
 All guides
All guidesHow to create and label text layers from PDF documents for AI
PDF documents are one of the toughest data types to handle when it comes to building AI models. While most other data types usually contain information in one format, PDFs can comprise multiple types of data within them, such as photos, graphs and charts, text formatted in paragraphs, outlines, lists, links, and more. To add to the complexity, PDF documents can be hundreds of pages long, so a single data point can amount to hundreds of hours of work to label for training a model.
That's why many AI teams working with this data type use PDF layers to separate and organize different information formats within a document, making them easier to view, edit, and enrich with labels. As most PDF documents contain primarily text, creating a text layer is often essential to the process of building AI on PDF data.
In this post, we’ll take a look at the different types of PDF layers and discuss various methods for creating PDF text layers, such as using PDF creation software, OCR software, or Python scripts with libraries like reportlab or PyPDF2. Additionally, we will highlight the usefulness of PDF text layers in applications such as Labelbox, where they can be imported for annotation and used to build robust AI models with contextual information from PDF documents.
What are PDF layers?
A PDF layer comprises a specific type of data contained within a PDF document. Separating a document into layers enables AI builders to process the different types of information within it.
Types of layers include:
- Text layer: Refers to the selectable and searchable text contained within a PDF document. The text layer is an essential component of the PDF format, as it enables users to interact with the document's content by copying, searching, and editing text.
- Image and graphics layers: Contain images, illustrations, and graphical elements.
- Background layer: Contains the background color or images, usually placed behind the main content.
- Annotations and comments layer: Contains any added annotations, comments, or interactive elements like form fields.
- Watermarks or overlays: Contains watermarks, stamps, or other overlay elements that appear over the main content.
How to create a PDF text layer
PDF text layers can be created in several ways, depending on the source of the document and the tools available. Here are a few methods for creating a PDF text layer:
- Using PDF creation software. There are dedicated PDF creation tools, such as Adobe Acrobat, that allow you to create a PDF document from various file formats, including images, Word files, and other document types. These tools often have built-in OCR (Optical Character Recognition) capabilities that can detect and create text layers from scanned or image-based documents.
- OCR software. If you have a scanned or image-based document without a text layer, you can use OCR software to recognize the text and create a new PDF with a text layer. There are many OCR tools available, such as Adobe Acrobat, AWS Textract, and Tesseract.
- Python script. You can separate a document into layers using libraries like reportlab or PyPDF2.
Why is a PDF text layer useful?
PDF text layers enable AI teams to annotate text data on its own, and then later add context to that information by combining it with the other data types within the document. Labelbox enables you to import your PDF and text layer so that you can annotate on the text layer and then export the labeled text with photos, graphics, and other information from the document to build robust AI models.
How to convert your PDF into Labelbox PDF text layer format
You can convert your PDF into the Labelbox PDF text layer format using the CLI shown here.
First, you will need to have AWS CLI installed globally and configured for your AWS user with permissions to S3 and Textract. The CLI will upload your PDF to S3 and save the Labelbox formatted PDF text layer JSON file in the specified folder.
There is a configuration file named config.json at the root level of the directory that must be updated before first running the CLI.
{
// The name of the bucket in your cloud provider that pdfs will be uploaded to
"bucketName": "<name_of_s3_bucket>"
}
convert - Run OCR on all pdfs contained in the input folder and convert the result into Labelbox's text layer JSON.
convert --inputFolder <input_folder_containing_pdfs> --format <aws-textract> --outputFolder <output_folder> --concurrency 10
--inputFolder The input folder containing the pdfs
--format The OCR format to use (aws-textract, google-cloud-vision)
--outputFolder The output folder to place the generated text layer json files
--concurrency How many pdfs to process at the same time. CAUTION: Setting this value too high can result in rate limits being reached.
Example (Mac)
./textlayer-macos convert --inputFolder input --format aws-textract --outputFolder output --concurrency 10
validate - Validates the provided text layer json
validate --textLayerFilepath <text_layer_filepath>
Once you have the PDF text layer in the Labelbox format, you can upload it and the PDF file to Labelbox as shown here.
You can also convert GCP OCR JSON or Adobe OCR JSON formats into Labelbox's format as shown here.
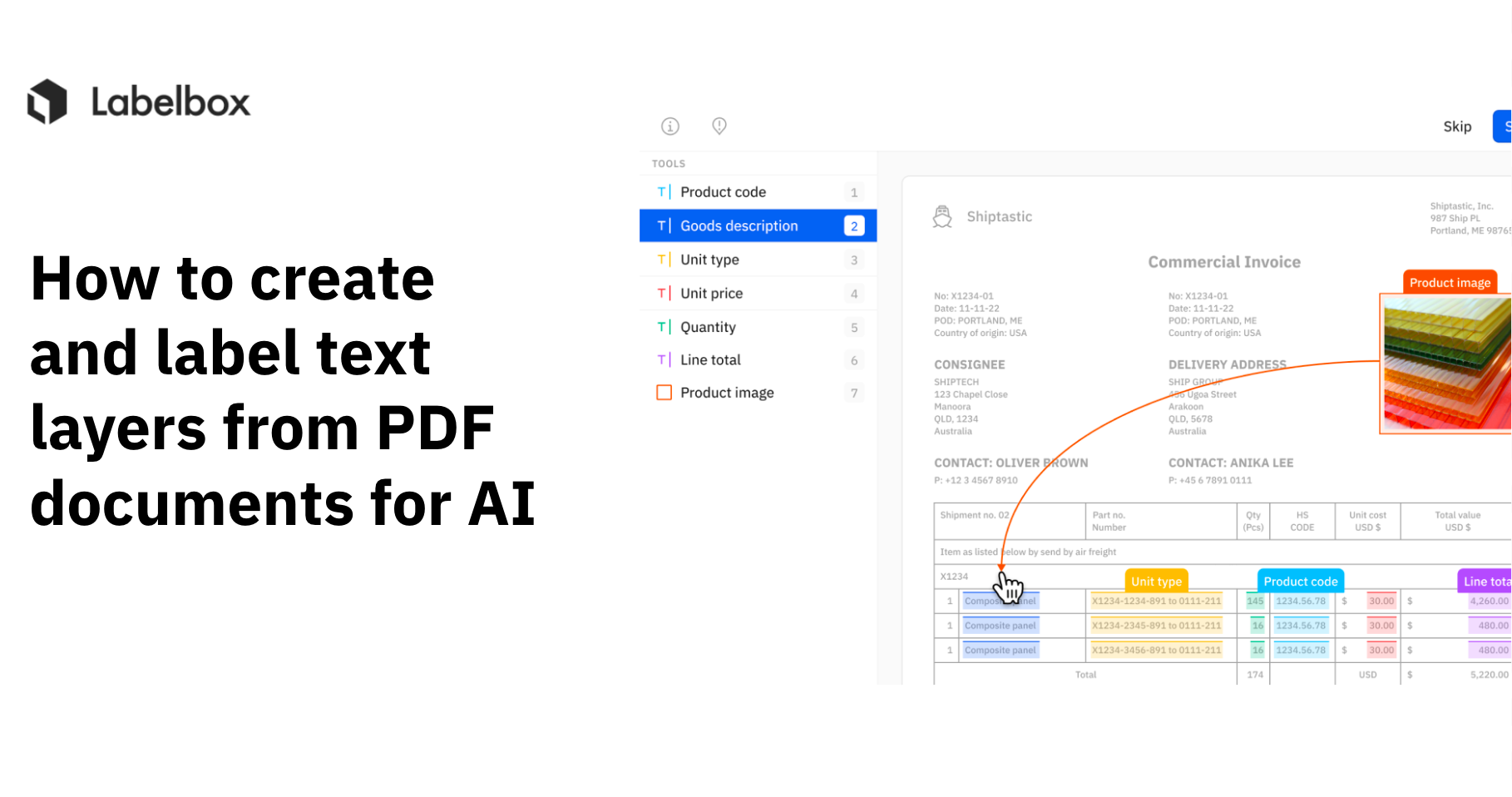
View and label PDF text layers
See how you can visualize and annotate PDF text layers for your AI projects using Labelbox by selecting "Show text layer" (illustrated below).
Show text layers within Labelbox

We hope what we covered in this post helps inspire you to better work with the different ways to create PDF text layers, from using software to OCR or Python scripts. These text layers can come in handy when building AI models with PDF context. Feel free to give it a try for yourself and we'd love to hear your feedback and what else you'd like to see when it comes to creating and labeling text layers for your ML use cases.
Learn more about:


