
 All guides
All guidesHow to build damage classification models with aerial imagery to improve claims automation

With AI-powered claims automation, you can now seamlessly integrate the latest advances in foundation models into your damage detection and disaster assessment models. As the demand for real-time intelligence into understanding residential and commercial properties grows, it's essential for teams to maximize compliance and minimize operational costs.
However, teams can face multiple challenges when implementing AI for damage detection. This includes:
- Data quality and quantity: Improving damage detection requires a vast amount of data in the form of images and videos. Orchestrating data from various sources can not only be challenging to maintain, but even more difficult to sort, analyze, and enrich with quality insights.
- Dynamic review landscape: The changing nature and format data from multiple sources poses the challenge for businesses to account for continuous data updates and re-training needs.
- Cost & scalability: Developing accurate custom AI can be expensive in data, tools, and expertise. Leveraging foundation models, with human-in-the-loop verification and active learning, can help accelerate model development by automating the labeling process.
Labelbox is a data-centric AI platform that empowers businesses to transform their claims automation through advanced computer vision techniques. Instead of relying on time-consuming manual reviews, companies can leverage Labelbox’s AI-assisted data enrichment and flexible training frameworks to quickly build task-specific models that uncover actionable insights from damage assessment.
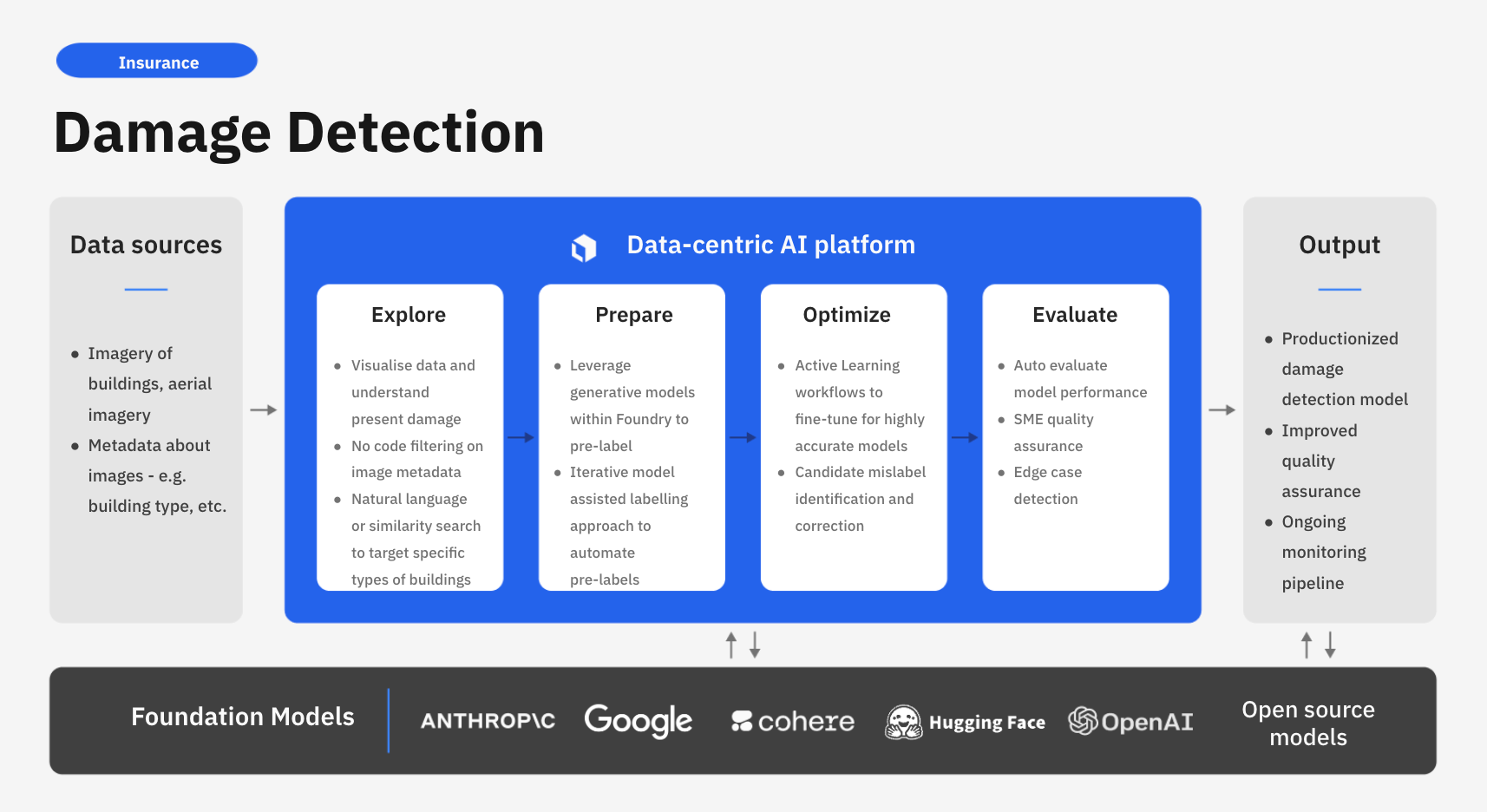
In this guide, we’ll walk through how your team can leverage Labelbox’s platform to build a task-specific model to improve building damage detection via aerial imagery. Specifically, this guide will walk through how you can explore and better understand unstructured data to make more data-driven business decisions around damage detection initiatives.
See it in action: How to visually assess damage and improve claims automation with AI
The walkthrough below covers Labelbox’s platform across Catalog, Annotate, and Model. We recommend that you create a free Labelbox account to best follow along with this tutorial.
Part 1: Explore and enhance your data
Part 2: Create a model run and evaluate model performance
You can follow along with both parts of the tutorial below via:
Part 1: Explore and prepare your data
