
 All guides
All guidesHow to use AI to automate invoice and document processing
With AI-powered invoice and document processing, you can now seamlessly integrate the latest advances in foundation models into your core financial and administrative operations. As the demand for better monitoring, reporting and compliance continues to rise, it's essential for teams to ensure accurate, timely, and organized handling of financial transactions. Labelbox empowers the world’s largest financial services organizations to leverage AI solutions tailored to their unique invoice and document processing challenges.
However, teams can face multiple challenges when implementing AI for large-scale invoice & document processing. This includes:
- Data quality and quantity: Improving invoice and document processing via OCR analysis requires a vast amount of data in the form of document PDFs and images. Orchestrating data from various sources can not only be challenging to maintain, but even more difficult to sort, analyze, and enrich with quality insights.
- Dynamic review landscape: The changing nature and format data from multiple sources poses the challenge for businesses to account for continuous data updates and re-training needs.
- Cost & scalability: Developing accurate custom AI can be expensive in data, tools, and expertise. Leveraging foundation models, with human-in-the-loop verification and active learning, can help accelerate model development by automating the labeling process.
Labelbox is a data-centric AI platform that empowers businesses to transform their invoice and document processing through advanced computer vision and OCR techniques. Instead of relying on time-consuming manual human review, companies can leverage Labelbox’s AI-assisted data enrichment and flexible training frameworks to quickly build task-specific models that uncover actionable insights for faster processing.
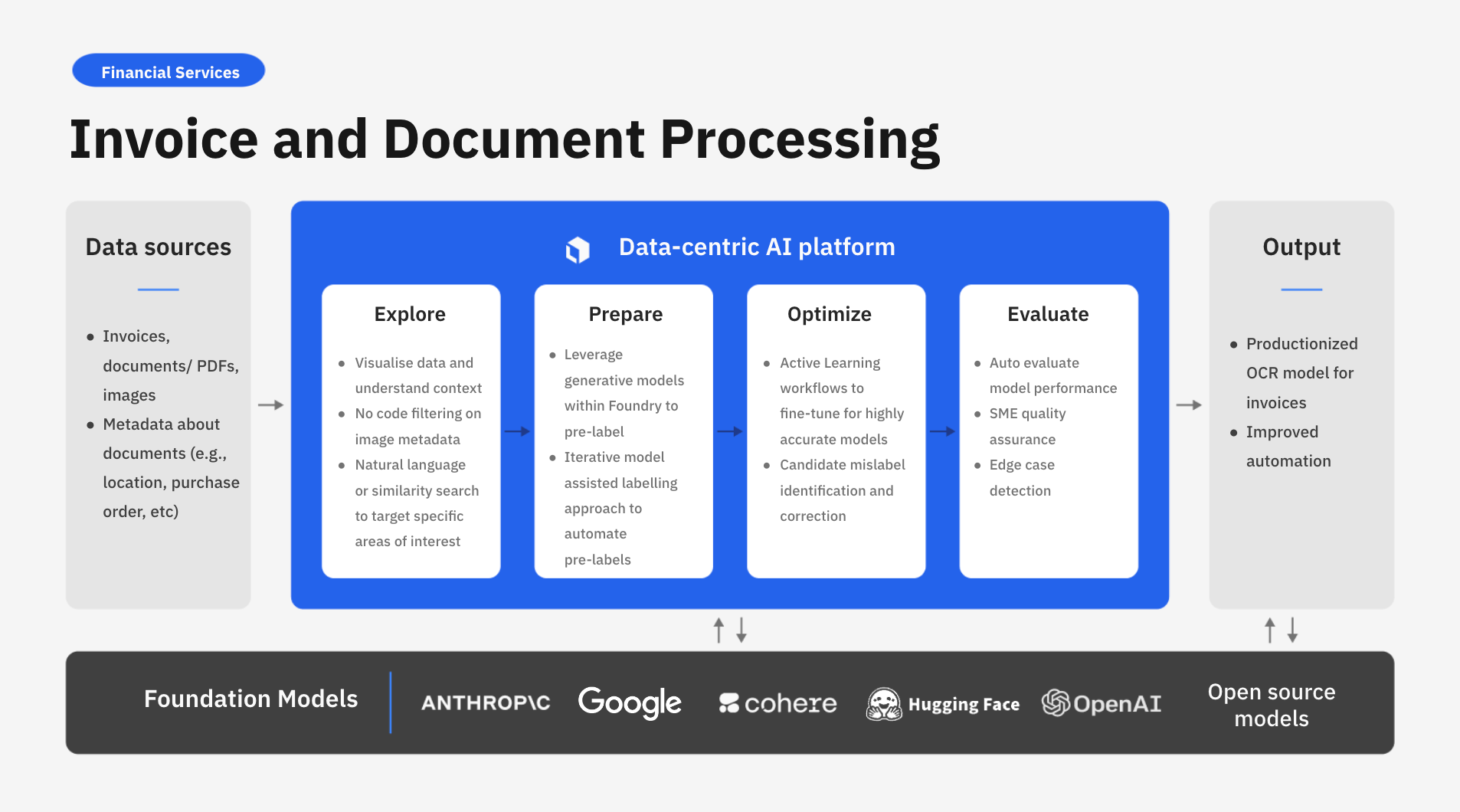
In this guide, we’ll walk through how your team can leverage Labelbox’s platform to build an AI model to improve invoice and document processing from images. Specifically, this guide will walk through how you can explore and better understand unstructured data to make more data-driven business decisions.
