
 All guides
All guidesHow to build generative captioning and enrich product listings faster with foundation models

The rise of foundation models has enabled companies to seamlessly enrich all of their products and services with rich captions and descriptions in minimal time and with little human effort required. Organizations can now use AI taught to automatically generate descriptions for product listings based on a wide range of images or product specifications. By incorporating a powerful generative captioning system, companies that span retail and internet & media can now readily enhance customer assets and foster stronger connections to boost customer loyalty and increase key metrics such as conversion rate, engagement, and average order value.
However, building a robust and effective AI-powered captioning system can be challenging for many teams. Some key challenges include:
- Data quality and quantity: Building a strong captioning system that makes accurate predictions requires a vast amount of high-quality data. Orchestrating data from various sources can not only be challenging to maintain, but even more difficult to sort, analyze, and enrich with quality insights. Furthermore, there are situations where the volume and speed of text generation tasks required means it is not efficiently achieved through human input alone.
- Scalability: As a business grows and their catalog expands, the system should be able to handle new and incoming data. Additionally, it can be a costly process when allocating significant portions of an individual’s or team’s time to repetitively generating text outputs. Ensuring scalability and maintaining model performance with new data can be particularly challenging for teams relying on in-house solutions or disparate ML tools.
- Privacy and Security: When it comes to customer data and specific product information, ensuring user privacy and safeguarding against potential security violations is critical to maintain trust with customers and maintaining a relevant website/app.
Labelbox is a data-centric AI platform that can help automate generative captioning systems. Rather than spending valuable time building in-house or relying on disparate systems and applications, teams can leverage Labelbox’s platform to seamlessly build an end-to-end workflow that integrates with your existing tech stack and helps teams build AI systems faster.
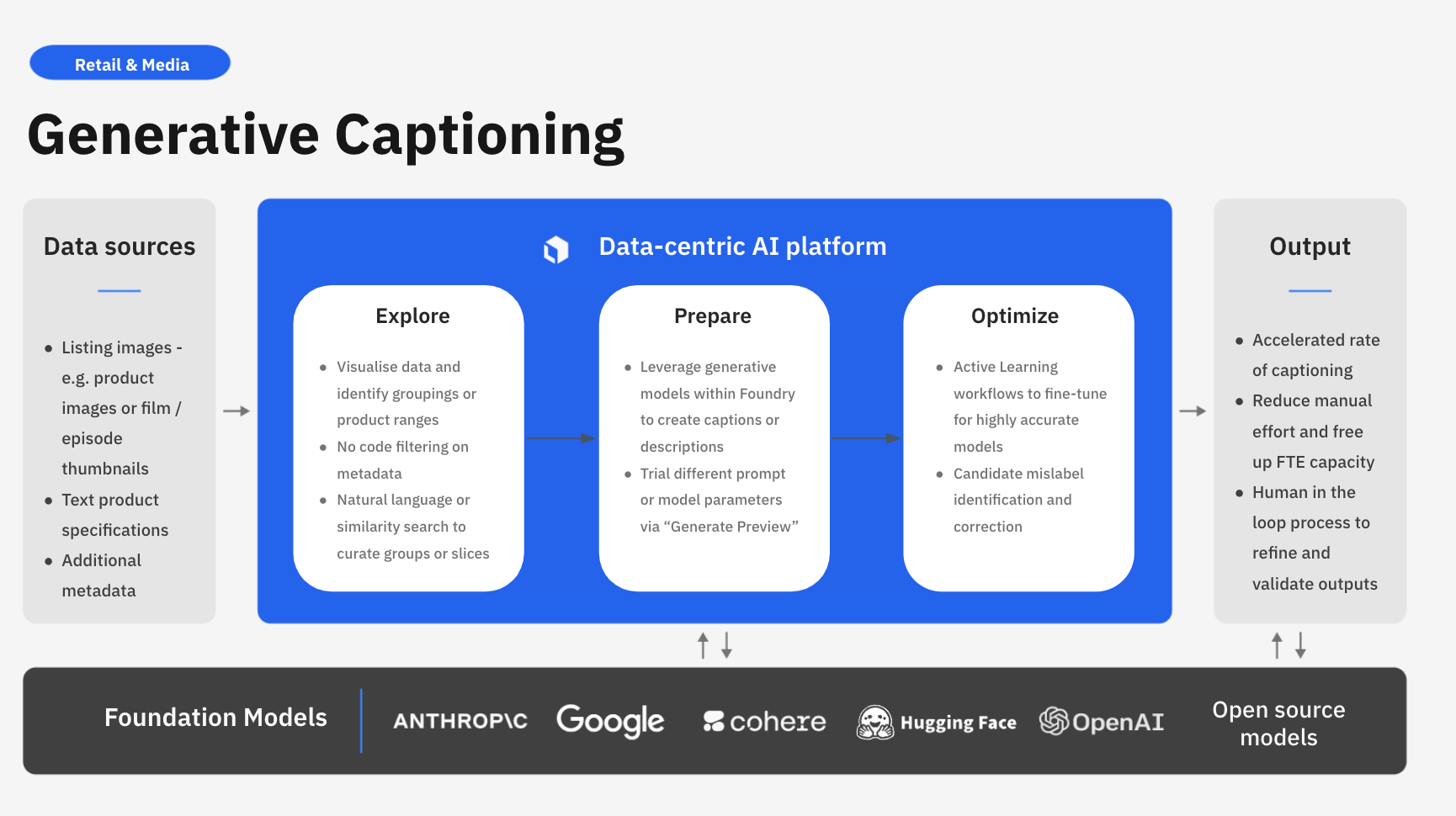
In this guide, we’ll walk through how you can leverage Labelbox’s platform to build a powerful generative captioning system, ensuring your customers get deeper personalization from LLMs and for your internal teams to derive insights faster from your website product listings.
