
 All guides
All guidesHow to build defect detection models to automate visual quality inspection

With AI-powered defect detection, you can now easily harness the latest advances in automation and computer vision into your quality inspection models. As the demand for defect-free manufacturing continues to rise, it's important for teams to deliver the highest-quality products for their assembly lines and minimize operational and quality-related costs. Labelbox empowers the world’s largest manufacturers to leverage AI solutions tailored to their unique defect detection challenges in order to more quickly build intelligent applications.
However, teams can face multiple challenges when implementing AI for large-scale defect detection for manufacturing use cases. This includes:
- Data quality and quantity: Improving defect detection requires a vast amount of data in the form of images and videos. Orchestrating data from various sources can not only be challenging to maintain, but even more difficult to sort, analyze, and enrich with quality insights.
- Dynamic review landscape: The changing nature and format data from multiple sources poses the challenge for businesses to account for continuous data updates and re-training needs.
- Cost & scalability: Developing accurate custom AI can be expensive in data, tools, and expertise. Leveraging foundation models, with human-in-the-loop verification and active learning, can help accelerate model development by automating the labeling process.
Labelbox is a data-centric AI platform that empowers businesses to automate their visual inspection through advanced computer vision techniques. Instead of relying on time-consuming manual human review, companies can now leverage AI-assisted data enrichment and flexible training frameworks to quickly build task-specific models that uncover actionable insights for visual inspection faster.
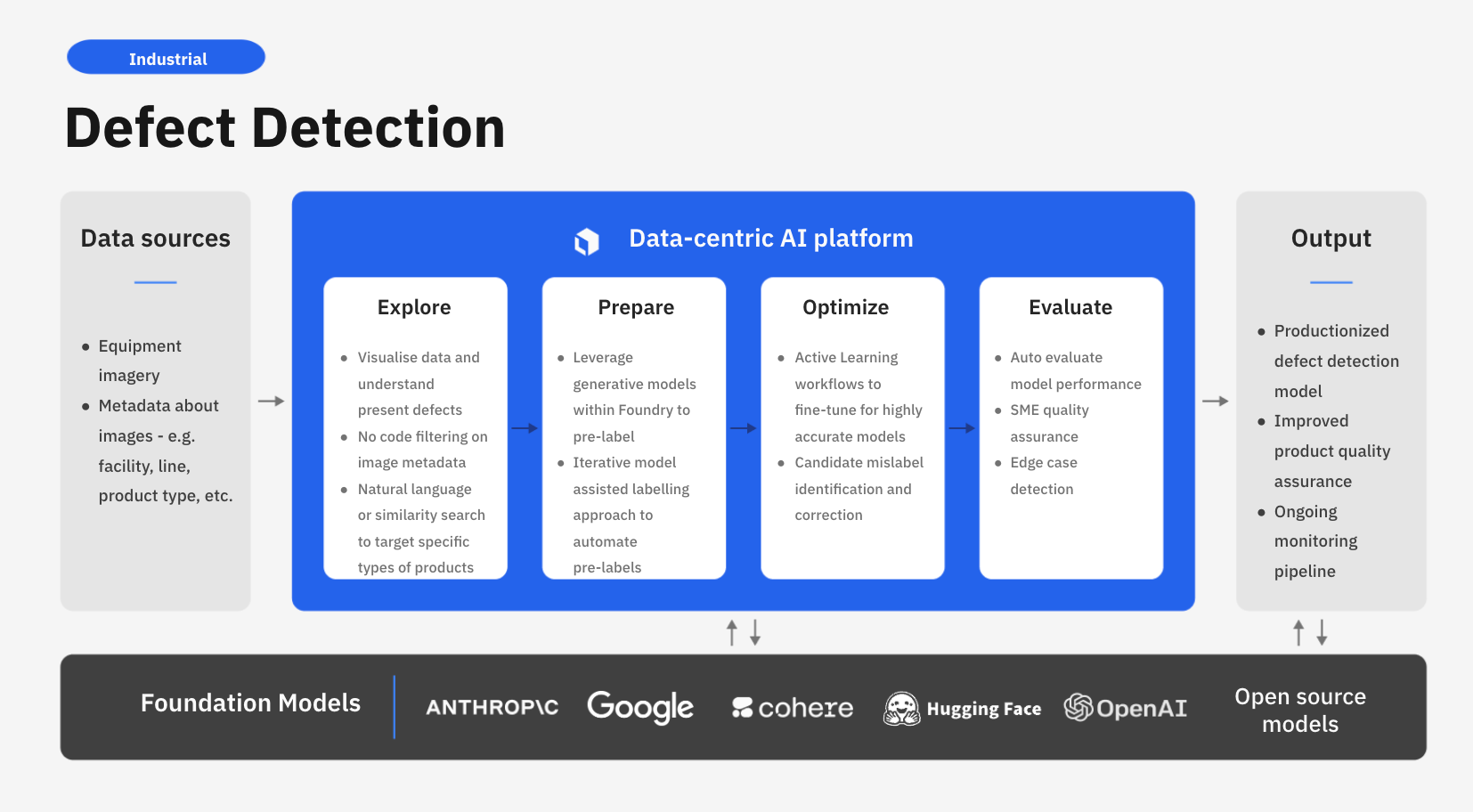
In this guide, we’ll walk through a workflow on how your team can leverage Labelbox’s platform to build a powerful task-specific models to improve defect detection using image segmentation. Specifically, this guide will walk through how you can explore and better understand your visual assets to make more data-driven business decisions for minimizing defects.
See it in action: How to build defect detection models to automate visual quality inspection
The walkthrough below covers Labelbox’s platform across Catalog, Annotate, and Model. We recommend that you create a free Labelbox account to best follow along with this tutorial.
