
 All guides
All guidesHow to generate data for model comparison and RLHF
Large language models (LLMs) have disrupted the way teams build and train intelligent applications. Trained on massive text datasets containing millions or even billions of data points, LLMs have become increasingly important for various AI applications such as chatbots, personalized recommendation systems, and more. These models have shattered the barriers of what was once thought possible in natural language understanding and generation.
While large language models have enormous potential to revolutionize intelligent applications, effectively deploying them requires adapting LLMs to align with human preferences to mitigate risks. Successfully adopting LLMs involves continually fine-tuning and evaluating the model’s performance. This requires assessing subjective qualities like tone, fluency, and propriety through a combination of automated techniques and human-in-the-loop validation.
The importance of human preference datasets and RLHF
As LLMs rapidly advance in capability, properly directing them for the benefit of humanity should be a top priority. Human preference datasets and reinforcement learning from human feedback (RLHF) provide critical approaches for promoting the safe and ethical alignment of these influential AI systems.
A human preference dataset comprises numerous examples where humans indicate their preferences between model outputs, such as judging which content could be more harmful or which summary appears more accurate. By training models with this data, we can instill more ethical and beneficial behaviors aligned to human values.
Reinforcement learning from human feedback (RLHF) goes one step further by actively querying humans within a feedback loop to continuously improve models by correcting mistakes and reinforcing positive behaviors. You can learn more about the importance of RLHF in this blog post.
Where does Labelbox come in?
Labelbox is a data-centric AI platform that can help your team navigate the future of large language models with human-centric evaluation. To ensure trustworthy, reliable, and safe AI aligned with human values, Labelbox allows teams to generate high-quality data for alignment and confidently ship LLMs with human experts to validate model outcomes.
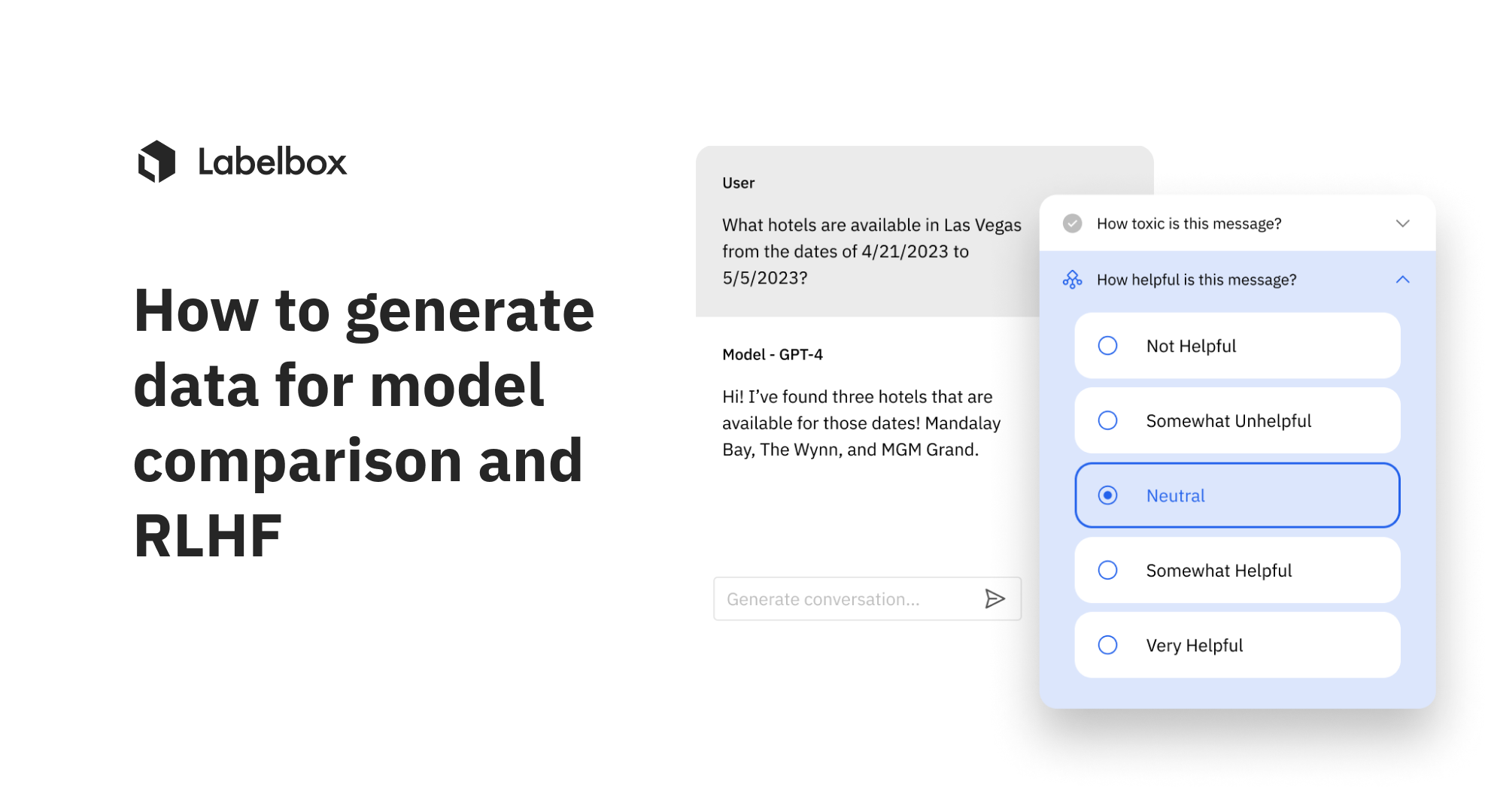
With the new LLM human preference editor, you can create human preference data for model comparison or RLHF (reinforcement learning with human feedback). You can compare model outputs side-by-side and select the most favorable model output on a conversational text thread by assigning the model output a classification. This editor solves two important problems that are critical to ensuring responsible AI aligned with human preferences:
- Model comparison: Conduct the evaluation and comparison of model configurations for a given use case and decide which one to pick.
- RLHF: Create preference data for training a reward model for RLHF based on multiple outputs from a single model.
The new LLM human preference editor and the previously released LLM data generation editor support:
- Markdown rendering and markdown editing capabilities
- The ability to import model predictions and ground truth through model-assisted labeling
With Labelbox, you can tap into both reinforcement learning from human feedback (RLHF) with your own internal team and skillful data labeling services with expertise in RLHF, evaluation, and red teaming. This human-centered approach is the key to developing reliable, responsible AI systems scaled for your business.
See it in action: How to generate data for model comparison and RLHF
We recommend that you create a free Labelbox account to best follow along with this tutorial.
For this tutorial, we will utilize conversational text data in Labelbox to train an AI assistant for a shopping app. This assistant will be designed to aid customers at various stages, including:
- Product discovery: Help browse items and make recommendations based on the customer's needs and interests
- Pre-purchase guidance: Answer questions and provide details to assist in the buying decision process
- Post-purchase support: Provide helpful information about orders, shipping, returns, or other purchase-related needs
Step 1: Data upload and setup
The data that we will be using for this tutorial are three conversational text datasets based on the above scenarios:
Conversation #1: The customer has a budget in mind and is searching for an affordable vacuum cleaner option that meets their needs.
Conversation #2: A customer's existing vacuum cleaner is having technical issues, so they require assistance troubleshooting the problems or finding a suitable replacement.
Conversation #3: A customer wants gift recommendations for a family member and asks the shopping assistant bot what it would suggest based on the situation.
The first step is to upload these conversations into Labelbox. To follow along with this tutorial, we’ve provided the 3 sample conversational text datasets in this Google Cloud folder available for download.
When inspecting the conversation JSON in VS code, you’ll notice it has 2 parts:
- The conversation itself
- Model outputs - containing:
- Title of the content (e.g “Response A”)
- The actual content (e.g "I have 2 options for you…”)
- Model configuration (e.g “modelConfigName": "GPT-3.5 with temperature 0") - this allows you to save the metadata around the models that are saved
In this JSON, the content is formatted in markdown since it is an important part of the experience when comparing detailed, nuanced conversations.
{
"title": "Response A",
"content": "I have 2 options for you:\n- The Dyson V15 [Product page](https://www.dyson.com/vacuum-cleaners/cordless/v15)\n- The Shark Stratos [Product page](https://www.sharkclean.com/products/shark-stratos-cordless-vacuum-with-free-steam-mop-zidIZ862HB)",
"modelConfigName": "GPT-3.5 with temperature 0"
}Since these data rows are stored in a cloud bucket, we can import them as a pairwise comparison dataset to Labelbox. You can learn more about how to upload a JSON to Labelbox through the UI or through a cloud storage integration.
Step 2: Explore and curate data in Catalog
Once you’ve successfully uploaded the conversations to Labelbox, you’ll be able to view them in Catalog. Since we’ve imported them as a pairwise comparison dataset, you can click into each conversation and view the conversation and outputs. Filtering by metadata makes it easy to locate these datasets – for example, you can set up a slice to capture all incoming comparison data in a single place.
Not only can you click in to view the outputs, you can switch to "markdown mode" and see all of the information with necessary links and formatting in markdown.
Step 3: Create a labeling project with the LLM Human Preference editor
Now that we have our conversation data in Catalog, we can create an ontology and a labeling project with the LLM Human Preference editor.
Create an ontology
After we’ve explored our data, we now have a better understanding of what topics exist in our dataset and can create our ontology. Ontologies can be reused across different projects and they are required for data labeling, model training, and evaluation.
To create a new ontology:
1) Navigate to the "Schema" tab
2) Hit "Create new ontology"
3) Select the media type that you wish to work with — for this use case it would be "Conversational text"
4) Give your ontology a name
5) Add objects and classifications based on you use case
For this use case, we’ll create two classifications:
1) Choose the best response (Radio classification) with options as:
- Response A
- Response B
- Tie
We strongly recommend doing pairwise comparison, especially for more nuanced use cases where alignment using RLHF or robust evaluation can have a significant impact on the quality of the model.
2) Provide a reason for your choice (Free form text)
After this, you can save your ontology.
After creating an ontology, you can create a labeling project and begin labeling your data.
Create a labeling project
1) Navigate to the Annotate tab
2) Click "Create new project"
3) Select the "LLM human preference" under LLM alignment
4) Name your project
5) Select your quality mode between benchmark or consensus
6) Save your project
Attach your previously created ontology to your new project to complete project setup.
Step 4: Import model predictions
To accelerate the labeling process, oftentimes you might want to leverage pre-labels or model predictions to automate the labeling process. This allows your team of labelers or an external team of experts to focus their valuable time on human review rather than spending time starting to label from scratch.
For this use case, we can import model predictions through Labelbox’s model-assisted labeling (MAL) to do exactly just that. With model-assisted labeling, you can import computer-generated predictions (or simply annotations created outside of Labelbox) as pre-labels on an asset. The imported annotations will be pre-populated in the labeling editor and a human can correct or verify and submit the prediction as ground truth.
To demonstrate, we’ve uploaded a choice of Response B as a model-generated label on one of these data rows, which will show up in the editor as a default response. From there, in the editor, a human could verify whether Response B is in fact the best option and provide an explanation for it.
You can follow this Google Colab Notebook to upload MAL predictions.
Step 5: Label data
With our data, ontology, and labeling project setup, we can begin reviewing the pre-labels and create ground truth data. You can select "Start labeling" and see both the conversation and the model outputs for comparison. The model outputs can be viewed both in markdown formatting and as raw text.
Depending on the conversation, you can select the appropriate response and provide a reason for your choice. You can continue to do this for all conversations and compare outputs to decide the best output based on human preference.
You can learn more about the new LLM human preference editor in our documentation.
As large language models continue to rapidly advance, maintaining reliable and ethical systems aligned to human values is essential. Techniques like human preference learning and reinforcement learning from human feedback are mechanisms for this.
As we build increasingly capable AI systems, maintaining human oversight is key. With Labelbox, you can enable reinforcement learning from human feedback (RLHF) by leveraging your internal team or external labeling services with specialized expertise in areas like evaluation and red teaming. This human-centered approach provides the ability to create reliable, responsible AI aligned with human values and tailored to your business use cases at scale.


