×![]()

 All blog posts
All blog postsLabelbox•December 23, 2022
Year in review: Labelbox 2022 product highlights

In the past year, Labelbox released features and products that helped AI teams better understand their unstructured data, label data more accurately and efficiently, and train their models more effectively. In this post, we’ll explore some of the most impactful recent updates to Labelbox Catalog, Labelbox Annotate, and Labelbox Model.
Find similar data rows among unstructured data in one click
Machine learning (ML) teams mine data by looking for all examples of rare assets or edge cases that will dramatically improve model performance. Powerful similarity search capabilities can give your team an edge by helping find specific data points in an ocean of data. Building a similarity search engine that scales to hundreds of millions of data points and generates instant results is difficult for even the most advanced ML teams. To help teams find data easier and faster than ever, we’ve made major updates to our similarity search capabilities.
With similarity search powered by vector embeddings, you can easily query and explore your unstructured data and develop a holistic understanding of your training data. Plus, it helps break down silos across datasets, so teams can focus on curating and labeling the data that will dramatically improve model performance. One-click similarity search can enable your team to better:
- Explore and understand your unstructured data
- Quickly mine for edge cases and rare examples
- Find and fix labeling mistakes
- Select high-impact data for labeling
- Find duplicates in your dataset
Finding unlabeled data similar to a specific data row is as easy as one click in Labelbox Catalog.
You can learn more about the one-click similarity search in our guide on how to find similar data in one click.
Natively upload and annotate PDF documents and text conversations
Documents such as PDFs are widespread across a variety of industries such as financial services, real-estate, healthcare, and many more. PDFs contain valuable information that often need to be extracted for greater understanding or a specific business use case.
