
 All guides
All guidesHow to build a powerful product recommendation system for retail

Personalized experiences are at the heart of customer satisfaction and are key to long-term brand loyalty and success. Amidst the abundance of choices available to the modern consumer, businesses must find innovative ways to stand out and forge meaningful relationships with their audience.
The rise of AI has enabled companies to craft personalized experiences at an unprecedented scale. Organizations can now rely on algorithms taught to recognize customer preferences, behavior, and provide recommendations based on purchase history, and more. With a powerful product recommendation system, retailers can create individualized customer interactions and foster stronger connections to boost customer loyalty and increase key metrics such as conversion rate, average order value, and repeat purchase rates.
However, building a robust and effective AI-powered product recommendation system can be challenging for many teams. Some key challenges include:
- Data quality and quantity: Building a strong recommendation system that makes accurate predictions requires a vast amount of high-quality data. Orchestrating data from various sources can not only be challenging to maintain, but even more difficult to sort, analyze, and enrich with quality insights.
- Scalability: As a business grows and their product catalog expands, the recommendation system should be able to handle new and incoming data. Ensuring scalability and maintaining model performance with new data can be particularly challenging for teams relying on in-house solutions or disparate ML tools.
- Privacy and Security: When it comes to customer data and specific product information, ensuring user privacy and safeguarding against potential security violations is critical to maintain trust with customers and build a successful recommendation system.
Labelbox is a data-centric AI platform to help build the best personalized product recommendation engine. Rather than spending valuable time building in-house or relying on disparate systems and applications, teams can leverage Labelbox’s platform to seamlessly build an end-to-end workflow that integrates with your existing tech stack and helps teams build AI systems faster.
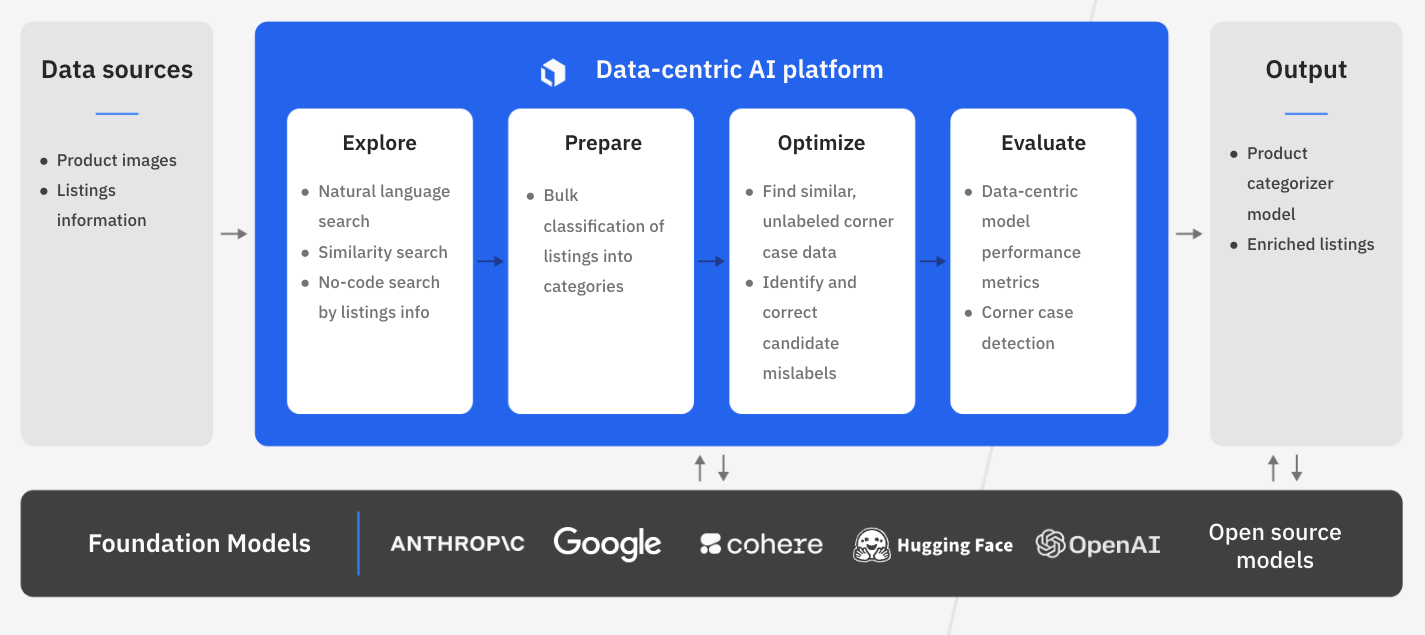
In this guide, we’ll walk through how your team can leverage Labelbox’s platform to build a powerful recommendation system, ensuring your customers embark on a seamless and delightful shopping journey that keeps them coming back for more.
See it in action: How to build a powerful product recommendation system in Labelbox
The walkthrough below covers Labelbox’s platform across Catalog, Annotate, and Model. We recommend that you create a Labelbox account to best follow along with this tutorial.
Part 1: Explore and enhance your data (Google Colab Notebook)
Part 2: Prepare data and evaluate model performance: (Google Colab Notebook)
Part 1: Explore and prepare your data
Follow along with the tutorial and walkthrough in this Colab Notebook. If you are following along, please make a copy of the notebook.
