
 All guides
All guidesAutomatically label images with 99% accuracy using foundation models
Overview
In this guide, you’ll learn how to exponentially increase your labeling speed and efficiency by leveraging Labelbox and foundation models. We will be walking through a sample image classification task: figuring out if images contain cats or dogs.
Here's a high-level summary of the process that we'll be walking through step-by-step below:
- Connect your data to Labelbox with just a few lines of code.
- Labelbox leverages foundation models to magically enrich your data.
- Use the powerful search capabilities of Labelbox to quickly find data with similar traits and classify them in one click. With the help of foundation models, you can instantaneously label large amounts of data. Pro tip: Combine a variety of search techniques, such as a similarity search, natural language search, and investigate clusters of similar data, to boost your results.
- While foundation models are a helpful starting point, they might not always correctly classify data, especially on challenging or rare data points. In this case, utilize human-in-the-loop labeling and QA by pre-labeling data using foundation models and sending it for your internal or external labeling team to review.
- Automatically apply these rules to all new incoming data by creating a slice in Labelbox.
Now, let’s take a look at how we can do the above in Labelbox. As a sneak peek into the process, by leveraging foundation models, we managed to classify 86% of our images in minutes with a 99.9% accuracy rate. An additional 13.5% of our images were successfully pre-labeled using foundation models, with 98% accuracy, and were sent for human review. This left us with less than 0.5% of images to manually label – a massive efficiency gain for any labeling team.
Step 1: Connect your data to Labelbox with a few lines of code
Since this is a classification task, our goal is to correctly have the model identify cats and dogs in images. We will be using the following Hugging Face dataset - cats_vs_dogs, containing 18,699 images for our analysis.
To begin, let's connect this data to Labelbox. Simply retrieve the dataset from Hugging Face and integrate it with Labelbox in just a few lines of code.
from datasets import load_dataset
dataset = load_dataset("cats_vs_dogs",split='train')
# iterate over the data
payload_imgs = []
counter = 0
for data in dataset:
image = data['image']
label = data['labels'] # 0 is cat, 1 is dog
global_key = "cat_vs_dog_" + str(counter)
# save image locally
path = "/content/images/"+global_key+".jpg"
image.save(path)
# create payload for images
payload_imgs.append({"row_data": path, "global_key": global_key})
counter += 1
# create dataset in Labelbox
lb_dataset = client.create_dataset(name="Cat_vs_dog")
# add data in Labelbox
task = lb_dataset.create_data_rows(payload_imgs[i:i+1000]) task.wait_till_done() # async
print(task.errors) # check errors Step 2: Leverage foundation models to instantly enhance your data
Labelbox will automatically compute and store CLIP embeddings for your data. Our CLIP model leverages OpenAI and we are using this implementation available through Hugging Face.
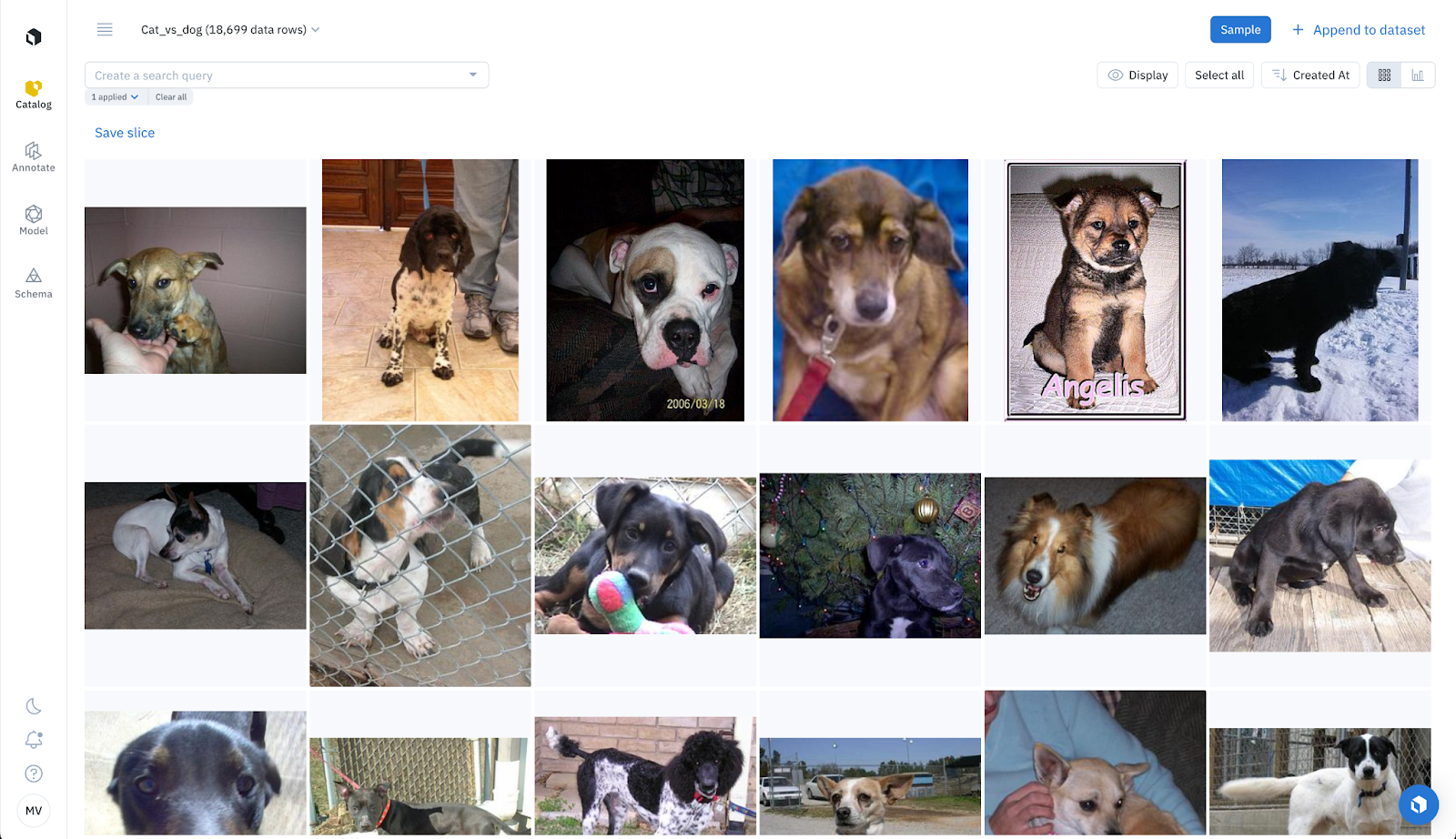
Once your data has been uploaded, you can enrich your data with foundation model embeddings. These embeddings are powerful in that they can be harnessed to automatically label, or pre-label, your data.