Follow along with the tutorial and walkthrough in either the Google Colab Notebook. If you are following along, please make a copy of the notebook.
Ingest data into Labelbox
For this use case, we’ll be working with an open dataset from the Hurricane Maria aerial assessment dataset – with the goal of quickly curating data and finding building damage from high-volumes of images.
The first step will be to gather data:
Please download the dataset and store it in an appropriate location on your environment. You'll also need to update the read/write file paths throughout the notebook to reflect relevant locations on your environment. You'll also need to update all references to API keys, and Labelbox ontology, project, and model run IDs
- If you wish to follow along and work with your own data, you can import your data as a CSV.
- If your images sit as individual files in cloud storage, you can reference the URL of these files through our IAM delegated access integration.
Once you’ve uploaded your dataset, you should see your image data rendered in Labelbox Catalog. You can browse through the dataset and visualize your data in a no-code interface to quickly pinpoint and curate data for model training.
Search and curate data
You’ll now be able to see your dataset in Labelbox Catalog. With Catalog, you can contextualize your data with custom metadata and attachments to each asset for greater context.
In this demo, we'll be using Catalog to find relevant images of buildings for our dataset with the goal of annotating footprints using foundation models.
Leverage custom and out-of-the-box smart filters and embeddings to quickly explore product listings, surface similar data, and optimize data curation for ML. You can:
- Search across datasets to narrow in on data containing specific attributes (e.g metadata, media attributes, datasets, project, etc.)
- Automatically find similar data in seconds with off-the-shelf embeddings
- Filter data based on natural language and flexibly layer structured and unstructured filters for more granular data curation
Use Foundry to Generate Building Footprints
The next step is to use foundation models to detect as many building footprints as possible.
Model Foundry enables teams to choose from a library of models and in this case, we'll be using an object detection model (Grounding DINO) to generate previews and attach them as pre-labels.
With Model Foundry, you can automate data workflows, including data labeling with world-class foundation models. Leverage a variety of open source or third-party models to accelerate pre-labeling and cut labeling costs by up to 90%.