Painlessly consolidate all your product data
Building a recommendation engine requires consolidating data of different types from various sources. Such data can include product, business, and customer information that might be siloed or stored in different databases. To holistically browse and visualize your entire product catalog, leverage Labelbox Catalog to bring and view all of your data in a single place.
Ingest data into Labelbox
For this tutorial, we’ve provided a sample retail dataset for you to view in your Labelbox app:
1) Input your Labelbox API key into the provided Google Colab notebook.
2) Specify an amount of data that you wish to ingest — we’ve provided up to 44,000 data rows for ingestion, but keep in mind that this will accrue LBUs in your account. If you are using Labelbox for free, we suggest that you ingest around 5,000 data rows.
3) Select ‘Runtime’ in the navigation bar and hit ‘Run all’ to bring the selected amount of data rows into your Labelbox Catalog — where you can browse, explore, and curate the data for insights and model development.
Accelerate product discovery across your entire catalog
An effective product recommendation relies on training a model with a thorough understanding of your product data, encompassing product tags, categories, and more. However, retailers often have an ever-growing product list with hundreds or thousands of products. Dealing with this volume of data at scale and effectively searching, organizing, and managing data for machine learning tasks can be a challenge.
You can leverage Labelbox Catalog to visualize, browse, and curate your product listings.
Search and curate data
You’ll now be able to see the sample retail dataset in your Labelbox Catalog. Try searching across key product-specific metadata such as category, the year the item was released, season, gender, and more. With Catalog, you can contextualize your data with custom metadata and attachments to each asset for greater context.
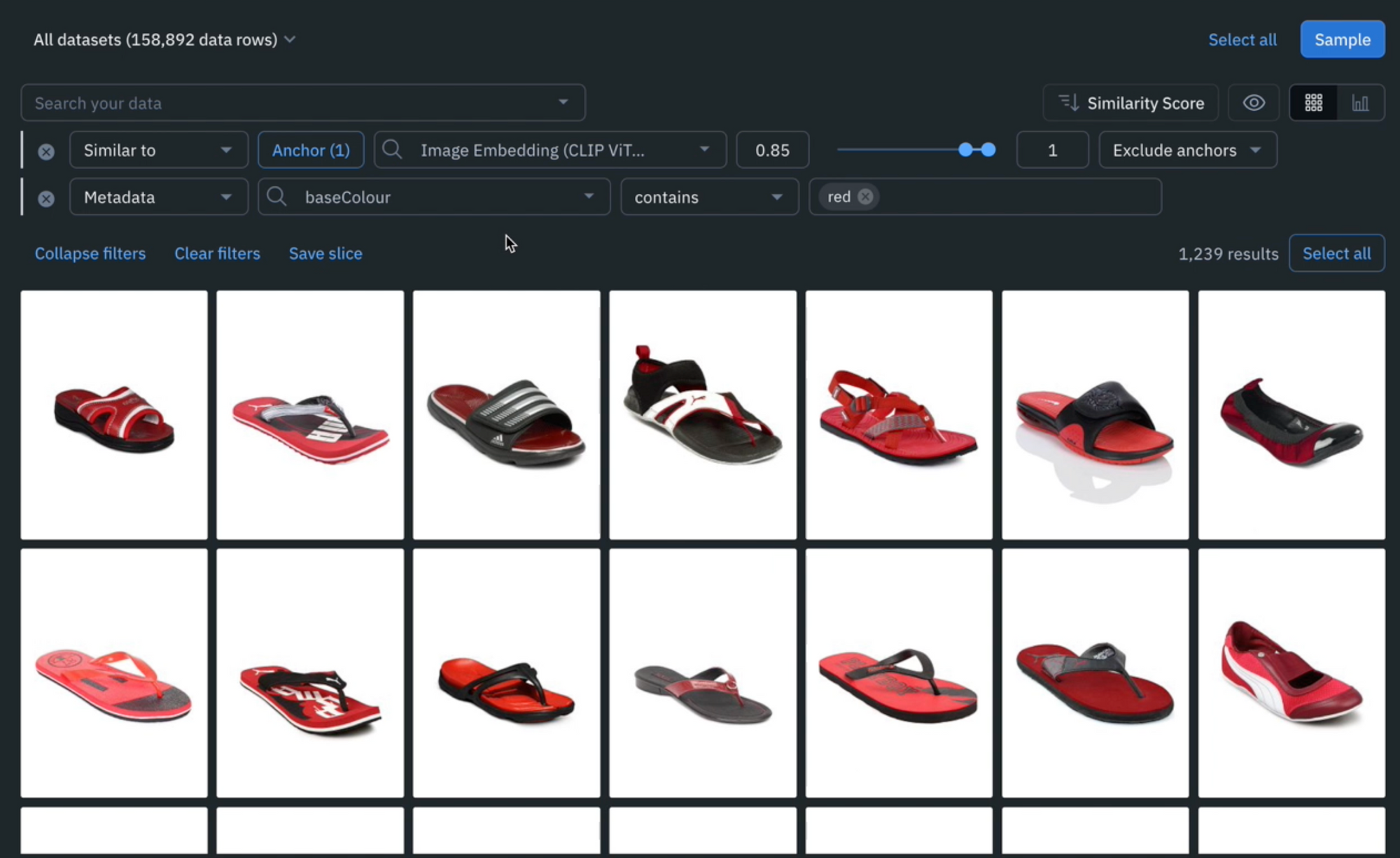
Leverage custom and out-of-the-box smart filters and embeddings to quickly explore product listings, surface similar data, and optimize data curation for ML. You can:
- Search across datasets to narrow in on data containing specific attributes (e.g metadata, media attributes, datasets, project, etc.)
