
 All guides
All guidesUsing Labelbox and foundation models to generate custom embeddings and curate impactful data

One of the biggest challenges that ML teams face is how difficult it is to select the right data to improve their ML models. From working with hundreds of teams, we’ve seen that ML teams possess a vast amount of unlabeled data, but lack a structured process for effectively finding and prioritizing specific data that can dramatically improve model performance.
This manifests itself in the form of trying to find specific examples of an edge case where your model is struggling, or in the case of wanting to surface all occurrences of a rare data point that needs to be labeled in priority. In these cases, what is the best way for your team to efficiently surface this high-impact data?
What will you learn in this guide?
In this guide, we'll show you how you can use a foundation model, such as Hugging Face’s embedding extractors, combined with Labelbox’s search capabilities to select impactful data. This technique will help your team quickly enrich your data with the latest advances in off-the-shelf models and embeddings.
By the end of this guide, you’ll know how to:
- Generate custom embeddings with Hugging Face using a single line of code and upload your data to Labelbox in order to better explore and visualize your data.
- Better understand the distribution of your data and quickly find similar high-impact data.
- Use Labelbox as a native similarity search engine, where you can leverage both off-the-shelf embeddings computed by Labelbox (for image, text, and documents) and upload your own custom embeddings to quickly find all instances of similar data.
What are embeddings?
In machine learning, an embedding, or feature vector, is an array of numbers assigned to an asset by a neural net. Assets that have similar content will also have similar embeddings.
For example, in a dataset comprising images of apples and oranges, an appropriate embedding used for image similarity will show that all the vectors corresponding to apples have similar values. The vectors for all images of oranges will also be grouped together.
In other words, the neural network acts as a feature extractor: it extracts an embedding vector that contains rich information about the data.
Off-the-shelf embeddings vs custom embeddings
When you connect your data to Labelbox, we automatically compute off-the-shelf embeddings on your data – this includes CLIP embeddings for images and PDFs and All-mpnet-base-v2 embeddings for text. These off-the-shelf embeddings are a useful starting point for you to explore your data and conduct similarity searches.
However, in some cases where your data has unique attributes, you may want to use your own custom embeddings to power your data selection. Labelbox allows you to upload up to 100 custom embeddings in addition to the off-the-shelf embeddings that are automatically computed.
You can easily compare the results of these custom and provided off-the-shelf embeddings in Labelbox to discover the best embeddings to use for data selection.
How to upload custom embeddings
First, connect your data with Labelbox. You can integrate your cloud storage bucket with Labelbox via IAM delegated access:
How to set up a delegated access integration with Labelbox
Once you’ve successfully uploaded your data, Labelbox will automatically compute off-the-shelf embeddings on your data.
You can then compute and upload custom embeddings from Hugging Face on your data:
Follow along in this Colab notebook with examples shown using ResNet-50 embeddings from Hugging Face.
- Import Labelbox into your notebook
# for labelbox
!pip3 install -q labelbox[data]
import labelbox as lb2. Import the ADVLib. This is a library built by Labelbox for you to upload custom embeddings.
# for custom embeddings in Labelbox
!pip3 install -q 'git+https://github.com/Labelbox/advlib.git'
#ndjson
!pip3 install -q ndjson
import ndjson
import time3. Select the data rows (images or text) in Labelbox on which you want to add custom embeddings.
# get images from a Labelbox dataset
dataset = client.get_dataset("clemr01l42uil07y36qkq7ygn")
drs = list(dataset.export_data_rows(timeout_seconds=9999))
data_row_ids = [dr.uid for dr in drs]
data_row_urls = [dr.row_data for dr in drs]4. Use Hugging Face to generate your custom embeddings by loading a specific neural network (e.g. Resnet50).
# import HuggingFace
!pip3 install -q transformers
!pip3 install -q timm
# load a neural network from HuggingFace
import transformers
transformers.logging.set_verbosity(50)
import torch
import torch.nn.functional as F
import PIL, requests
from tqdm import tqdm
# get ResNet-50
image_processor = transformers.AutoImageProcessor.from_pretrained("microsoft/resnet-50")
model = transformers.ResNetModel.from_pretrained("microsoft/resnet-50")
5. Generate custom embeddings by iterating over your image or text data.
Note: This should take approximately ~2 minutes for 512 images. For the similarity search function to work in Labelbox, you must upload at least 1,000 embeddings.
- Retrieve your images/text and run model inference
# process images
img_hf = image_processor(imgs, return_tensors="pt")
# generate resnet embeddings, thanks to inference
with torch.no_grad():
last_layer = model(**img_hf, output_hidden_states=True).last_hidden_state- Remember to do global pooling on the last layer of your embedding to reduce dimensionality
resnet_embeddings = F.adaptive_avg_pool2d(last_layer, (1, 1))
resnet_embeddings = torch.flatten(resnet_embeddings, start_dim=1, end_dim=3)6. Create the payload to upload custom embeddings to Labelbox in the form of an NDJSON file.
# create the payload
payload = []
for (dr_id,resnet_embedding) in zip(dr_ids, resnet_embeddings):
payload.append({"id": dr_id, "vector": resnet_embedding})
# write to NDJson file
with open('payload.ndjson', 'w') as f:
ndjson.dump(payload, f)7. Pick an existing custom embedding or create a custom embedding.
# max pool to reduce dimensionality
resnet_embeddings = F.adaptive_avg_pool2d(last_layer, (1, 1))
resnet_embeddings = torch.flatten(resnet_embeddings, start_dim=1, end_dim=3)
8. Upload your payload of custom embeddings into Labelbox.
!advtool embeddings import <EMB ID> ./payload.ndjson9. Use Labelbox Catalog UI to start conducting similarity searches.
How to quickly find instances of similar data
Once you have uploaded your custom embeddings to Labelbox, you can focus on curating data in Catalog that will dramatically improve your model’s performance.
- Identify an edge case or rare example image/text you want to use to find similar data.
This can include examples of data on which your model might be struggling. For example, let’s say the model is incorrectly classifying images with sparse patches of grass as having been affected by a wildfire.
