
 All blog posts
All blog postsKahveh Saramout•March 31, 2023
How to prepare your manufacturing organization for the fifth industrial revolution: AI

In last week’s blog post, I showed how manufacturing organizations can save millions by leveraging foundation models. With the fifth industrial revolution underway, however, ensuring that these millions translate into competitive advantage will require them to adopt AI solutions as quickly as possible — a challenge for larger enterprises with baked-in data architecture that’s slow and difficult to change.
To embrace the fifth industrial revolution, manufacturing organizations will need to break down data silos and consolidate their unstructured data, including documents (SOPs, technical documents), images (from computer vision systems at the edge), production history, data historians, and more, into centralized data lakes. This enables the construction of robust production data pipelines that can effectively utilize this valuable information, further enhancing operational efficiency and driving innovation across the enterprise.
Aside from enabling an organization to leverage modern AI technologies, data lakes also promote data democratization empowering all employees to make informed decisions, enabling enterprise wide analytics, and creating standardized processes for data retention and integration. Building a data lake for fine-tuning large language models (LLMs) in a manufacturing environment requires a well-planned strategy and adherence to the following best practices.
- Define clear objectives. Start by outlining the specific goals you want to achieve with the data lake, such as improving the efficiency of the manufacturing process, reducing downtime, or optimizing supply chain management.
- Implement data governance. Your governance framework needs to ensure data quality, consistency, and security. This should include data cataloging, data lineage tracking, access control, and compliance with data privacy regulations.
- Optimize data ingestion and integration. Collect data from various reliable sources, including IoT devices, production machines, and enterprise systems. Use real-time and batch processing methods as needed. Ensure that data is properly cleaned, transformed, and integrated to maintain consistency and accuracy.
- Create a scalable and flexible architecture. Design your data lake architecture to handle large volumes of data, accommodate various data formats, and easily scale up or down depending on your needs. Cloud-based solutions often provide such flexibility and scalability.
- Manage metadata. Maintain comprehensive metadata for all the data stored in the data lake. This includes information about data source, format, schema, and any transformations applied. Metadata helps in data discovery, lineage tracking, and understanding the context of data.
- Ensure data security and privacy. Implement strong security measures to protect sensitive data, including encryption, access control, and monitoring. Ensure compliance with data privacy regulations like GDPR and CCPA.
- Optimize data storage. Choose the right storage format (e.g., Parquet, Avro, or ORC) based on your query patterns and access requirements. Optimize storage costs by leveraging data tiering and data lifecycle management policies.
- Process and analyze data. Use a combination of batch and real-time processing tools (such as Apache Spark, Flink, or Beam) to analyze and process the data. Implement machine learning pipelines for fine-tuning LLMs and other advanced analytics tasks.
- Set it up for monitoring and maintenance. Continuously monitor the performance and health of your data lake. Set up alerts for potential issues and plan regular maintenance activities like data cleanup, optimization, and updates.
- Establish a change management process. This is necessary to handle updates to data sources, schema changes, and modifications in processing logic. This helps in maintaining the stability and reliability of your data lake.
The fifth industrial revolution, fueled by foundation models, holds tremendous potential to revolutionize the manufacturing industry by unlocking value from automation assets, enhancing productivity, and providing organizations with a competitive edge.
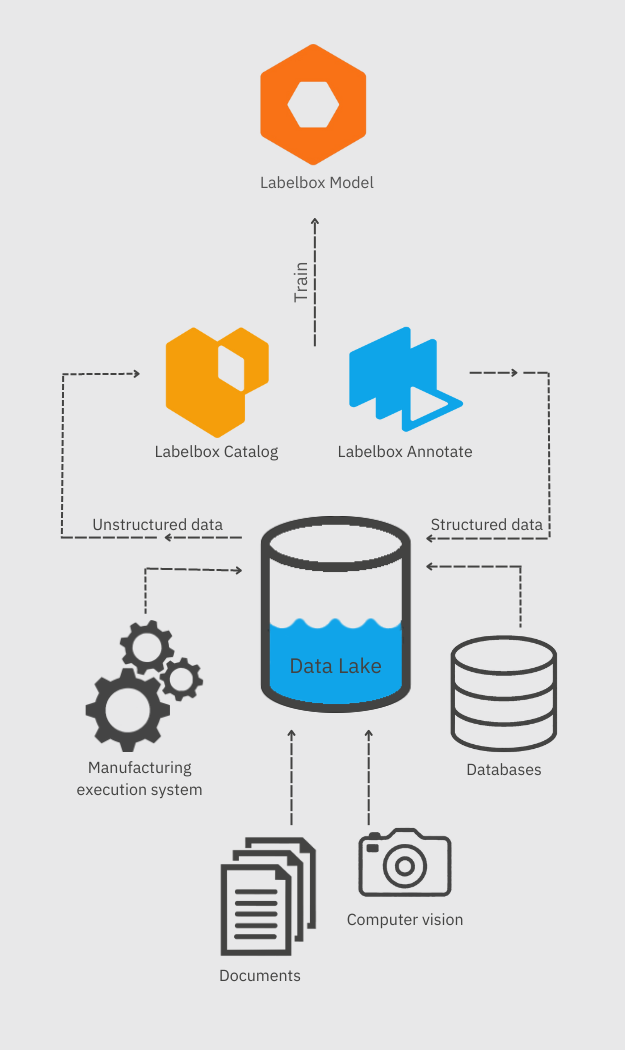
The foundation of the fifth industrial revolution lies in the seamless extraction, transformation, and loading (ETL) of data into a data lake. As a robust storage system, a data lake allows for the accommodation of structured and unstructured data at any scale. In a manufacturing setting, this includes data from manufacturing execution systems, databases, data historians, computer vision systems, and SOP or tech spec repositories.
Here's a simplified ETL strategy for this transition:
- Identify data sources: This includes your execution systems, databases, data historians, and document repositories.
- Establish connections: Ensure safe and accurate data extraction by creating secure links to these systems.
- Define extraction routines: Specify the frequency and the specific data points to be extracted.
- Transform data: Modify the extracted data to a format suitable for the data lake, dealing with any discrepancies.
- Load data into the data lake: Develop a robust process that can handle the volume and variety of your data.
Labelbox has crafted a platform that is optimally suited to help your organization quickly structure your data and develop production-grade models. Tools like Labelbox Catalog facilitate this process by incorporating data from your data lake into an intuitive and user-friendly interface. You can effortlessly query data and find similar information using advanced similarity search features. This holistic approach allows your organizations to fully exploit your data assets and unlock the potential of foundation models.
Labelbox Annotate further enables your organization to label their data and transform unstructured data into structured formats, either by utilizing your own labelers or leveraging Labelbox's expert in-house labeling service. Model Foundry and Labelbox Model offer the quickest path from labeled data to trained models, providing easy access to the most popular and high-performing LLMs. By offering an end-to-end solution, Labelbox empowers your organization to develop and implement AI-driven strategies effectively and efficiently.
The financial benefits of implementing such a system are significant, with net-present values well into the millions. The numerous use cases for LLMs in manufacturing environments demonstrate their capacity to transform various aspects of operations, from decision-making and quality control to predictive maintenance and cross-plant collaboration.
As we stand on the cusp of this transformation, it is essential to remain proactive and agile. By doing so, you can ensure your continued growth, competitiveness, and success in the ever-changing world of industrial automation.