Part 1: Explore and enhance your data with Foundry
Part 2: Create a model run and evaluate model performance
You can follow along with both parts of the tutorial below via:
Explore and prepare your data
Follow along with the tutorial and walkthrough in the Colab Notebook. If you are following along, please make a copy of the notebook.
Ingest data into Labelbox
For this tutorial, we’ll be working with a dataset that shows submersible pump impeller images for a defect detection use case – with the goal of quickly curating data and segmenting for chips and frayed edges in order to detect broken parts.
The first step will be to gather data:
Please download the dataset and store it in an appropriate location on your environment. You'll also need to update the read/write file paths throughout the notebook to reflect relevant locations on your environment. You'll also need to update all references to API keys, and Labelbox ontology, project, and model run IDs
- If you wish to follow along and work with your own data, you can import your data as a CSV.
- If your images sit as individual files in cloud storage, you can reference the URL of these files through our IAM delegated access integration.
Once you’ve uploaded your dataset, you should see your image data rendered in Labelbox Catalog. You can browse through the dataset and visualize your data in a no-code interface to quickly pinpoint and curate data for model training.
Search and curate data
You’ll now be able to see your dataset in Labelbox Catalog. With Catalog, you can contextualize your data with custom metadata and attachments to each asset for greater context.
In this demo, we'll be using Catalog to find relevant images of submersible pump impellers for our dataset with the goal of annotating broken parts using foundation models.
Leverage custom and out-of-the-box smart filters and embeddings to quickly explore product listings, surface similar data, and optimize data curation for ML. You can:
- Search across datasets to narrow in on data containing specific attributes (e.g metadata, media attributes, datasets, project, etc.)
- Automatically find similar data in seconds with off-the-shelf embeddings
- Filter data based on natural language and flexibly layer structured and unstructured filters for more granular data curation
Manually label a subset of data to train a first model with Auto-Segment
The next step is to manually label a subset of our data using the Segment Anything Model within Annotate.