However, not only are PDFs inherently complex – as they often contain text, images, graphs, and more – but the format of PDFs can vary. Interpreting and extracting information from native PDFs of various formats and structures is a key challenge in any AI use case based on PDF data. The Labelbox document editor is a multimodal annotation platform, allowing you to easily turn stores of PDF files and documents into performant ML models. You can annotate text with an NER text layer alongside traditional OCR to extract both text and images without losing context.
The rise in natural language processing (NLP) language models have given machine learning teams the opportunity to build custom tailored experiences for their business use cases. Use cases can range from improving customer support metrics, creating delightful customer experiences, or preserving brand identity and loyalty. Labelbox now enables the development of these AI solutions with the new conversational text editor.
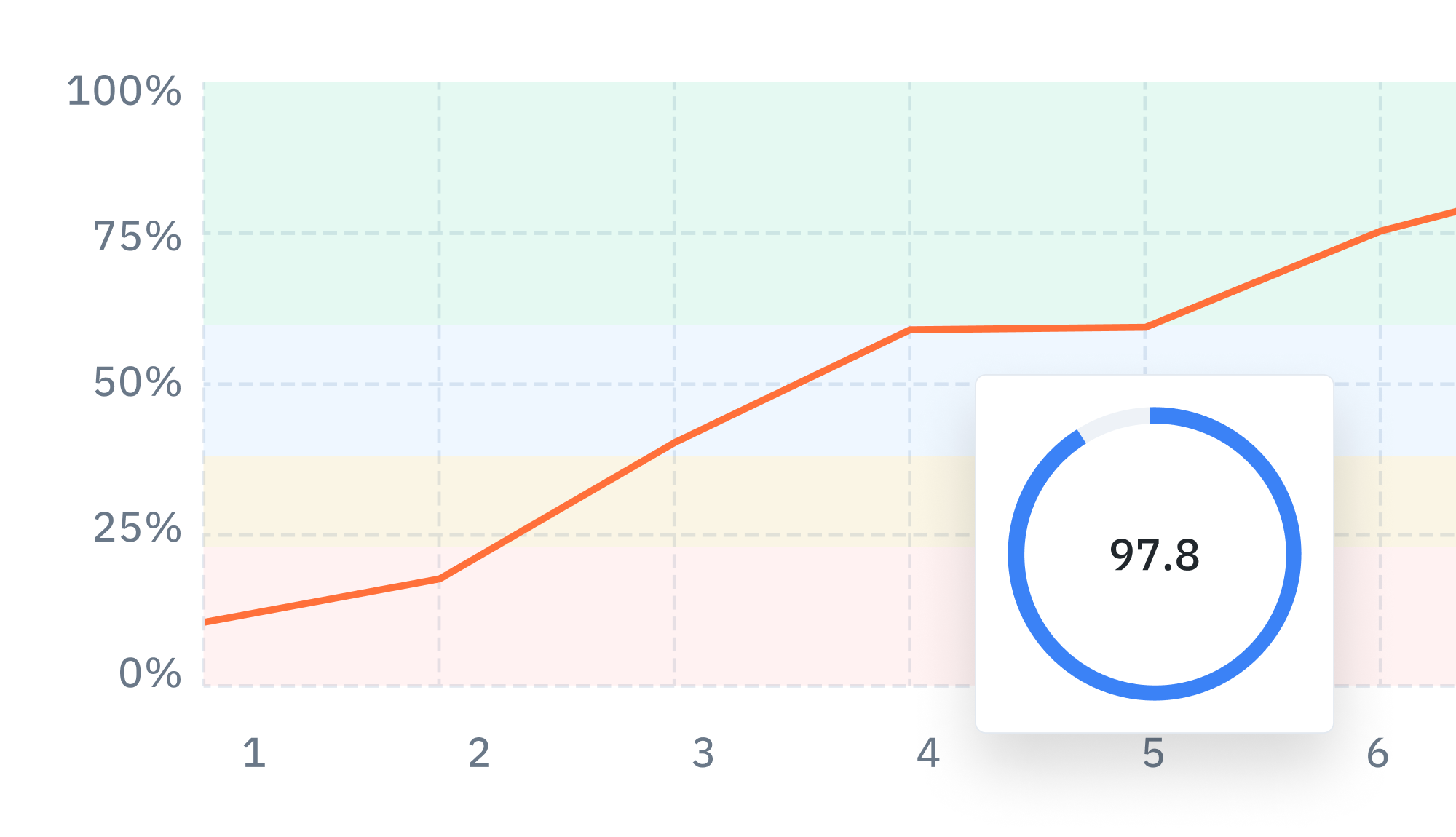
Measure and improve pre-labeling workflows with the automation efficiency score
Automating your data labeling process is not only a key component of an effective data engine, but is key to producing high-quality data, fast. While automation can range from AI-assisted tools to automated labeling pipelines, there is one method that provides the most significant and long-term time and cost savings: pre-labeling. However, it's hard for most teams to measure the impact of their specific use of pre-labeling — a requirement for those experimenting with different tactics and/or models. Quantifying the savings and efficiencies from pre-labeling typically requires teams to meticulously track (usually via manual means such as spreadsheets) labeling time and costs, and then compare them to previous or control group results.
The automation efficiency score is a new metric that will appear on Labelbox users’ project dashboard, on the Automation tab. Instead of operating blindly or spending more time manually tracking efficiency gains from pre-labeling, AI teams now have a tangible way to quantify how their use of pre-labeling accelerates model development.
Curate and version your hyperparameters and datasets
Being able to understand and visualize how different models compare to each other is a crucial aspect of a successful data engine. Rather than flying blind, teams can use Model to configure, track, and compare essential model training hyperparameters alongside training data and data splits. You can easily track and reproduce model experiments to observe the differences and share best practices with your team.