See it in action: How to use AI to automate invoice and document processing
The walkthrough below covers Labelbox’s platform across Catalog, Annotate, and Model. We recommend that you create a free Labelbox account to best follow along with this tutorial.
Part 1: Explore and label your data with Catalog and Foundry
Part 2: Create a model run and evaluate model performance
Part 1: Explore and prepare your data
Ingest data into Labelbox
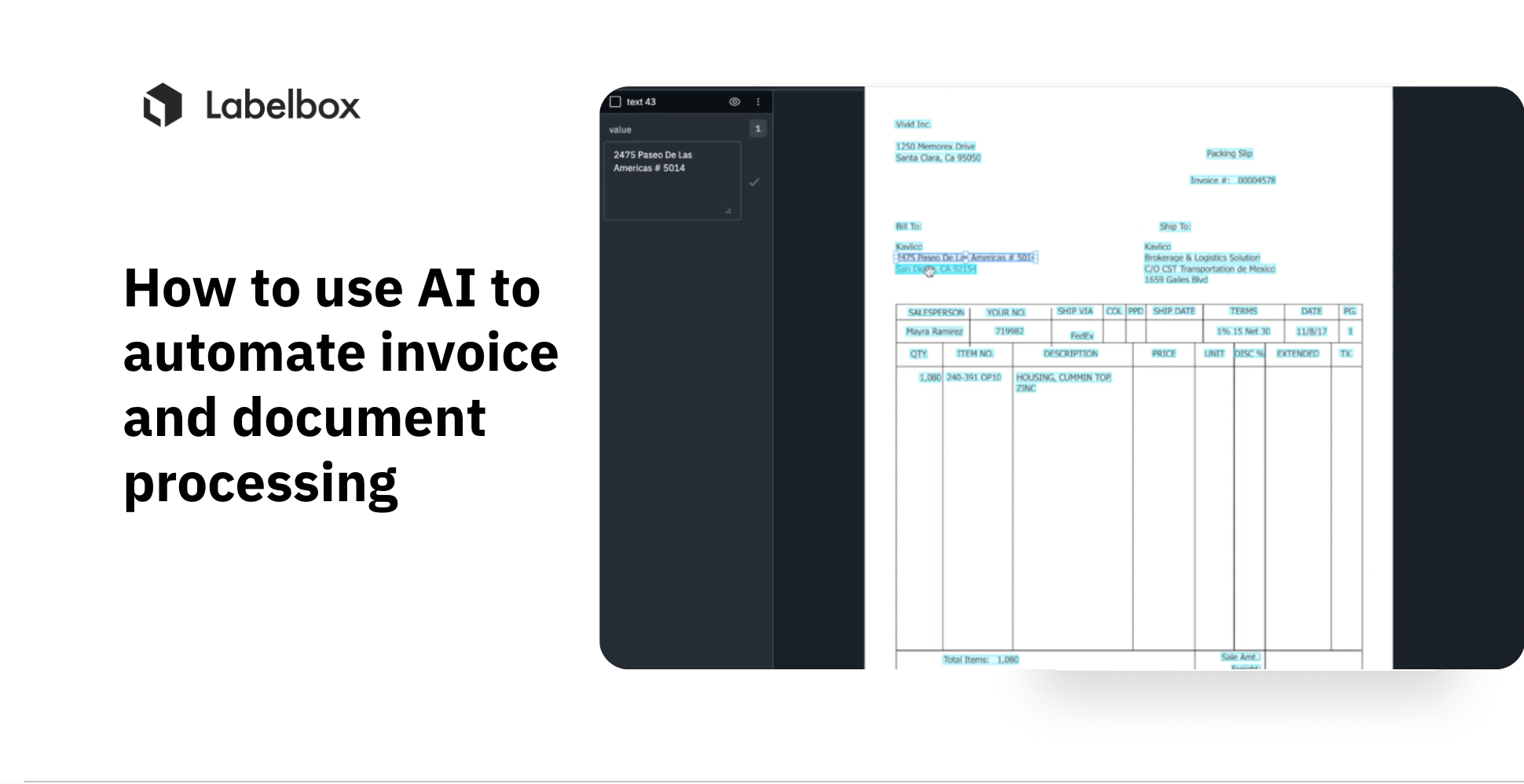
For this tutorial, we’ll be working with a dataset of image invoices – with the goal of quickly curating data, and using OCR to understand where the text is and to identify what information these invoices contain while finding and correcting model errors. This workflow is very popular with Labelbox users because it allows teams to have a model do most of the work, while humans (aka subject matter experts) will be able to focus on the task of correcting the model, thereby reducing the amount of manual work.
