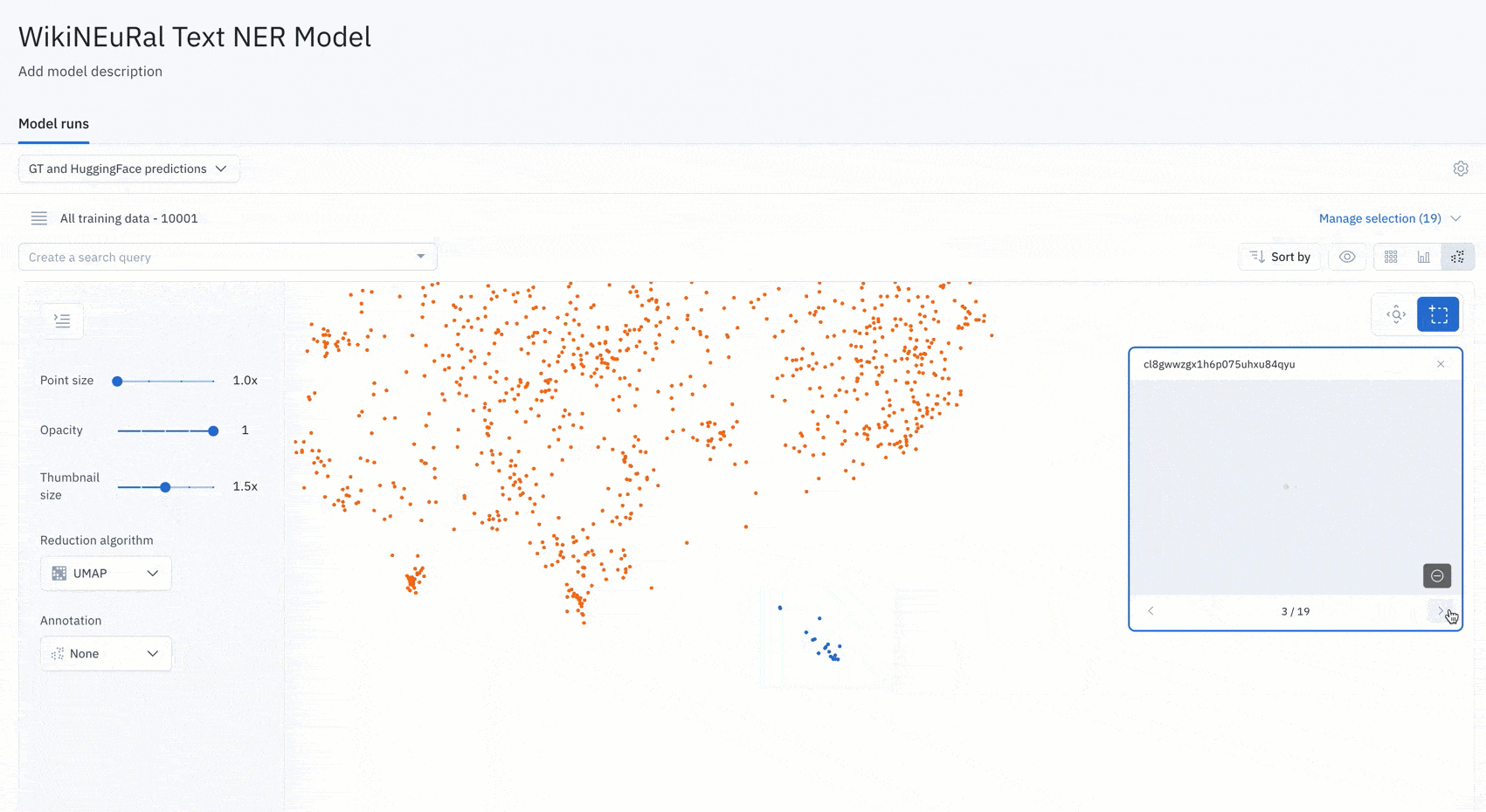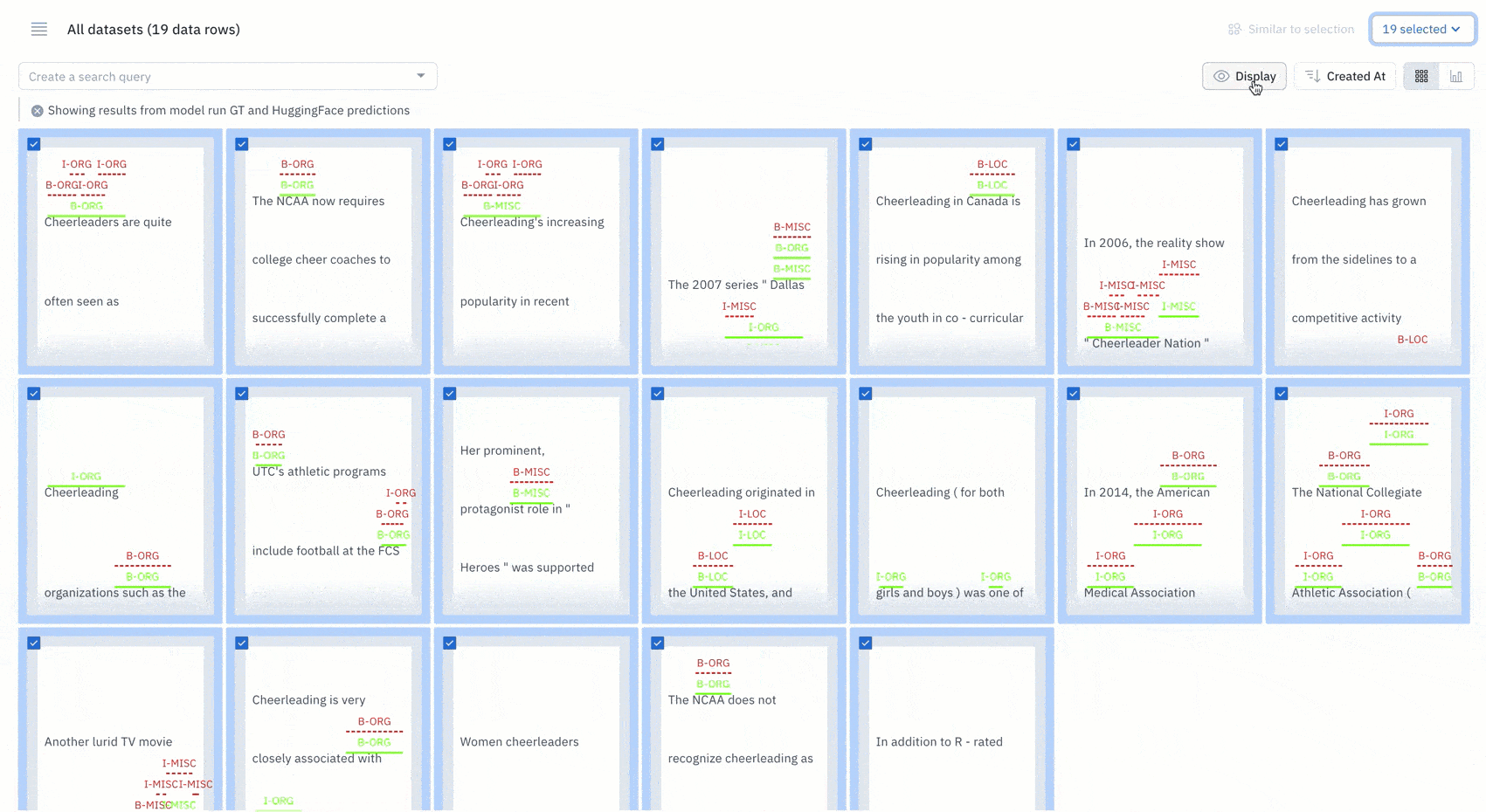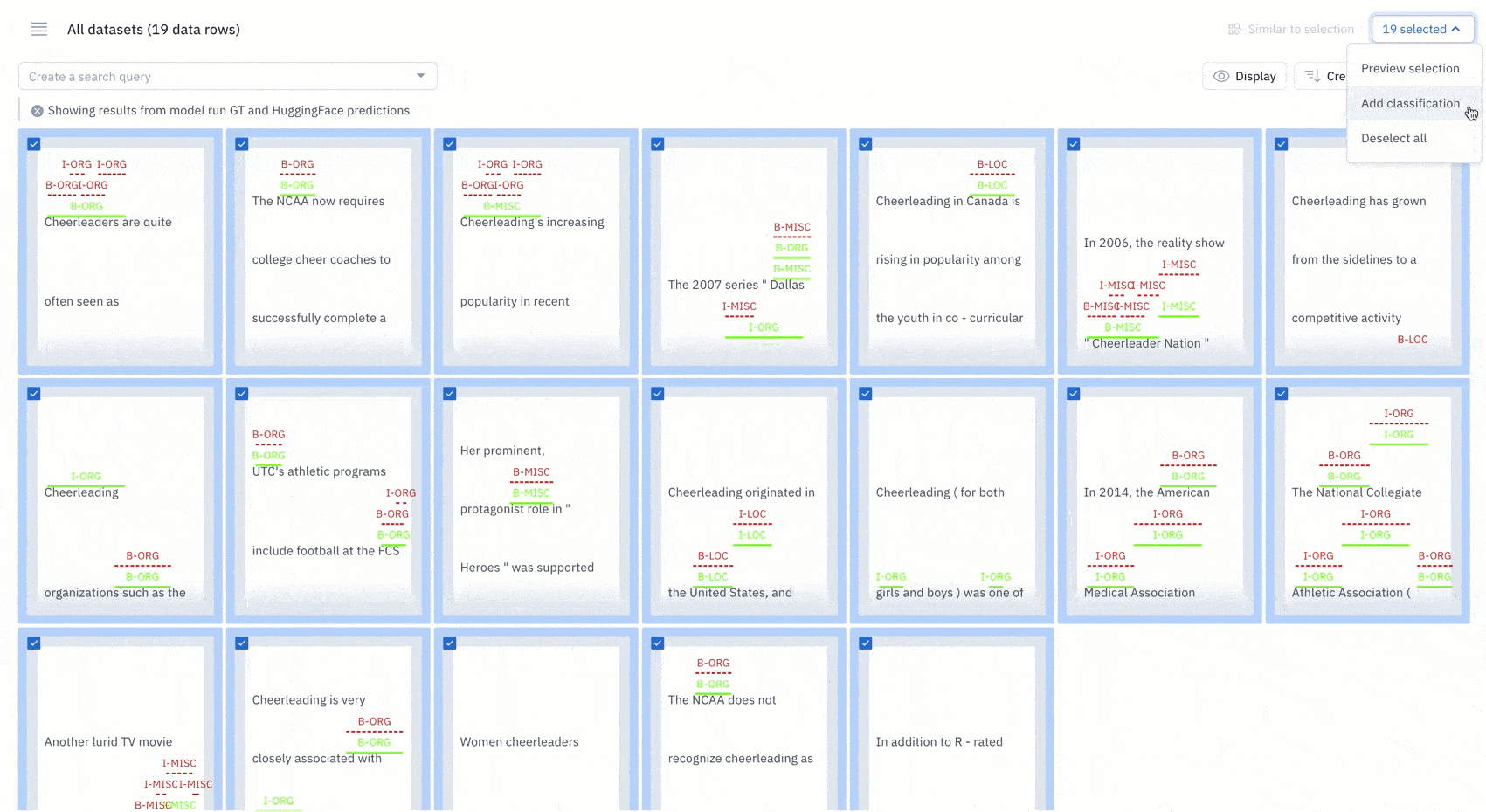
Once you’ve identified a group of data rows that share a set of common characteristics, you can bulk classify them.