- Automatically find similar data in seconds with off-the-shelf embeddings
- Filter data based on natural language and flexibly layer structured and unstructured filters for more granular data curation
Categorize and curate product listings faster
Advanced ML teams often adopt partially automated labeling workflows to mitigate costs and accelerate model development. Product recommendation models require a vast amount of accurately labeled data with a wide array of features. Manually labeling this data can not only be time consuming, but can also get exponentially expensive. Scaling data curation and enrichment effectively is key to quickly creating a powerful ML solution.
One simple way to achieve this is by leveraging bulk classification and using human-in-the-loop review for quality assurance. Some AI teams using this technique have cut labeling costs by nearly 90%.
Streamline labeling automation through bulk classification
Create a new labeling project
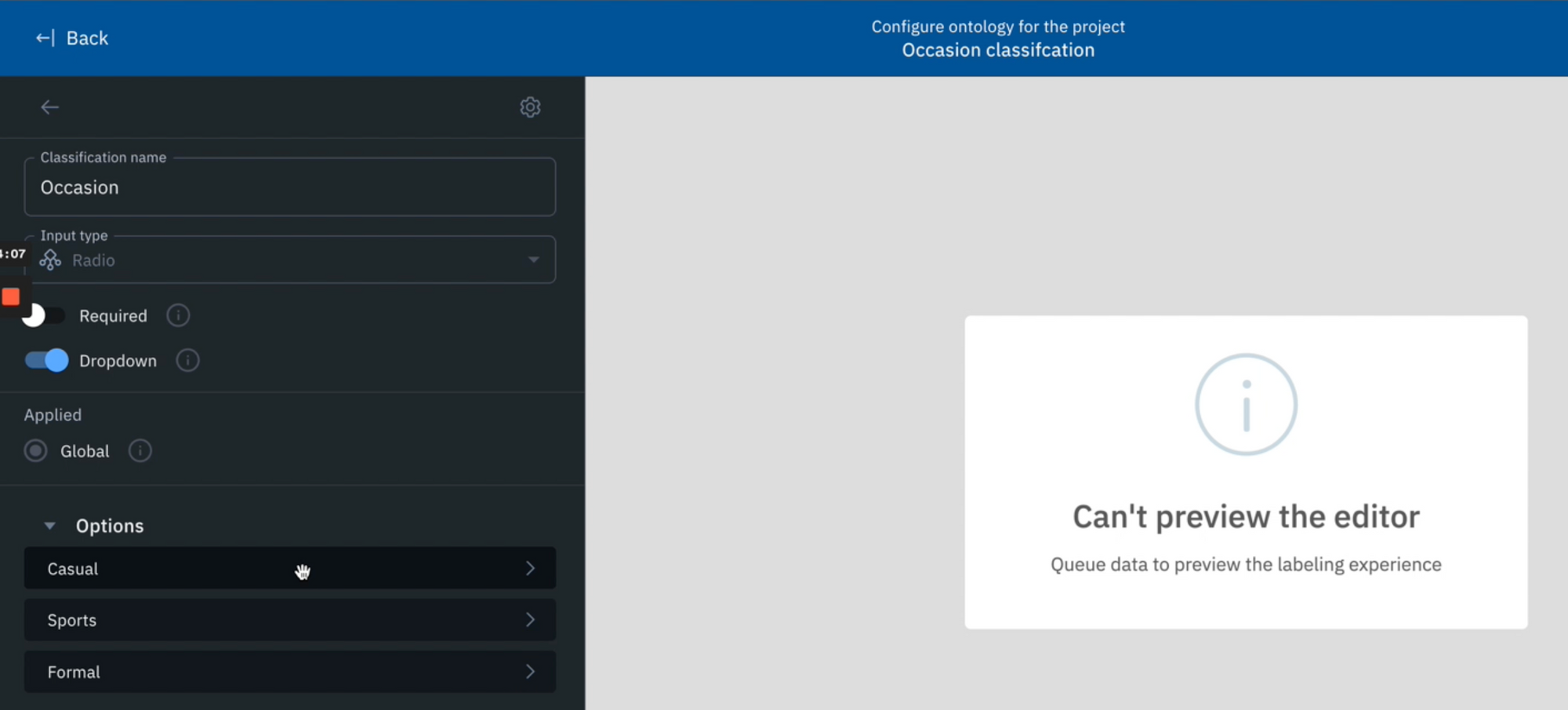
Once you’ve narrowed in on a specific slice of data that you’d like to take action on, you can send them to a labeling project of interest in just a few clicks.
1) Create a new image project in Annotate.
2) Configure the editor and create a new ontology. For the ontology, create a new classification called ‘Occasions’ with options such as ‘Casual’, ‘Sports’, ‘Formal’, etc. feel free to add any other classifications of interest.
3) Save your labeling project.
