
 All blog posts
All blog postsLabelbox•October 23, 2023
RLHF vs RLAIF: Choosing the right approach for fine-tuning your LLM

In a previous blog post, we explored how reinforcement learning with human feedback (RLHF) is a powerful way to fine-tune large language models (LLMs). However, as teams adopted this trial-by-error method, some found that the human expertise required for their project presented a challenge. For some, the amount of human feedback required made it a costly process; others found that the process of obtaining this feedback was slow and delayed the pace of iteration.
As a result, a new method of reinforcement learning emerged: one that relied on AI-based feedback instead of human feedback. In research, reinforcement learning with AI feedback (RLAIF) resulted in similar improvements in fine-tuning an LLM, but with far fewer resources. For those developing AI solutions for specific and complex real-world tasks, however, the choice between the RLHF and RLAIF might not be quite so clear cut.
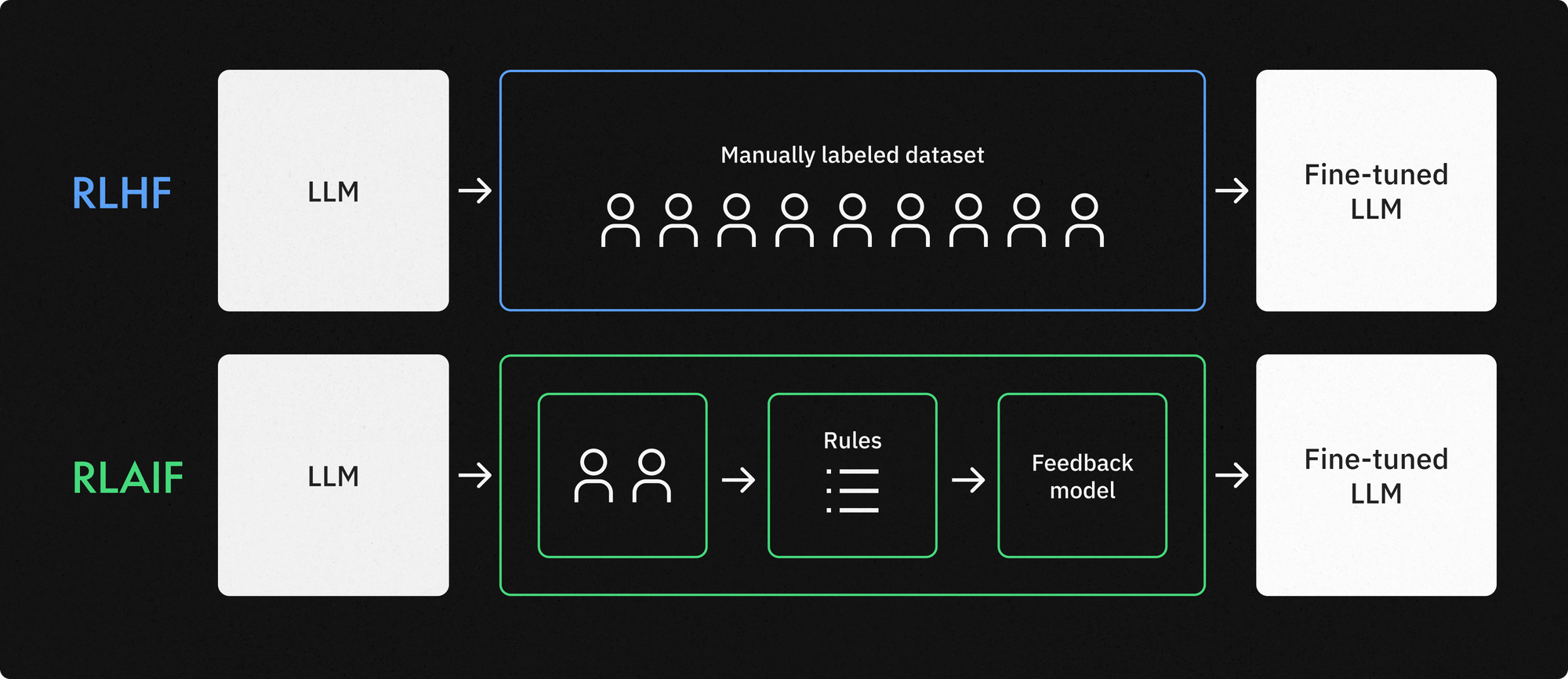
Read on to learn how these two methods differ, the pros and cons of each, and how to choose the right method for your fine-tuning project.
The pros and cons of RLHF
RLHF gained prominence as a method for fine-tuning LLMs to achieve complex goals. It has been successfully leveraged to develop some of the most powerful and popular LLMs available today, including GPT 3.5 by OpenAI and Claude by Anthropic.