If you don’t want to use the default embeddings by Labelbox, you can also upload custom embeddings from any other foundation model, with up to 100 custom embeddings for each data point.
Whether you’re using the default or custom embeddings, embeddings are helpful in curating and finding subsets of data that share similar characteristics. For instance, embeddings power Labelbox’s similarity search, natural language search, and 2D projector view. You can search and explore all of your data with tools that help you powerfully surface specific subsets of data.
Step 3: Use powerful search capabilities to quickly find data
With powerful search capabilities in Labelbox, you can easily find and classify data that share similar characteristics. This is a special case of zero-shot and few-shot learning: the challenge is to find all examples of cats and dogs, based on zero (or a few) examples from each class.
With the help of foundation models, and minimal human signal, you can quickly label a lot of data in just a few clicks. The following are tools in Labelbox that help provide labeling signal to make it easy to automatically classify your data:
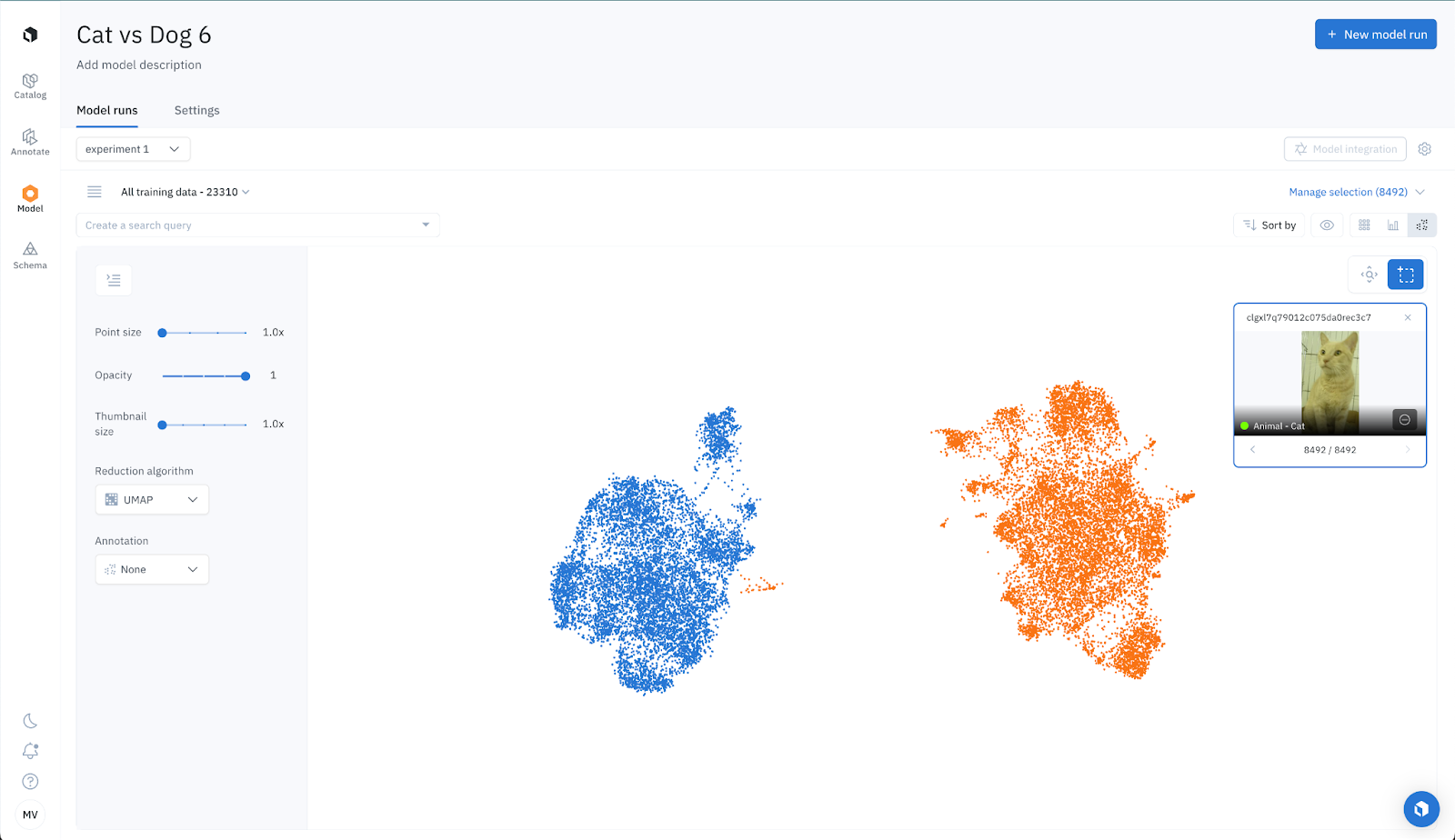
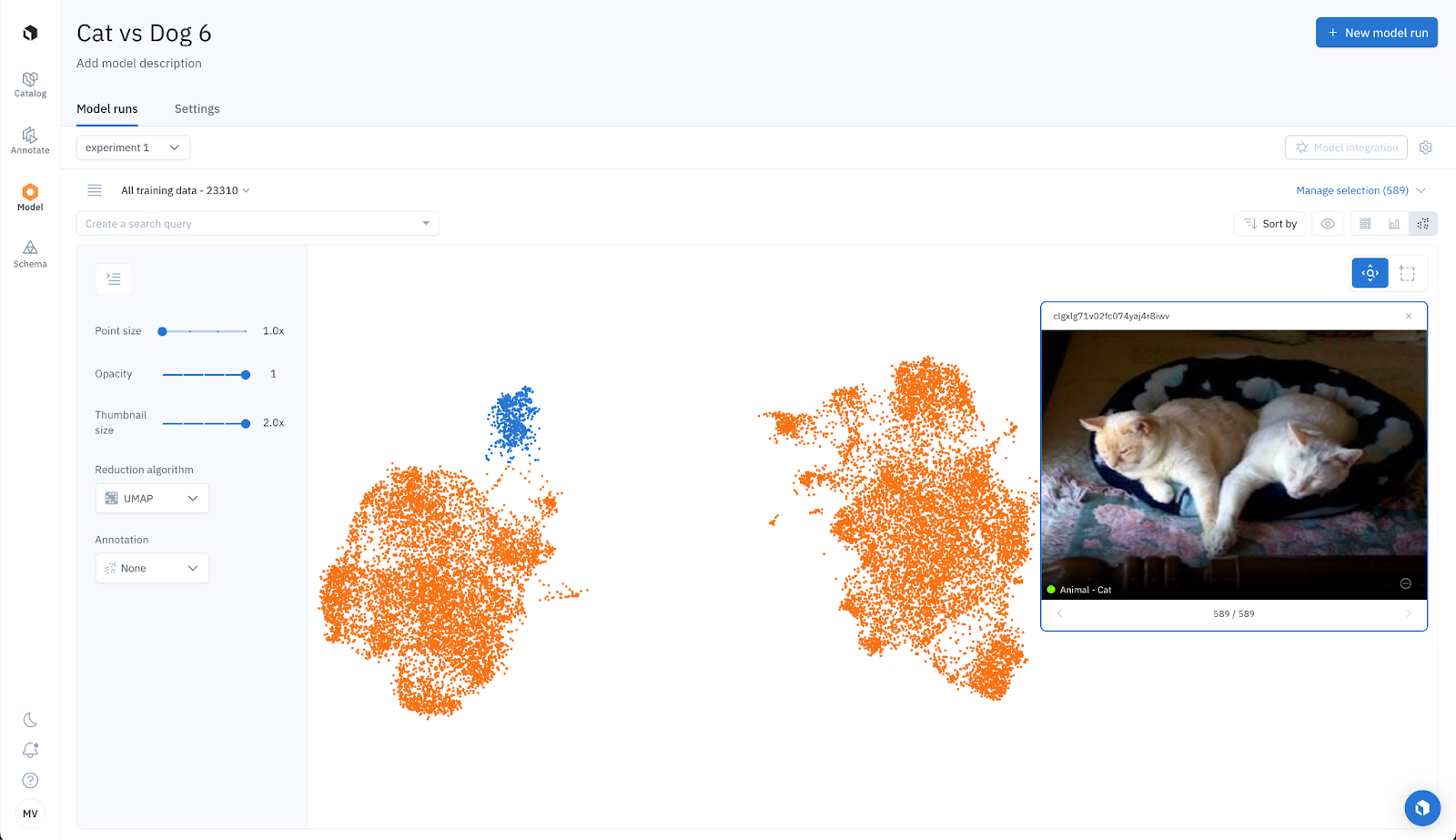
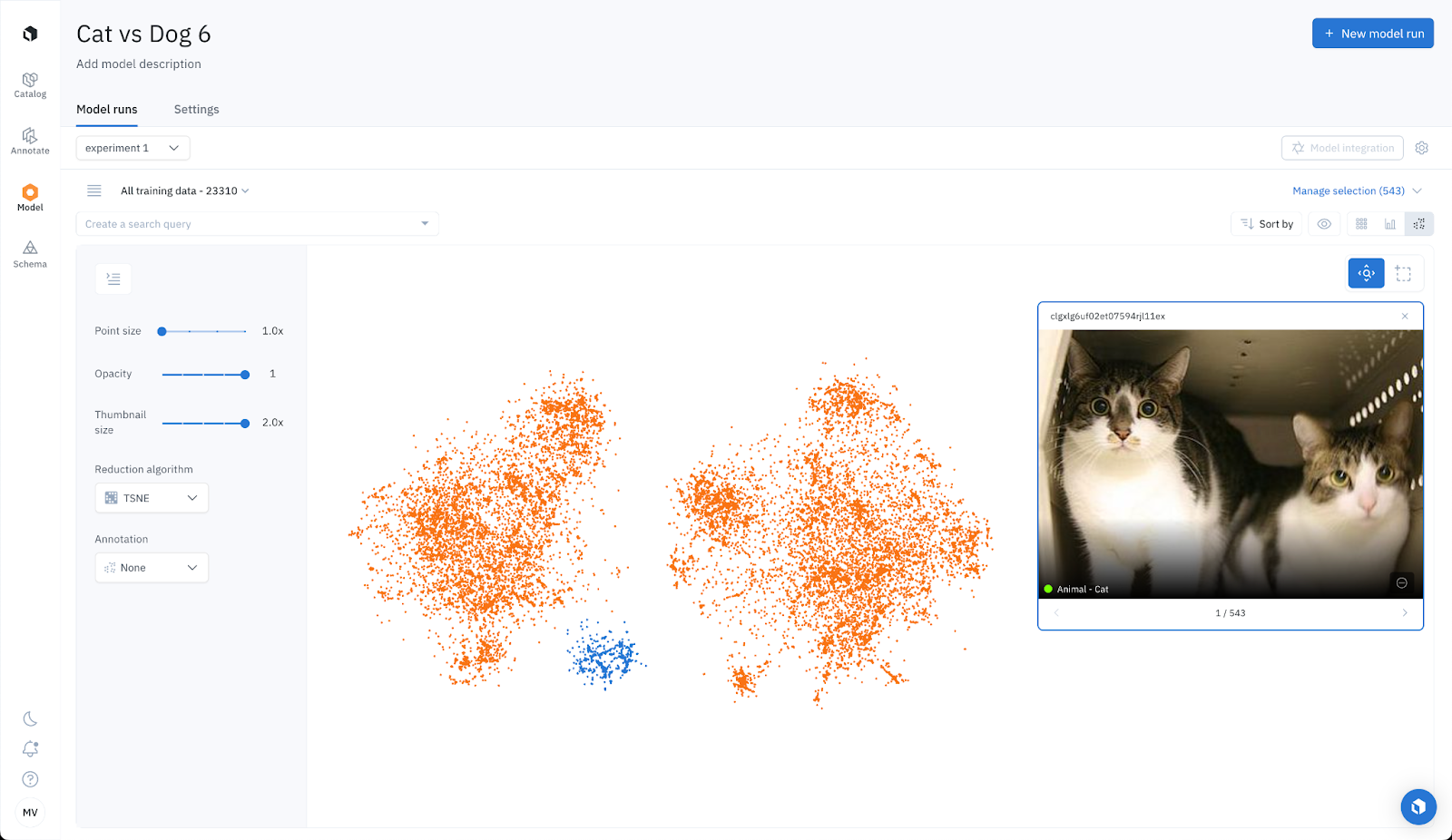
Zero-shot Labeling: Projector View for classification
Labelbox allows you to visualize data clusters in 2D. For this example, we can see two distinct clusters: one for cats and another for dogs. By inspecting a few examples, we can ensure the data clustering is accurate. We then manually select each cluster and tag it with "UMAP: cats: high confidence" and "UMAP: dogs: high confidence". We intentionally left out data points situated between clusters, as these represent challenging data points. This is expected since each labeling function won’t be perfect in isolation and some data points are difficult and challenging.