Send a subset of data to the labeling project
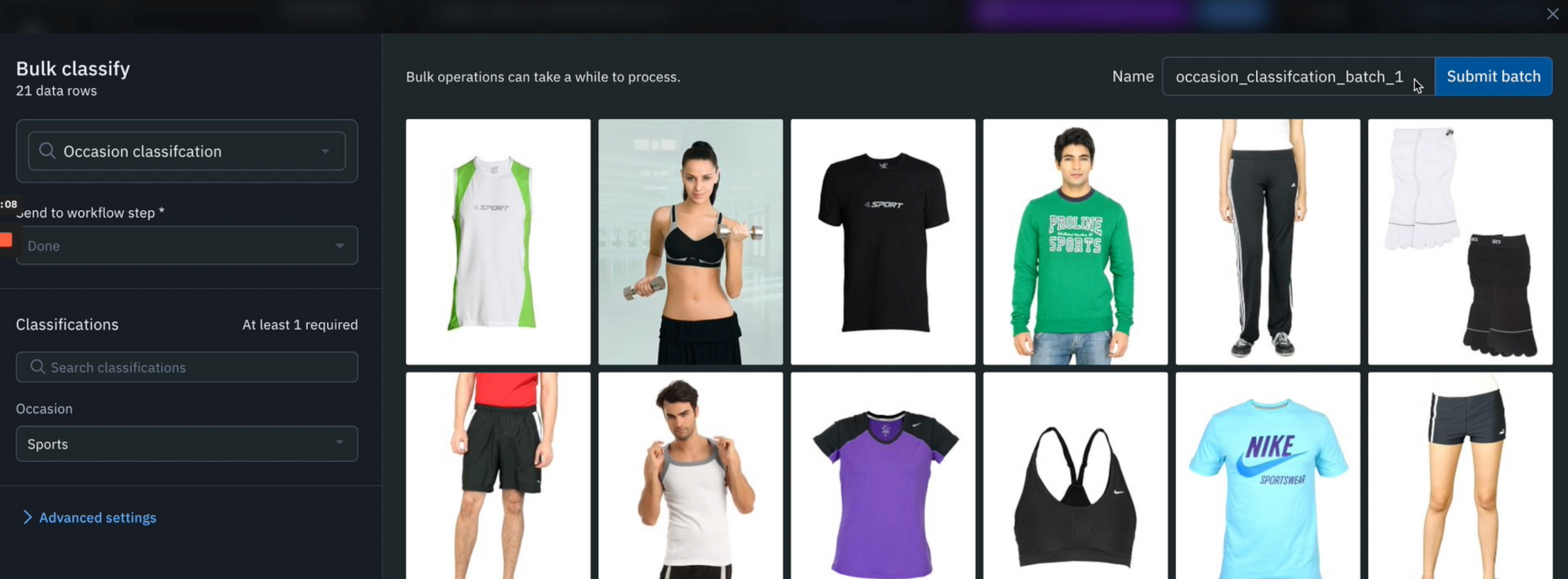
Return to Catalog and surface a specific subset of data that you want to bulk classify. For example, you can surface all instances of ‘Sporty apparel’ clothing with a natural language search.
1) Highlight any data rows of interest and select ‘Manage selection’ > ‘Add classifications’.
2) Select the labeling project that you made in the previous step and determine a step of the project’s review workflow that you would like to send the classifications to. In the above demo, we are sending these to the ‘Done’ stage because we have verified that these images fall under the ‘Sports’ category and want to automatically create ground truth labels.
3) Pick ‘Sports’ under the Classification section and you can submit the classification batch.
Save high-impact searches
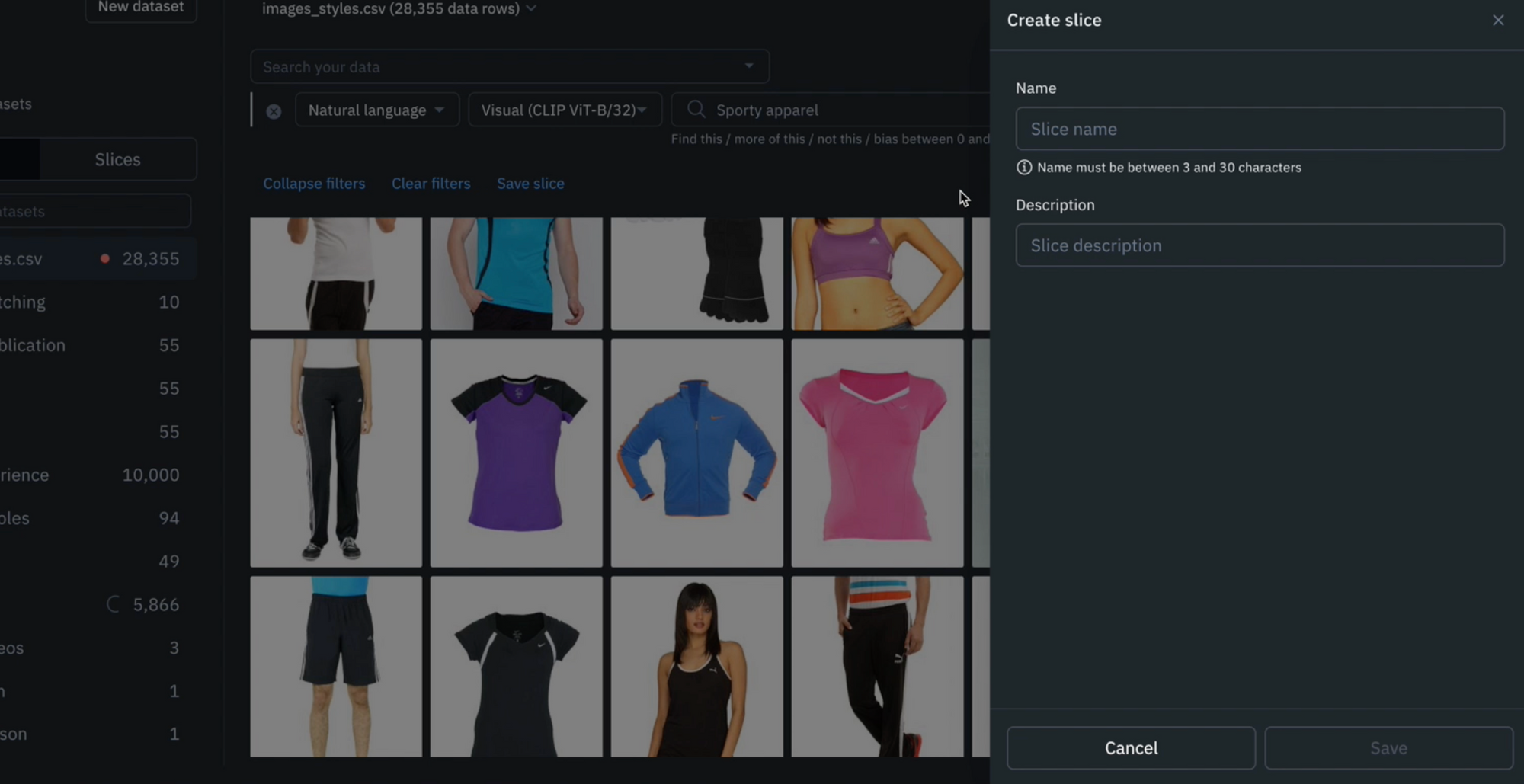
You can save any combination of searches as a slice in Catalog. For example, saving the natural language search of ‘Sporty apparel’ as a slice called ‘Sporty apparel’, creates a dynamic slice of data that can easily be revisited or edited as project needs evolve. Any