
 All guides
All guidesHow to improve your task-specific chatbot for better safety, relevancy, and user feedback
Building task-specific chatbots requires a structured approach when it comes to improving their everyday usefulness, specifically for better safety, relevancy, and user feedback. Given the highly subjective tasks LLM-powered chat applications are expected to perform, a common denominator for how well they do in real-world settings depend on the availability of reliable high-quality training data and how closely aligned they are to human preferences. Working hand-in-hand with leading AI teams, we've observed a set of best practices that we wanted to share in order to help you improve the performance of your task-specific chatbots.
- To ensure high levels of trust & safety, an LLM-powered chatbot should be able to detect intentions, entities, and topics when interacting with a user. With quality labeled examples, a task driven application can steer away from conversations that are not relevant to its intended task, ensuring a safe and smooth user experience.
- The large language model (LLM) at the heart of the chat application must be fine tuned with relevant responses or enhanced with human feedback from RAG techniques (e.g. Reranking) in order to ensure that the user receives the most relevant information. Examples of LLMs that can be used, include GPT.
- To prevent a chatbot from drifting or getting stale with outdated responses, ML teams must continuously monitor and evaluate model performance using ground-truth responses and / or human feedback.
In this tutorial guide, we'll walk through some of these top considerations and how Labelbox can be used as a platform to help accelerate chatbot development.
Part 1: Trust and Safety — Understanding Intentions
To ensure the best user experience, an LLM-based chatbot must be properly scoped to deliver on its intended area of expertise. For example, a chatbot application for an airline company should not be responding to off topic questions, such as politics. Therefore, a chatbot that understands user intent can steer the user towards its intended areas of expertise and away from potentially harmful or unrelated conversations.
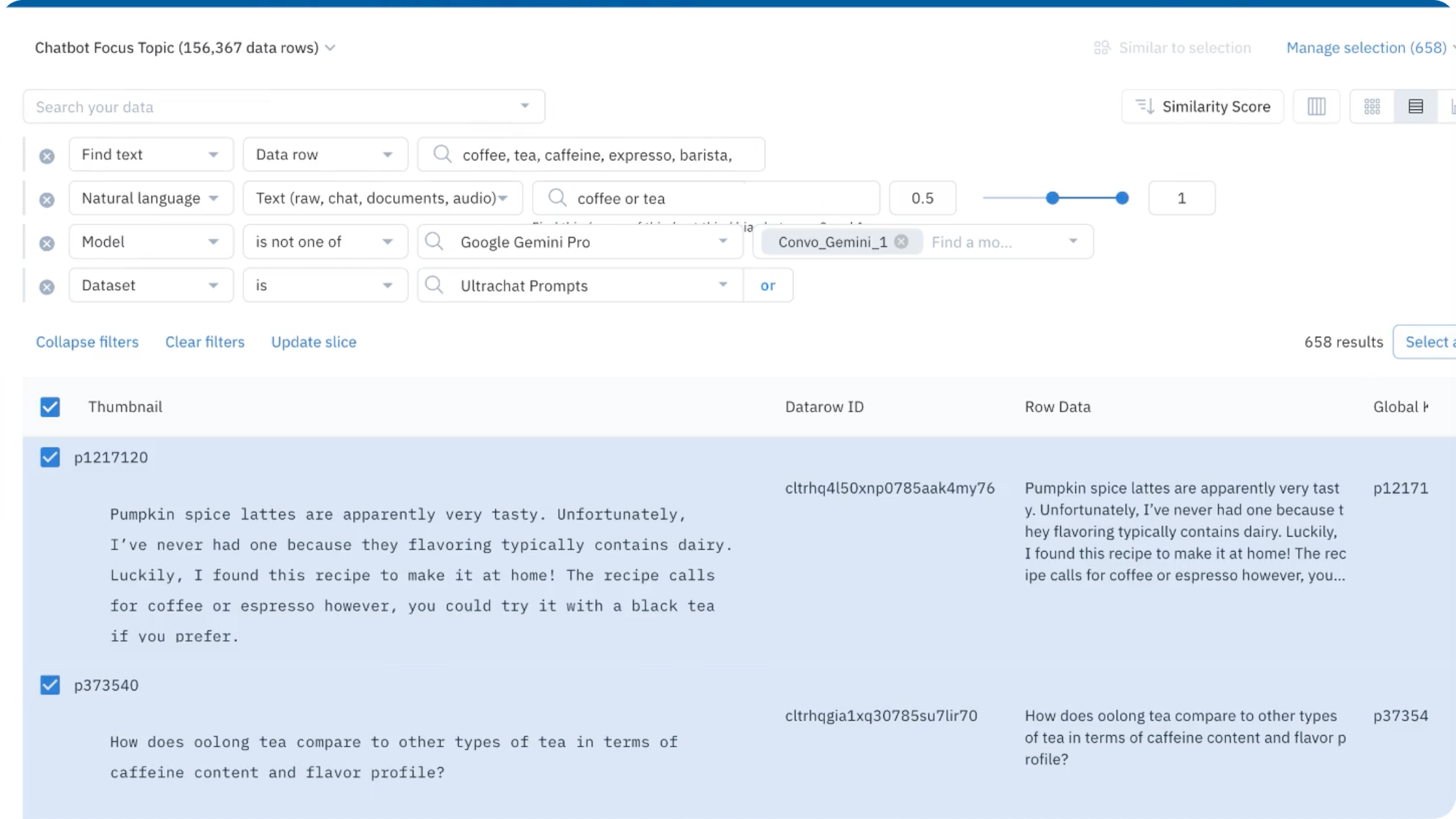
In this section, we'll leverage Labelbox to classify the intent of historical conversations as on-topic (coffee / tea) or off-topic (politics). To start off, let’s load a subset of the Ultrachat dataset to Labelbox Catalog. Ultrachat is an open-source dialogue dataset powered by Turbo APIs to train powerful language models with general conversational capability.
To being, let's first identify political conversations that your chatbot shouldn’t be able to answer.
- Using the Catalog filters, we can cast an initial wide net of examples.
- Semantic Search — utilize the underlying vector embeddings to return relevant prompts (Politics and opinionated text)
- Other functions (e.g. find text) — this will be used to identify targeted keywords or phrases
- Save the filters as a "Slice" for further reference