We then repeat the process with t-SNE, instead of UMAP, and tag each cluster with "t-SNE: cats: high confidence" and "t-SNE: dogs: high confidence".
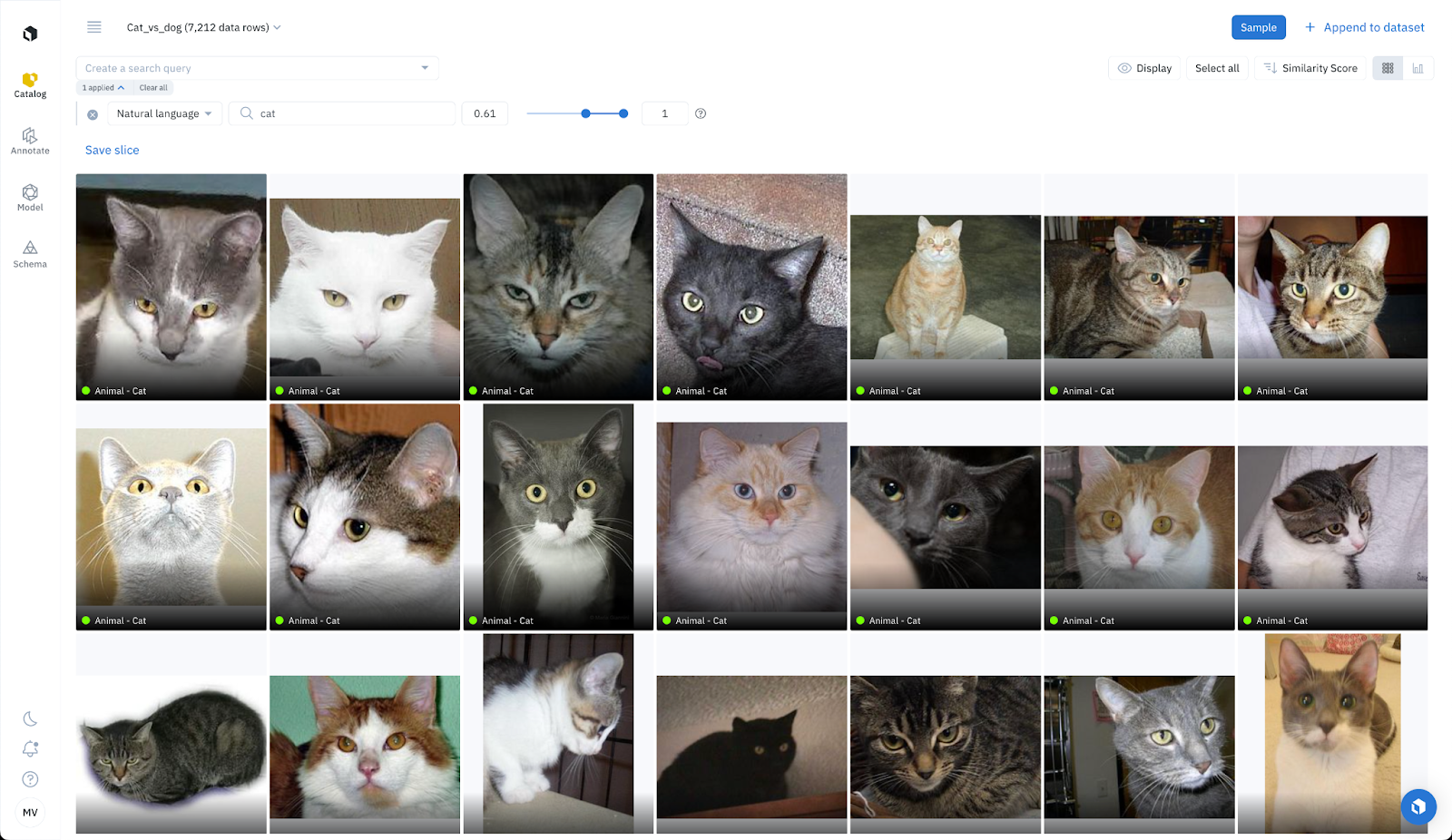
Zero-shot Labeling: Natural language search for classification
Labelbox enables you to conduct natural language searches, for example you can type in “photos of cats” to surface all cat images. Adjusting the similarity threshold will narrow the search parameters to show only the images that contain cats. For this use case, we can filter for a similarity score higher than 0.61 and tag all of the 7,125 images as “Natural language search: Cats (high confidence)”. If we adjust the similarity score to be between 0.6 and 0.61, we can tag the 1,299 images as “Natural language search: Cats (low confidence)”.
We take the same approach for images containing dogs. Using the same technique above, we tag 7,738 images of dogs as “Natural language search: Dogs (high confidence)” and surface and tag 2,750 images as “Natural language search: Dogs (low confidence)”.
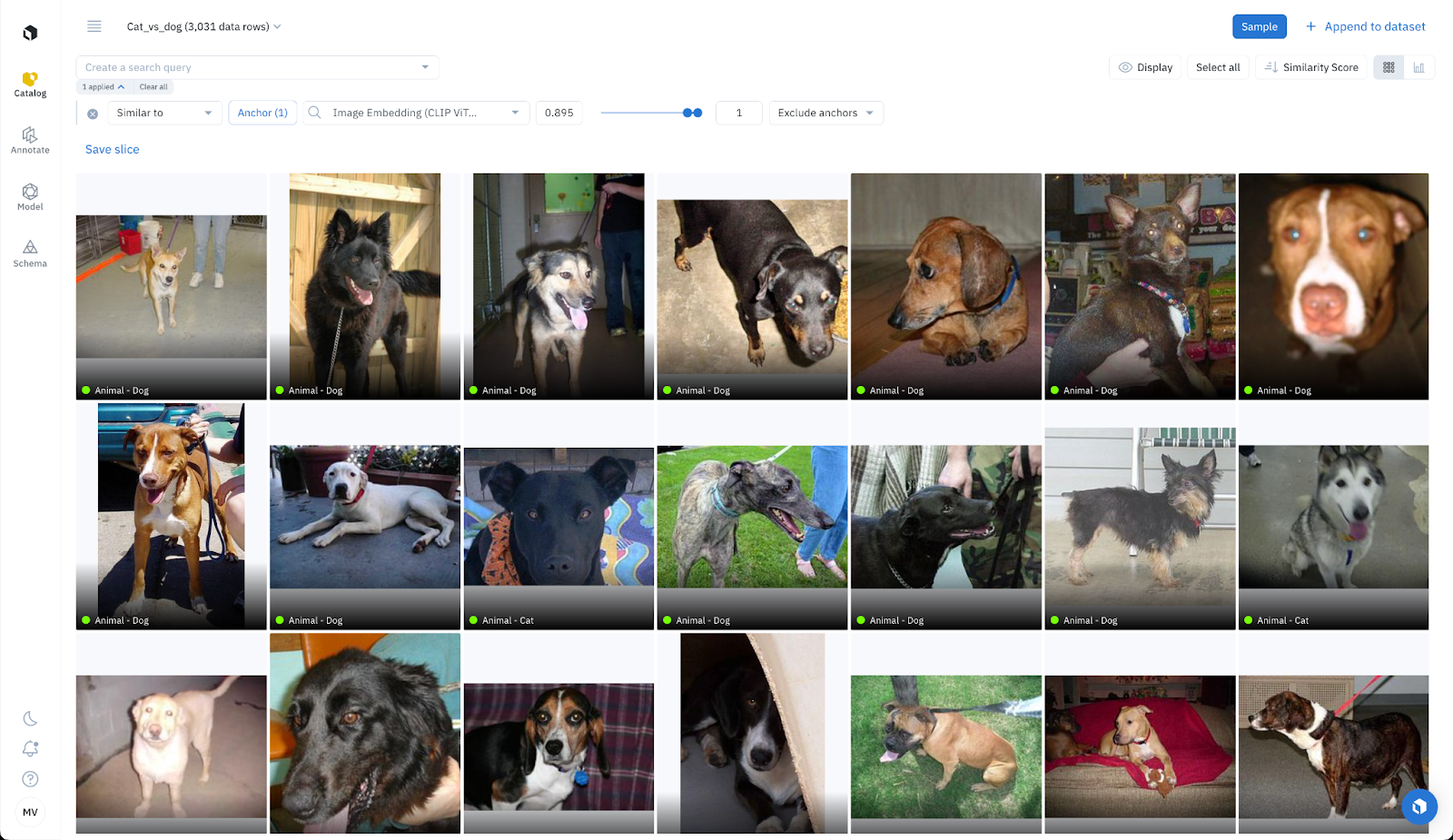
Few-shot Labeling: Similarity search for classification
Labelbox also streamlines few-shot labeling. Quickly browse all your data in Catalog to surface 5 images of cats and 5 images of dogs. Perform a similarity search in one click using these 10 images as anchors. For each anchor image, run a similarity search and tag the top results (e.g with a similarity score of higher than 0.895) as “Labeling function: similarity search (cats: high confidence)”. This provides us with 10 new labeling functions that surface images similar to the anchor images.
Weak Labeling: Combining different sources of signal
While each of these labeling signals is powerful on its own, you can combine multiple sources in Labelbox. This allows you to apply simple rules in a weak supervision fashion to further enhance your results. Integrate different labeling signals, such as similarity searches, natural language searches, and data clusters, to boost your outcomes. You can combine various filters by using the AND and OR functions.
Step 4: Automatically classify data with foundation models and use human-in-the-loop QA for challenging cases
High confidence data points: direct classification
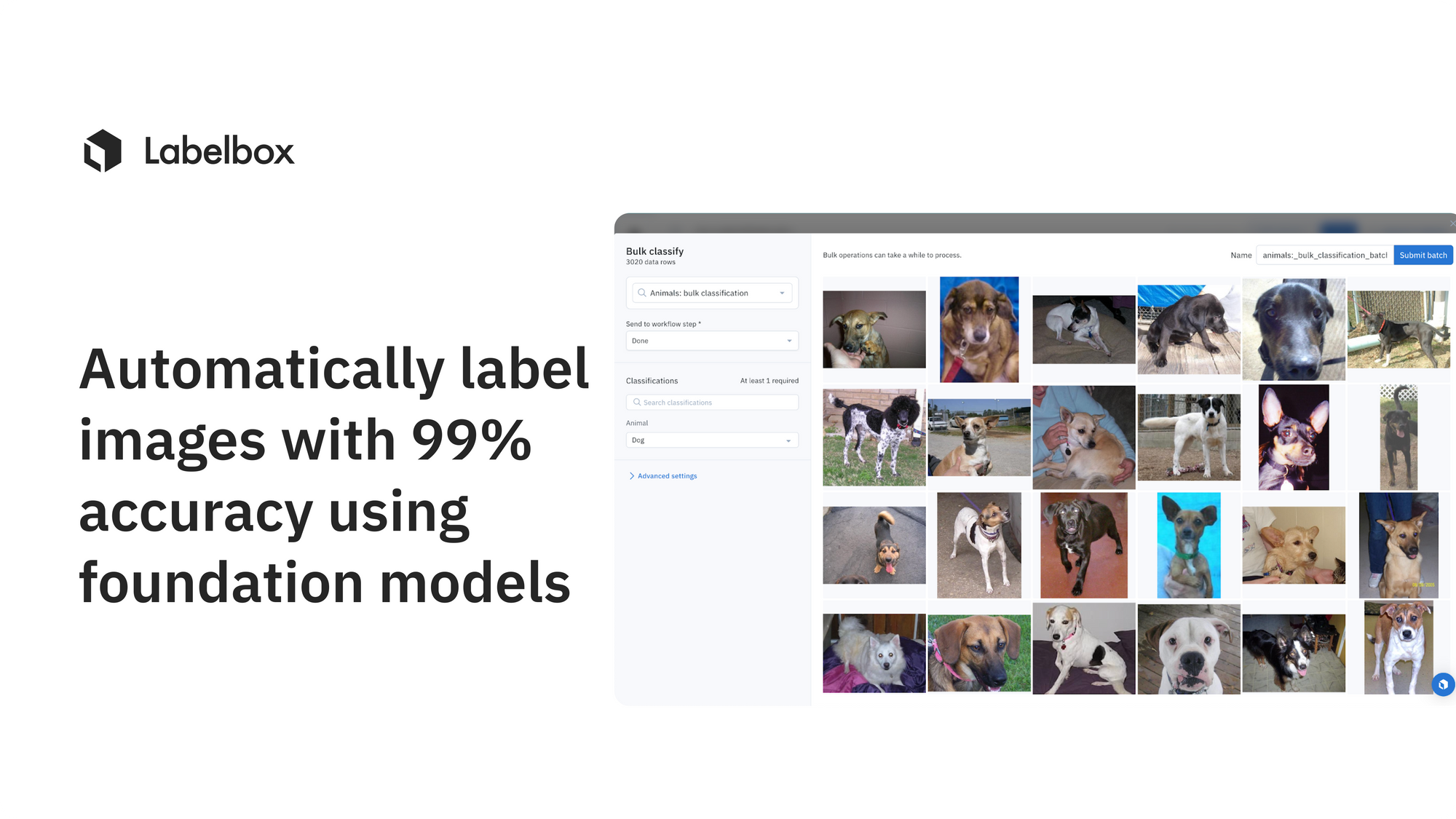
Foundation models are highly confident about most data points. So much so that we can directly classify data points leveraging Labelbox’s bulk classification feature. With this new feature, you can specify and send your data rows to a specific step of the labeling and review workflow. We can directly move these high-confidence data points straight to the “Done” task.