See it in action: How to build a powerful generative captioning system in Labelbox
The walkthrough below covers Labelbox’s platform across Catalog, Annotate, and Model. We recommend that you create a Labelbox account to best follow along with this tutorial.
Part 1: Explore and prepare your data
Painlessly consolidate all your product listing data
Building a generative captioning system requires consolidating data of different types from various sources. Such data can include product, business, and customer information that might be siloed or stored in different databases. To holistically browse and visualize your entire product catalog, leverage Labelbox Catalog to bring and view all of your data in a single place.
Accelerate product discovery across your entire catalog
An effective captioning system for product listings relies on training a model with a thorough understanding of your product data, encompassing product tags, categories, and more. However, organizations often have an ever-growing product catalog with hundreds or thousands of products. Dealing with this volume of data at scale and effectively searching, organizing, and managing data for machine learning tasks can be a challenge.
You can leverage Labelbox Catalog to visualize, browse, and curate your product listings.
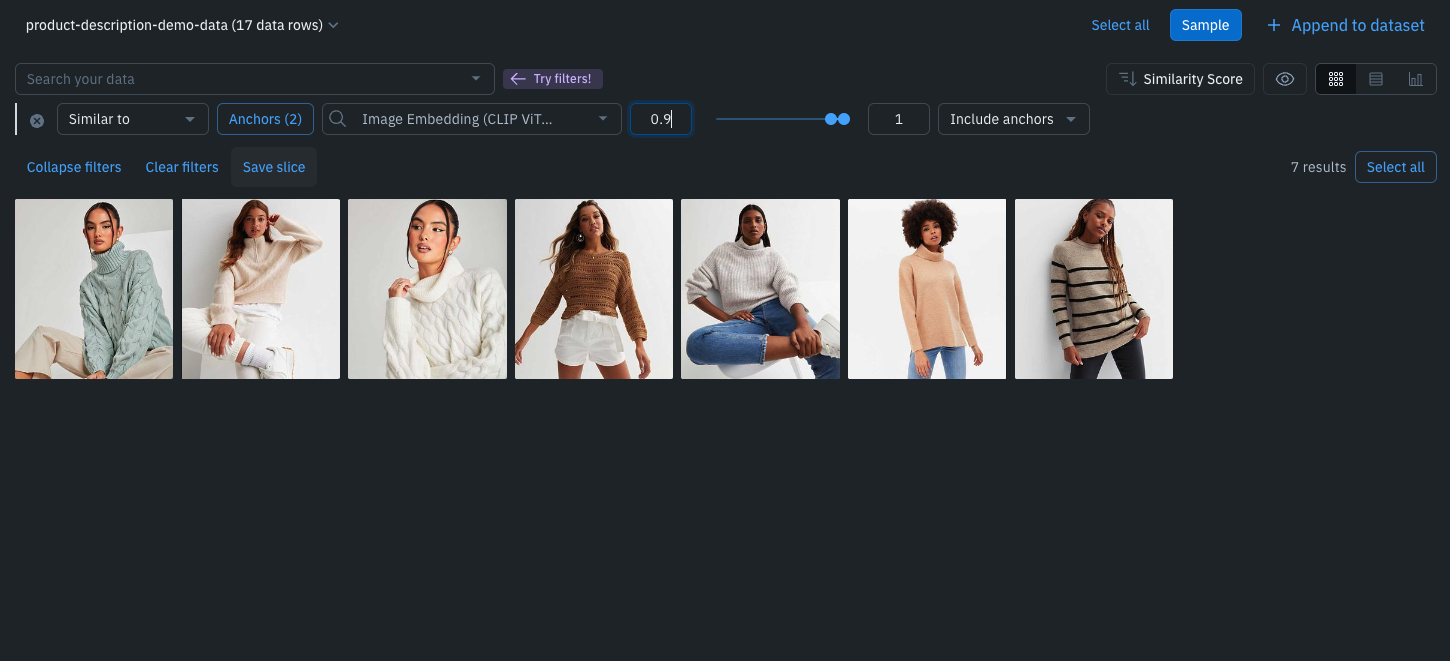
Search and curate data
With Catalog, you will be able to see the sample your product listings dataset and query specific items such as shoes, tops, trousers, and more. Try searching across key product-specific metadata such as category, the year the item was released, season, type, and more. With Catalog, you can contextualize your data with custom metadata and attachments to each asset for greater context.
Leverage custom and out-of-the-box smart filters and embeddings to quickly explore product listings, surface similar data, and optimize data curation for ML. You can:
- Search across datasets to narrow in on data containing specific attributes (e.g metadata, media attributes, datasets, project, etc.)
- Automatically find similar data in seconds with off-the-shelf embeddings
- Filter data based on natural language and flexibly layer structured and unstructured filters for more granular data curation
Categorize and curate product listings faster
Once we have appropriately explored and curated our data, we're now in a position to begin generating product descriptions for the images that we have available to us. In some cases, it may be beneficial to create a product description for all images at once. However, in a real-world setting, it may be the case that specific teams are responsible for creating product listings for various departments such as shoe wear tops or dresses.
To replicate this scenario, we can navigate to the slices that we created earlier. For example, one team may be responsible for generating product descriptions for the tops department. In this instance, you can select a subset of the data or you can select all data rows available within the slice. Having done so, you can then predict with Model Foundry which allows API connectivity to state-of-the-art foundational models as well as the option to integrate custom models that you may have trained within your own organization.
Part 2: Streamline captioning product listings and labeling automation with Foundry
In this example, we're interested in generating a text description for the images provided and will therefore be working with a multi-modal model (i.e., OpenAI's GPT-4 Vision).
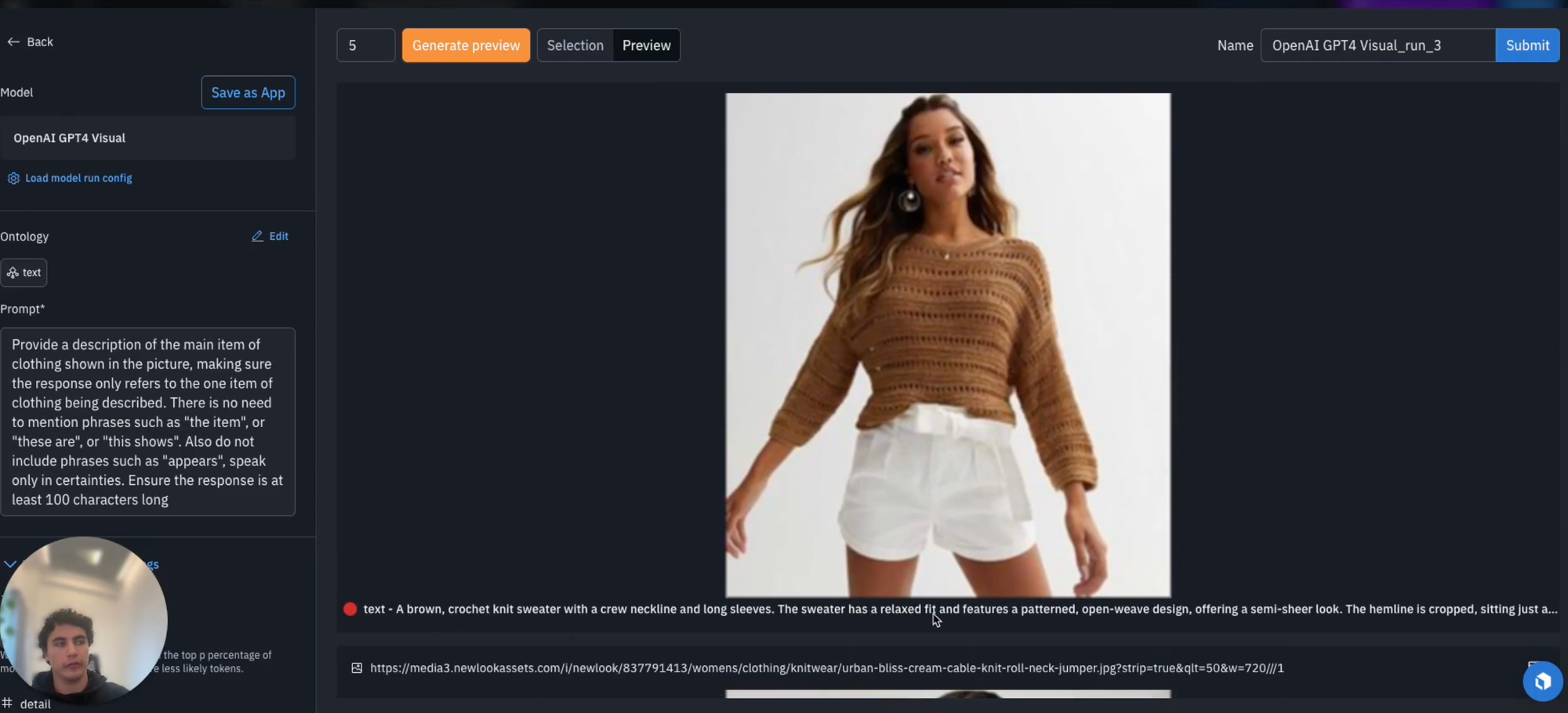
As a next step, you'll have the option to consider model run parameters and provide a prompt. The prompt helps you describe to the model what it is you want it to execute during inference.
You can generate a prompt in a conversational manner specifying various characteristics such as the type of tone that you want your generated response to have, the aspects of the picture that you're interested in or the desired length of the response.