Set up your annotation project
By pre-labeling building footprints, we have significantly sped up our labeling efficiency and the next step is to set up our annotation project.
1) Set up annotation project and ontology.
2) Ensure ontology includes sub classification for damage severity (e.g., Low, Medium, High).
3) Include bounding box model predictions from Foundry pre-labels.
4) Zoom-in to determine the level of damage and select the appropriate level of damage or draw additional bounding boxes as needed.
[Optional] Send ground-truth data to Annotate
These next series of steps are optional and will help you bypass the manual component by uploading ground-truth directly by using the Annotation project ID.
1) Reference a cloud bucket that references annotations and corresponding damage classifications.
2) Send annotation data type of annotation project so that you have ground-truth data.
3) By uploading annotation data directly via the Python SDK, you can access ground-truth data to send directly to your models for fine-tuning and refinement.
Part 2: Create a model run and and evaluate model performance
Follow along with the tutorial and walkthrough in this Colab Notebook. If you are following along, please make a copy of the notebook.
Create a model run
Once you have your labeled data in your project in Annotate, you’re ready to move on to creating a model run in Labelbox Model.
Model training occurs outside of Labelbox. Labelbox Model works with any model training and inference framework, major cloud providers (AWS, Azure, GCS), and any data lake (Databricks, Snowflake).
We’ll be using this Colab notebook to train a model on the training dataset and bring back inferences from the trained model for evaluation and diagnosis.
You’ll be able to view the model in the ‘Experiments’ tab in Labelbox Model – you can view ground truth predictions in green and predictions in red.
Evaluate and diagnose model effectiveness
A disagreement between model predictions and ground truth labels can be due to a model error (poor model prediction) or a labeling mistake (ground truth is wrong).
- After running the notebook, you’ll be able to visually compare ground truth labels (in green) to the model predictions (in red).
- Use the ‘Metrics view’ to drill into crucial model metrics, such as confusion matrix, precision, recall, F1 score, and more, to surface model errors.
- Model metrics are auto-populated and interactive. You can click on any chart or metric to open up the gallery view of the model run and see corresponding examples.
- Use Labelbox Model for 10x faster corner-case detection – detect and visualize corner-cases where the model is underperforming. For example, you can drill into cases where ‘empty’ objects are not predicted, where the model might have difficulty identifying empty spaces on shelves where there is a wire mesh material present.
After running error analysis, you can make more informed decisions on how to iterate and improve your model’s performance with corrective action or targeted data selection.
Curate high-impact data to drastically improve model performance
Once you’ve identified an example of a corner-case where the model might be struggling, you can easily leverage Catalog to surface similar unlabeled examples to improve model performance.
- Select any corner-cases and select ‘Find similar in Catalog’ from the Manage Selection dropdown. This will bring you back into Catalog and will automatically surface all similar data rows (both labeled and unlabeled) to the selected example.
- To only surface unlabeled images that you can send to your model for labeling, you can filter on the ‘Annotation is’ filter and select ‘none’. This will only show unlabeled images that are similar to the selected corner case.
- Select all images that apply and send them as a batch to your original labeling project. Labeling these in priority will help improve model performance.
Compare model runs across iterations
Improve model development by up to 90% by leveraging Labelbox Model to compare model runs across iterations to track and quantify how model performance has improved over time.
With new high-impact data labeled, you can retrain the model using the same steps with the Colab notebook on this improved data set. You can track model improvements across various runs for comparison and how this has affected model performance.
By analyzing high-volumes of images, videos and text, Labelbox provides valuable human-in-the-loop insights for damage detection processes to ensure underwriting risks, enabling insurance companies to make data-driven decisions that improve operational efficiency, compliance and revenue.
Labelbox is a data-centric AI platform that empowers teams to iteratively build powerful task-specific models. To get started, sign up for a free Labelbox account or request a demo.