RLHF is ideal for training AI systems for use cases such as content moderation, where humans have better judgment than AI for language that constitutes hate speech, bullying, and other poor behavior. Leveraging human preferences enables teams to train AI systems on human intuition — a far more complex operation than simply identifying specific words or phrases.
Human feedback can also be easily understood by other people, making AI systems more transparent — and therefore, more trustworthy, for their end-users. In a world where AI is increasingly both distrusted and pervasive, transparency and explainability can be vital to ensuring that your AI solution is useful once it’s deployed.
As some AI teams learned, however, RLHF is not without its deficiencies. For use cases that require feedback from domain experts with specific knowledge and skill sets, the process can quickly become expensive and time consuming. It can also cause difficulties when scaling, as these costs will rise as the amount of data increases and the availability of human expertise remains scarce. Ensuring that the data management and labeling setup used for RLHF is secure and efficient can decrease the long-term time-to-value for this process.
Human feedback can also be subjective and inconsistent — which can lead to increased biases and confusion in your model’s performance, rather than the desired result of increased understanding of nuanced and complex situations.
The pros and cons of RLAIF
Reinforcement learning with AI feedback is a more recently developed method that uses another model — often another off-the-shelf LLM — to generate the reward signal for the model in training. You can also use previous versions of the model-in-training or a purpose-built model for this task. This method was developed with the goal of reducing human input — and therefore, time and costs related to training AI.
RLAIF is particularly useful for use cases that involve adherence to a specific set of rules or principles, such as fine-tuning an LLM to function as an AI assistant for your sales department. Teaching a model to recognize specific SKUs and use professional language will usually involve a list of rules, and a different LLM can be used to evaluate whether or not a specific rule was followed or broken by the model in training.
Because it reduces human input, teams leveraging RLAIF can usually expect the following benefits:
- Efficiency: RLAIF can be more efficient in terms of time and resources because it doesn't rely on human feedback, which can be slow and costly to obtain
- Consistency: AI-generated feedback can be more consistent and less subject to human biases, potentially leading to more stable training
- Scalability: RLAIF can scale better to tasks that require a vast amount of training data or when human expertise is limited or unavailable
- Automation: RLAIF can be automated, reducing the need for continuous human involvement in the training process
AI teams that rely solely on RLAIF for fine-tuning their model can also expect to see fewer benefits than RLHF in understanding complexity and nuance, however. The success of the RLAIF will also heavily depend on the model used to create feedback — choosing the right model for this process will likely make the difference between saving resources and wasting them.
Additionally, the amount of data required to train a model with this method can be substantial — and for complex and domain-specific use cases, using the right LLM for feedback generation can end up raising costs. And once you have the AI-generated feedback available, ensuring that it’s in the format required to train your model — reward signals, comparisons, demonstrations, etc. — can require more engineering hours and infrastructure development.
So which one is best?
As usual, the right choice will depend on your specific use case and its goals and requirements, the AI development and data management infrastructure you already have in place, and a host of other factors such as time, budget, the availability of domain experts, the suitability of available LLMs for feedback generation, etc.
In practice, a hybrid approach that combines the strengths of both RLHF and RLAIF methods will likely reap the most benefits for your team. For example, human feedback can be used to kickstart the fine-tuning process, and the model trained on that feedback can then be used to generate feedback for further training. Other ways to create a hybrid method include:
- Using an RLHF workflow to determine the set of rules to use in the prompt for the RLAIF workflow
- Fine-tuning in two iterations, once with RLHF and once with RLAIF
- Using an RLAIF workflow, but adding a human-in-the-loop to review, edit, and approve the AI-generated dataset before using it to fine-tune your LLM
With an AI platform that can support both learning methods and enables you to quickly set up new workflows, you can easily test both methods as well as multiple hybrid approaches to find the one that can produce the best results in terms of efficiency, cost, and quality.
With Labelbox, you can quickly and easily generate responses from an LLM or import responses as necessary and add them to a labeling project, when labelers can review and edit them in real time on the same platform. The labeled dataset can then be exported for fine-tuning. Watch the video below to see this RLHF workflow in action.
RLAIF is also easy with Labelbox’s soon-to-be-released Model Foundry solution. You can import responses from the model-in-training, query another LLM to prioritize or choose the correct responses for your use case based on a set of rules, and export the newly labeled dataset for fine-tuning downstream. Watch the video below for a quick demo of an RLAIF workflow with Labelbox Model Foundry.
Fine-tuning large language models is critical to ensuring that they work the way you need them to. Learn more about how you can better build and fine-tune LLMs with Labelbox.