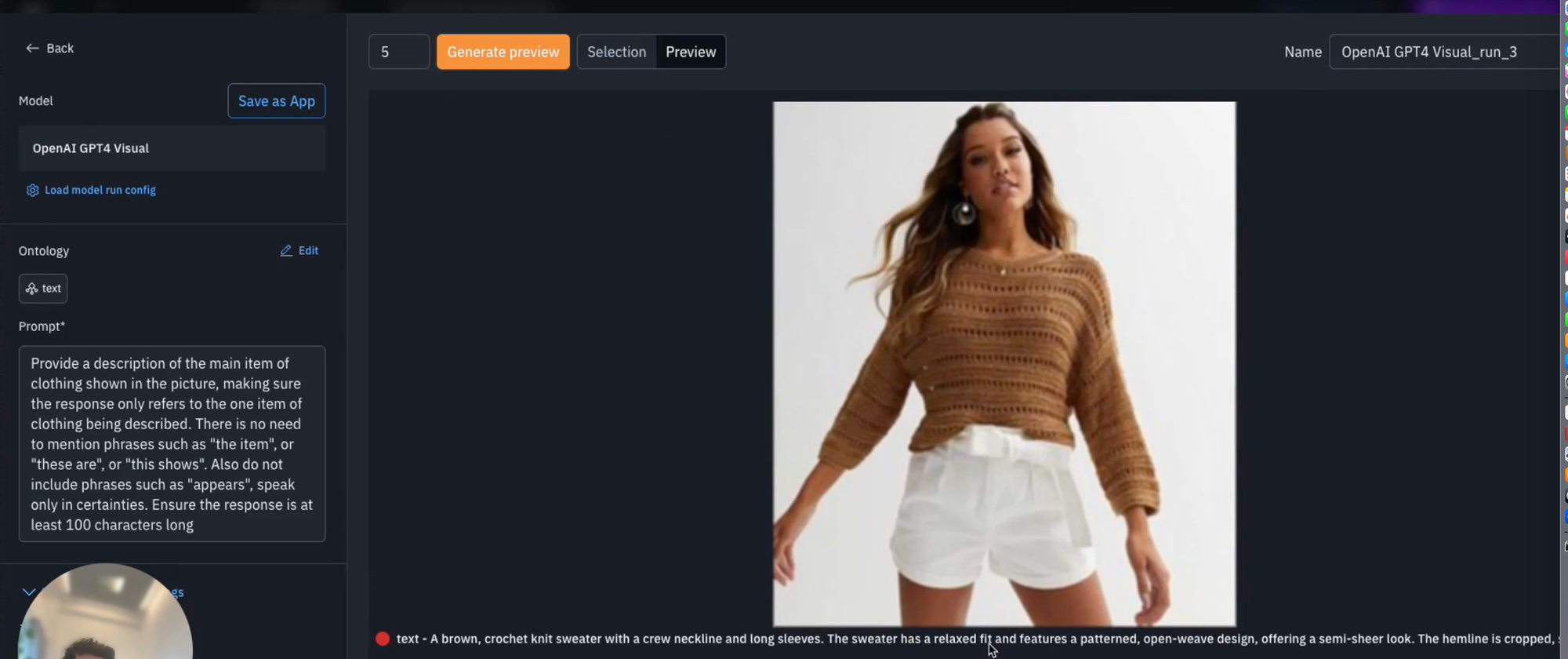
Here, we asked the model to create a description for the main item of clothing shown in the picture and asked it to exclude words such as "the item", "these are" or "this shows", and also to speak in certainties by ignoring such phrases as "it appears". We also ask for a specific prompt response length.
Having done so, we can configure any of the additional parameters as required, and then we have the option to generate preview. Generating preview allows you to run inference on just a sample of the data. In this case, the maximum is five however, if of interest, we can decrease this as required.
After completing your first model run, we can navigate back to your model to explore the outputs. We now have the option to explore each data row and observe the outputted description that GPT4-Vision has generated. Here we can see a remarkable level of detail and accuracy based on the image provided.
At this point, the descriptions may be appropriate to pass straight to our website for the product listing. However, in some instances, we may wish to have a human in the loop to either tweak or validate the product descriptions that our model outputs.
Send a subset of data to the labeling project for human-in-the-loop validation
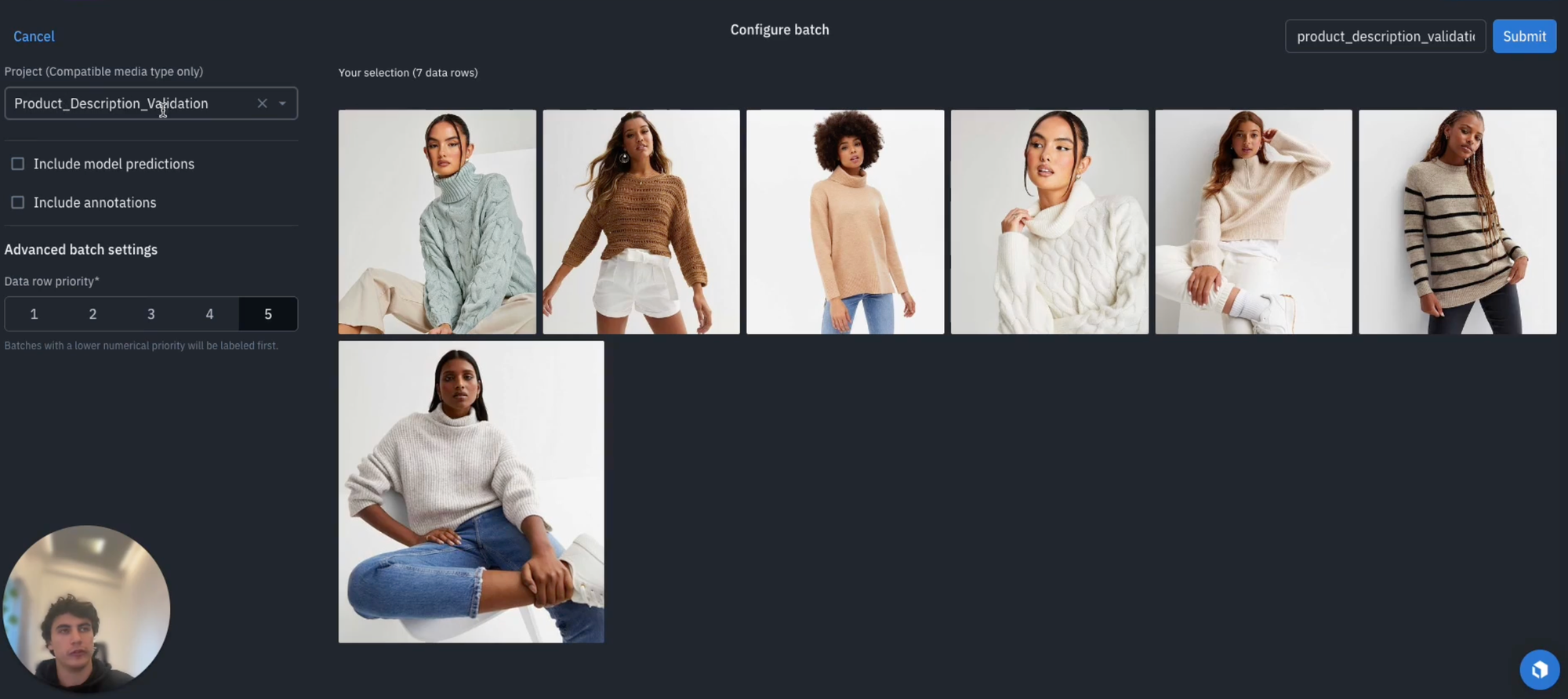
1) When it comes to setting up an Annotate project that enables human in the loop validation for our model outputs, the first thing to do is to set up our ontology. When doing so, it may also be of interest to have a binary classification, such as whether or not we needed to tweak the overall description, such as validation and we can have an option edited or accepted.
