×![]()

 All blog posts
All blog postsLabelbox•September 23, 2022
Better visualize and track model errors at every iteration

This month's improvements to Labelbox Model empowers teams to better visualize and track model errors. Your model is only as good as your training data — and with these updates, teams can better find and fix label errors for text data, understand model weaknesses with in-depth metrics, and easily compare results for different model runs with different hyperparameters.
Find and fix model & label errors for text data
Teams can now dramatically improve NER model performance by finding and fixing labeling errors within text training data.
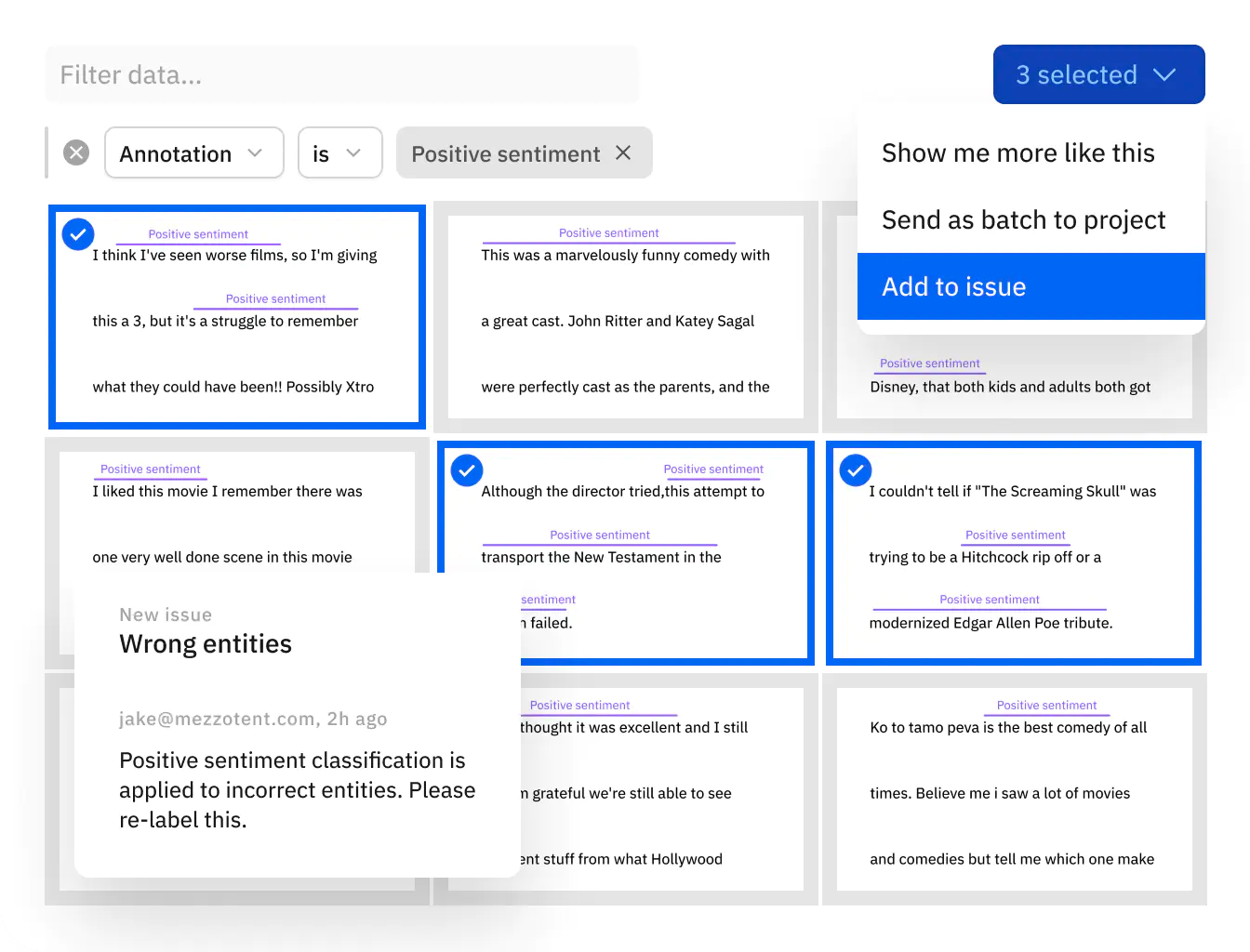