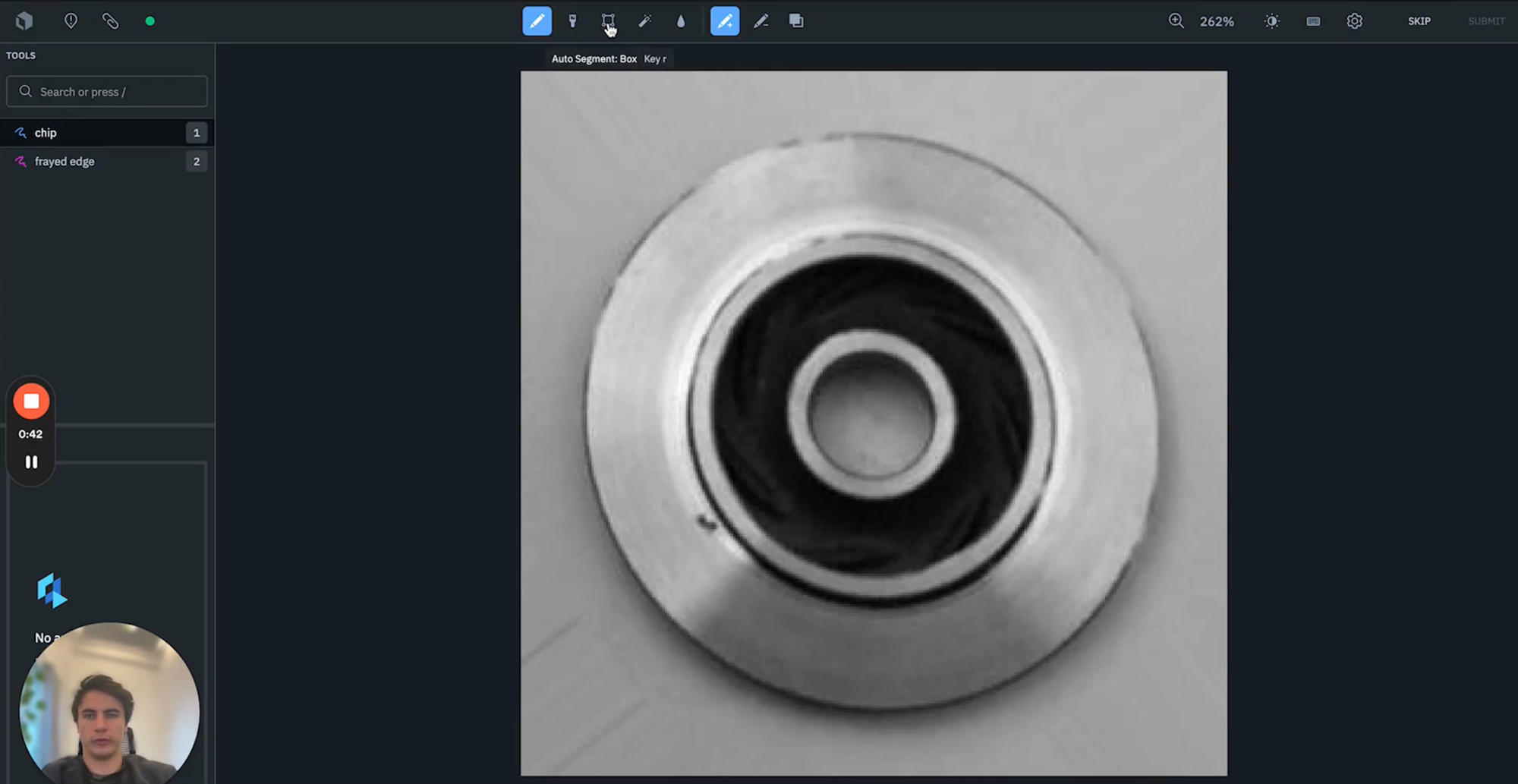
1) Let's first start off with two hundred images and include the project that we've just set up within Annotate. Once the data rows have been loaded into our Annotate project, we can begin the labeling process.
2) By navigating to the labeling editor, we can set up and use the ontology that we defined earlier with each of the objects of interest, in this case, chips and frayed edged.
3) Next, let's use the auto-segment tool powered by Facebook's Segment Anything Model to accelerate the overall labeling. This makes use of powerful AI in the back end of the editor and allows the user to simply draw a bounding box around objects of interest before the model automatically identifies the segment mask for chips and edges.
4) An additional aspect you can make use here are keyboard hotkeys to save us time, which is shown as the number next to our object of interest. By simply selecting one of the keys, this allows us to activate the chip annotation. Hovering over the auto-segment tool, we can see the key "R" is shown. By selecting "R" on our keyboard, we can activate the auto-segment tool on and off. So having tagged this one chip, we may want to select the second one.