2) Once we've established this ontology, you can create it, and we're now in a position to set up our annotate project. You can navigate to Annotate, create a new project and name it something appropriate such as "product description validation".
3) Next, attach the ontology that we've just created and we're now in a position where our project has set up and the last thing we need to do is to add our data. For this, let's navigate back to the model and select the appropriate model run as before and select all our data rows.
4) We now want to "Send to Annotate" and we can include our model predictions. An option will appear on whether we want to to map the text output that the model is created to our description free text classification. Select "Map", and select description, and we can then select text, and then "Save" to ensure that we have correctly mapped the text output from the model to the description option within our ontology.
5) Next, let's set our batch settings. In this case we can set it to "1" given this is the highest priority within our project, and dictate what step of the workflow we want to put it in. In our case, we'll select "Initial labeling task". Having done so, we can navigate back to our Annotate project where we'll see that the data rules have been successfully added and we're now in a position for the our subject matter experts to validate all of the outputs coming from the model, and to start our labeling process (as shown below).
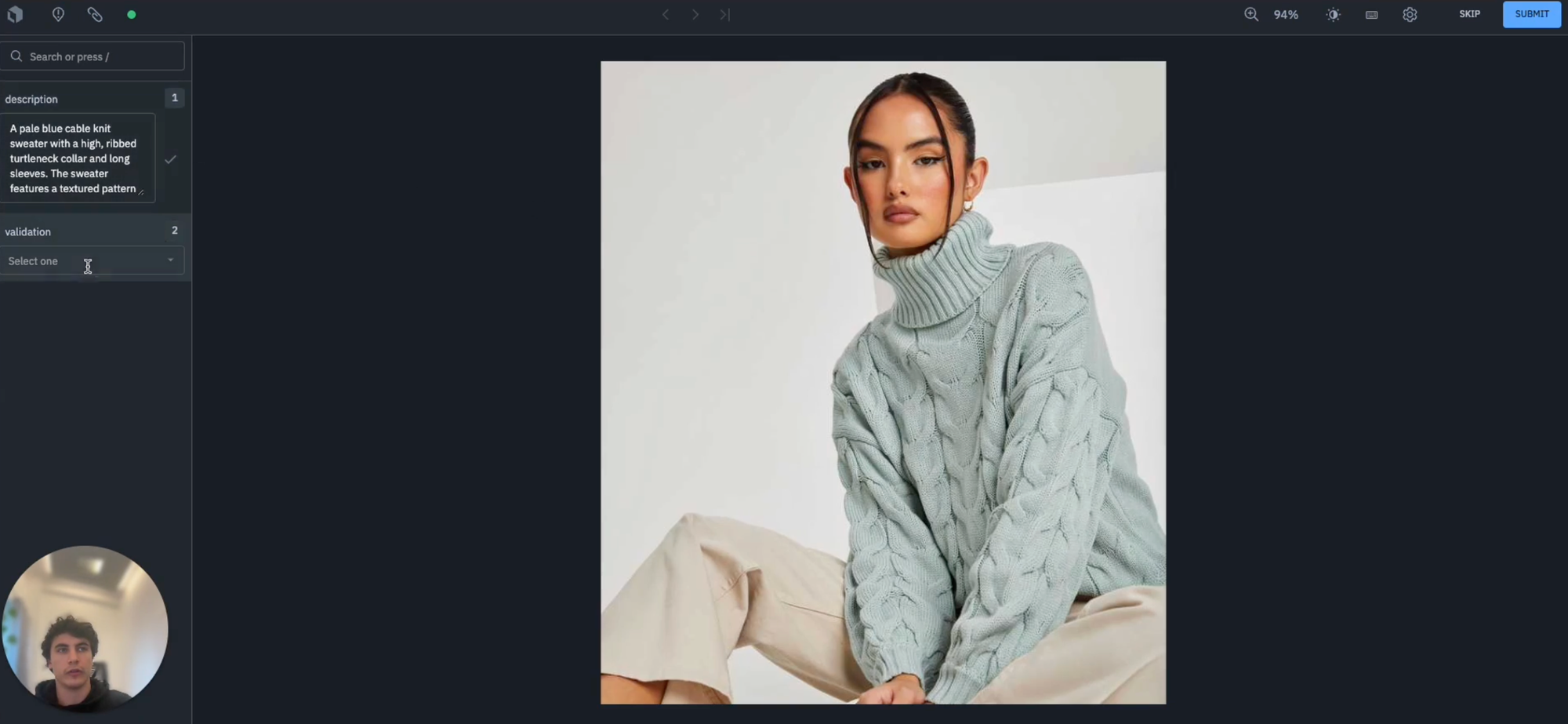
We can see above that the description provided, "a pale blue cable knit sweater with a high, ribbed turtleneck collar and long sleeves" appears to be appropriate so we may not need to edit it and can simply hit "Accept".