- Visualize ground truth and model predictions for NER data in both Catalog and Model
- Unlock active learning workflows to quickly surface labeling mistakes, understand how your model is performing against ground truth, and prioritize what data to label next
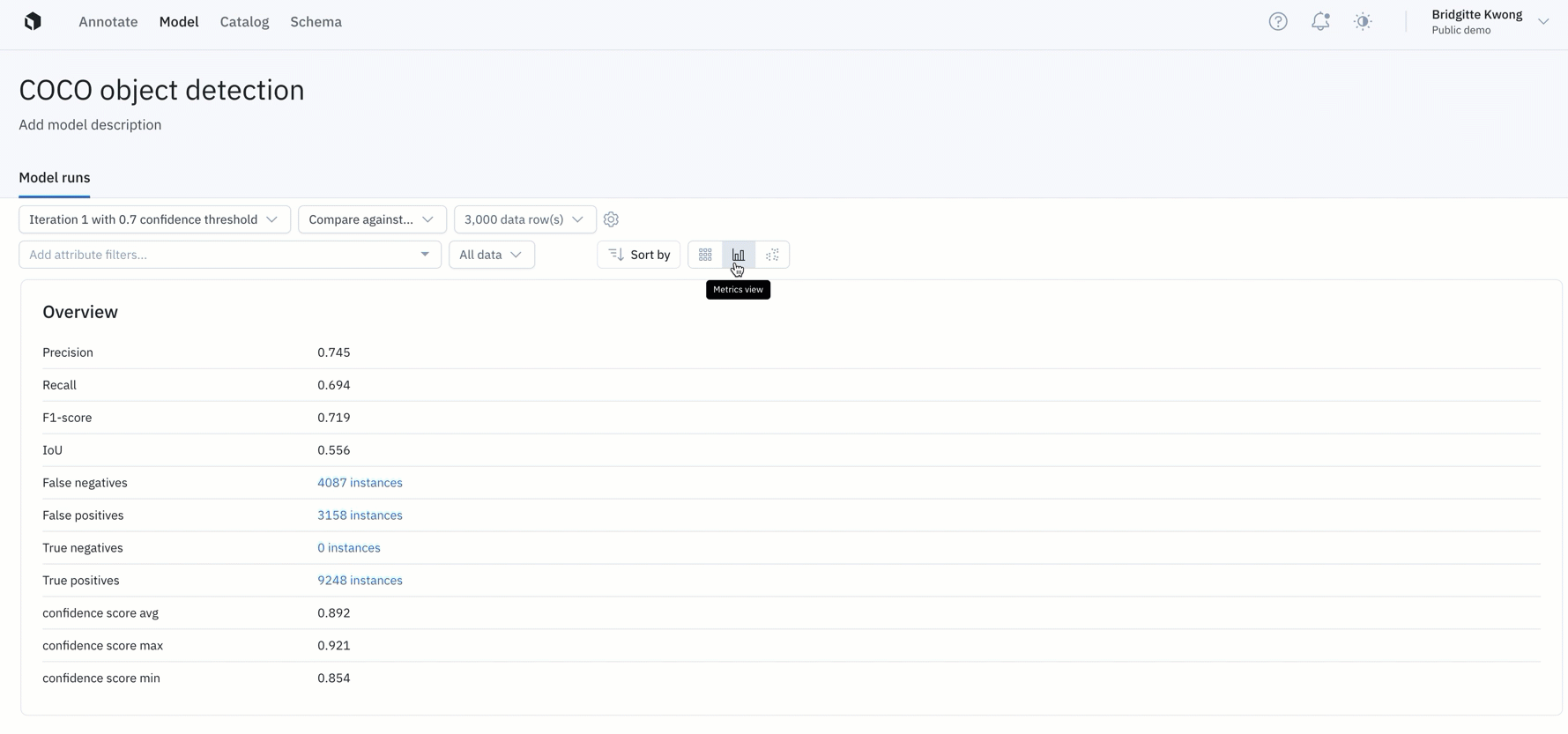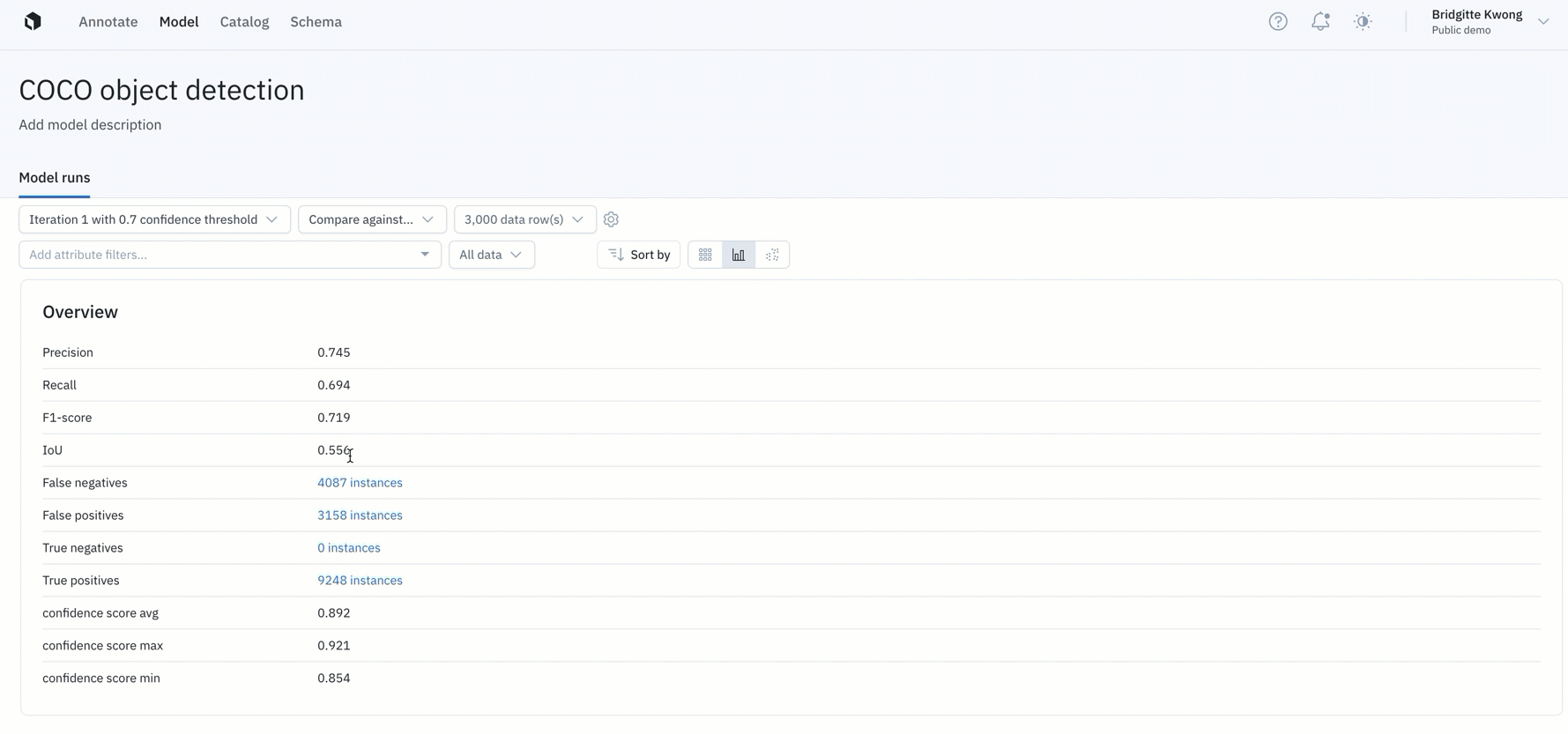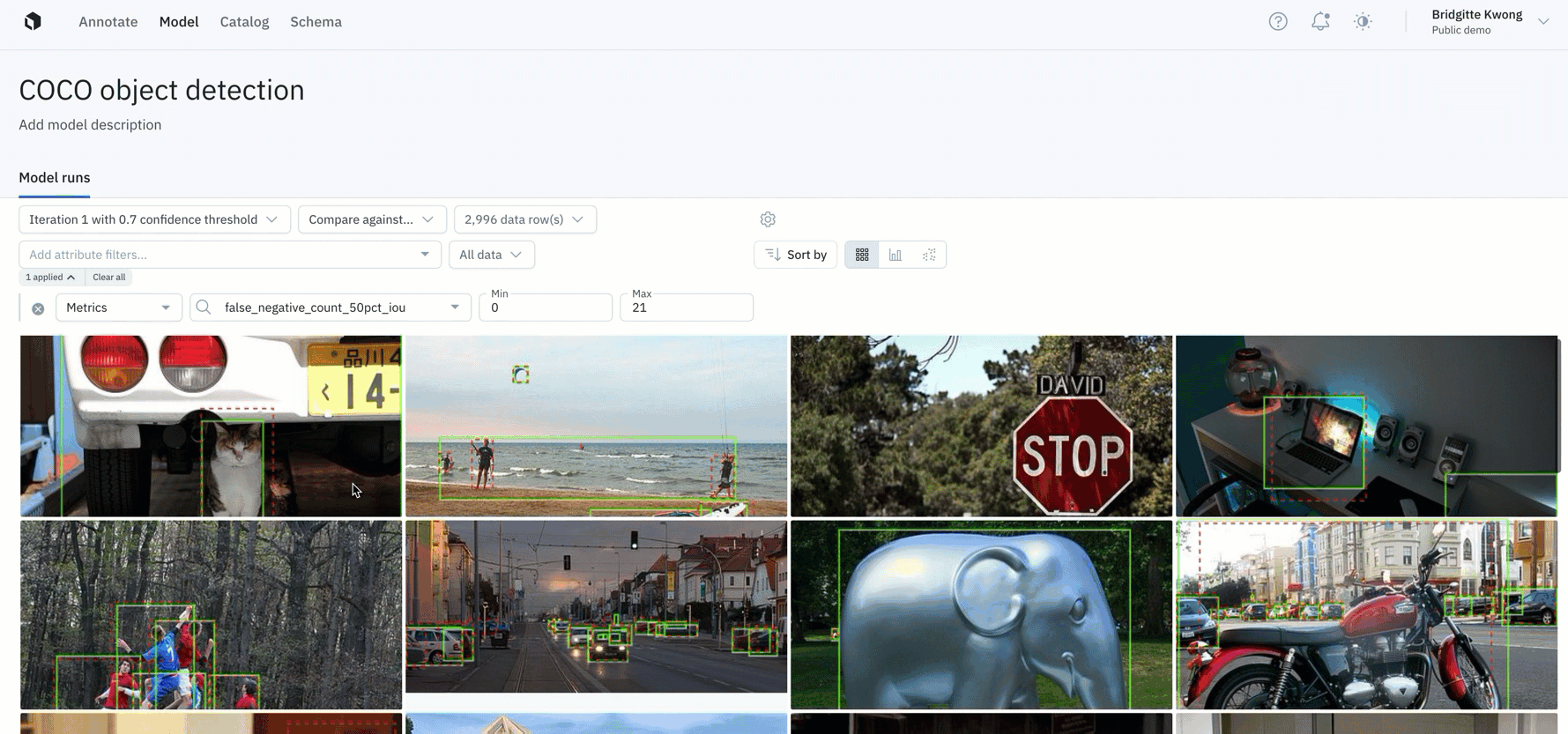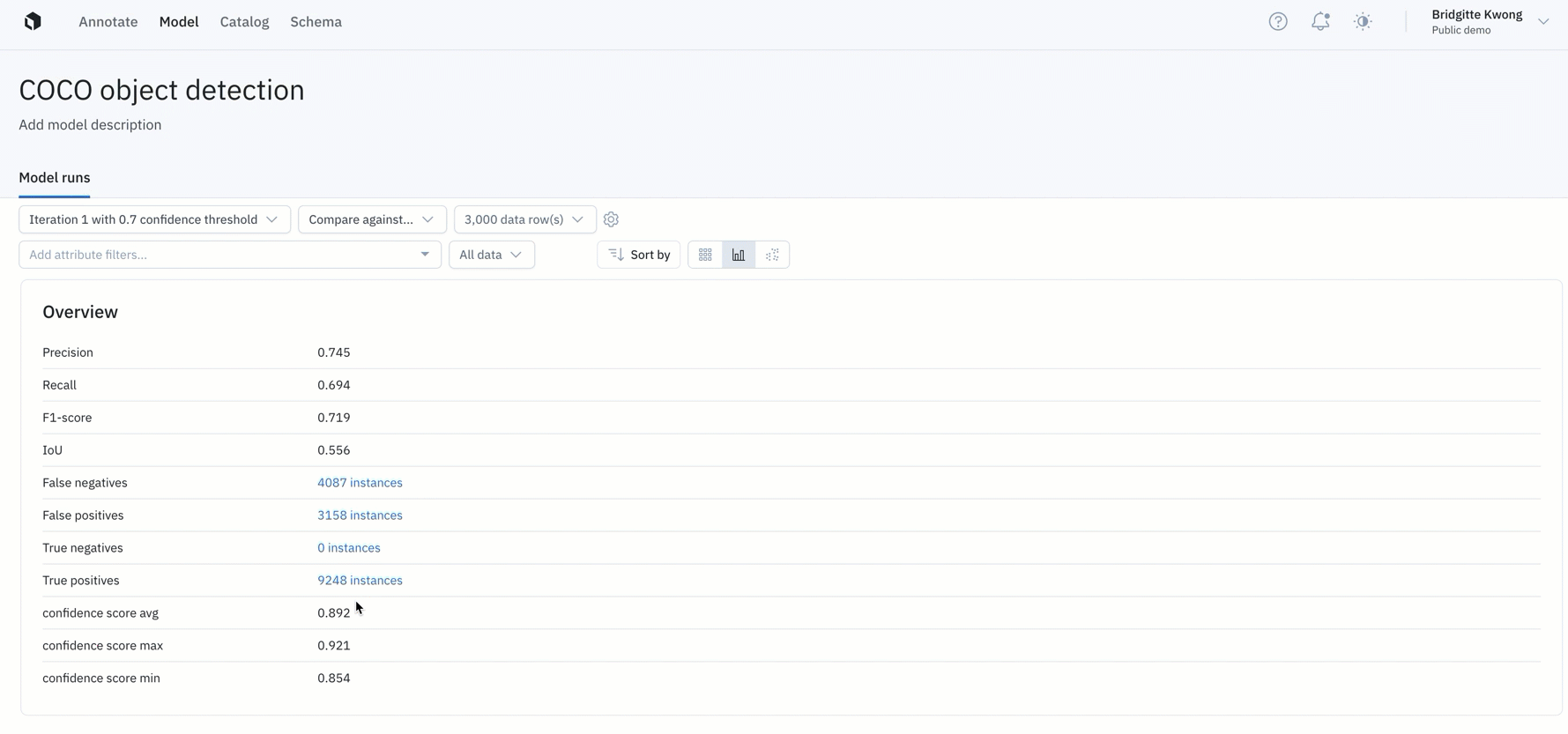