future data that gets uploaded to Labelbox will automatically populate in any relevant slices based on its filters, creating an automatic data curation pipeline as your product catalog grows.
Part 2: Prepare data and evaluate model performance
Follow along with the below with the tutorial and walkthrough in this Colab Notebook. If you are following along, please make a copy of the notebook.
Prepare a training dataset for model diagnosis
Model diagnosis can play a pivotal role when training a model for personalized shopping experiences. The success of personalized recommendation systems hinge on the accuracy of a model’s understanding of a retailer’s product catalog or individual customer preferences. A properly curated and organized training dataset serves as the foundation for accurate model performance evaluation and fine-tuning.
Send the curated training dataset from Labelbox Annotate to Model in a few clicks to efficiently diagnose model performance of the training dataset.
Curate a training dataset for evaluation
Creating a new model
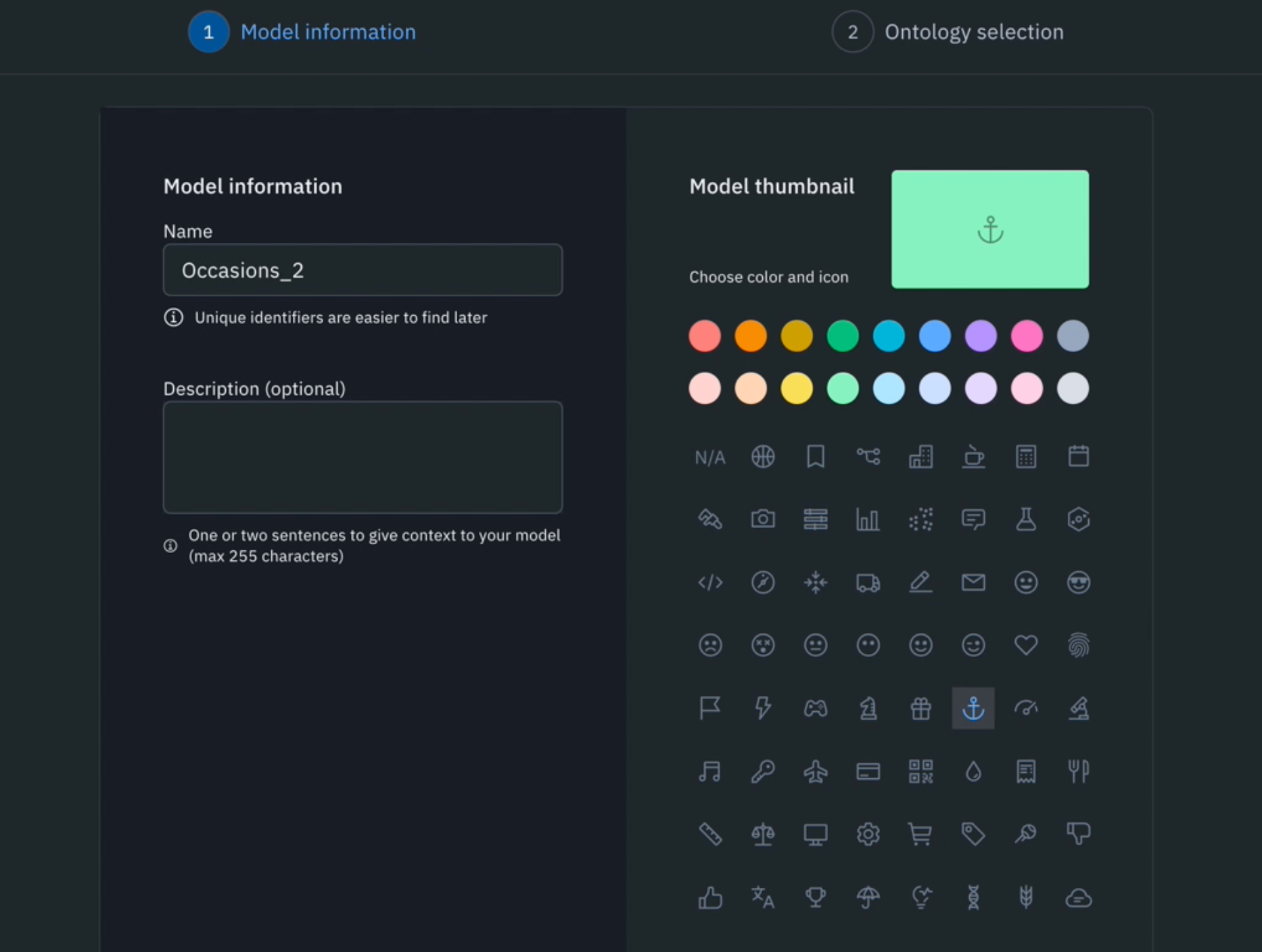
1) Navigate to the Model tab, select ‘Experiments’, and create a new model.