In the example below, the model appears to struggle on recognizing images with ‘no wildfire'
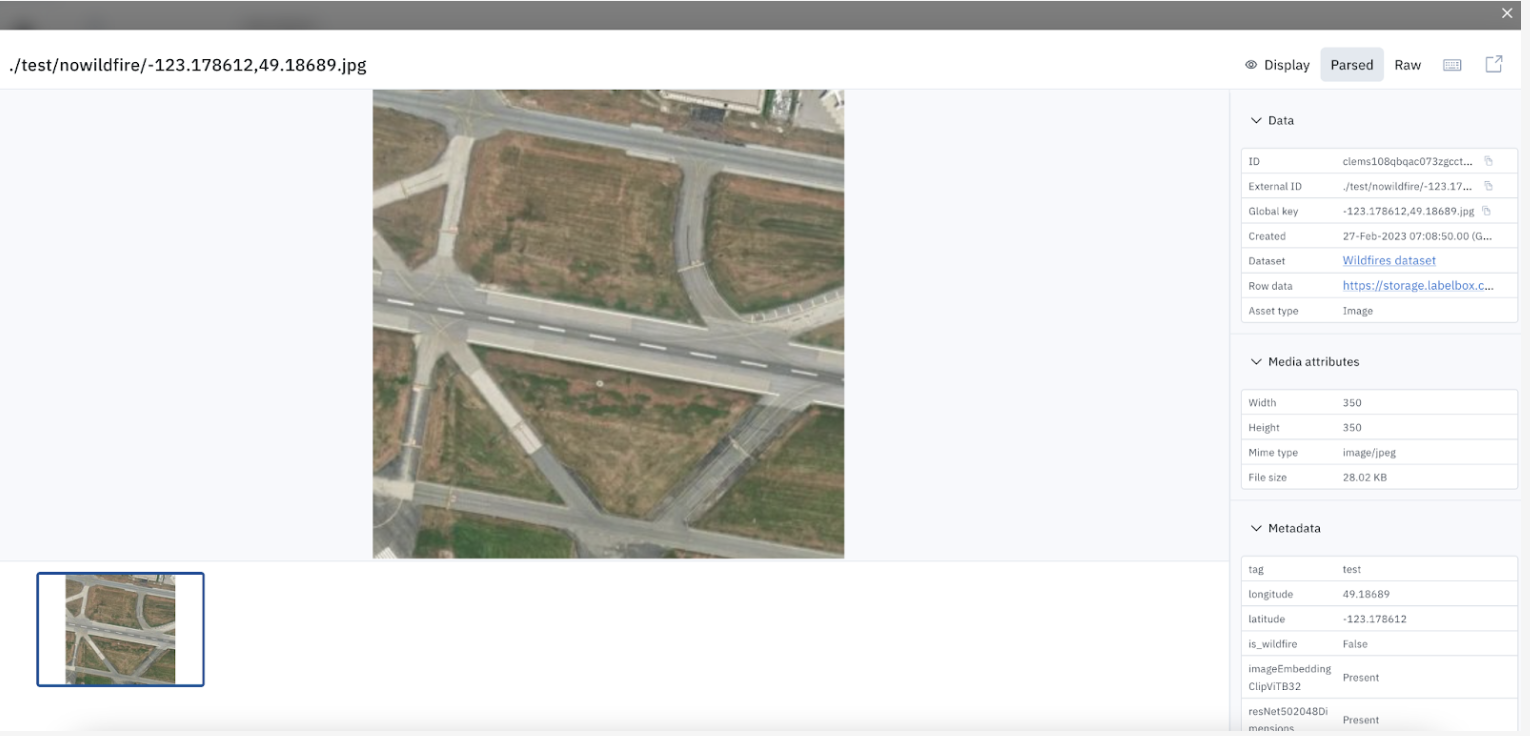