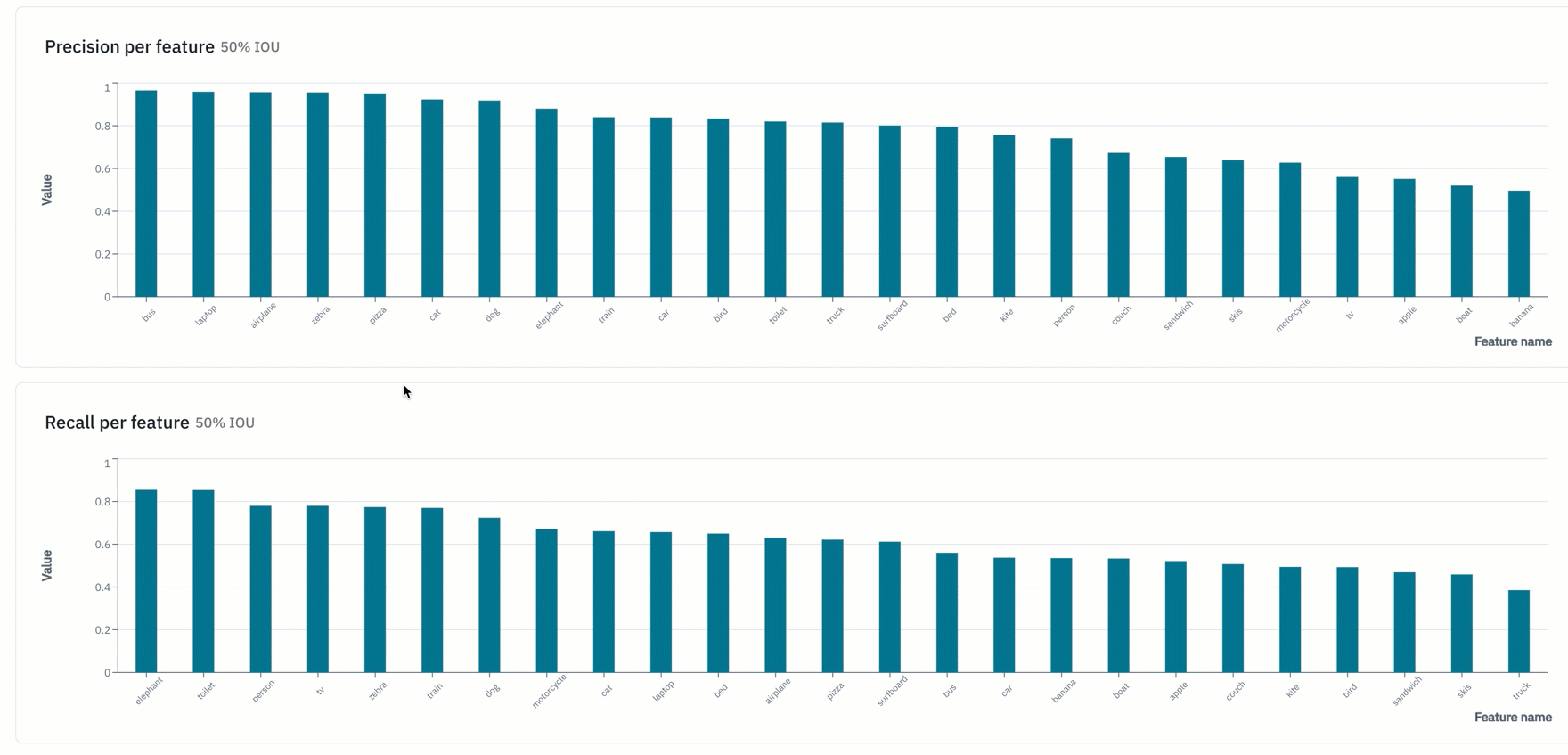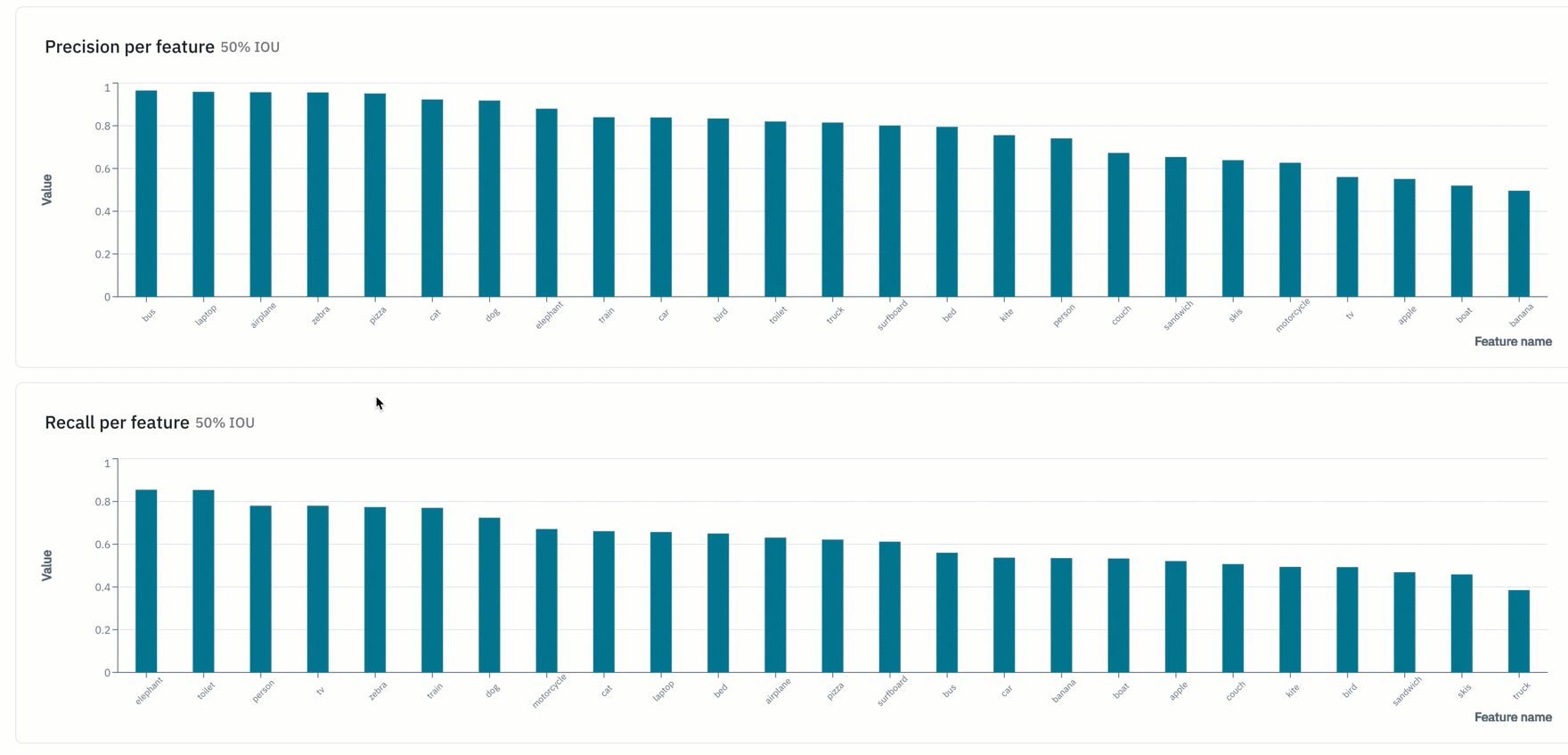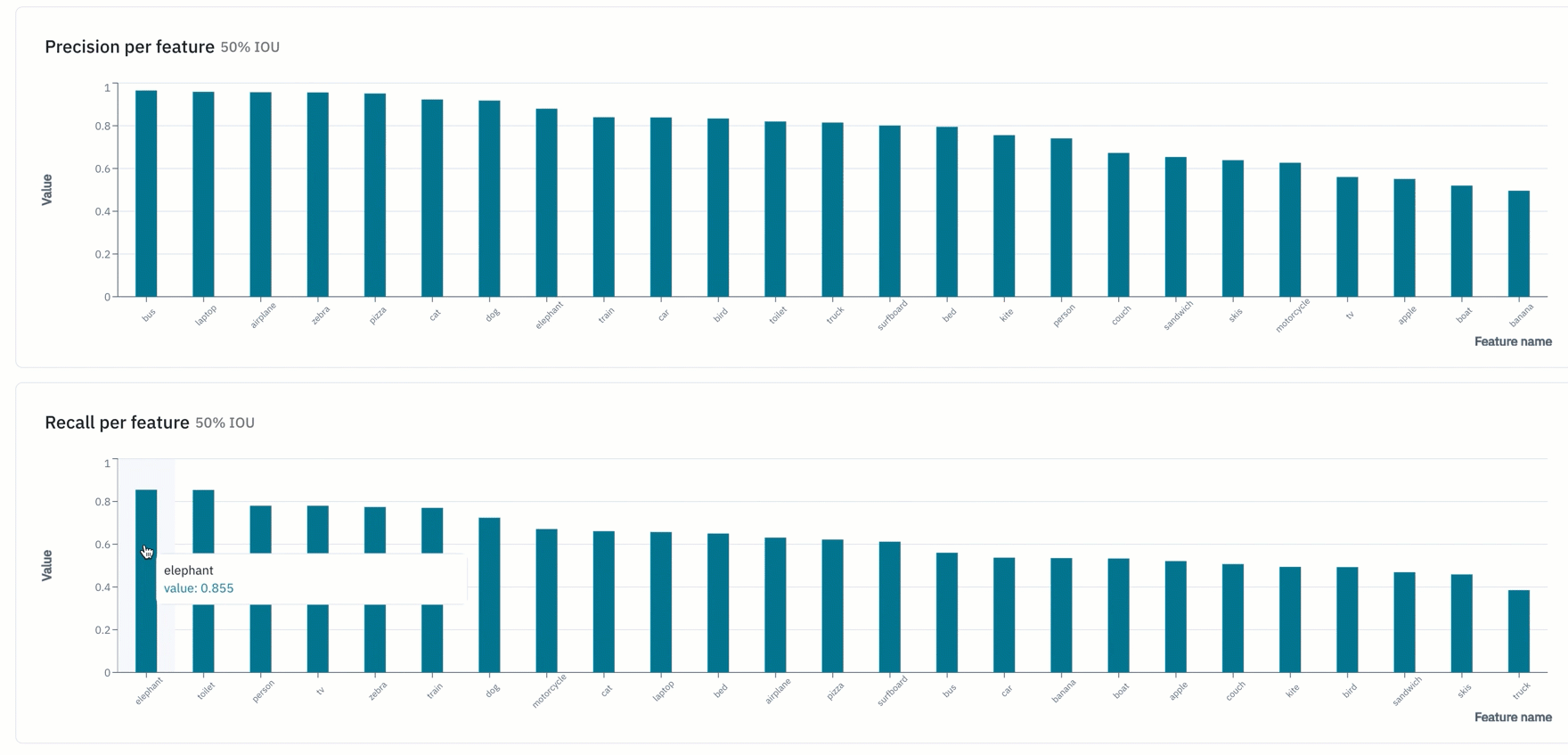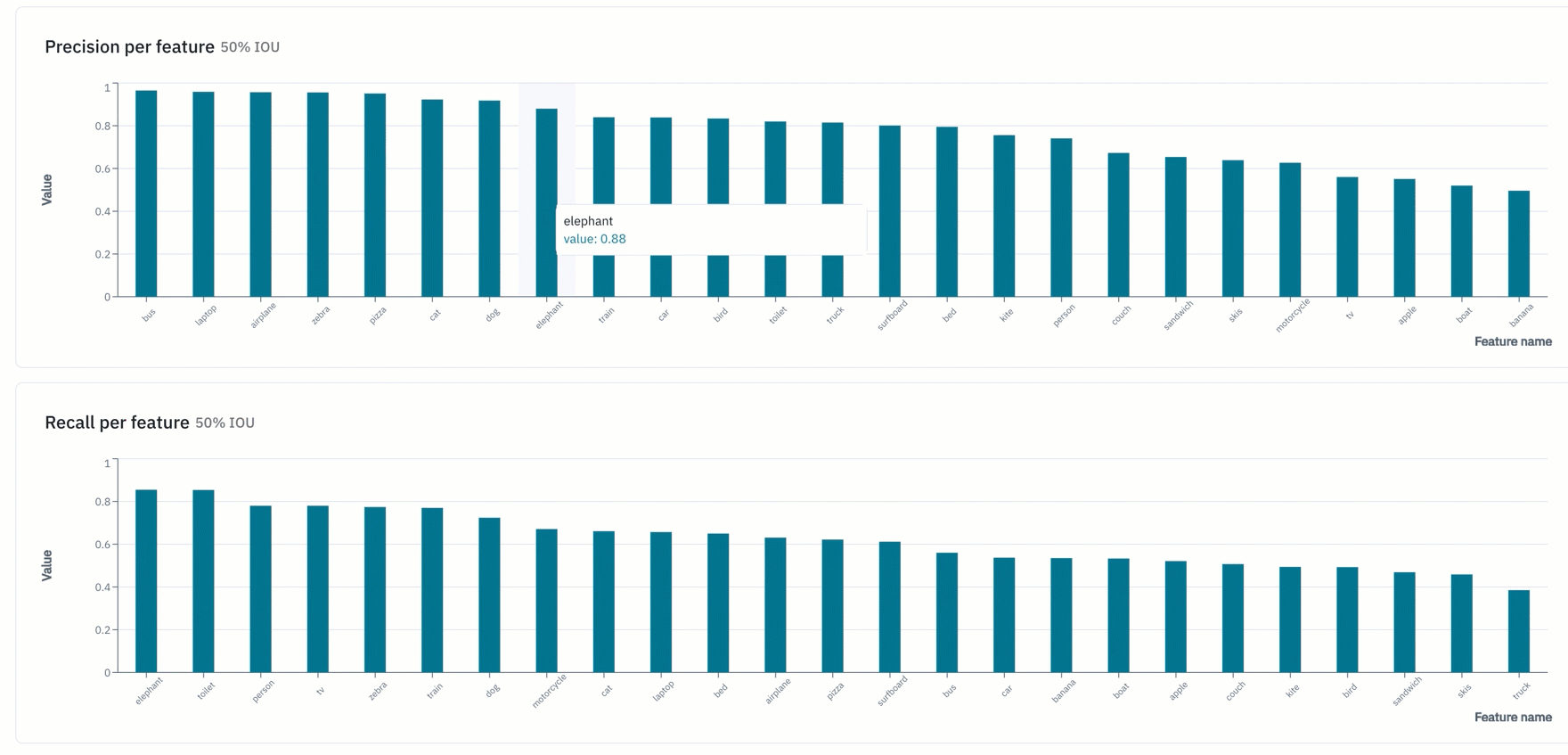
Improve your training data with error analysis and model metrics
Detailed analytics and metrics can compliment active learning workflows to help teams prioritize what data to label next.
- "Overview" provides teams with a snapshot of key metrics such as precision, recall, F1-score, and more
- Binary confusion matrix can help teams figure out the classes with which their model is struggling
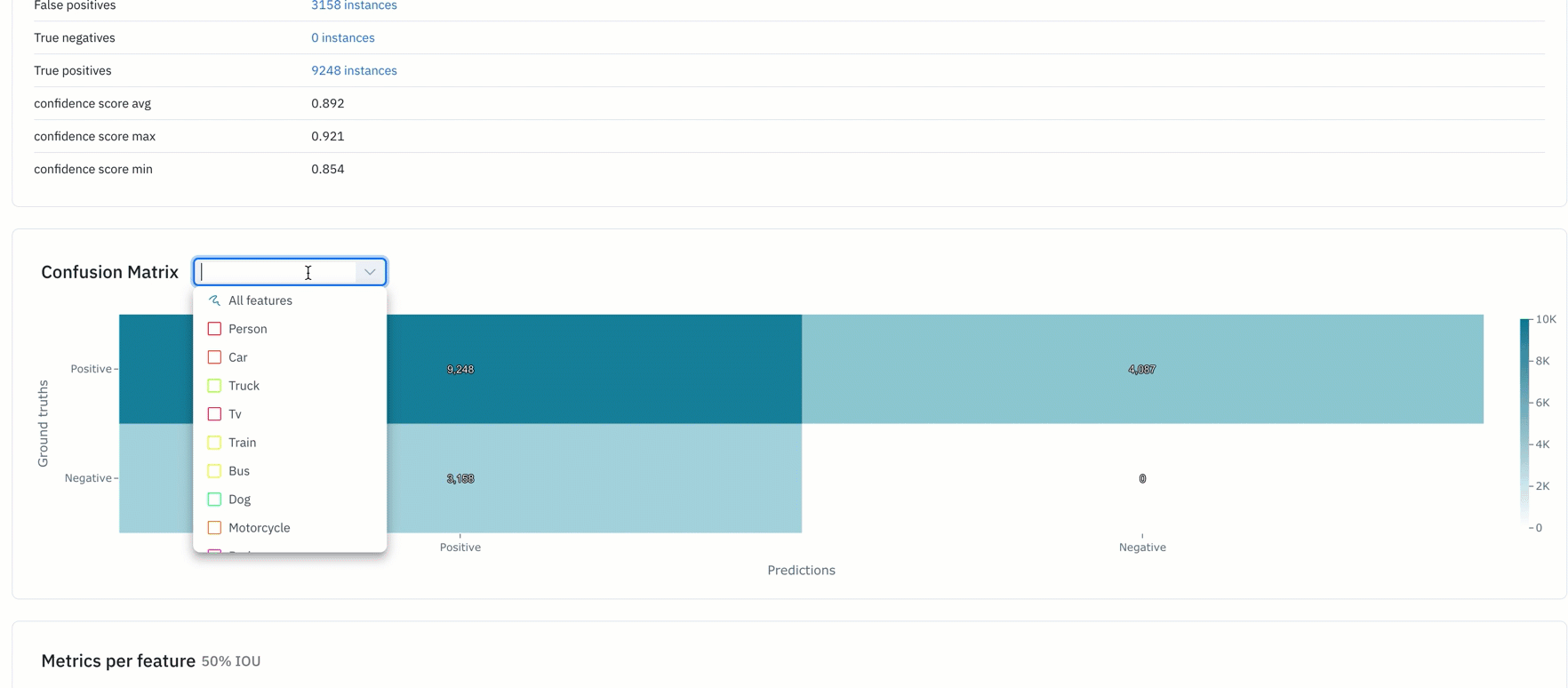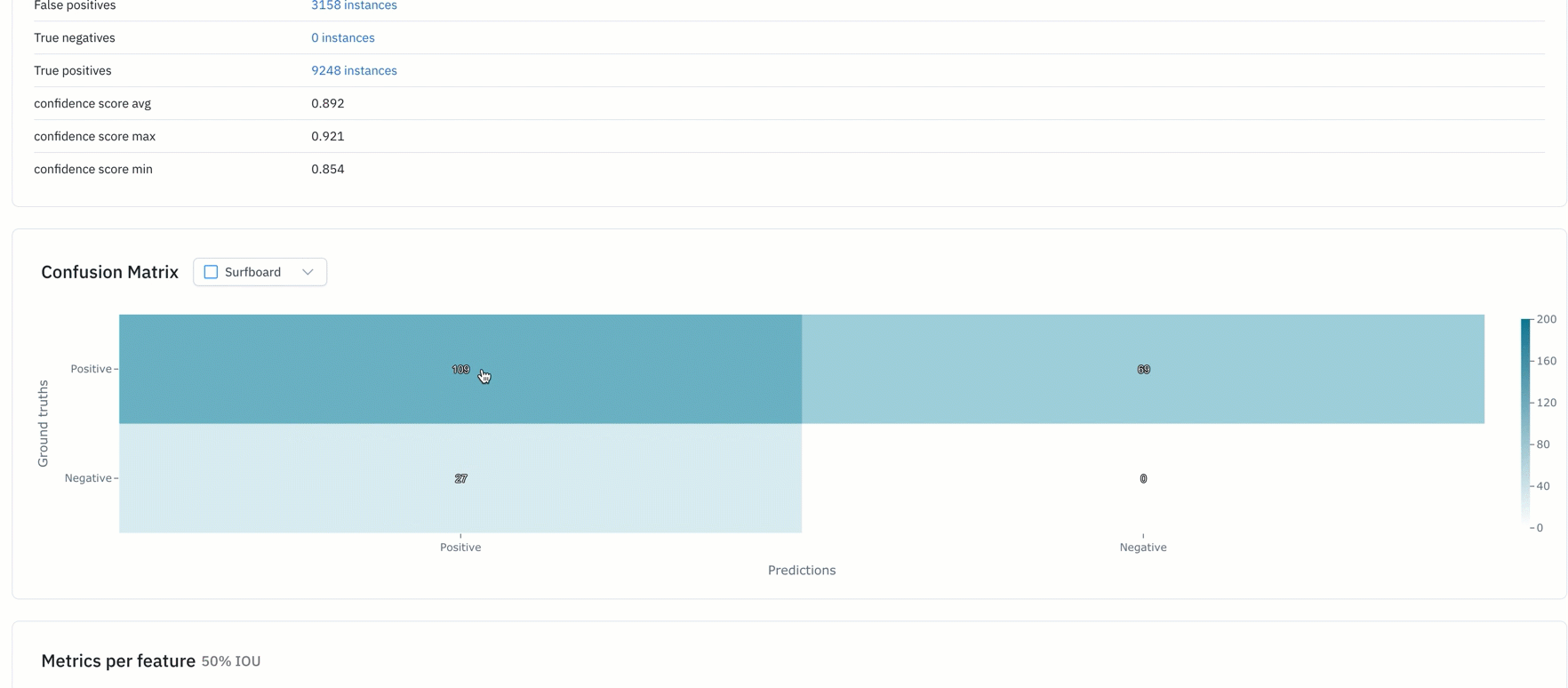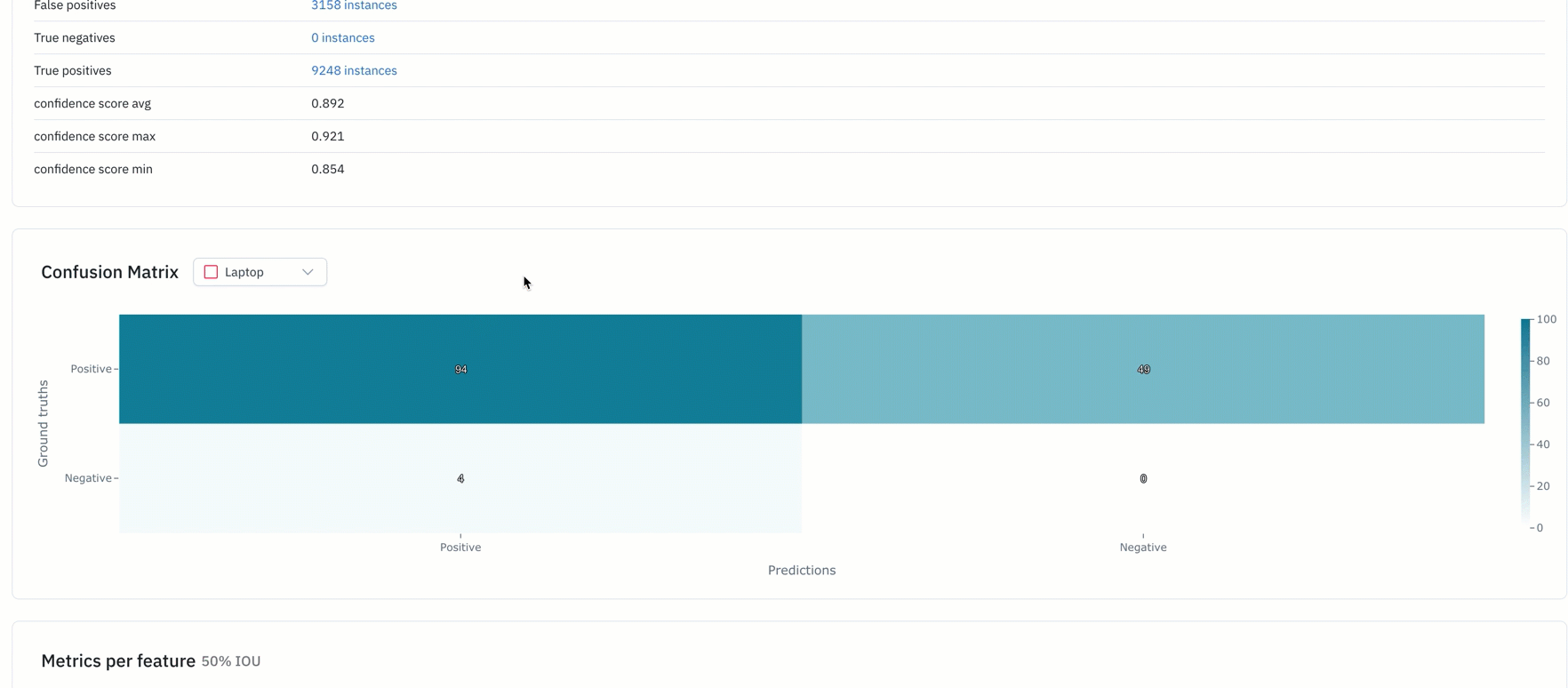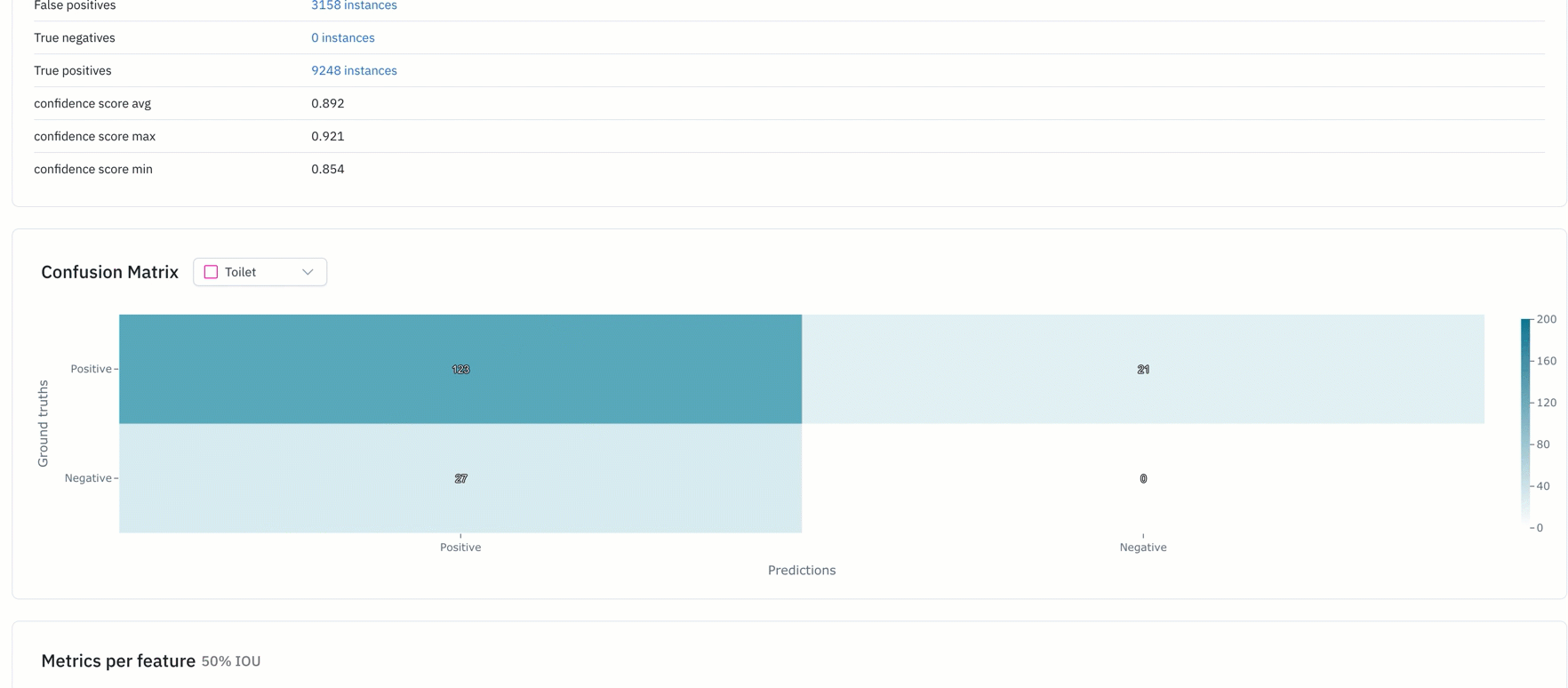
- The precision-recall curve helps teams fine-tune the confidence threshold of their models
- View model metrics in the "detailed view" of a data row in Model to view how a model is performing on a given data row

Configure, track, and compare essential model training hyperparameters
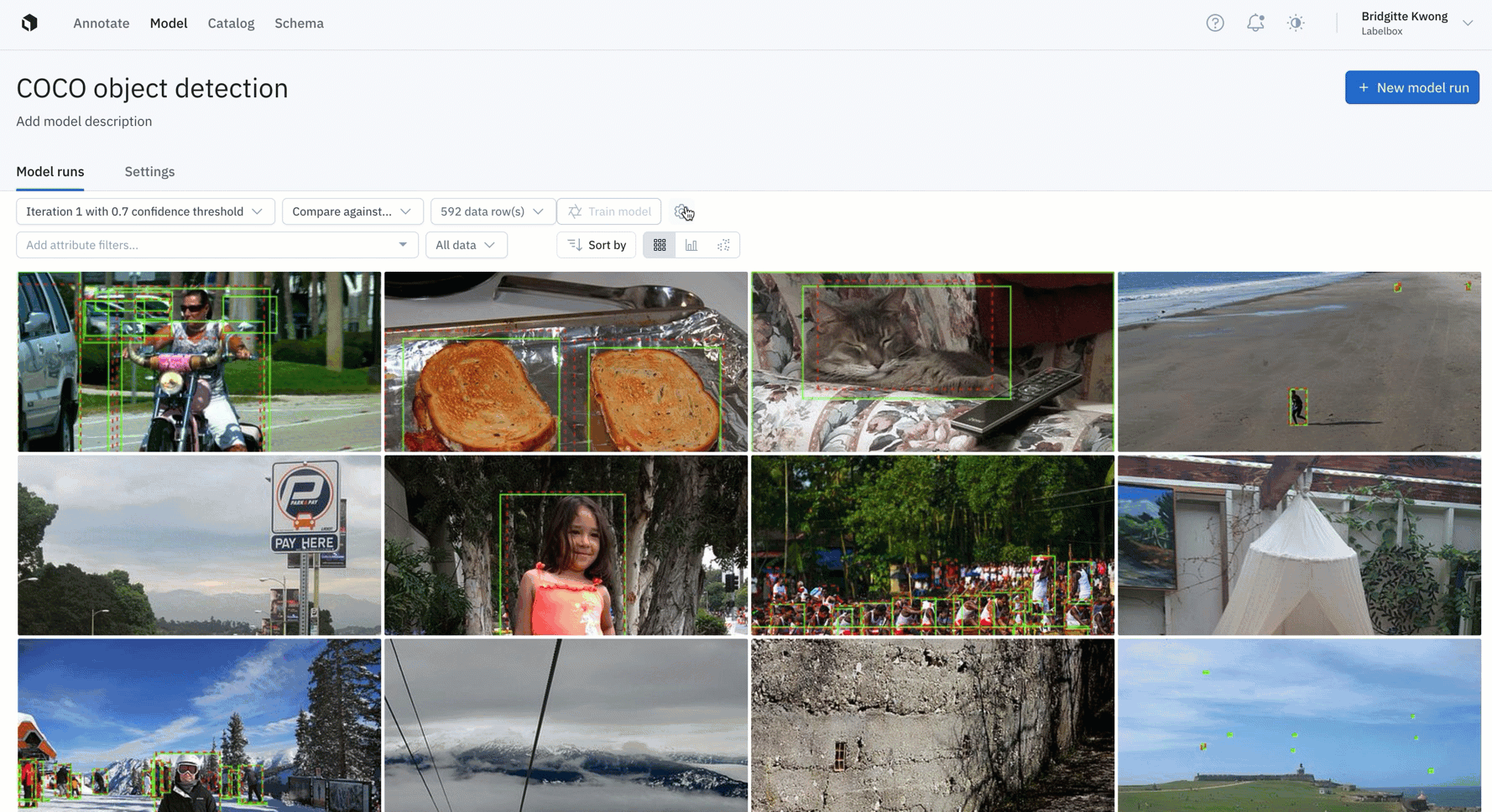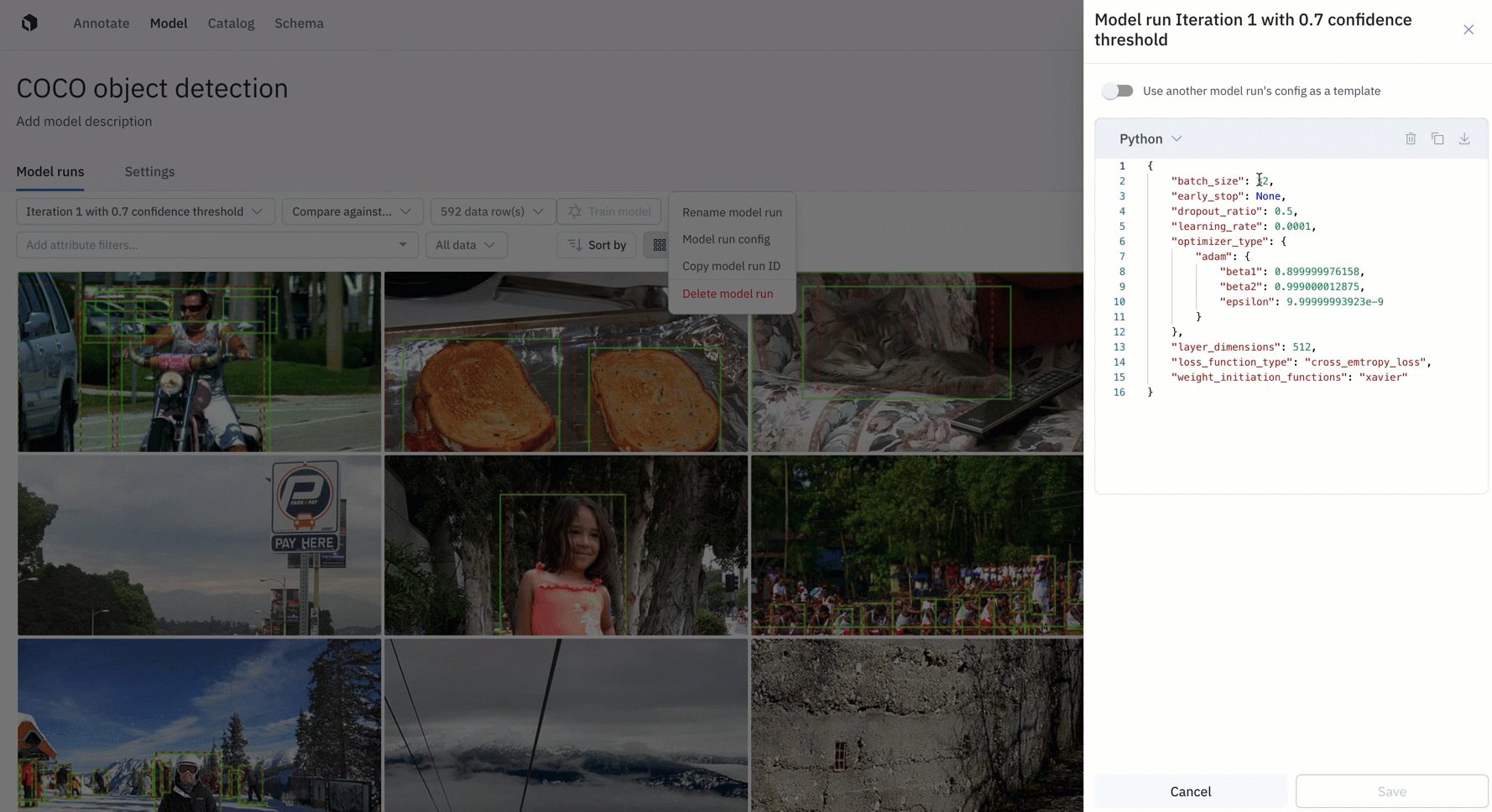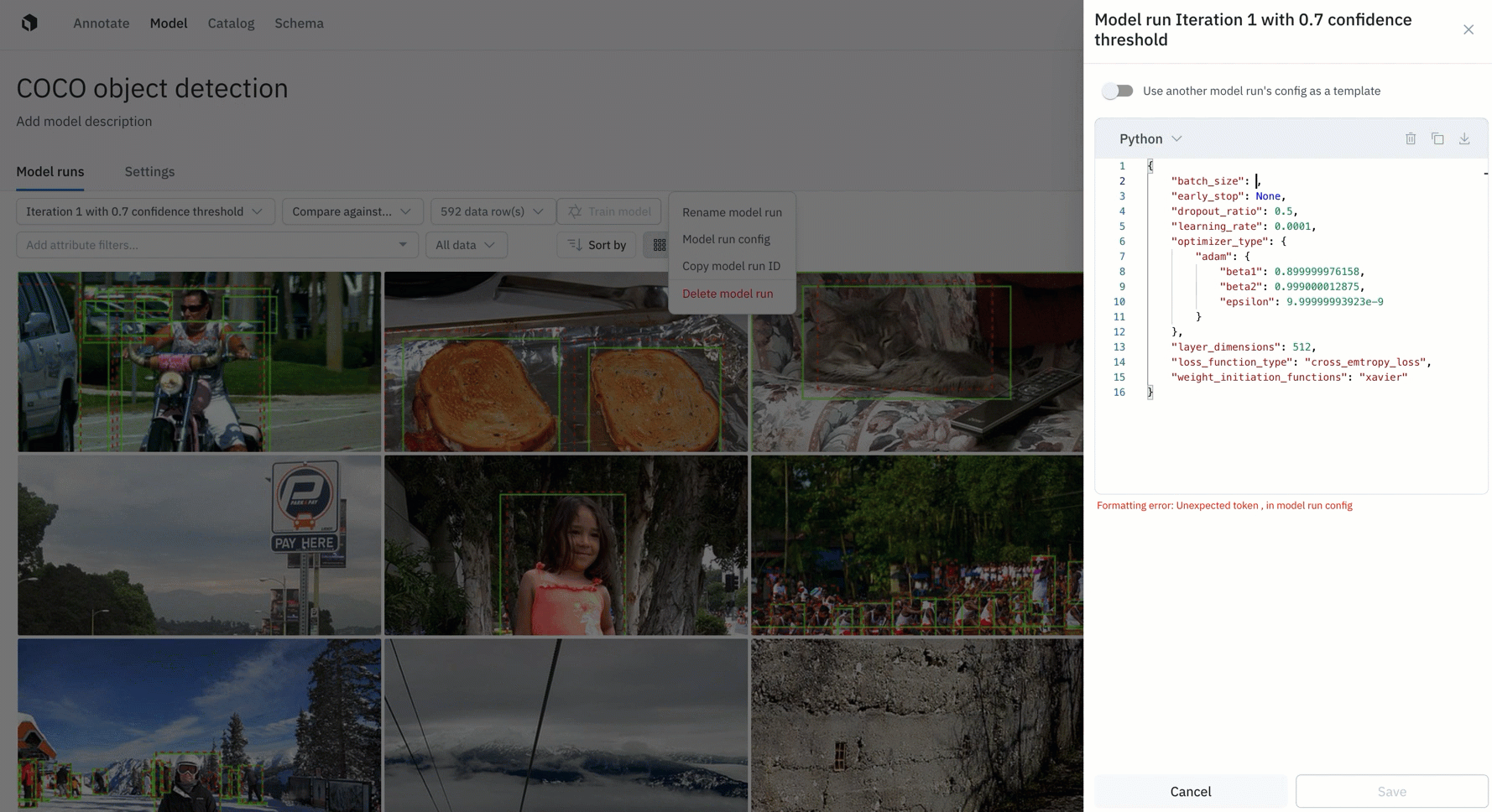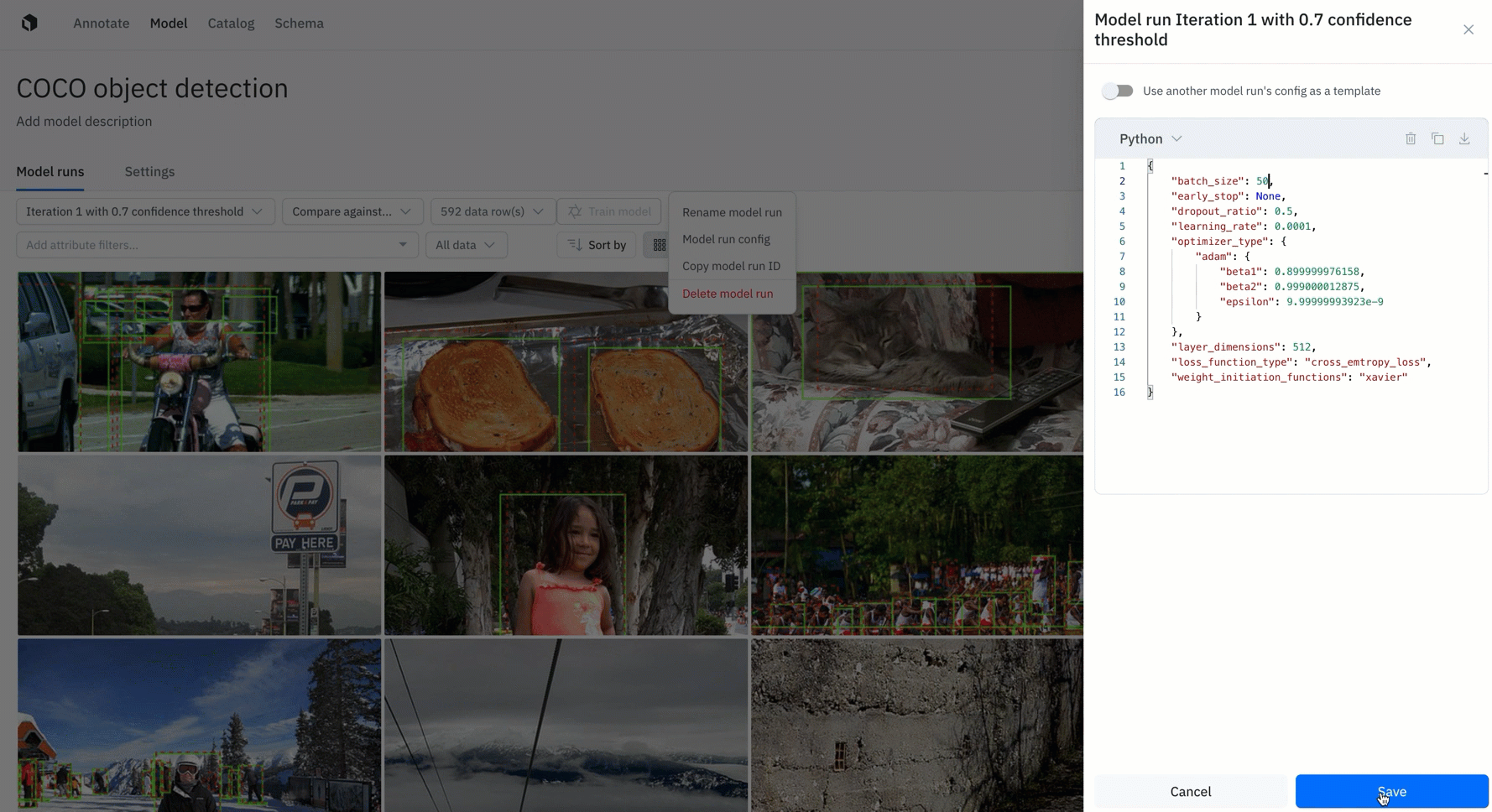
Tracking and reproducing model experiments to compare performance is crucial to AI development, and an integral process supported by a data engine.
- All Labelbox users can now configure, track, and compare essential model training hyperparameters alongside training data and data splits in a single place
- Create and modify model hyperparameters directly through the Labelbox UI or use the SDK
To learn more about how to curate and version your training datasets and hyperparameters, watch this step-by-step video tutorial walkthrough.