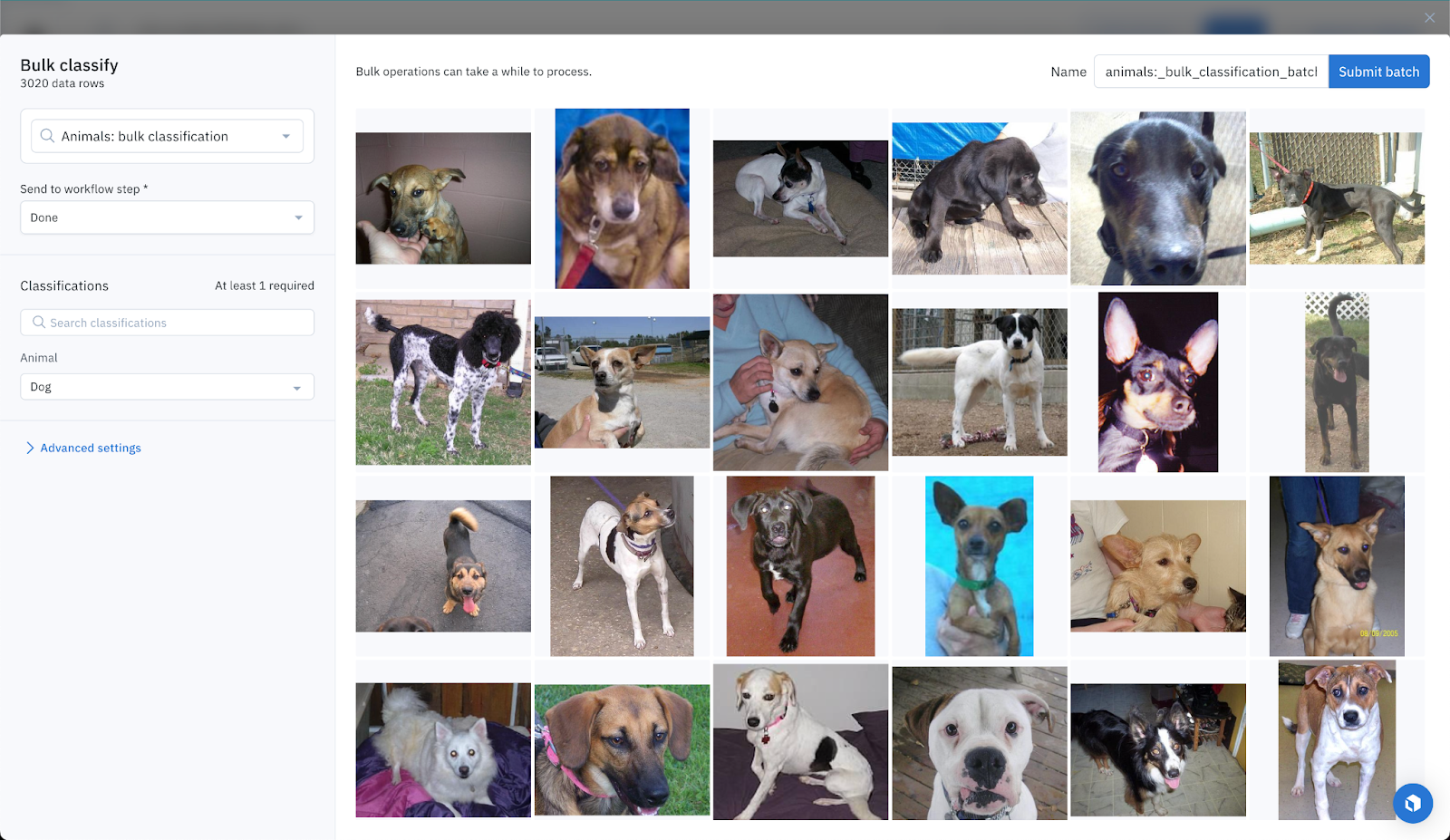
In practice, these high-confident data points are those that belong to the cat or dog cluster, both with UMAP and t-SNE, and where the natural language score is higher than 0.61. This results in 7,627 dog classifications. But just how accurate are these classification predictions?
To answer this question, we looked at the Hugging Face ground truths. On the surface, 10 out of the 7,627 dog predictions are incorrect (0.13%). However, upon closer inspection, it turns out that the Hugging Face dataset contains a few labeling mistakes and only 6 out of the 7,627 predictions (0.078%) of the foundation model’s predictions are actually incorrect. Similarly, there were 6,587 cat classifications. Only 6 out of the 6,587 cat predictions (0.09%) of the foundation model’s predictions are incorrect.

High-confident data points are also those that are found with a similarity search proximity to 2 or more anchors with a 0.895 or higher score. There were 907 dog classifications that fit this criteria, all of which were accurate except 1, and 1,022 cat classifications, all of which were accurate except 6.
By leveraging the above methods, we were able to classify 16,143 data rows - with only 19 errors - achieving an accuracy of 99.9%. Since 16,143 out of 18,699 data rows have been classified directly by foundation models, the coverage is 86%.
Now, let’s move on to classify the remaining 14% of data rows, on which the foundation model appears to be less confident.
Medium confidence data points: Human-in-the-Loop labeling
For some data points, foundation models exhibit moderate confidence. We can bulk classify these data points in Labelbox, but move them to the “To Review” task. This will ensure a human is looped in and will review the classifications coming from foundation models.