Choose to bulk classify all data rows in one click
With this new feature, you can easily enrich your data with bulk classifications:
- Highlight all the data rows you wish to classify and select ‘add classification’ from the dropdown
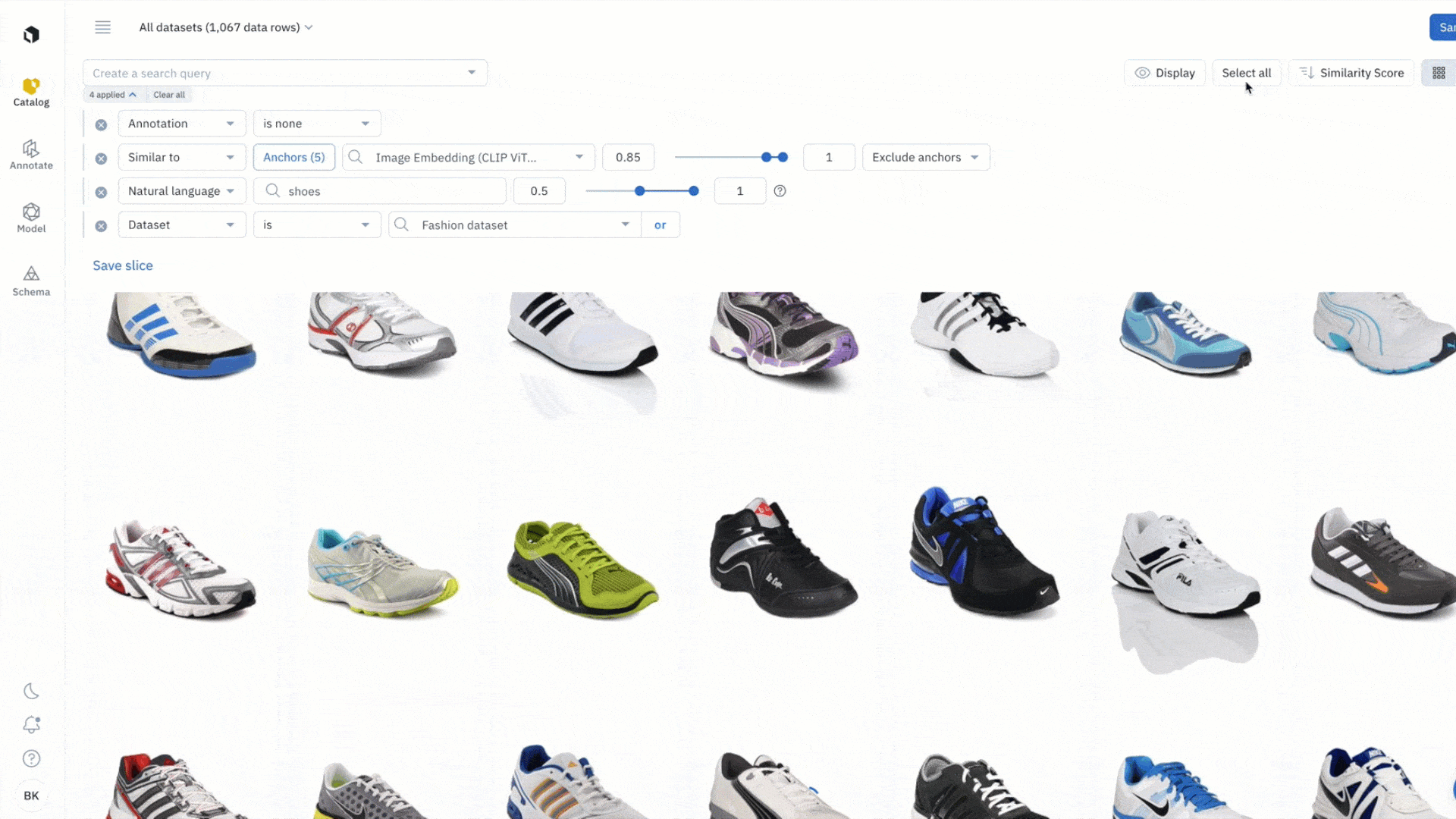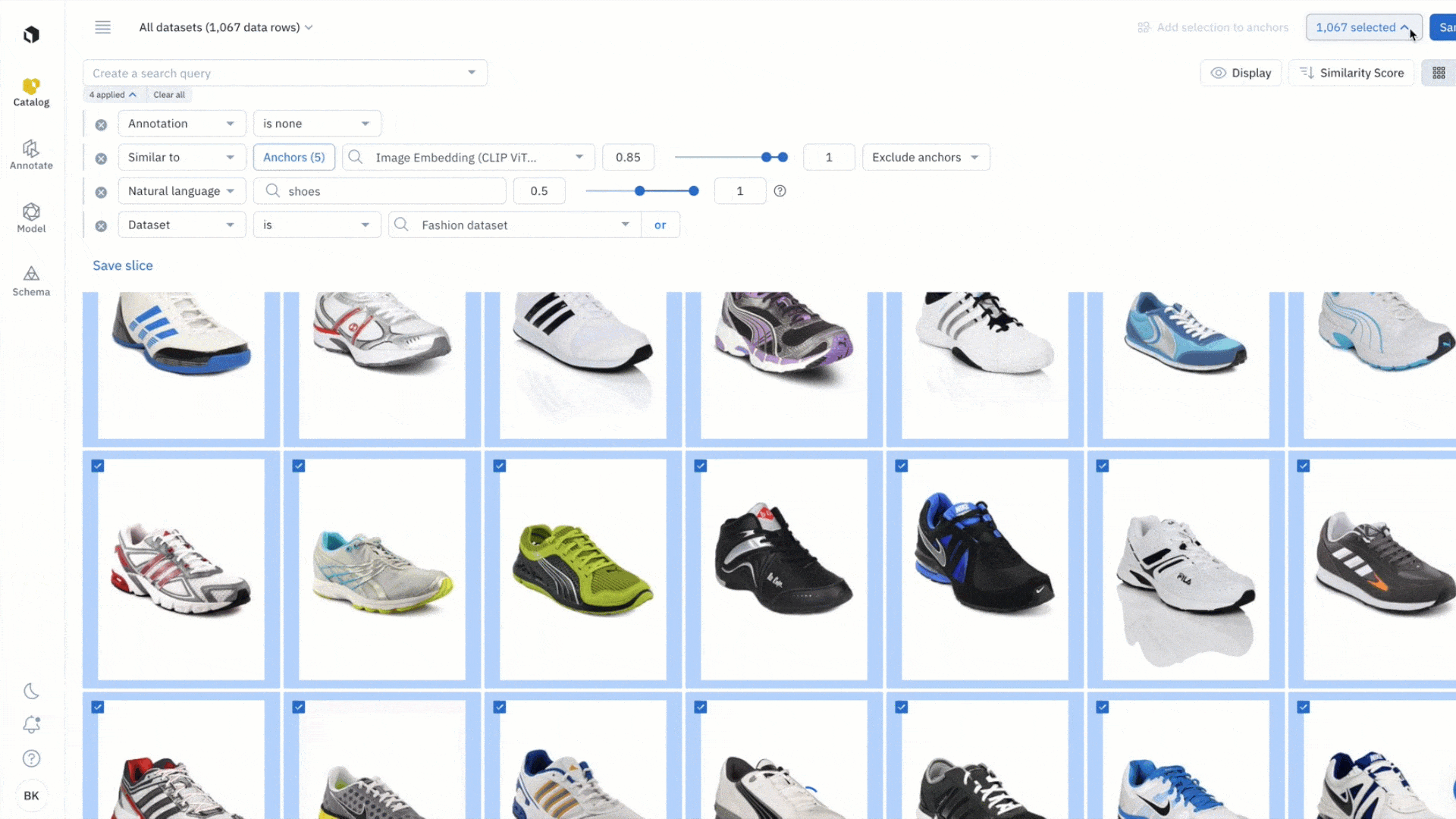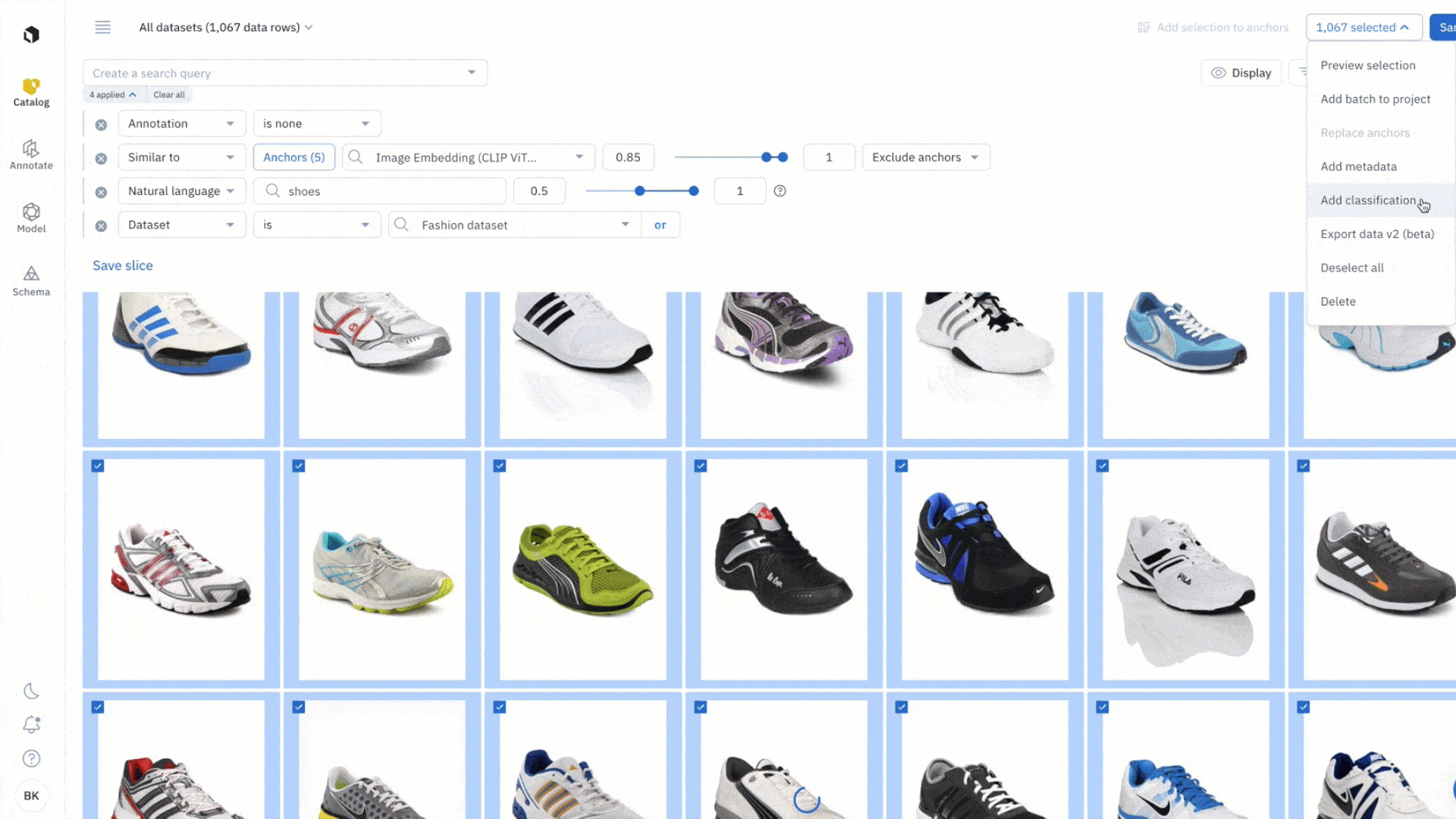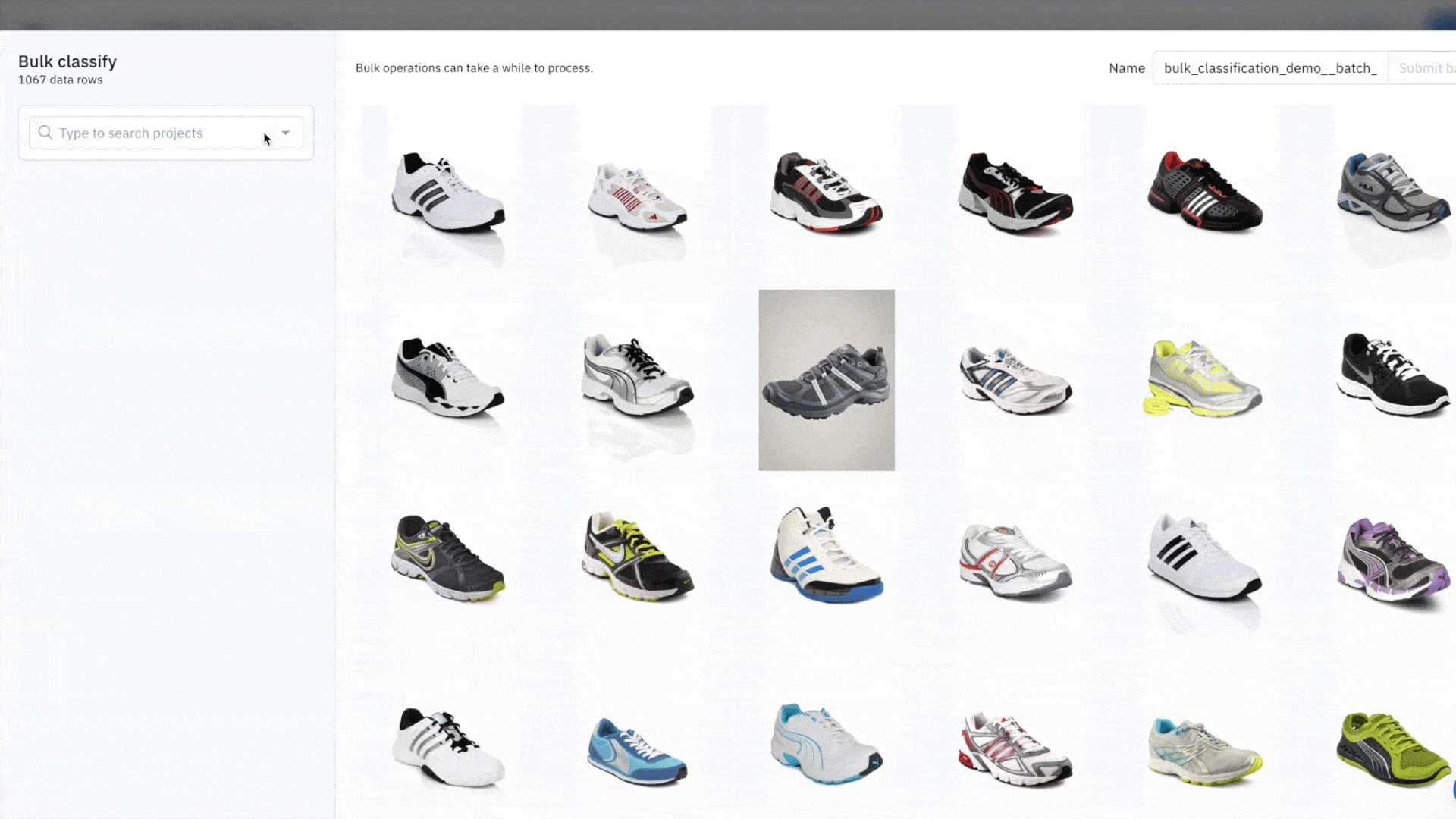