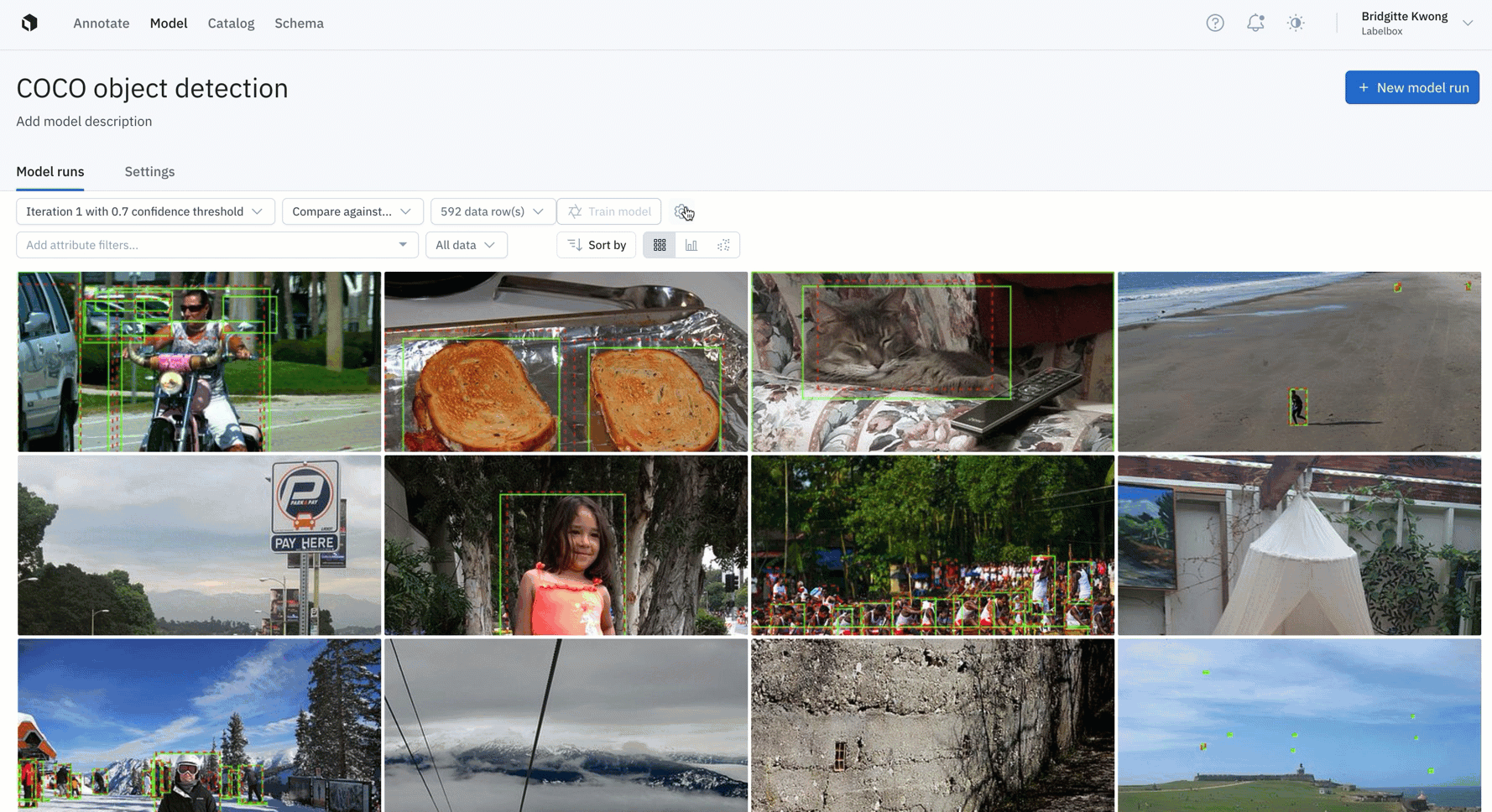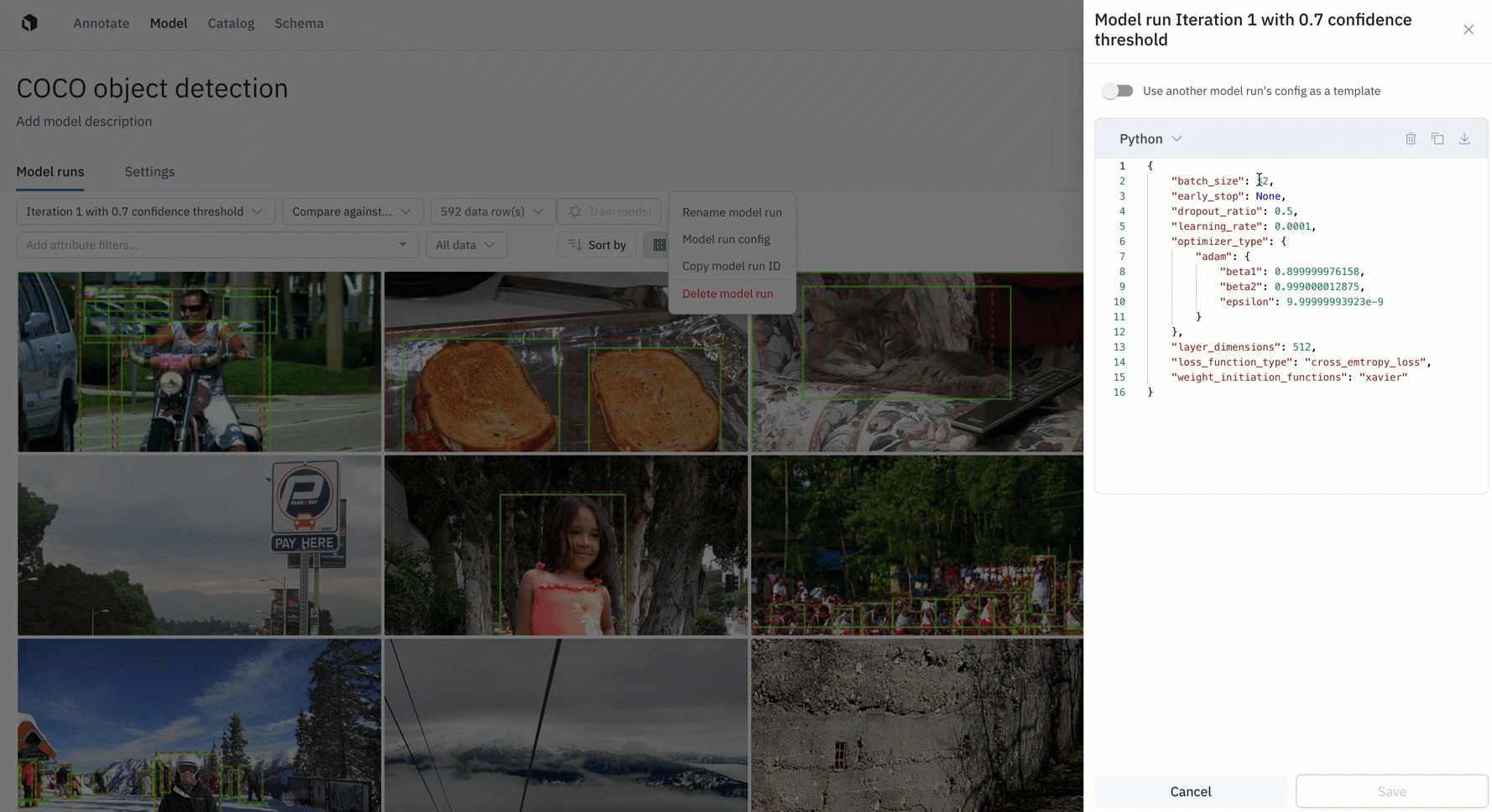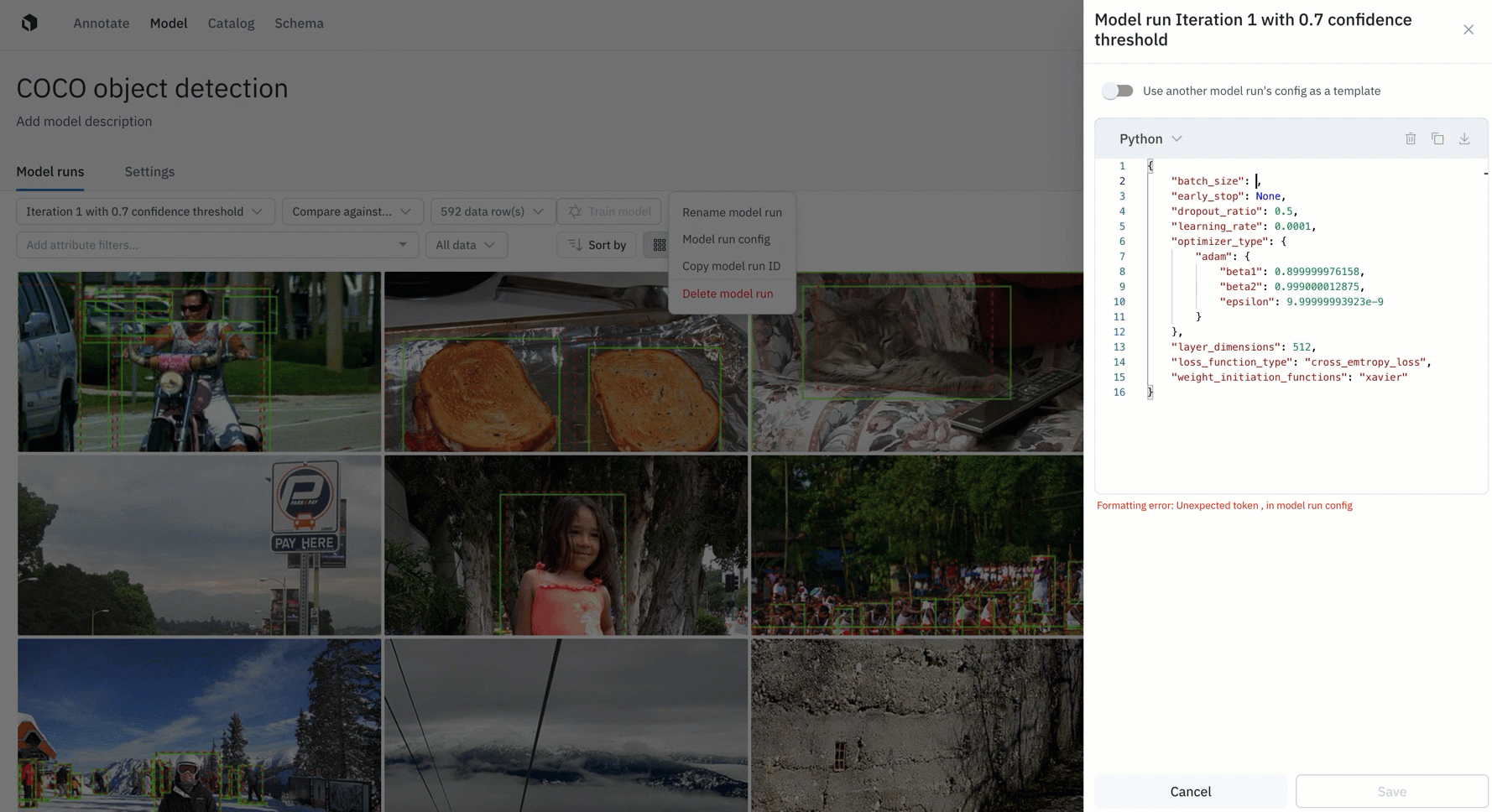