You can see that using semantic search and labeling functions have produced promising initial results. As a next step, let’s validate your results further with foundation models.
- With Labelbox, you can use a pre-trained foundation model to verify the results from semantic search and other functions.
- By selecting the targeted Data Rows within the slice, you can apply Google’s Gemini Pro to check for political and opinionated classification.
- The results will be returned to you as pre-labels.

To ensure completeness, you can next leverage a human-in-the-loop (HITL) approach to conduct a final review for intent.
- Using Labelbox Annotate, you create an Annotation Project for Text.
- You can now send the Prompts and responses (as pre-labels) to your Annotation Project.
- A human-in-the-loop (HITL) approach ensures that the prompts are checked for complex nuances by skilled professionals that the models may have missed.

- Utilizing the Labelbox SDK, these prompts, along with their labeled classifications, can now be seamlessly integrated with trust and safety frameworks, such as NeMo Guardrails, an open source toolkit for controlling the output of a large language model.
- Based on the prompts and classifications labeled in the previous steps, we can feed these examples into NeMo to ensure that the application does not respond to potentially sensitive political topics.

Part 2: Generating Quality Responses for your LLM-based Chatbot
When your intelligent chat application is powered by an underlying large language model, you can customize these LLMs to a defined task with 2 key approaches: Fine-tuning or Retrieval Augmented Generation (RAG).
- For this exercise, you will fine tune a task-specific LLM, and you can follow along via text below or from the video above. It’s worth noting that Labelbox can also be used for optimizing RAG based systems with techniques such as Reranking.
To start off, let's first generate quality responses to selected prompts. Ideally, we’ll want the chatbot to replicate the responses provided by your annotators.
- Using Labelbox Catalog, you'll identify the relevant prompts related to coffee, and you can combine filters such as:
- Semantic search with input prompt
- Similarity search with ideal example data rows
- Keywords matching
- Exclude already classified prompts that were shown in Part 1 of this tutorial
- Save your filters as a Slice

- Once you have the initial set of LLM prompts, you will next create an annotation project for Humans Responses to Uploaded Prompts. This allows you to quickly generate quality responses to each of the selected prompts.

Your team of annotators can now produce specific responses for the LLM to learn from.
- If you need help in this domain, Labelbox provides on-demand teams of skilled professional labelers with LLM experience via Labelbox’s Boost Workforce.

- Once your dataset is generated, you can use the Python SDK to export the labels and convert it to a format for model fine-tuning (e.g. JSONL format for GCP Vertex AI)
By identifying relevant prompts and generating quality responses, you can now train a task specific LLM model and output predictions for any new requests.
Part 3: Model Evaluation and Deployment
Before deploying your model into production, let’s evaluate the performance of the responses when compared to your ground-truth data (expected output). Using holdout prompts and responses pairs not used to train the model, you can evaluate the performance of your fine-tuned LLM.
- Using Labelbox Model, let’s first create a new experiment as shown below.

Afterwards, you can create a model run to add the holdout dataset containing the ground-truth responses.

Using the Python SDK, you can next export the prompts to generate responses from your fine-tuned model from Google's Vertex AI.
- Using 3rd-party libraries, you can calculate custom metrics for evaluating NLP tasks, such as the BLEU score
- The predictions and custom metrics can now be uploaded back into your model run

- With the metrics and predictions uploaded, you can filter by various metrics to identify the highest and lowest performing prompts, along with overall model performance.
- You can then select these data rows (such as this high performing prompt below) to find similar prompts within the catalog, which will be used to train the next iteration of your chat application.

Conclusion
In this guide, we highlighted a few best practices for ensuring better safety, relevancy, and user feedback when building a task-specific chatbot. Regardless of the techniques used and the models chosen, it is crucial to generate and classify data to the highest quality for optimizing chatbot outputs.
By incorporating semantic search, labeling functions, foundation models, and a human-in-the-loop approach, you will be able to generate and classify data in higher qualities consistently. Combined with an SDK-driven approach, you can more easily train models and enhance LLM performance through faster iterations. Give the tutorial a try and we'd love to hear your feedback or ideas on how we can help you improve your LLM-based chatbot applications.