- Pick a destination labeling project that you wish to send the data rows to
Note: only projects whose ontologies contain a global classification question will appear in the dropdown.
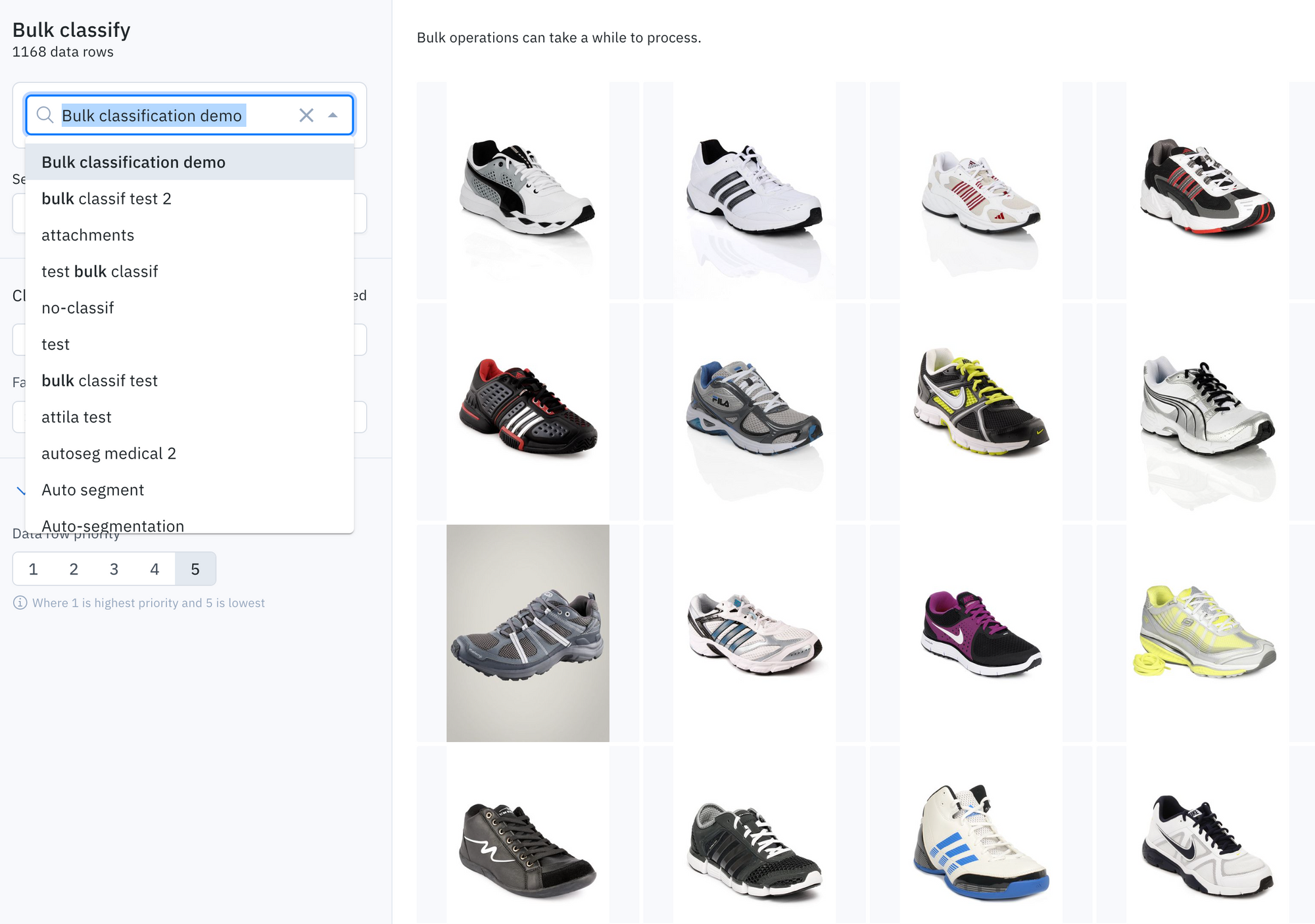
- Input classification values for the classification questions
Note: you need to answer all required classifications and subclassifications, but you do not need to answer all optional classifications and nested subclassifications.
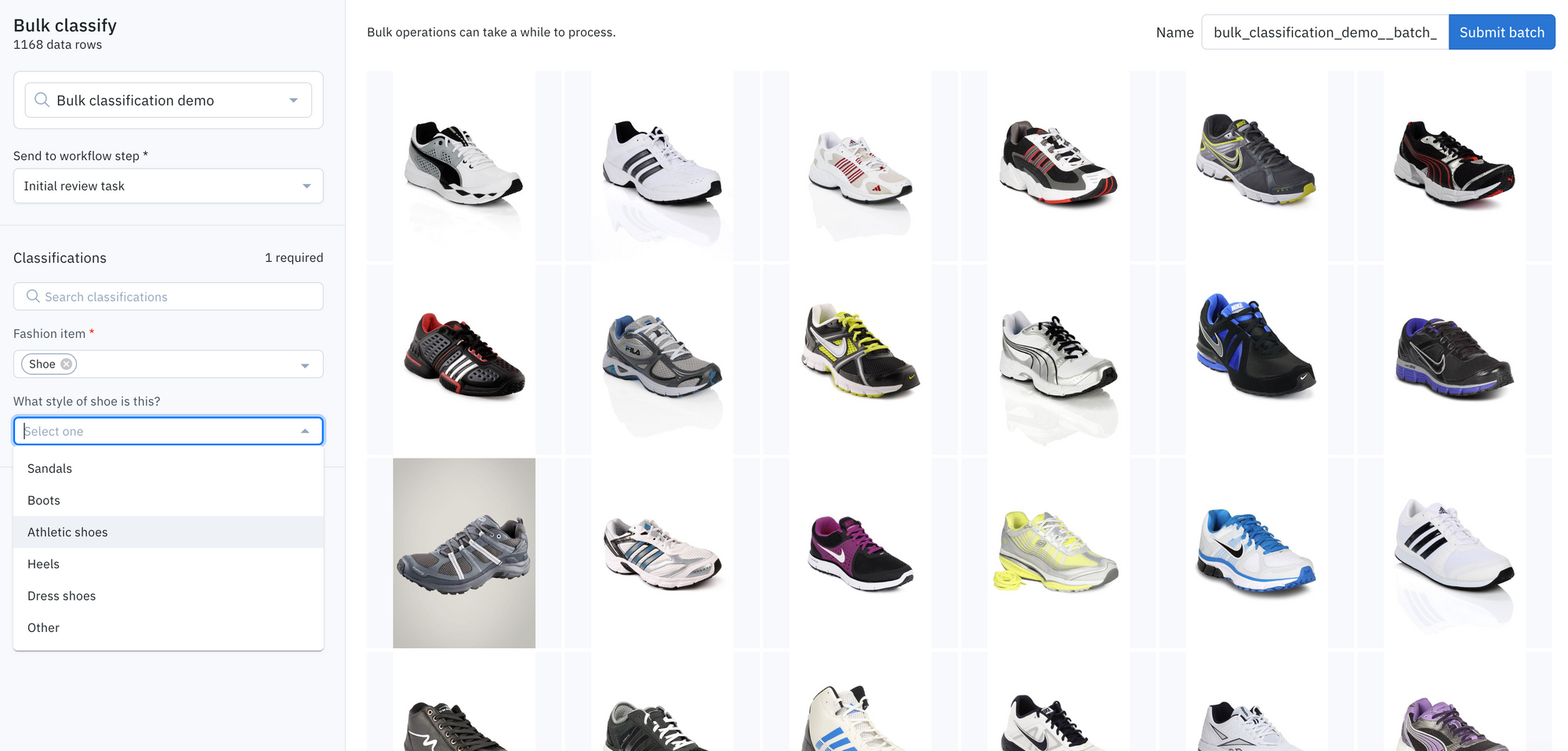
Send the data rows to any step in a labeling project’s workflow
Rather than sending data rows to be individually labeled, speed up and automate your labeling workflow.
You can specify which step of the labeling and review workflow these data rows with classifications should be sent to.

For example, you can send bulk classifications to “done” as labels, to speed up the labeling process, or you can send them to other steps such as the ‘rework’, ‘initial review task’, or ‘initial labeling task’ steps as labels to be reviewed or corrected with human-in-the-loop review.
Track the progress of the bulk classification job in the notification panel and view data rows in your project once completed.