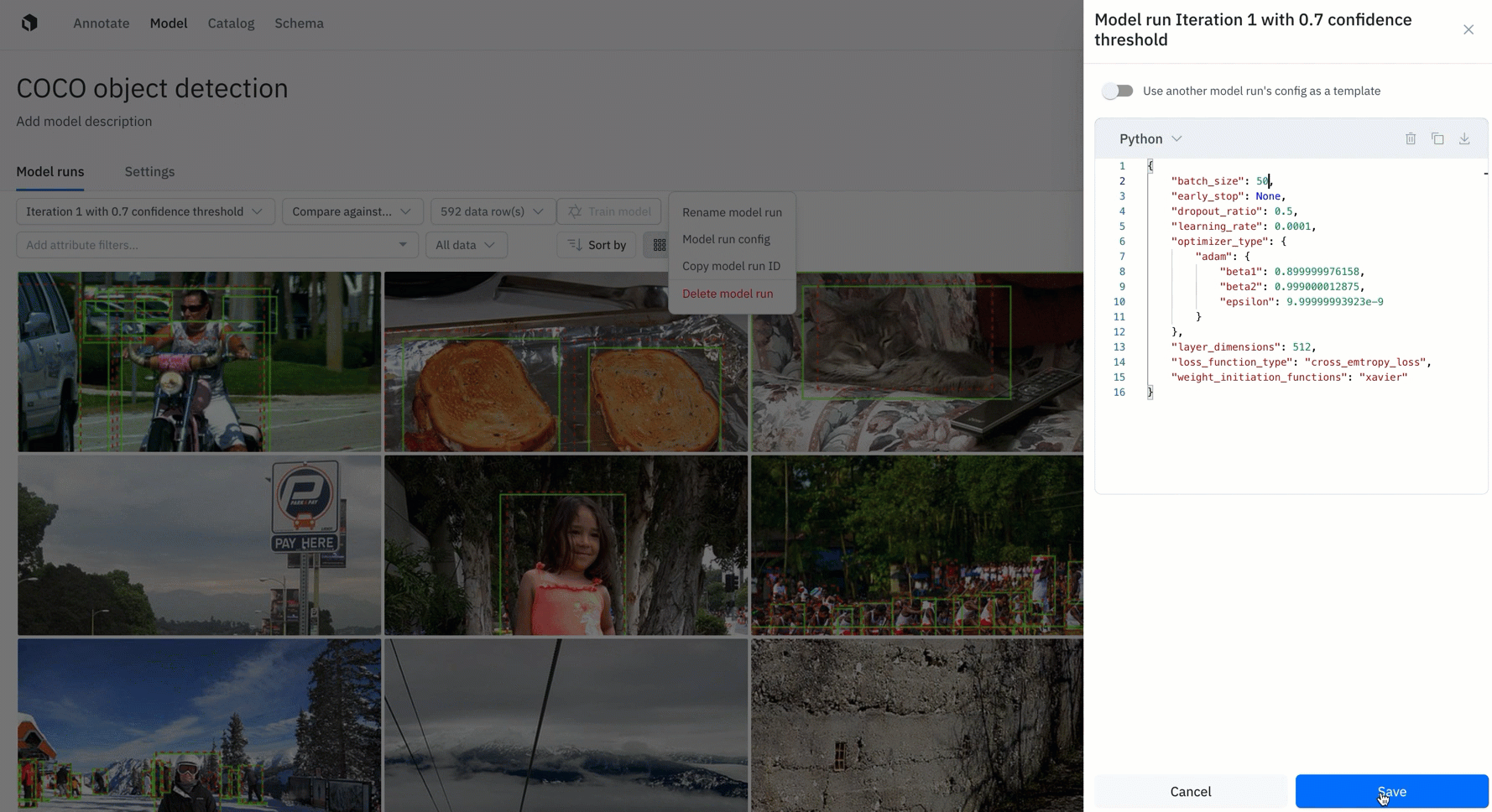
ML teams may want to kick off multiple model runs with different sets of hyperparameters and compare performance. Having a single place to track model configurations and performance is crucial to model iteration and for reproducing model results. Read the guide to learn more.
Discover more impactful features in Labelbox Catalog, Annotate, and Model by visiting our documentation and guides.