Once you’ve uploaded your dataset, you will see your image data rendered in Labelbox Catalog. You can browse through the invoice dataset and visualize your data in a no-code interface to quickly pinpoint and curate data for model training.
Search and curate data
You’ll now be able to see your invoice dataset in Labelbox Catalog. With Catalog, you can contextualize your data with custom metadata and attachments to each asset for greater context.
Leverage custom and out-of-the-box smart filters and embeddings to quickly explore image invoices, surface similar data, and optimize data curation for ML. You can:
- Search across datasets to narrow in on data containing specific attributes (e.g metadata, media attributes, datasets, project, etc.)
- Automatically find similar data in seconds with off-the-shelf embeddings
- Filter data based on natural language and flexibly layer structured and unstructured filters for more granular data curation
Using Foundry to pre-label invoices
In this next step, we'll walk through how you can take a human-in-the-loop approach to iterate or modify pre-labels and speed up the annotation process.
Model Foundry enables teams to choose from a library of models and in this case, we'll be using Amazon's Textract to generate previews and attach them as pre-labels.
With Model Foundry, you can automate data workflows, including data labeling with world-class foundation models. Leverage a variety of open source or third-party models to accelerate pre-labeling and cut labeling costs by up to 90%.
Send to your Annotation project for human review
The next step in order to send our annotation project for human review is to to set up your ontology. In this case, we'll call it "test OCR" and we'll be using bounding boxes on our images. Note that you can reuse the ontology that you've created previously or you can create a new one.
In this case, we want a bounding box for text, as well as a sub-classification for the value with the goal of identifying where the text is for bounding boxes.
We can now include the model predictions that we just completed, and if we're confident that the model is performing well, we can set it to an initial labeling task or as an initial review task. A labeling task means that the labeler will be able to adjust and modify before it goes to a reviewer, and your reviewer will be able to just reject or accept the labels.
In this case, we have chosen to use Amazon Textract but there are a variety of OCR-specific models that are available within Foundry. Alternatively, we can choose to use your own custom model for OCR invoice detection. The benefits of this approach is that it will allow you to run predictions using your custom model as an end-to-end workflow and more quickly classify parts of interest.
Note: If this is interesting and you're looking to adopt this method within Labelbox, please reach out to our support team as we would be happy to assist with deploying your custom model within Foundry.
Human-in-the-loop review for OCR invoices
Once the initial comparison task is completed, our labelers can now start labeling and we can see how the Amazon Textract model performs on these image invoices with a human-in-the loop come workflow to correct labels for any mistakes. From this example, we can see that the model seems to be performing well so that we can submit these labels for further review and QA.
Evaluate and diagnose invoice processing model effectiveness
The final step involves comparing or A/B testing different OCR models to see which one is the best fit for our specific use case. In this case, we'll be comparing Amazon's Textract with the Tesseract OCR model. A disagreement between model predictions and ground truth labels can be due to a model error (poor model prediction) or a labeling mistake (ground truth is wrong).
- Visually compare ground truth labels (in green) to the model predictions (in red).
- Use the ‘Metrics view’ to drill into crucial model metrics, such as confusion matrix, precision, recall, F1 score, and more, to surface model errors.
- Model metrics are auto-populated and interactive. You can click on any chart or metric to open up the gallery view of the model run and see corresponding examples.
- Use Labelbox Model for 10x faster corner-case detection – detect and visualize corner-cases where the model is underperforming. For example, you can drill into cases where ‘empty’ objects are not predicted, where the model might have difficulty identifying specific fields in the image.
After running error analysis, you can make more informed decisions on how to iterate and improve your model’s performance with corrective action or targeted data selection.
Conclusion
By analyzing high-volumes of documents or images, Labelbox provides valuable human-in-the-loop insights for invoice and document processing to ensure enable financial services and insurance companies to make data-driven decisions that improve operational efficiency, compliance and revenue.
Labelbox is a data-centric AI platform that empowers teams to iteratively build powerful task-specific models. To get started, sign up for a free Labelbox account or request a demo.