In an instance such as this one above, we may wish to edit the description slightly. In this case, the sleeves are "long", but not "full length", so let's describe them as "quarter length" sleeves and keep everything else as consistent with what the model outputted, but mark it as "edited".
We can continue with this workflow until all of our data rows have been processed with a human-in-the-loop review. The advantage of this approach is that it allows you to validate whether or not the model is performing is expected, offering a certain level of security by having domain experts assess each of the product descriptions before they go live on your website or app.
Part 3: Using text inputs to generate and compare detailed product descriptions with Foundry
In the walkthrough above, we looked at how we could create product listing descriptions based on an image input. Next, let's look at how we can generate detailed product descriptions based on text input containing rough product specifications, such as those found on online marketplaces.
1) The first step is to set up your ontology again by navigating to the schema tab, creating a new scheme and selecting the "text" media type as we're dealing with text inputs this time. We recommend naming it something descriptive such as "multi description", and then add the overall text classifications for our descriptions, with free text responses. In this example, we'll be generating 3 product descriptions. We will then need some indicator to say which of the preferred descriptions has been identified as the best by the human labeler (e.g., description 1, description 2, description 3, preferred description) as shown below .
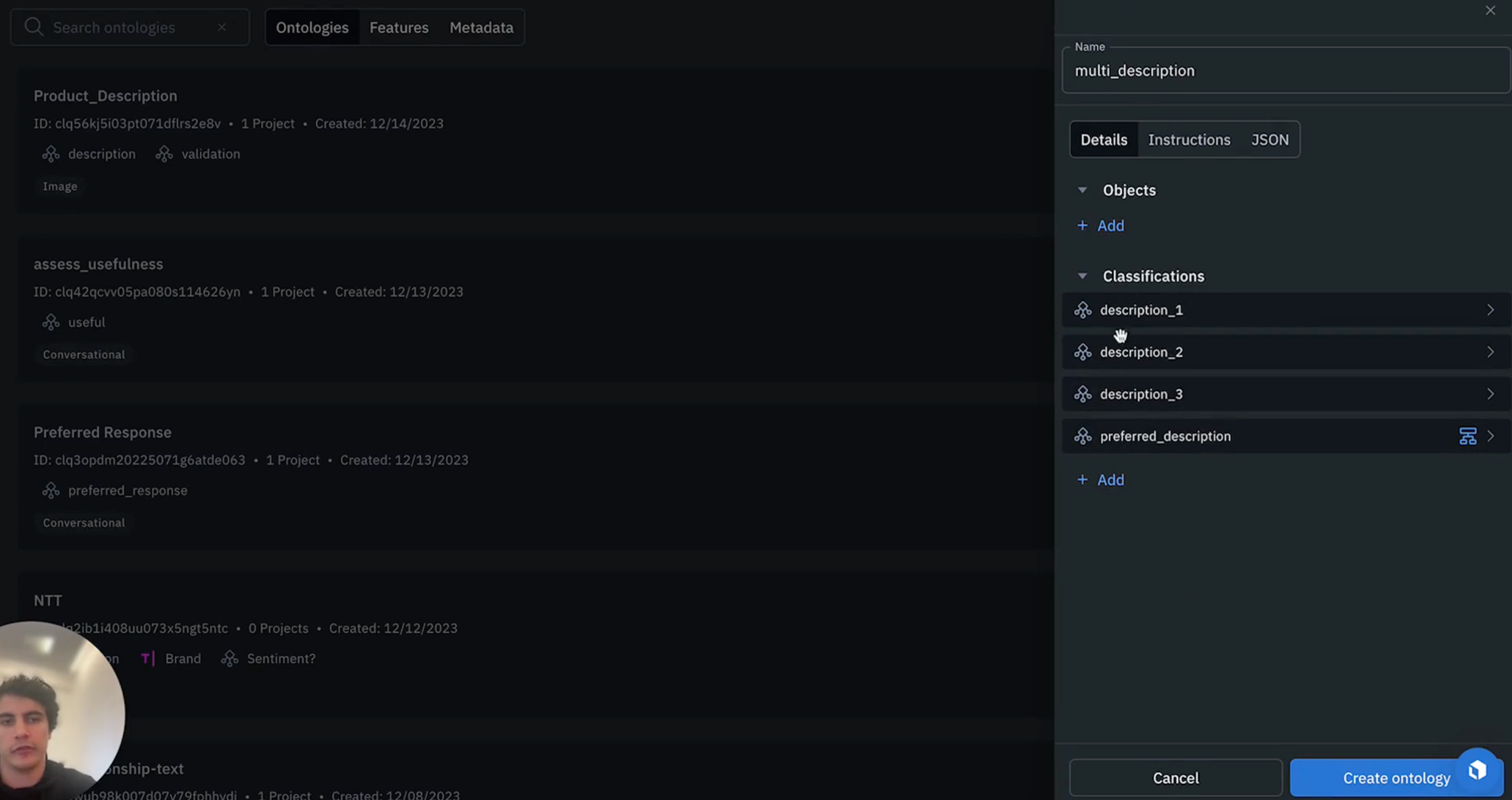
2) We're now in a position to execute our Model Foundry run, which we can do by selecting all the data rows within this data set and by predicting with Foundry. Since we're interested in generating an output text based on the input provided, let's use OpenAI's GPT-4 again in this instance.
3) As a next step, let's select an ontology. We're going to want to edit this ontology because we're not interested in asking the model to provide the preferred description but simply to output each of the three descriptions. To do so, we can click "edit", then we can ignore the preferred description option. Clicking "save" will update the automatically generated prompt before and we can add some additional information via prompt to direct the model in our desired manner.
4) As shown above, we'll be asking the model to provide three different output descriptions based on the input specifications provided. We can then edit any of the parameters available to us as required and once we're ready, we can generate the preview as shown below.
5) After we've generated our preview, we can begin to explore each of the outputted results for the sample of five data rows. To see the full response, we can navigate to to "view log" and see the outputted response from our model which has provided three different descriptions. As it appears the model is performing as expected and we can now execute the full model run (as shown below).
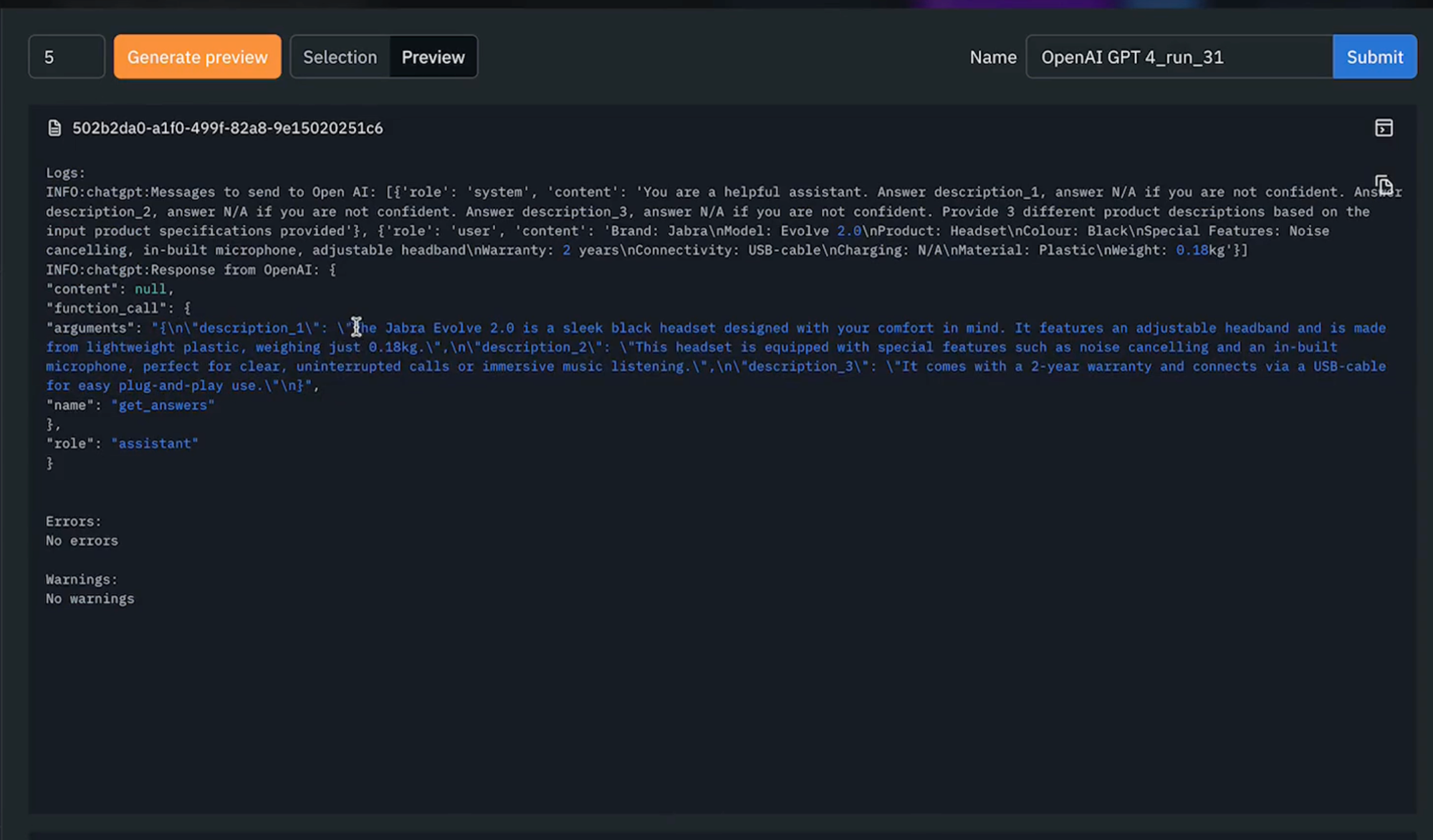
6) Once our model run has been complete, we're in a position to navigate to the Model Run of interest. We can explore the three different descriptions that the model has generated for each of our data rows. Let's pass these to an Annotate project for a human labeler to select which of the three descriptions are preferable. To do so, we'll set up an Annotate project again, making sure to select "text", add our ontology that we used earlier, and then pass our model run outputs, and then "Send to Annotate".
7) Finally, we can view the 3 descriptions that the model has outputted. We can now have a human labeler review each of these descriptions, and select which one of the descriptions is most appropriate to include in the website listing as shown below.
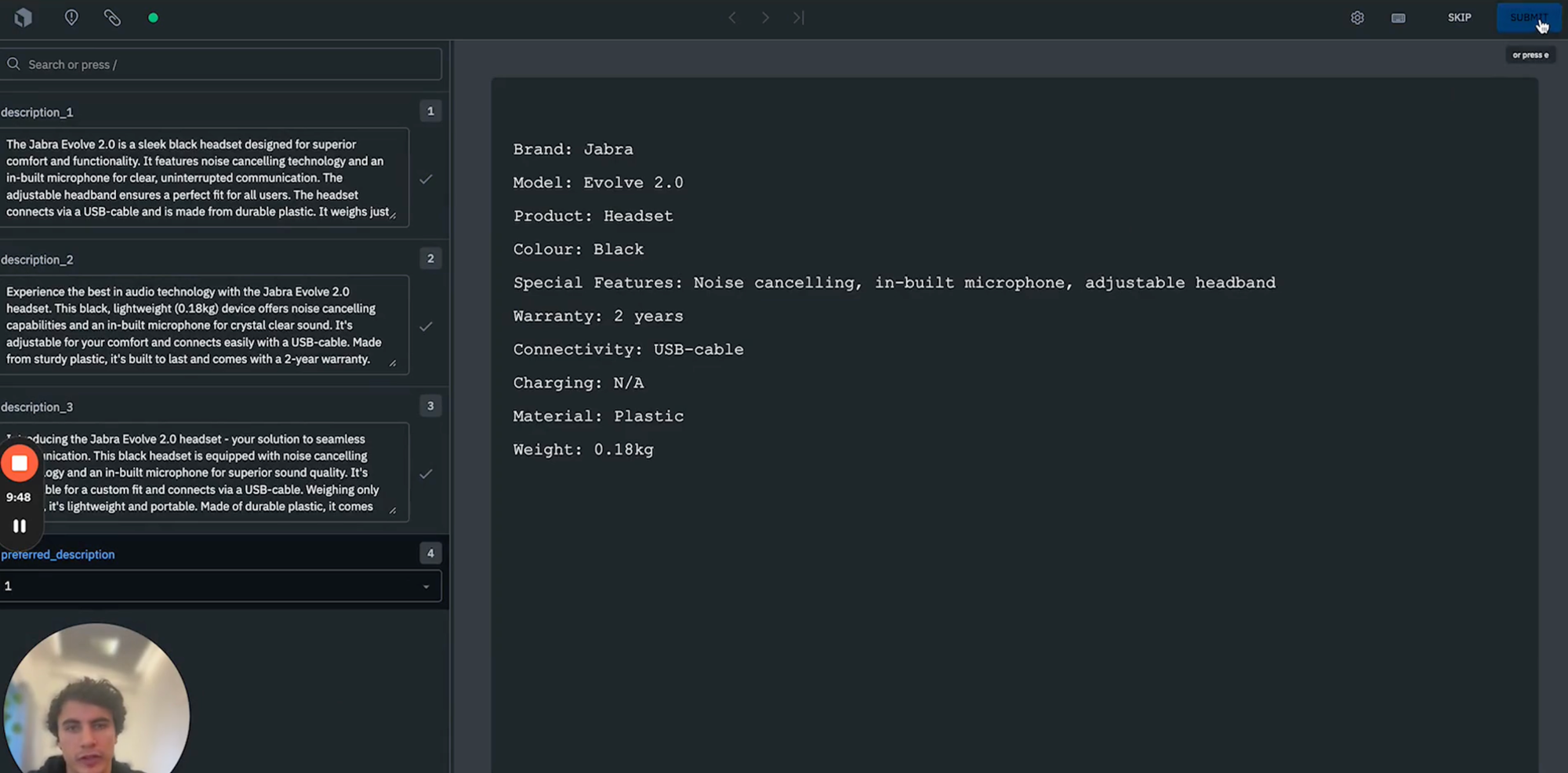
We can continue with this workflow until labelers have reviewed and assessed all data row descriptions. This allows us to build a dataset ready to extract and identify preferred descriptions and pass these description downstream for whatever use case is required such as inclusion on the product listing of our website.
We hope that this walkthrough gives you an idea of how you can leverage Labelbox's Foundry capabilities to create automatically generated product descriptions for a wide range of use cases. This should dramatically reduce the time taken and costs associated with generating outputted text (from product descriptions, to alt-text, to articles), while leveraging foundation models to automate the first pass.
As consumer businesses in media, retail, and internet strive to distinguish themselves in a competitive market, the power of AI-driven captioning systems for automating product listings serves as a powerful lever for speeding up manual tagging processes. Companies can tap into their vast data stores and harness the capabilities of advanced algorithms to enrich the customer experience.
Labelbox is a data-centric AI platform that empowers teams to more quickly build intelligent applications. To get started, sign up for a free Labelbox account or request a demo.