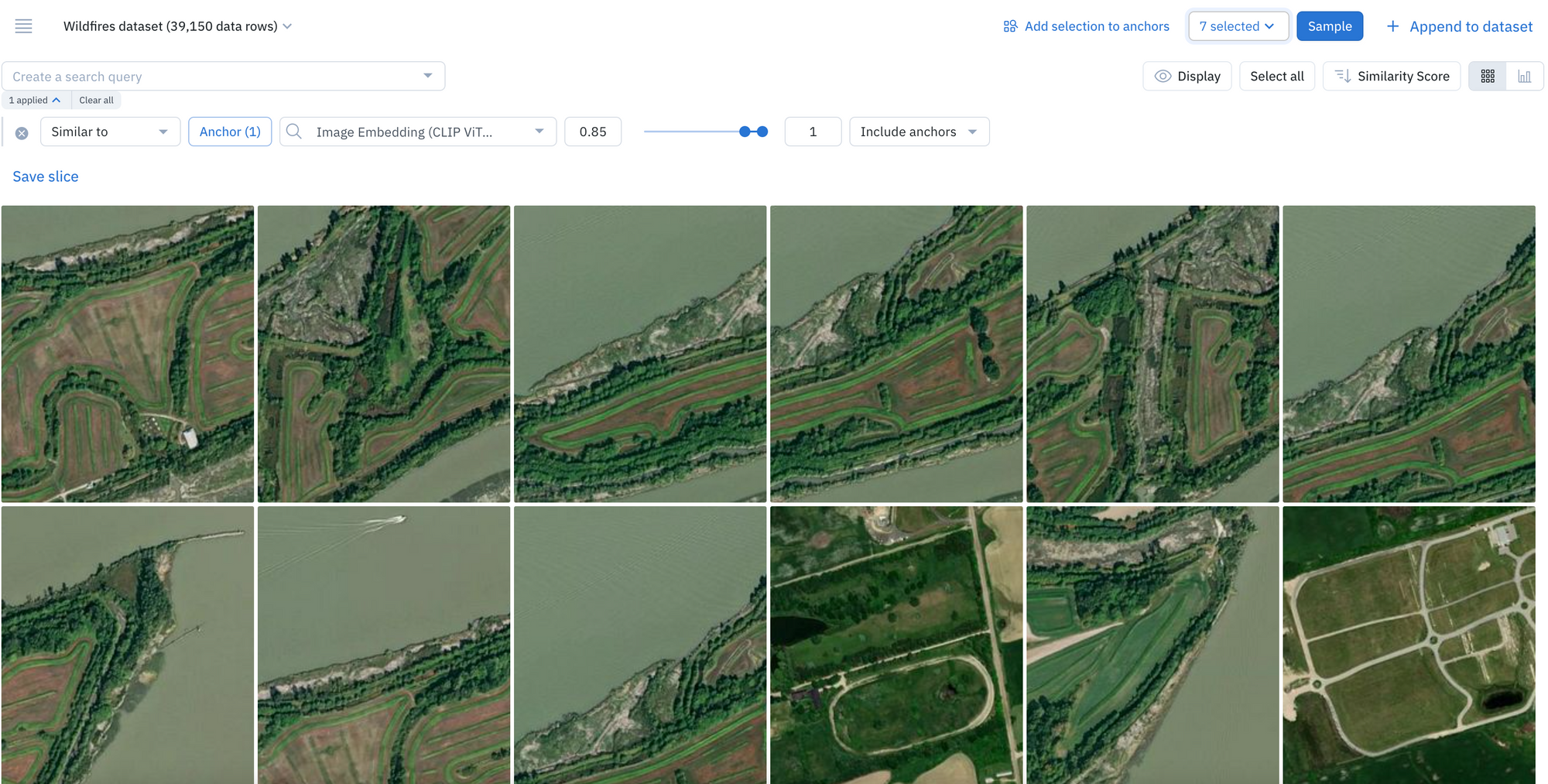
2. Surface all instances of similar data.
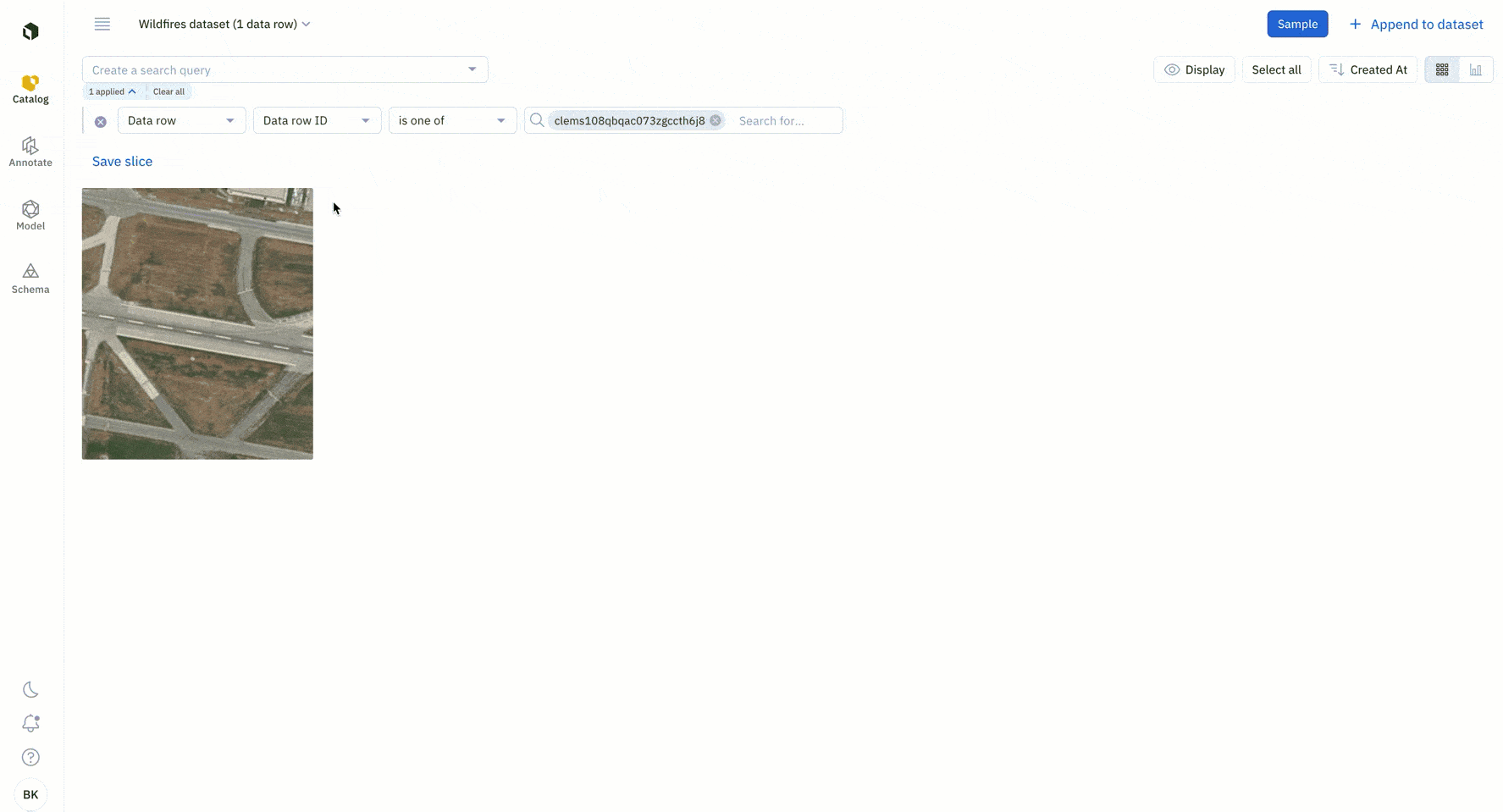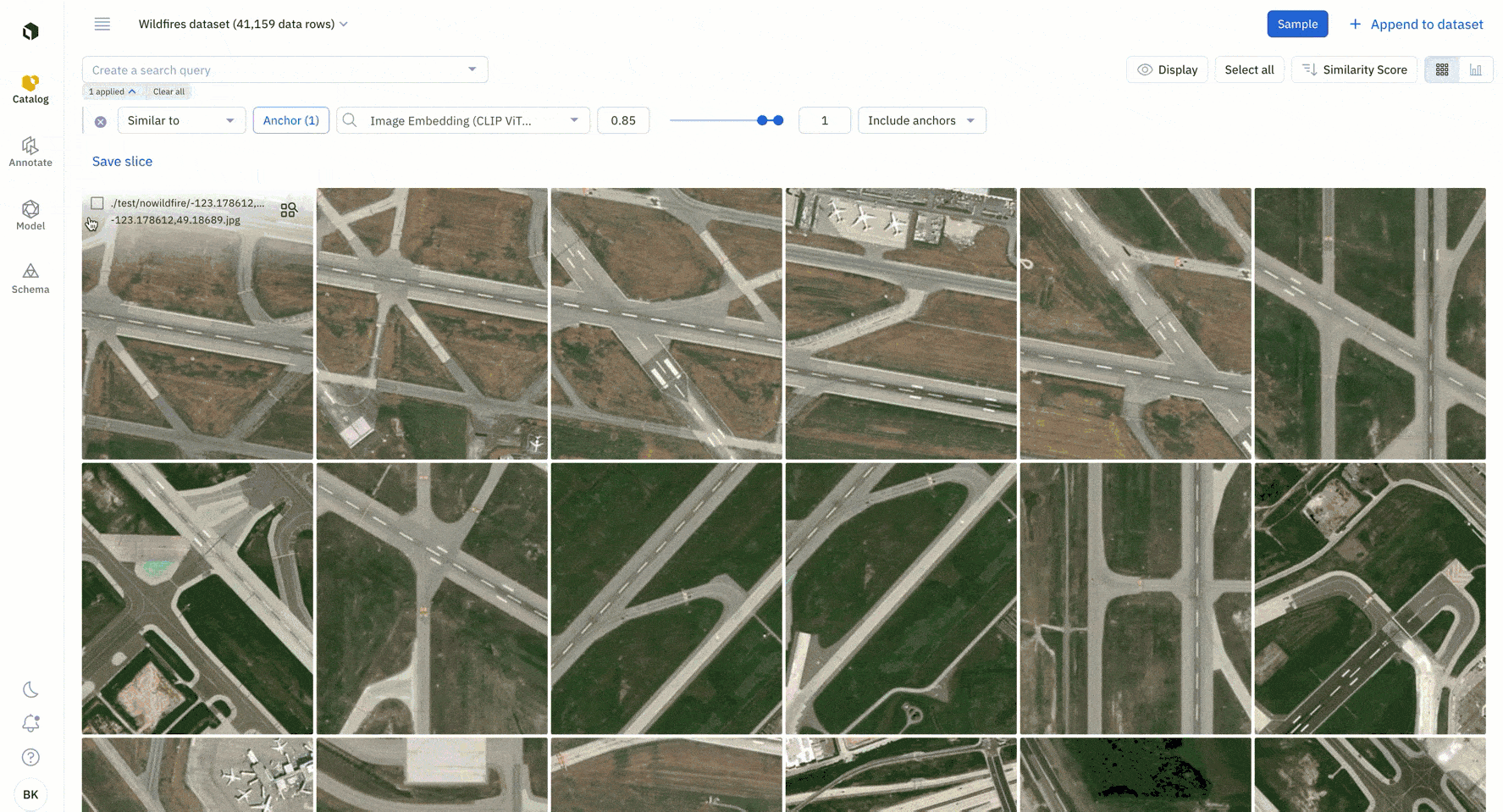