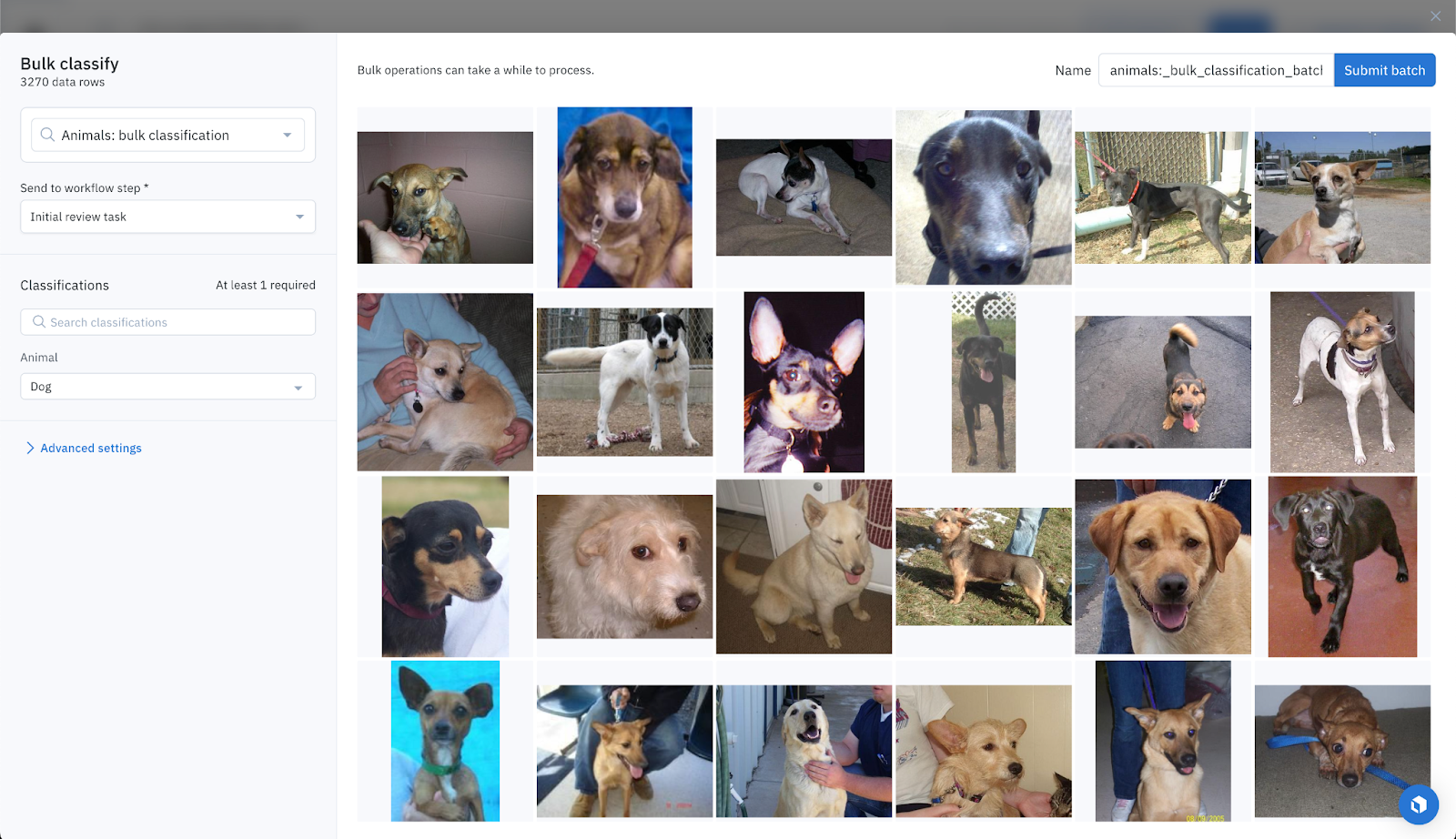
In practice, these data points are those that belong to the cat or dog cluster, with UMAP or t-SNE, and that we hadn’t classified before:
- 1,622 dogs classifications, which turn out to be all accurate except 10.
- 907 cat classifications, which turn out to be all accurate except 38.
Using this approach, we manage to classify 2,529 data rows, with an accuracy of 98% (48 errors). Good that we send them to humans for review! So far, we’ve classified all data rows except 27, so the coverage is 99.85%.
Now, let’s move on to classify the remaining 27 images.
Low confidence data points: Manual labeling
After applying these rules, 18,672 data rows out of 18,699 (99.85%) have been labeled, leaving only 27 data rows unclassified. Foundation models lack the confidence to label these remaining data points.
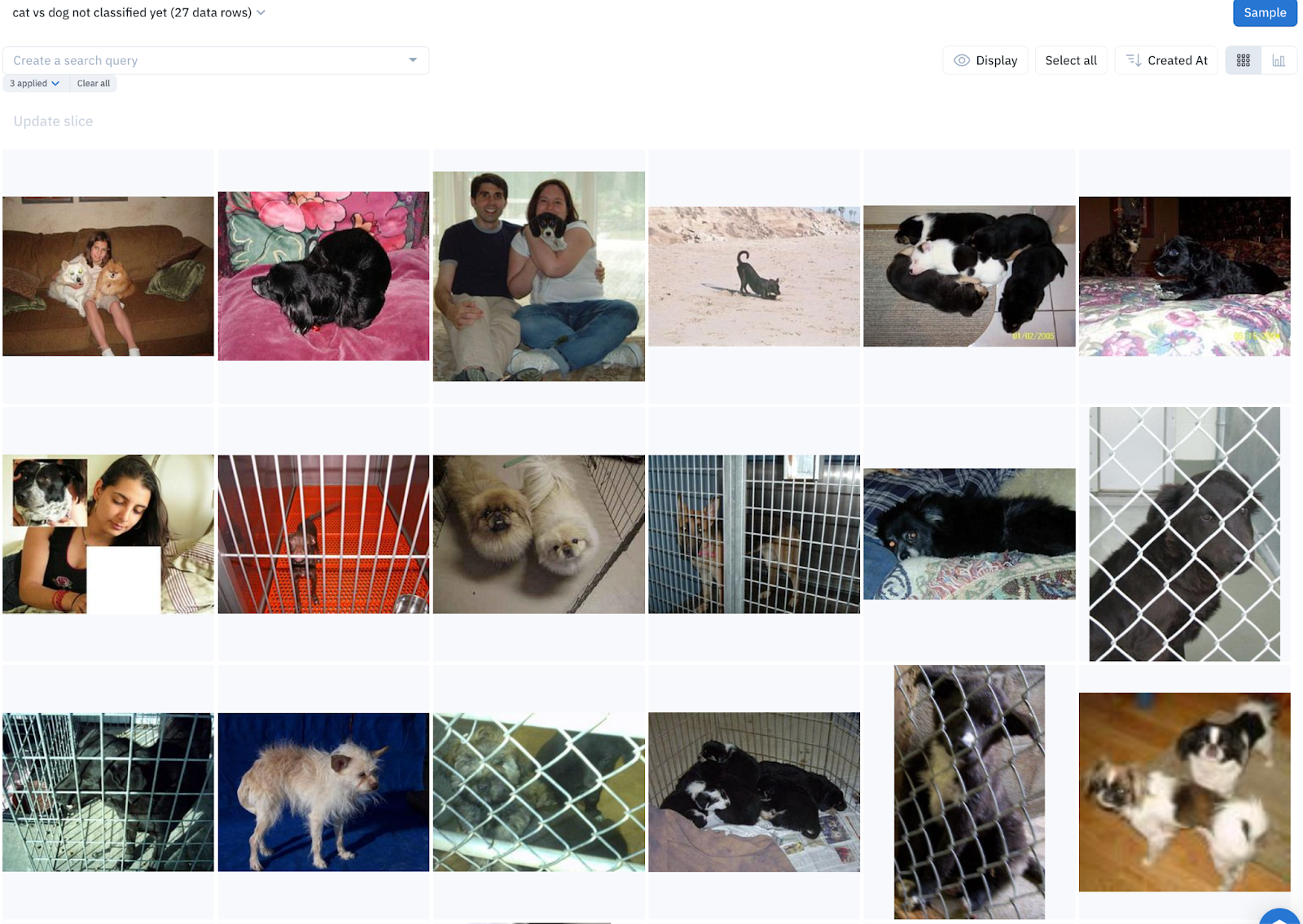
These 27 data points will require manual labeling by humans, which represents only 0.14% of data rows - a massive efficiency gain in labeling effort and speed!
Results
With powerful search capabilities and the bulk classification feature, we managed to classify 16,143 images (86%) in minutes, with 99.9% accuracy thanks to foundation models. An additional 2,529 data points (13.5%) have been pre-labeled with foundation models, with 98% accuracy, and sent for human review. This leaves with only 27 very challenging images to label manually!
Step 5: Set it and forget it – automatically apply these rules to fresh, incoming data
With Labelbox slices, we can automatically classify fresh, incoming data as cats or dogs.
For example, we can set up a slice that automatically surfaces all new images that have been connected to Labelbox in the past week, that haven’t been classified yet. We can set the slice’s criteria to include only images where the natural language search for the prompt “photo of a cat” is higher than 0.61 (since we know that these images are very likely to contain cats).
With slices, you can easily surface and inspect any new and high-impact data that gets added to your data lake.
From there, it only takes one click to classify all of these images as cats.
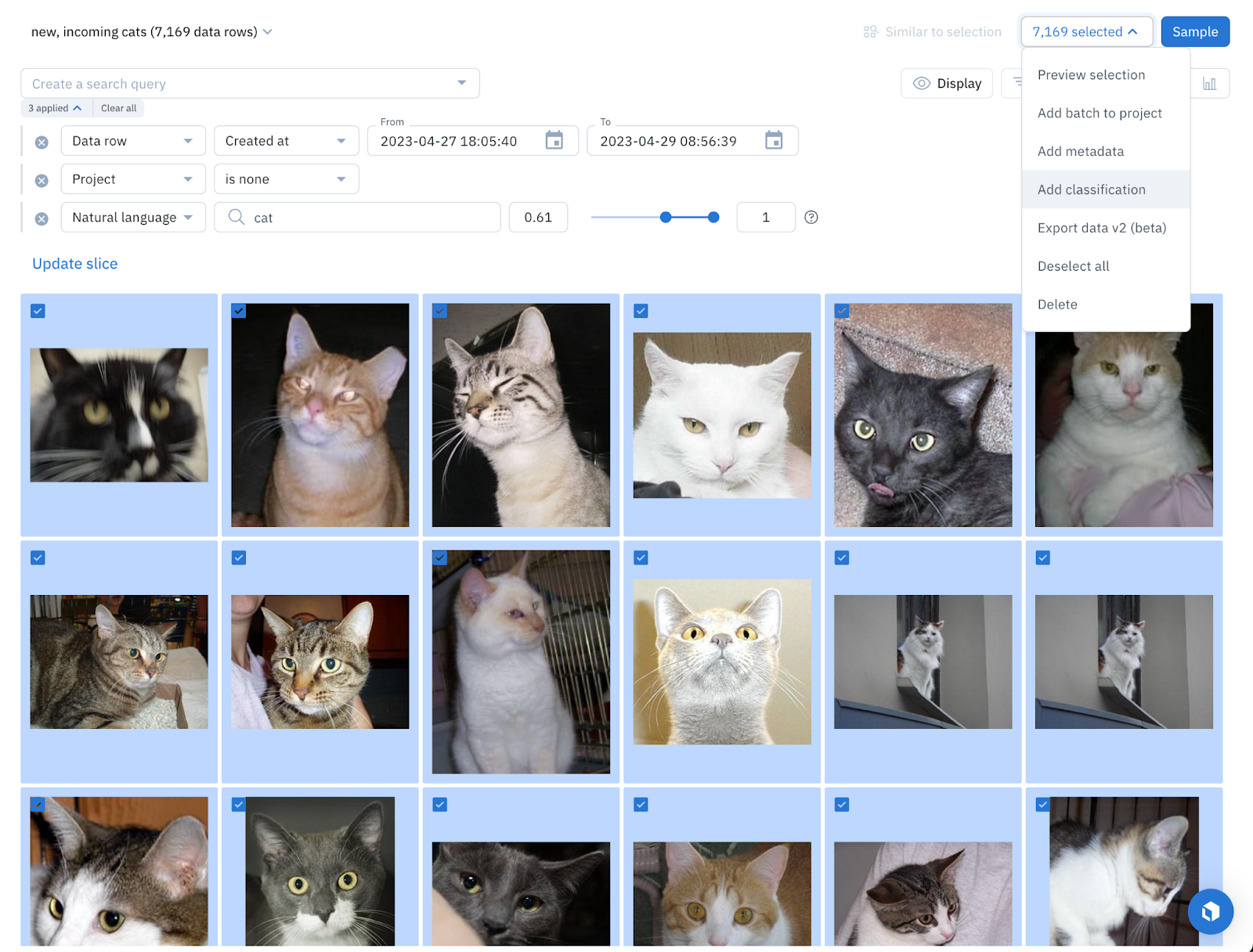
You can learn more about how to bulk classify data in our documentation or in our recent blog post.
Conclusion
With powerful search capabilities, the bulk classification feature, and foundation models, we managed to classify 16,143 images (86%) in minutes, with 99.9% accuracy. An additional 2,529 data points (13.5%) have been pre-labeled with 98% accuracy and sent for human review. This only left us with 27 very challenging images that we needed to label manually.
If you’re a current Labelbox user who wants to leverage any foundation model to supercharge your data labeling process in just a few clicks, try our bulk classification feature today or get started with a free Labelbox account.