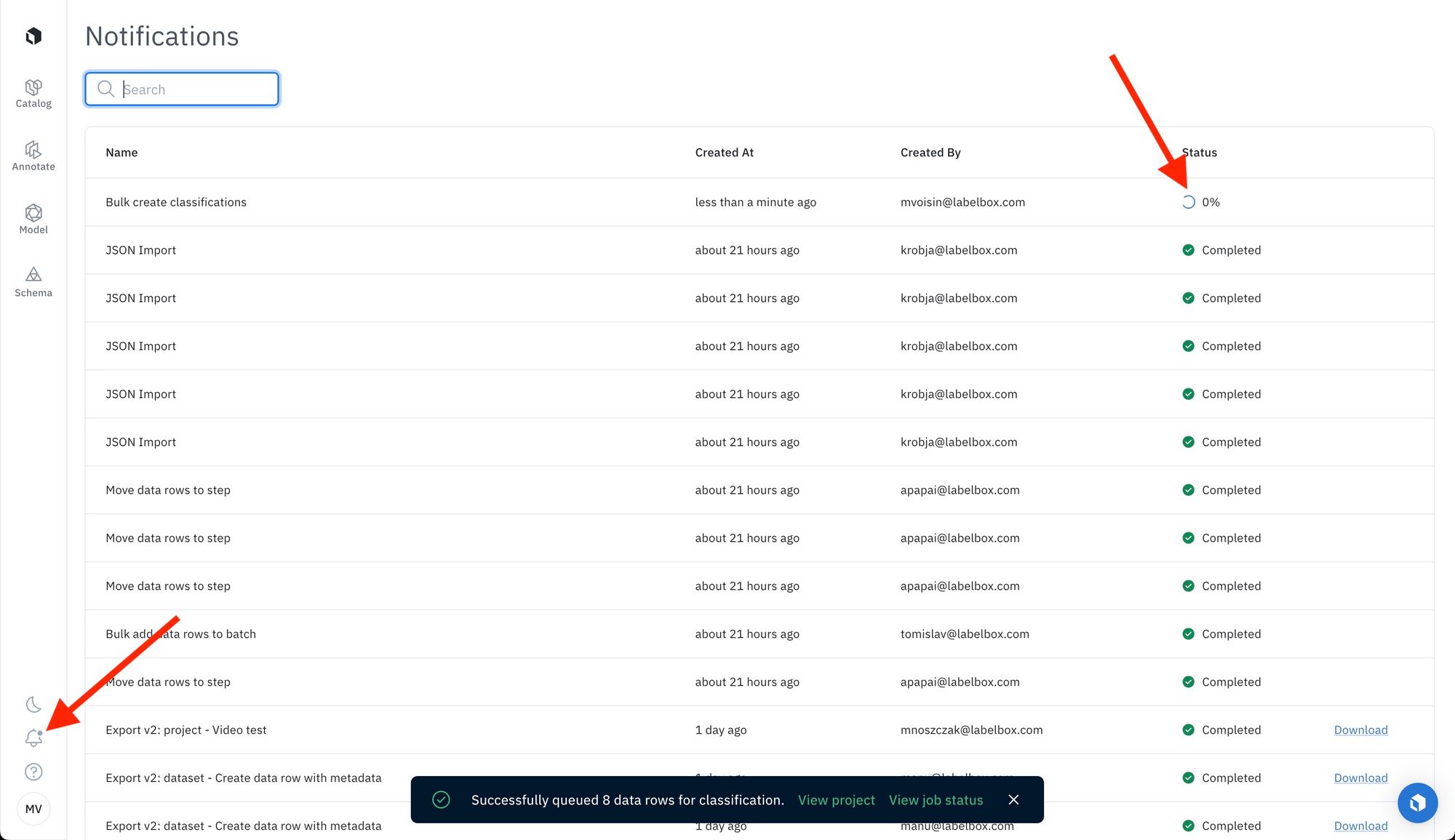
You can learn more about the bulk classification workflow in our documentation.
Rather than manually labeling or sifting through your data, classifying data rows in bulk helps your team:
Accelerate the labeling process and reduce associated costs
Generate labels faster than ever by replacing manual labeling with zero-shot learning and few-shot learning and human-in-the-loop review. Have unparalleled flexibility in determining whether to send classifications as pre-labels or labels for review, or if they’re robust enough to automatically be integrated into downstream workflows.
Automatically identify and classify instances of edge cases to improve your model’s performance
Surface examples of high-impact data, such as rare edge cases, to label in order to improve model performance. By doing so, you can rapidly identify other similar data instances and classify them in bulk, leading to a significant improvement in the model's performance with little to no time investment.
Organize and enrich your data to answer critical business questions in a few clicks
Leverage bulk classification to uncover valuable trends and gain deeper insights from your data, enabling your team to make more informed business decisions. With just a few clicks, you can quickly and accurately categorize vast amounts of data, eliminating the need for manual labeling to free up valuable time and resources.
See bulk classifications in action
Click through the tour below to learn how bulk classification works:
For a more detailed walkthrough with a demo video, check out a recent blog post on utilizing zero-shot and few-shot learning with Open AI embeddings.
All Labelbox users can now try bulk classifying data in Catalog. If you’re not a current Labelbox user, we encourage you to create a free account to get started today.


