
 All guides
All guidesA comprehensive approach to evaluating text-to-image models

To explore our latest in image generation evaluation, visit Labelbox leaderboards. By leveraging our modern AI data factory, we're redefining AI evaluation. Our new, innovative approach combines human expertise with advanced metrics to surpass traditional benchmarks.
As text-to-image AI models continue to evolve, it's become increasingly important to develop robust evaluation methods that can assess their performance across multiple dimensions. In this post, we'll explore a comprehensive approach to evaluating 3 leading text-to-image models - DALL-E 3, Stable Diffusion, and Imagen 2 - using both human preference ratings and automated evaluation techniques.
The rise of text-to-image models
Text-to-image generation has seen remarkable progress in recent years. Models like DALL-E 3, Stable Diffusion, and Imagen 2 can now produce strikingly realistic and creative images from natural language descriptions. This technology has many useful applications, from graphic design and content creation to scientific visualization and beyond.


As these models become more advanced, having reliable ways to compare their performance and identify areas for improvement are paramount. Let’s next dive into how we developed a two-fold evaluation approach for getting more granularity into their performance.
[1] Human preference evaluation

To capture subjective human preference, we first set up the evaluation project using our specialized and highly-vetted Alignerr workforce, with consensus set to three human labelers per data row, allowing us to tap into a network of expert raters to evaluate image outputs across several key criteria:
Alignment with prompt: Raters assessed how well each generated image matched the given text prompt on a scale of high, medium, or low. For example, for the prompt "A red apple on a wooden table":
- High: Image shows a clear, realistic red apple on a wooden table
- Medium: Image shows an apple, but it's green or the table isn't clearly wooden
- Low: Image shows an unrelated scene
Photorealism: This criterion evaluates how closely the image resembled a real photograph:
- High: Realistic lighting, textures, and proportions
- Medium: Somewhat realistic but with slight issues in shadows or textures
- Low: Cartoonish or artificial appearance
Detail: Raters then determined the level of detail and overall clarity:
- High: Fine details visible (e.g., individual leaves, fabric textures)
- Medium: Major elements clear, but finer details somewhat lacking
- Low: Overall blurry or lacking significant detail
Artifacts: Finally, raters identified any visible artifacts, distortions, or errors, such as:
- Unnatural distortions in objects or backgrounds
- Misplaced or floating elements
- Inconsistent lighting or shadows
- Unnatural repeating patterns
- Blurred or pixelated areas
[2] Automated evaluations
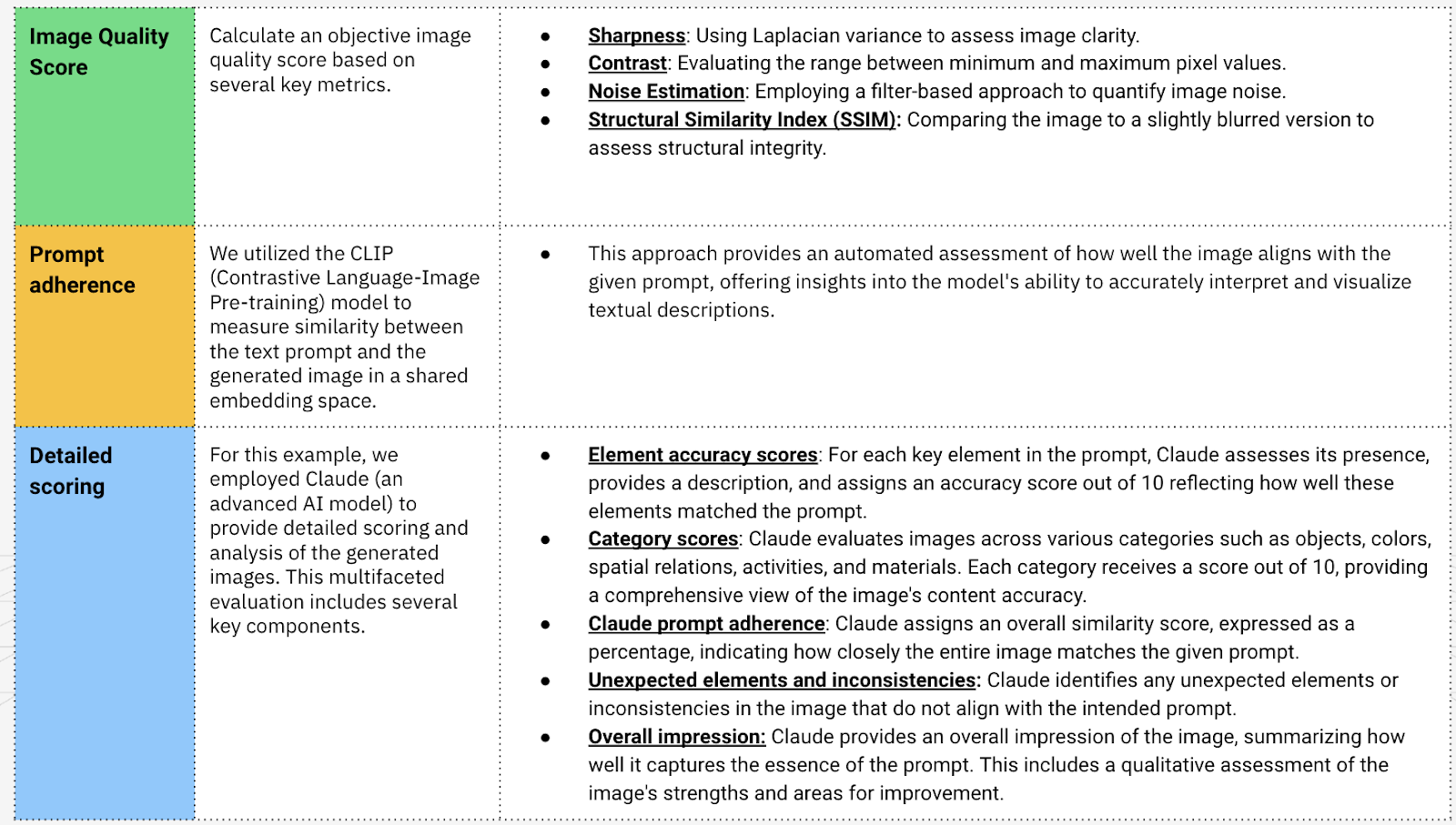
To complement human ratings, we implemented several automated evaluation techniques. Here’s an example for one image.