2) Name your model (e.g ‘Occasions’) and select a model thumbnail.
3) Select the same ontology that was used to bulk classify the data rows in the previous step.
4) Select the project that the classifications were sent to in the previous step. After selecting both the correct ontology and project, you should see the number of data rows that were bulk classified and ready to be added to the new model.
5) Hit ‘Create model’.
Creating a new model run
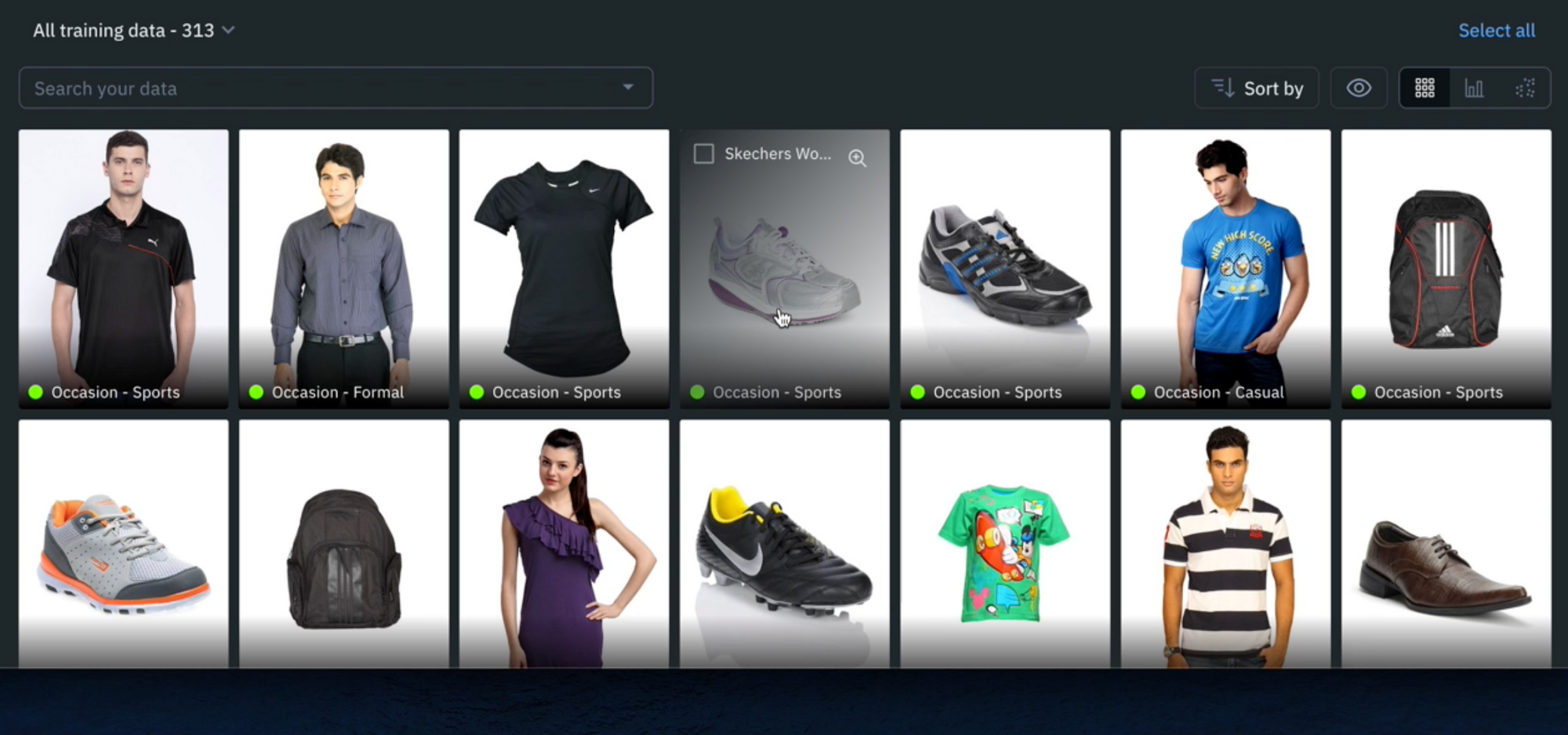
1) Once you’ve created your model, you can navigate back to the ‘Experiments’ tab and find the newly created model.
2) Create a ‘new model run.’ A model run is a model training experiment within a model, providing a versioned data snapshot of all data rows, annotations, and data splits for that model run.
3) To create a model run, you’ll need to give it a name (e.g ‘dataset version 1’) and can adjust the balance of the data split. For this demo, we will leave them in the default setting (80% train, 10% validate, 10% test).
4) After creating the model run, you’ll be able to see the populated training data classifications.
Train a model on a provided training dataset
Model training occurs outside of Labelbox. Labelbox Model works with any model training and inference framework, major cloud providers (AWS, Azure, GCS), and any data lake (Databricks, Snowflake).
We’ll be using the Colab notebook to train a model on the training dataset and bring back inferences from the trained model for evaluation and diagnosis.
For this step, you will need:
- Your Ontology ID — found in the Settings tab on the model run page
- Your Model Run ID — found in the gear icon on the top-right of the model run page
- Your API key
1) Enter your API key, Ontology ID, and Model Run ID in the Colab Notebook.
2) Once those are inputted, you can select ‘Runtime’ in the navigation bar and hit ‘Run all’ – this will take the classifications from your model run and train a provided image classification model. After training, the notebook will also take the trained model and use it to run inference on the data.
3) If you want to adjust your data splits, you can leverage search filters in Model to surface any data rows and move them to the train, test, and validation splits.
Evaluate and diagnose model effectiveness for retail
A well-performing model can accurately predict consumer behavior or recommend products based on past preferences. Effective model diagnosis helps fine-tune recommendation algorithms, resulting in more accurate and appealing product suggestions.
Model diagnosis and evaluation are not one-time tasks. By leveraging effective diagnostic tools and an active learning workflow, retailers can continuously identify areas of improvement and adapt to changing customer behavior or an evolving product catalog. This iterative approach keeps personalized experiences relevant and effective for driving business outcomes over time.
Diagnose model performance with model metrics
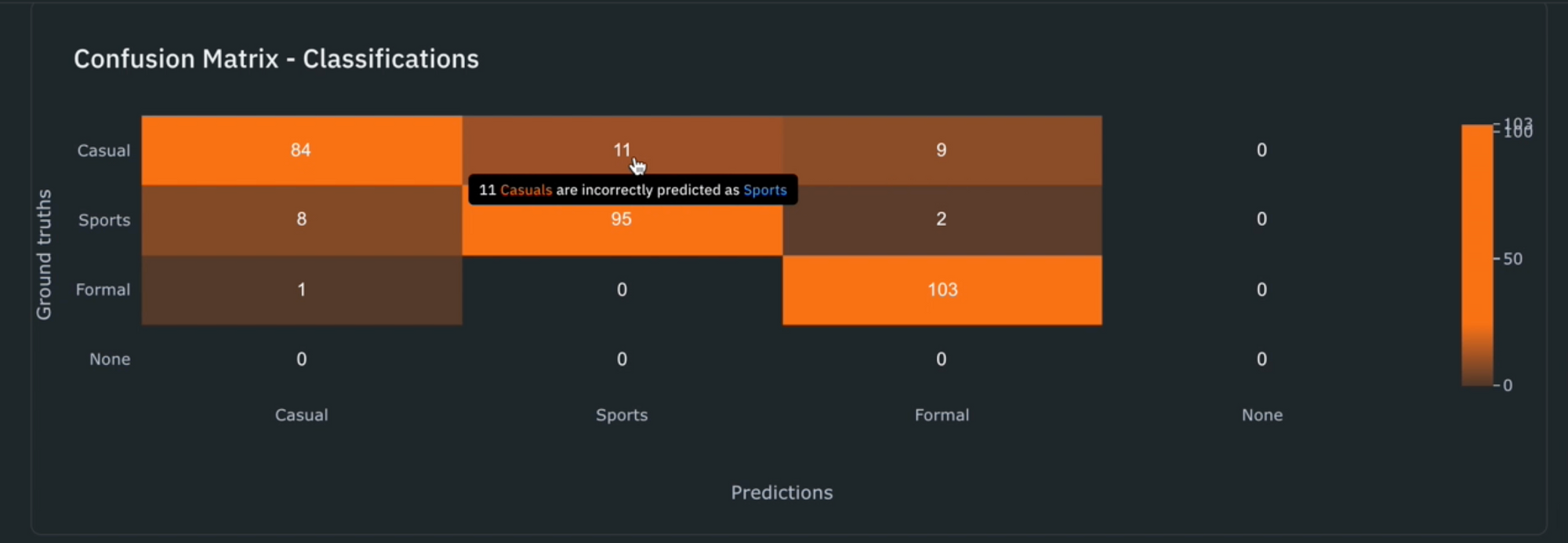
1) After running the notebook, you’ll be able to visually compare ground truth labels (in green) to the model predictions (in red).
2) Use the ‘Metrics view’ to drill into crucial model metrics, such as confusion matrix, precision, recall, F1 score, and more, to surface model errors.
3) Model metrics are auto-populated and interactive. You can click on any chart or metric to open up the gallery view of the model run and see corresponding examples.
4) Detect and visualize corner-cases where the model is underperforming. For example, in the demo above, we notice that the model is classifying this type of white shoe as a ‘Sports’ shoe when in fact it is a ‘Casual’ shoe.
After running error analysis, you can make more informed decisions on how to iterate and improve your model’s performance with corrective action or targeted data selection.