5) You can continue through in this manner until you reach an appropriate data set for training your first iteration of your model. In the example shown, once we reach two hundred images, we're now in a position to train the first version of our model and upload our model predictions.
Having uploaded our model predictions, we can step back into the Labelbox platform to begin to explore our model run and understand how we performed in terms of predictions versus ground truth.
To do so, you can navigate to the Model tab, find the experiment of interest, in this case defect detection and make sure that we're selecting the run that we have just created. We can begin to explore visually how our predictions compare to the ground truth data.
We can see that there's some good overlap when it comes to chips, but the frayed edges are performing poorer in this case. Aside from just simply visualizing and exploring in this manner here, we can also step into the Analytics tab which provides various views of performance. You'll see that in the overall object metrics, (which provides a traditional precision recall F1 score) is performing fairly well in terms of where there is an instance of a object be that afraid edge or a chip.
However, the intersection over union (IoU) score is still low, which suggests that while we're detecting some objects, we are not correctly detecting the full segmentation area of the objects. This is where you can deep dive into the confusion matrix and see that on the whole chip detection performing significantly better than frayed edges.
Now that we have our first iteration of the model, we can see that there's room for improvement. In the next step, let's use our initial model's predictions as part of a model assisted labeling pipeline to accelerate the overall annotations for our second iteration of the training data.
Leveraging Model Assisted Labelling to accelerate labeling and improve model performance
Having trained the first iteration of our model, we can now run inference over the remaining dataset and upload these predictions into our Annotate project as part of a model-assisted labeling pipeline. You can do this by following through the code provided in the Colab Notebook that accompanies this demo.
Once you've uploaded your predictions to your Annotate project, you can step back into Labelbox, find the appropriate project and iterate or modify pre-labels and speed up the annotation process.
You can continue through with this process, accelerating the time it takes for labeling until you arrive at a suitable sized dataset for training your second iteration of your model. This process will continue until you have reached a model that is of production quality as assessed through the Model tab we have seen previously.
Set up a second Model run and train an improved model
After having progressed through a second round of labeling, we'll arrive at a point where the labeled dataset is sufficiently large for training a second iteration of our model.
In this case, we have a thousand datarows, and we're now in a position to create our second model run. To do so, we navigate to the model experiment that we created previously.
Let's keep the splits between the train, validate, and test set as they were before and create a new Model run. Once this is done, so we can select Model run and see the splits between training, validation, and test sets. By refreshing this view, we will be able to visualize our labeled data, and continue with the second training of a new model.
Upload second model results and compare performance
As a next step, after having uploaded our second model runs predictions is the to evaluate whether or not we have seen the expected improvement between our two models.
Let's navigate back to our Experiments tab within Labelbox. For our first model we had a particularly low intersection over union (IoU) score. If we're interested in understanding whether or not we've seen improvement in this metric, we can scroll down to the appropriate graphic that demonstrates our intersection over union performance and in the top left, we can select the option to compare against our second model run.
Looking at this graph allows us to compare the intersection over union (IoU) scores between our two classes across both model runs. We can see that while there's been a small improvement in performance for a chip class, there's been a larger performance improvement for frayed edges. This shows that we're heading in the right direction with the overall performance of our second model run being better than that of our first.
In a real-world setting, a decision point would have to come as to whether or not our second model is ready for production. In the event that it is not, we recommend training a third iteration using our second model to perform model-assisted labeling and accelerate the time for labeling a larger proportion of our dataset.
Teams can repeat this iterative process at each stage, evaluating whether or not your model performance is improving with each iteration. In conclusion, this workflow should be able to help you leverage Labelbox at each stage from evaluating models to helping speed up labeling and accelerating your time to value.
Summary
By analyzing high-volumes of images using automation and model-assisted labeling, Labelbox provides teams with the ability to inject valuable human-in-the-loop insights for delivering better models that allow you to detect defects faster that can help improve throughput, quality assurance and overall visual inspection.
Labelbox is a data-centric AI platform that empowers teams to iteratively build powerful task-specific models. To get started, sign up for a free Labelbox account or request a demo.