Image Quality Score: We calculated an objective image quality score based on several key metrics:
- Sharpness: Using Laplacian variance to assess image clarity.
- Contrast: Evaluating the range between minimum and maximum pixel values.
- Noise Estimation: Employing a filter-based approach to quantify image noise.
- Structural Similarity Index (SSIM): Comparing the image to a slightly blurred version to assess structural integrity.
These metrics were combined into a comprehensive quality score in order to provide an objective measure of the image's technical attributes.
Prompt adherence: We utilized the CLIP (Contrastive Language-Image Pre-training) model to measure similarity between the text prompt and the generated image in a shared embedding space. This approach provides an automated assessment of how well the image aligns with the given prompt, offering insights into the model's ability to accurately interpret and visualize textual descriptions.
Detailed scoring: We employed Claude, an advanced AI model, to provide detailed scoring and analysis of the generated images. This multifaceted evaluation includes several key components.
- Element accuracy scores: For each key element in the prompt, Claude assesses its presence, provides a description, and assigns an accuracy score out of 10 reflecting how well these elements matched the prompt.
- Category scores: Claude evaluates images across various categories such as objects, colors, spatial relations, activities, and materials. Each category receives a score out of 10, providing a comprehensive view of the image's content accuracy.
- Claude prompt adherence: Claude assigns an overall similarity score, expressed as a percentage, indicating how closely the entire image matches the given prompt.
- Unexpected elements and inconsistencies: Claude identifies any unexpected elements or inconsistencies in the image that do not align with the intended prompt.
- Overall impression: Claude provides an overall impression of the image, summarizing how well it captures the essence of the prompt. This includes a qualitative assessment of the image's strengths and areas for improvement.
Results
Our evaluation of 100 images across a diverse set of complex prompts, generated by GPT-4, stress-tested and provided valuable insights into the capabilities of Stable Diffusion, DALL-E, and Imagen 2.
Here’s a summary of the human-preference evaluations:
Model rankings and initial findings:
- Stable Diffusion ranked first in 50.7% of cases, DALL-E in 38%, and Imagen 2 in 11.3%.
- Stable Diffusion ranked second (37%), followed by DALL-E (33%) and Imagen 2 (30%)
- Imagen 2 was ranked third (59%), while DALL-E and Stable Diffusion were ranked last less often (29% and 12% respectively
Performance metrics (as percentages of maximum possible scores):
- Stable Diffusion: 84.3% prompt alignment, 85.3% photorealism, 91.7% detail/clarity.
- DALL-E: 84.3% prompt alignment, 58.3% photorealism, 83.7% detail/clarity.
- Imagen 2: 61.3% prompt alignment, 74.7% photorealism, 71.3% detail/clarity.