Curate high-impact data to drastically improve model performance
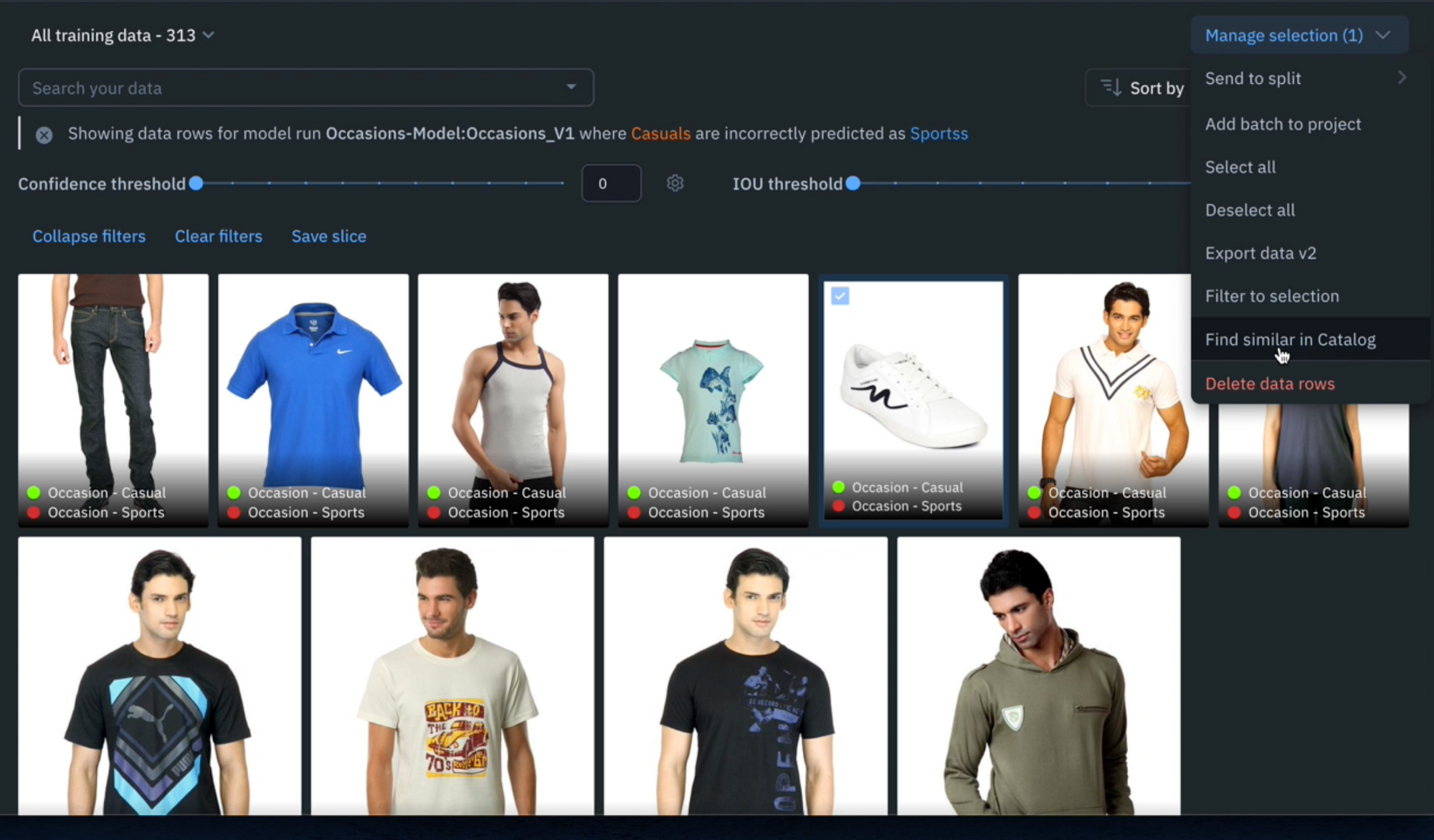
1) Select any corner-cases and select ‘Find similar in Catalog’ from the Manage Selection dropdown. This will bring you back into Catalog and will automatically surface all similar data rows to the selected example.
2) In addition to the similarity search, you can filter on ‘Annotation’ > ‘is none’ to surface only unlabeled data rows that you can retrain the model on to boost model performance.
3) Select any relevant examples and ‘Manage selection’ > ‘Add classifications’. In this case, we’d want to bulk classify these examples to reinforce to the model that these images are ‘casual’ shoes.
4) This step is similar to the bulk classification step in part 1. Select the labeling project that you made in the previous step and determine a step of the project’s review workflow that you would like to send the classifications to. We can send these to the ‘Done’ stage because we want to tell the model these white shoes fall under the ‘Casual’ category and want to automatically create ground truth labels.
5) Create a new model run (within the same model) and have the newly added classifications as a part of the training dataset.
6) Run the notebook again to train the model on this new training dataset and evaluate model performance with model metrics. You can compare results from the initial model run with the new model run to evaluate how the adjustment influenced model performance.
As consumer businesses strive to distinguish themselves in a competitive market, the power of AI-driven product recommendation systems cannot be underestimated. Companies can tap into their vast data stores and harness the capabilities of advanced algorithms to forge deeper connections with their customers.
Labelbox is a data-centric AI platform that empowers teams to iteratively build powerful product recommendation engines to fuel lasting customer relationships. To get started, sign up for a free Labelbox account or request a demo.