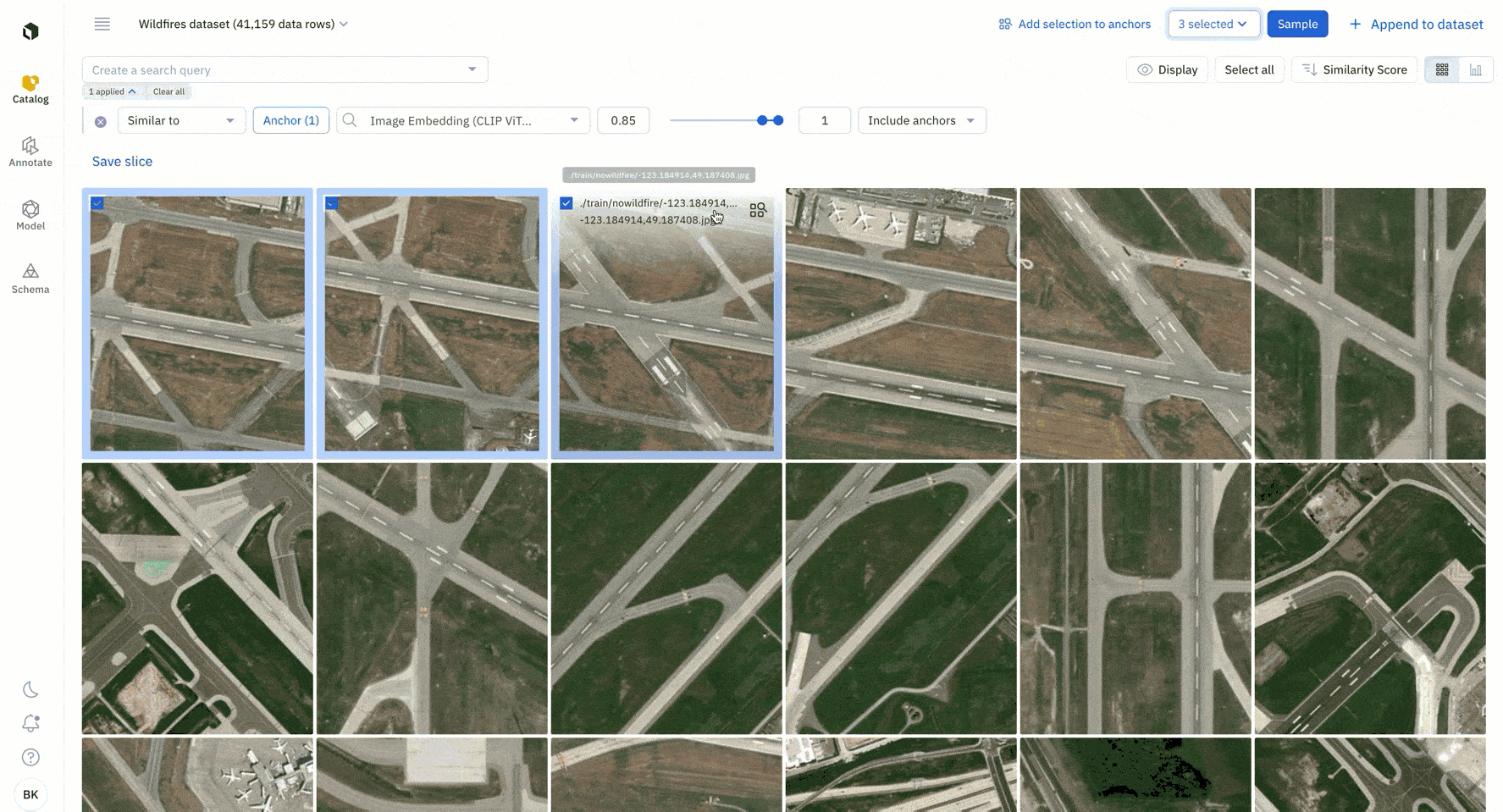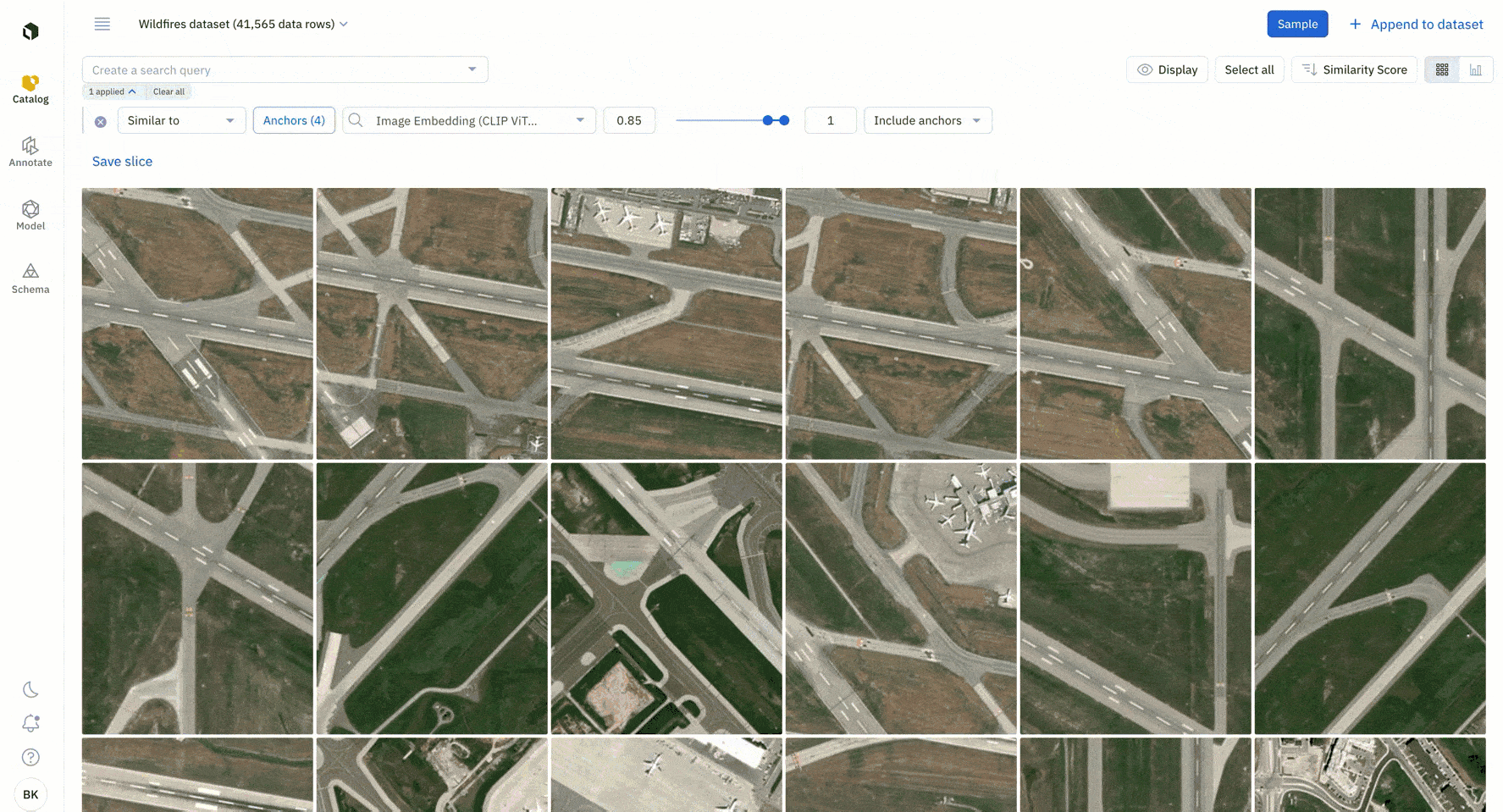
You can run similarity searches to find all instances of similar data. A similarity search will automatically surface all similar data rows – you can select multiple data rows as anchors to continue to refine your similarity search.