Here’s a summary of the detailed auto evaluation metrics:
Stable Diffusion emerged as a consistent performer across various metrics:
- Claude’s prompt adherence score: 82.27%. More specifically, attributed to accurate/realistic colors (89.40%) and depicting objects (89.30%)
- However, image quality (34.98%) was relatively low
DALL-E excelled in prompt interpretation and visualization:
- Claude’s prompt adherence score: 87.04%. More specifically, attributed to depicting objects well (91.60%) and displaying moving activities accurately (81.10%)
- Strongest in translating textual descriptions into visual elements
- However, image quality (30.11%) was lowest
Imagen 2 performed the worst, but had a higher technical quality for images:
- Lowest Claude prompt adherence score (76.86%) and aspect accuracy (70.92%)
- Much weaker in moving activities (72.20%) and detailed attributes (77.70%)
- Higher image quality (55.55%) than the other two models
Analysis and insights:

Comparing the auto evaluation metrics to the human preference evaluations reveals some additional interesting findings:
- Stable Diffusion's balanced performance: Stable Diffusion emerged as the top performer overall in human evaluations, ranking first in 50.7% of cases. It showed consistent high scores across human-evaluated metrics, particularly excelling in detail/clarity (91.7%) and photorealism (85.3%). However, the auto evaluation revealed a relatively low image quality score (34.98%), suggesting that technical image quality doesn't always correlate with human perception of quality.
- DALL-E's strengths and weaknesses: While DALL-E ranked first in 38% of human evaluations, it showed a significant weakness in human-perceived photorealism (58.3%). Interestingly, it had the highest Claude prompt adherence score (87.04%) in the auto evaluation, which aligns with its strong performance in human-evaluated prompt alignment (84.3%). This suggests DALL-E excels at interpreting and executing prompts, but may struggle with realistic rendering.
- Imagen 2's technical quality vs. human preference: Imagen 2 consistently ranked lower in human preferences, struggling particularly with prompt alignment (61.3%). However, it had the highest technical image quality score (55.55%) in the auto evaluation. This discrepancy highlights that technical image quality doesn't necessarily translate to human preference or perceived prompt adherence.
- Prompt alignment discrepancies: While human evaluations showed Stable Diffusion and DALL-E tied in prompt alignment (84.3% each), the auto evaluation gave DALL-E a higher score (87.04%) compared to Stable Diffusion (82.27%). This suggests that human and AI perceptions of prompt adherence may differ slightly.
- Photorealism and image quality: The human-evaluated photorealism scores don't align with the auto-evaluated image quality scores. Stable Diffusion led in human-perceived photorealism (85.3%) but had low technical image quality (34.98%). Conversely, Imagen 2 had the highest technical image quality (55.55%) but ranked second in human-perceived photorealism (74.7%).
- Detail and clarity vs. technical metrics: Stable Diffusion stood out in human-evaluated detail and clarity (91.7%), which aligns with its high auto-evaluated scores in depicting objects (89.30%) and accurate colors (89.40%). This suggests a correlation between these technical aspects and human perception of detail and clarity.
It's also important to note that this study didn't include Midjourney due to its Discord-only integration, which made it challenging to implement into our evaluation study. While Midjourney is recognized for its high-quality output, its unconventional access method can be a barrier for users seeking traditional API or web-based interactions. Additionally, Google’s Imagen 2 implements strict safety and content filters across a wide range of topics, which did limit versatility and required additional pre-processing. Such factors, alongside the technical and human-based perceptual metrics evaluated in our study, also influence the overall usability and adoption of AI image generation models in real-world scenarios.
Conclusion
Our comprehensive evaluation of leading text-to-image models, combining human preference ratings with automated metrics, reveals intriguing contrasts between quantitative performance and human perception. Stable Diffusion emerged as the overall top performer in human evaluations, excelling in detail/clarity and photorealism despite a lower technical image quality score. This underscores the complex relationship between technical metrics and human perception of quality. DALL-E demonstrated strength in prompt interpretation and adherence across both human and automated evaluations, although it showed weakness in human-perceived photorealism. Imagen 2, while scoring highest in technical image quality, consistently ranked lower in human preferences, particularly struggling with prompt alignment.
As these technologies continue to evolve, our results indicate that each model has distinct strengths and areas for improvement. Stable Diffusion offers balanced performance across various criteria, making it suitable for a wide range of applications. DALL-E excels in prompt interpretation and execution, making it ideal for tasks requiring precise visualization of detailed descriptions. Imagen 2's high technical quality suggests it could be particularly useful in applications where image fidelity is prioritized, although improvements in prompt adherence would enhance its overall performance. Future research should focus on bridging the gap between technical metrics and human perception, as well as addressing specific weaknesses identified in each model, such as DALL-E’s photorealism or Imagen 2’s prompt alignment. By refining these aspects, we can push the boundaries of AI-generated imagery and develop more versatile and capable text-to-image systems that better meet the needs of various applications and user preferences.
Get started today
The comprehensive approach to evaluating text-to-image models presented here represents a significant advance in assessing AI-generated images. When combined with Labelbox's platform, AI teams can accelerate the development and refinement of sophisticated, domain-specific image generation models with greater efficiency and quality through our dataset curation, automated evaluation techniques, and human-in-the-loop QA.
If you're interested in implementing this evaluation approach or leveraging Labelbox's tools for your own text-to-image model assessment, sign up for a free Labelbox account to try it out or contact us to learn more. We'd love to hear from you and discuss how we can support your AI evaluation needs.


