
 All guides
All guidesUsing Meta's Segment Anything (SAM) model on video with Labelbox's model-assisted labeling

While Yolov8 is no longer supported on Labelbox, this blog remains relevant if you are working with other object detection models. Alternatives such as OWL-ViT, Rekognition, GroundingDINO, and GroundingDINO + SAM can still be found and used on Labelbox’s platform.
In this guide, we will demonstrate the application of foundation models, such as Meta’s Segment Anything and YOLOv8, to automatically detect, classify and draw masks on objects of interest in a video. This is a follow-up to earlier guide: Using Meta’s Segment Anything with YOLOv8 to Automatically Classify Masks. In this guide, we’ll automatically detect and segment objects in a video.
Videos have many frames and are tedious to label. Segmentation masks are even more time consuming to label as they vary ever so slightly frame-by-frame, requiring manual fine-tuning each time. With foundation models, you can automate and significantly speed up the labeling process to label more video data, in less time. This allows you to focus valuable time on review, simply correcting the AI models’ output.
In this guide, we will be walking through a simple semantic segmentation task: drawing masks around a person as they skateboard.
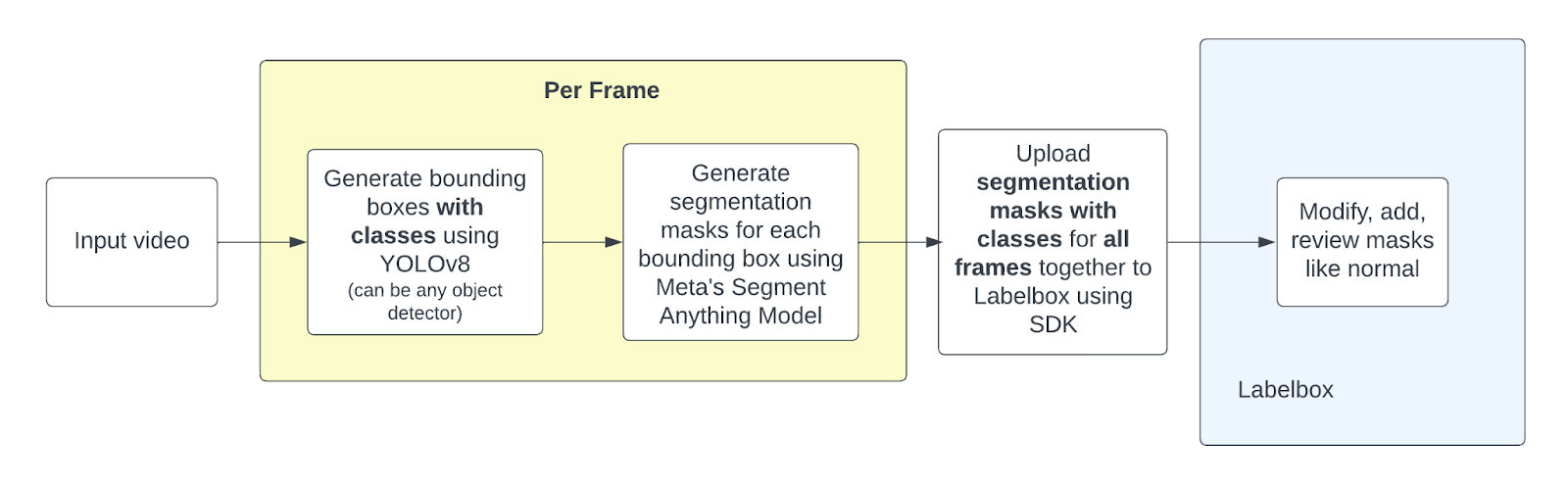
Here’s a high-level summary of the process that we will be walking through step-by-step below, with code:
1) Load YOLOv8, SAM and Labelbox Python SDK
2) For each frame of the video:
- Run an object detector to generate bounding boxes with classifications for specified classes
- Feed the bounding boxes as inputs to Meta’s Segment Anything model which will produce segmentation masks
- Prepare mask predictions in a format that Labelbox Python SDK expects
3) Upload all frames at once to Labelbox via prediction import
4) Open up video editor and review or modify the pre-labels as you usually do
You can run all of the above out-of-the-box on your video(s) using our Colab notebook. Simply load in your video and get automatically segmented masks, with classes in Labelbox, in minutes!
For this guide, we will use the following video:

Step 1: Load YOLOv8
YOLOv8 is a state-of-the-art object detector that produces bounding boxes and classes around common objects. It's the latest iteration of the YOLO (You Only Look Once) family of models, and it boasts some impressive features. YOLOv8 is known for its speed and accuracy, making it an invaluable tool for a wide range of applications. Here, we use YOLOv8 to automatically detect and localize the person skateboarding in the video.
import ultralytics
ultralytics.checks()
from ultralytics import YOLO
model = YOLO(f'{HOME}/yolov8n.pt')
# each class id is assigned a different color
colors = np.random.randint(0, 256, size=(len(model.names), 3))
print(model.names)
# Specify which classes you care about. The rest of classes will be filtered out.
chosen_class_ids = [0] # 0 refers to person, as per model.namesStep 2: Load SAM
Meta's SAM model is a state-of-the-art computer vision model that is designed to accurately segment images and videos into distinct objects. Using advanced deep learning techniques, Segment Anything is able to identify and segment objects in images, making it a powerful tool for a wide range of applications. The SAM model is able to generate segmentation masks based on prompts, including bounding box prompts, which we will use in the code below.
For an in-editor experience of SAM, please read our other blog post Auto-Segment 2.0 powered by Meta’s Segment Anything Model.
import torch
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
sam = sam_model_registry["vit_h"](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)
mask_predictor = SamPredictor(sam)Step 3: Load Labelbox's Python SDK
Labelbox’s Python SDK gives you easy methods to create ontologies, projects and datasets, and upload masks to a video.
import labelbox as lb
import labelbox.types as lb_types
# Create a Labelbox API key for your account by following the instructions here:
# https://docs.labelbox.com/reference/create-api-key
# Then, fill it in here
API_KEY = ""
client = lb.Client(API_KEY)Step 4: Run YOLOv8 and SAM per-frame
Here we run the models on each frame and generate masks automatically.
cap = cv2.VideoCapture(VIDEO_PATH)
# This will contain the resulting mask predictions for upload to Labelbox
mask_frames = []
frame_num = 1
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Run frame through YOLOv8 to get detections
detections = model.predict(frame, conf=0.7)
# Run frame and detections through SAM to get masks
transformed_boxes = mask_predictor.transform.apply_boxes_torch(detections[0].boxes.xyxy, list(get_video_dimensions(cap)))
mask_predictor.set_image(frame)
masks, scores, logits = mask_predictor.predict_torch(
boxes = transformed_boxes,
multimask_output=False,
point_coords=None,
point_labels=None
)
# Combine mask predictions into a single mask, each with a different color
class_ids = detections[0].boxes.cpu().cls
merged_with_colors = add_color_to_mask(masks[0][0], colors[int(class_ids[0])]).astype(np.uint8)
for i in range(1, len(masks)):
curr_mask_with_colors = add_color_to_mask(masks[i][0], colors[int(class_ids[i])])
merged_with_colors = np.bitwise_or(merged_with_colors, curr_mask_with_colors)
# Upload multi-colored combined mask to temp location
# to get temp instance uri
instance_uri = get_instance_uri(client, global_key, merged_colored_mask)
# Create MaskFrame object to be uploaded to Labelbox
mask_frame = lb_types.MaskFrame(index=frame_num, instance_uri=instance_uri)
mask_frames.append(mask_frame)
frame_num += 1
cap.release()


Step 5: Upload the predicted masks as pre-labels onto Labelbox
The predicted masks can be easily and seamlessly integrated into Labelbox via our SDK.
# Create MaskInstance per unique class predicted / chosen
instances = []
for cid in chosen_class_ids:
color = get_color(colors[int(cid)])
name = model.names[int(cid)]
instances.append(lb_types.MaskInstance(color_rgb=color, name=name))
# Create list of VideoMaskAnnotation objects, one for each unique class
annotations = []
for instance in instances:
video_mask_annotation = lb_types.VideoMaskAnnotation(
frames=mask_frames,
instances=[instance]
)
annotations.append(video_mask_annotation)
# Create Label object
labels = [
lb_types.Label(data=lb_types.VideoData(global_key=global_key),
annotations=annotations))
]
# Run import job
upload_job = lb.MALPredictionImport.create_from_objects(
client=client,
project_id=project.uid,
name="mal_import_job" + str(uuid.uuid4()),
predictions=labels
)
upload_job.wait_until_done()
print(f"Errors: {upload_job.errors}", )
print(f"Status of uploads: {upload_job.statuses}")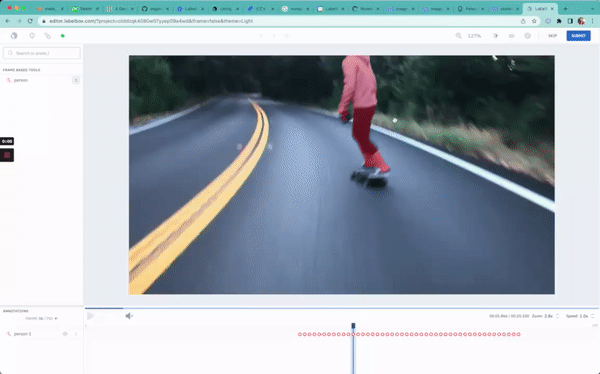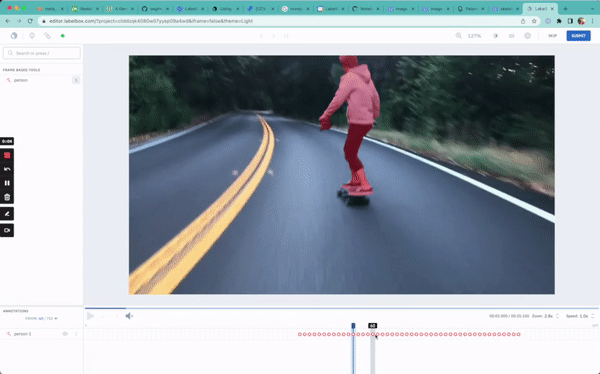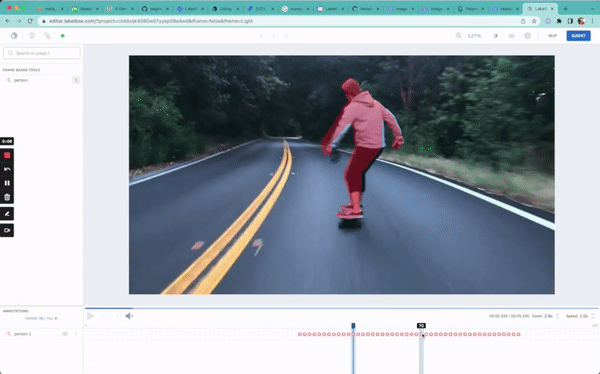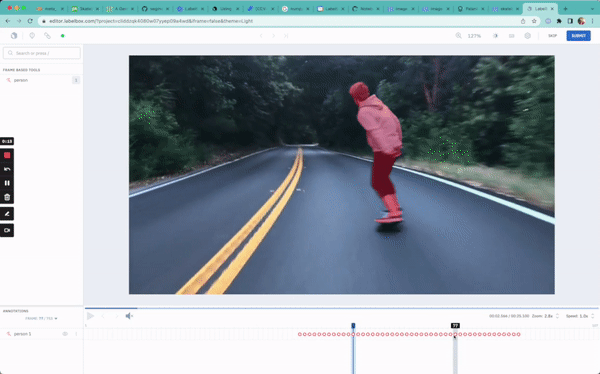
Creating segmentation masks on video data can be tedious and time-consuming. Using the power of foundation models in Labelbox, you can easily generate masks with classifications in a matter of minutes. Rather than spending hours labeling video data, you now have a way to accelerate video labeling and not only reduce time to market, but also the cost of developing your models.