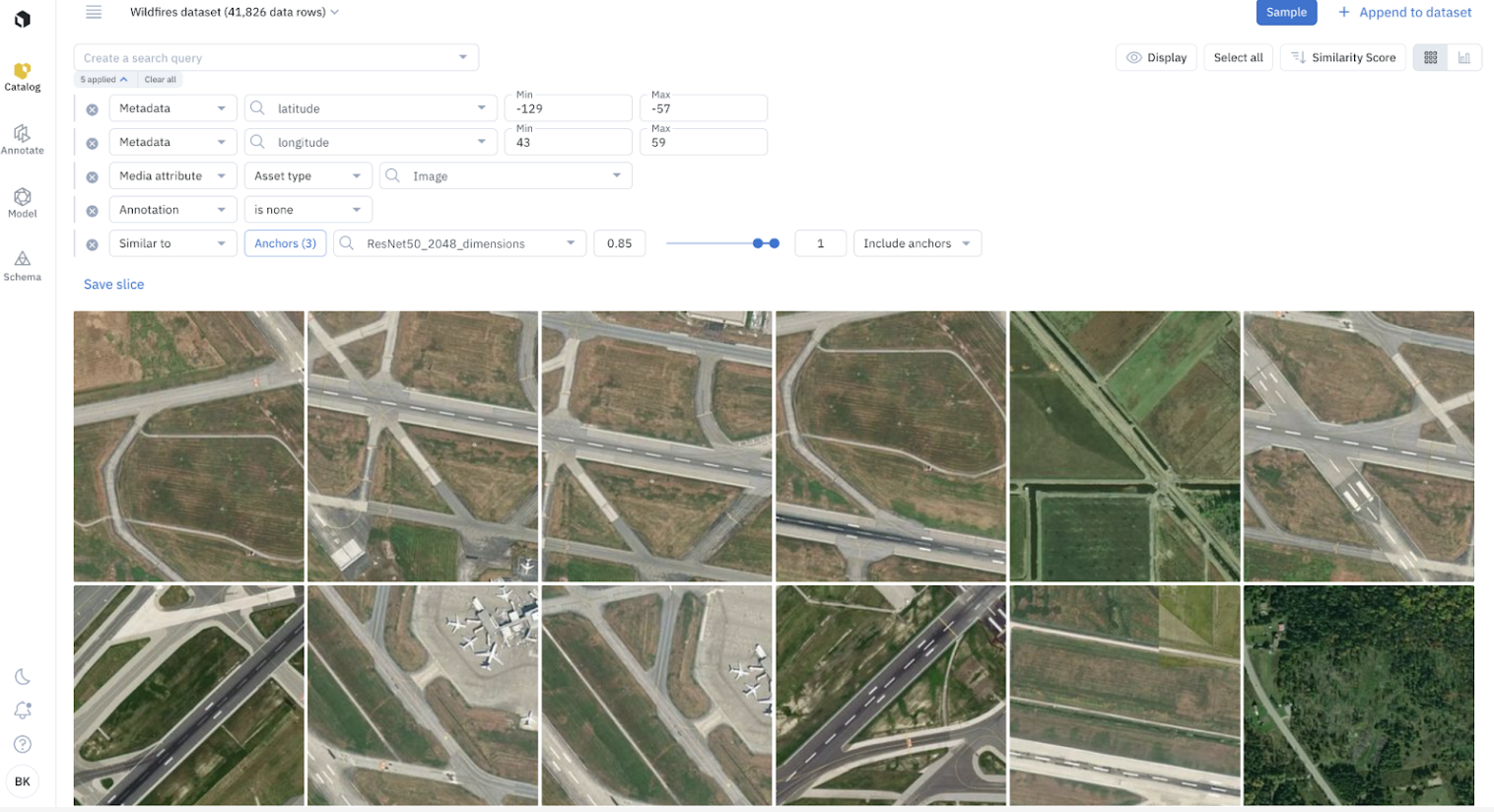
3. Combine a similarity search with other search filters.
To filter the dataset even further, you can combine a similarity search with other search filters. This includes filtering on metadata, media attribute, annotation, and more.
4. Compare similarity search results.

You can compare the results of the similarity search on different embeddings (across off-the-shelf and custom embeddings). This gives you an understanding of which embeddings are most effective towards providing your desired results.
5. Add all instances of similar data to a labeling project or save it as a slice.
Once you’ve found additional examples of similar data rows on which your model is struggling, you can queue them to your labeling project in priority or save the filters as a slice.
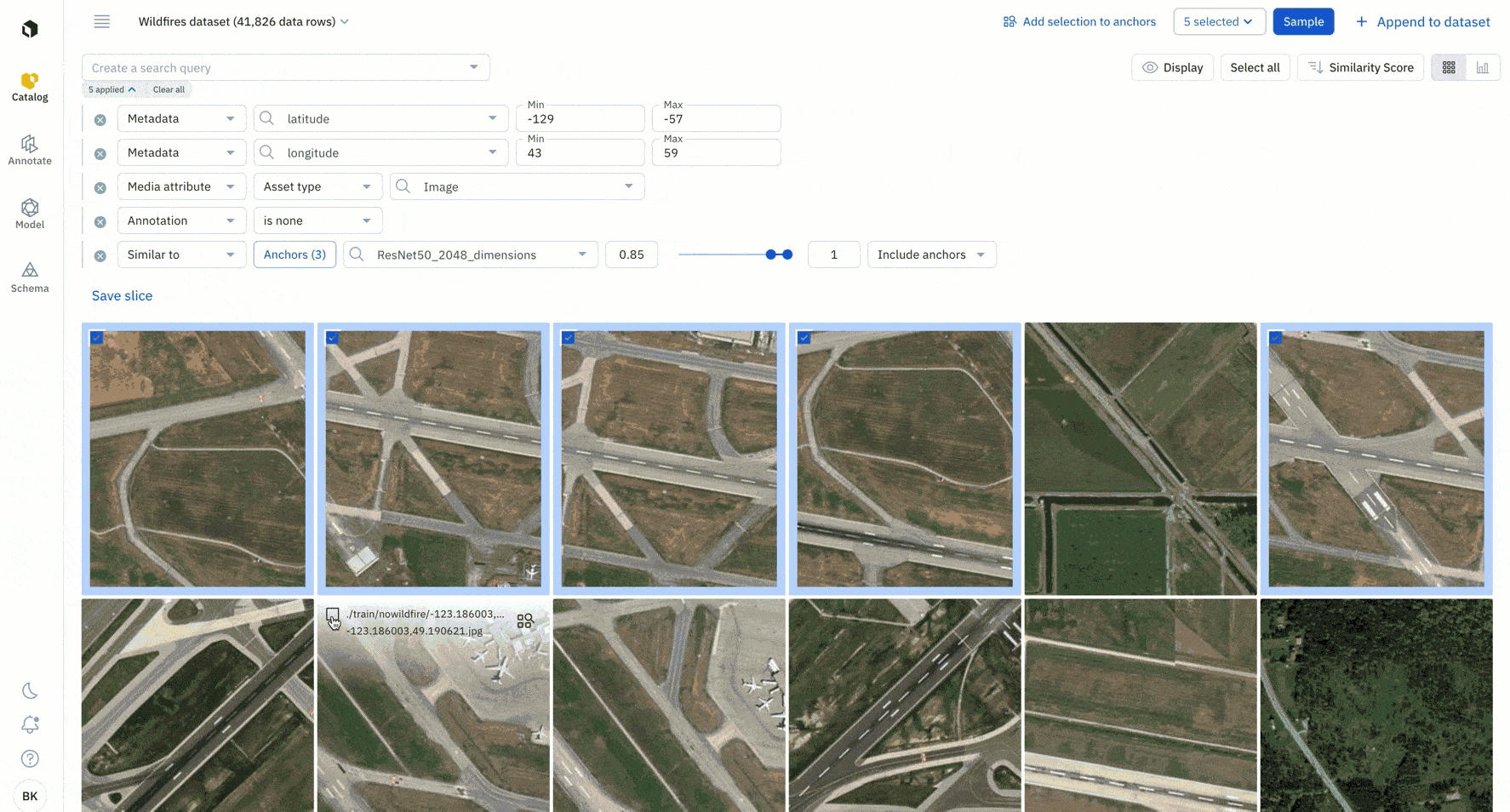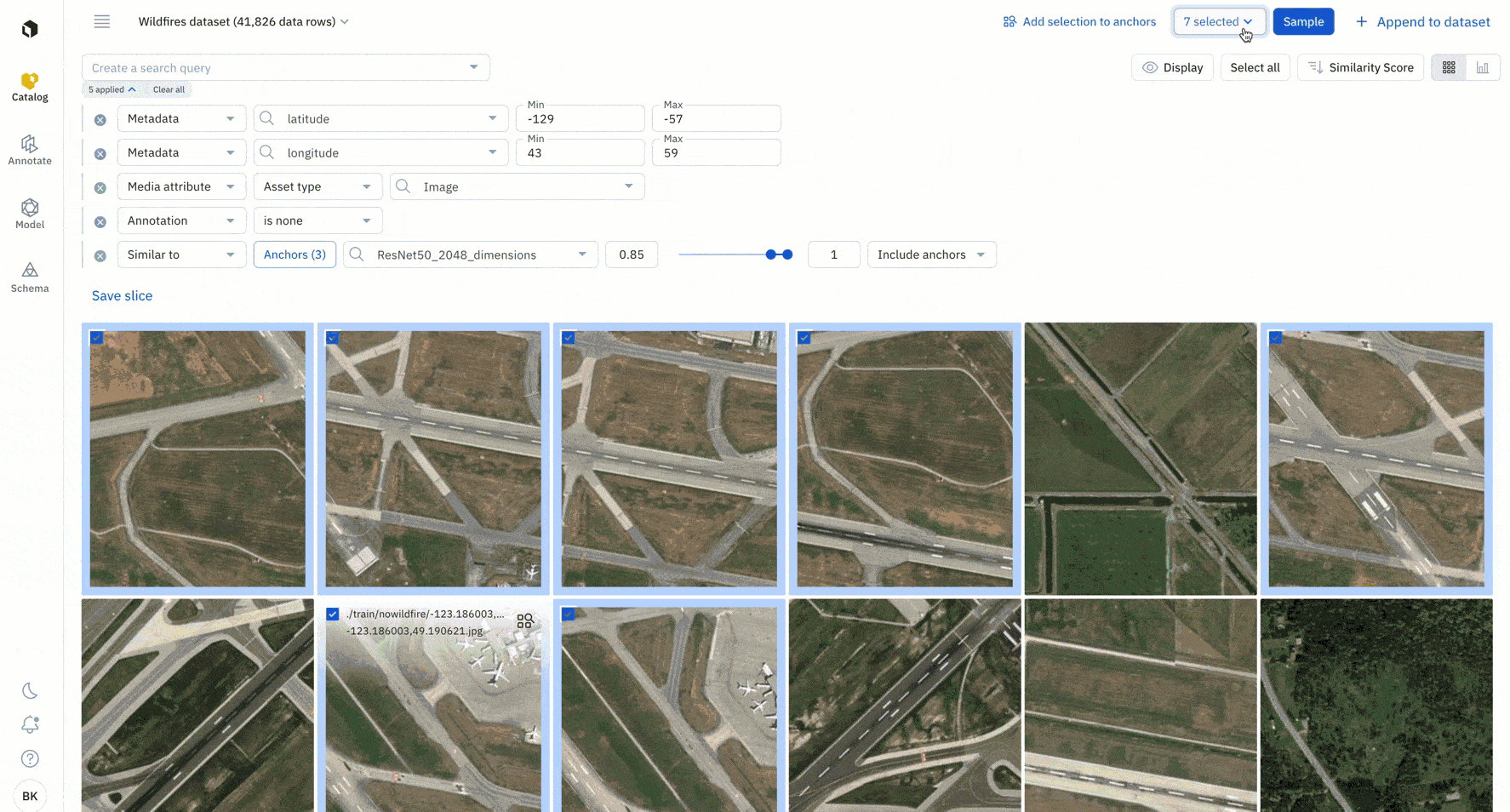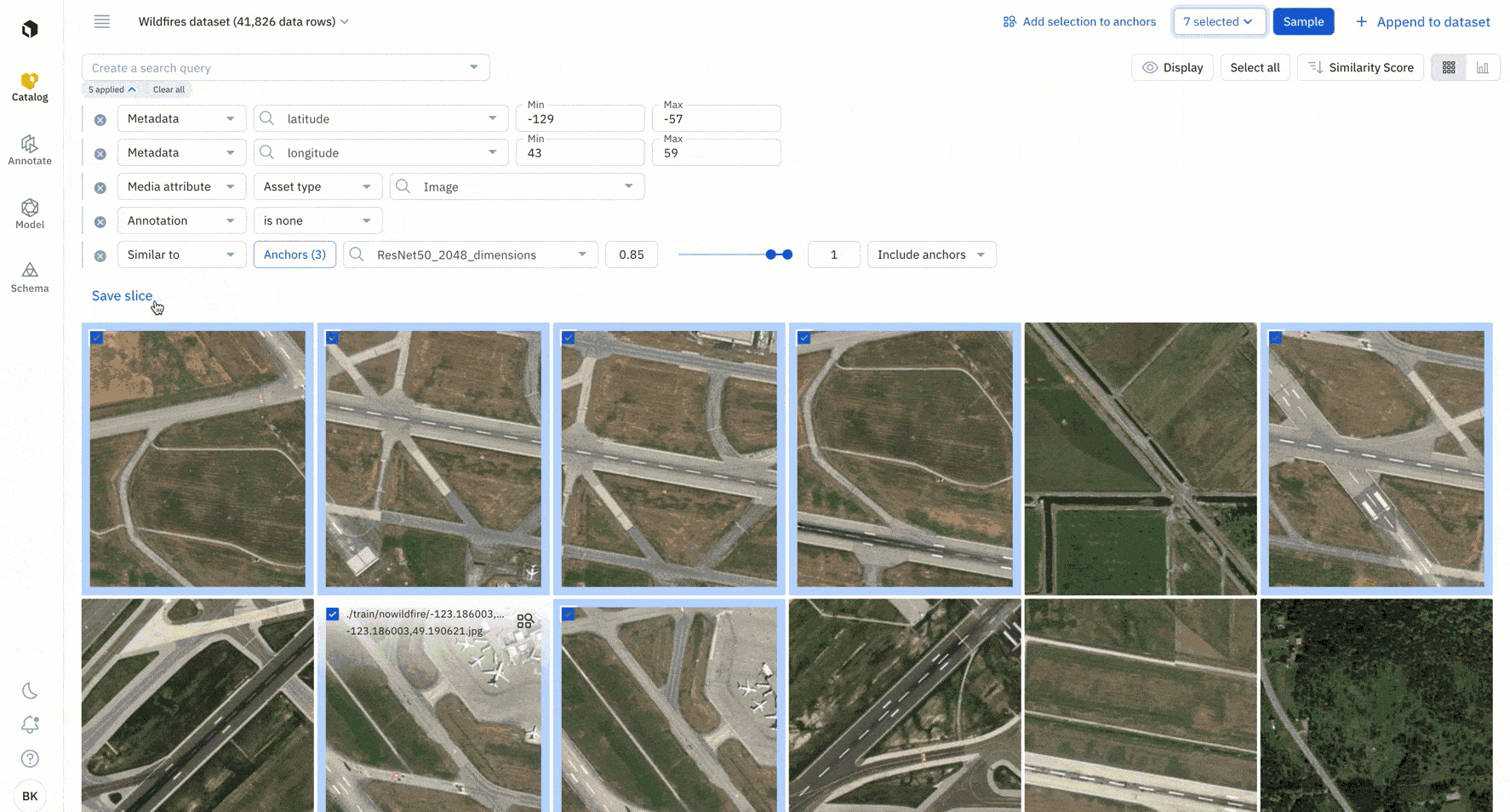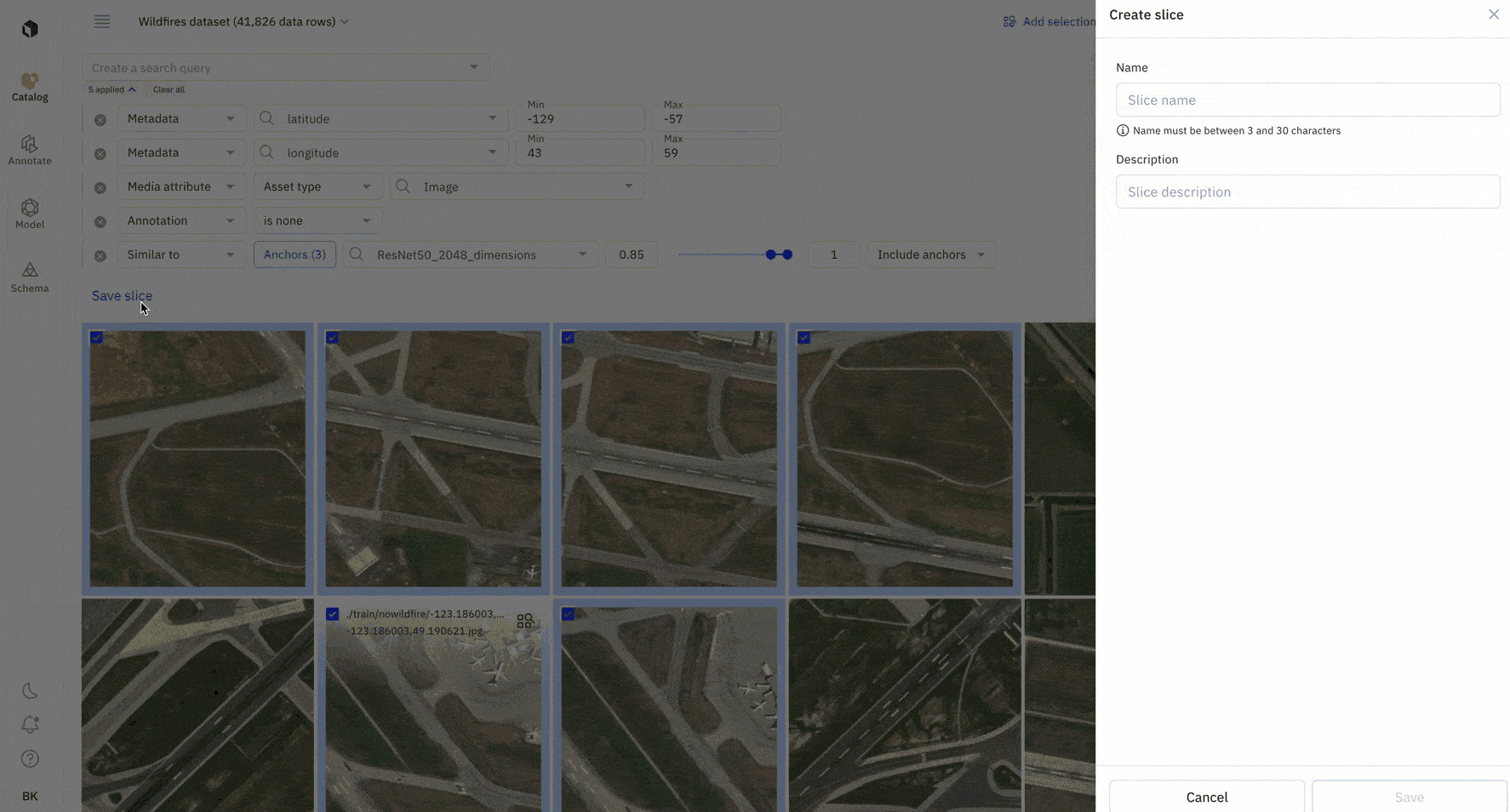
By saving your similarity search as a slice, any new incoming data that matches the search criteria will automatically show up in the slice. This enables automatic data curation.
Learn more about other key ML workflows that you can perform using similarity search in this guide.
Leveraging embeddings as a powerful similarity search technique can help you find specific data points within an ocean of data. With a similarity search, you can easily query and curate specific data that will dramatically improve your model performance. If you’re interested in learning more, please check out the additional resources below.
Additional resources:


