
 All guides
All guidesHow to turn LangSmith logs into conversational data with Labelbox
To design task-specific LLMs, a step-by-step approach that will improve their day-to-day usability needs to be taken while ensuring safety and relevance and obtaining user feedback. The success of these in real-world scenarios depends on the availability of reliable, high-quality training data and with alignment from human preferences.
LangChain, one of the most popular frameworks for building LLM-powered applications, is complemented by LangSmith, a unified developer platform for building, testing, and monitoring LLM applications. Together, LangChain and LangSmith provide the framework and platform for you to manage the entire LLM-powered application lifecycle.
Labelbox offers a comprehensive data-centric AI platform that includes a native labeling editor, model-assisted labeling, human-labeling workflows, human labeling workforce, and diagnostics to align task-specific models and develop intelligent applications across various data modalities, including text, documents, audio, images, and video, while also providing features like data catalog, model automation, and workforce services to optimize labeling operations and scale human evaluation.
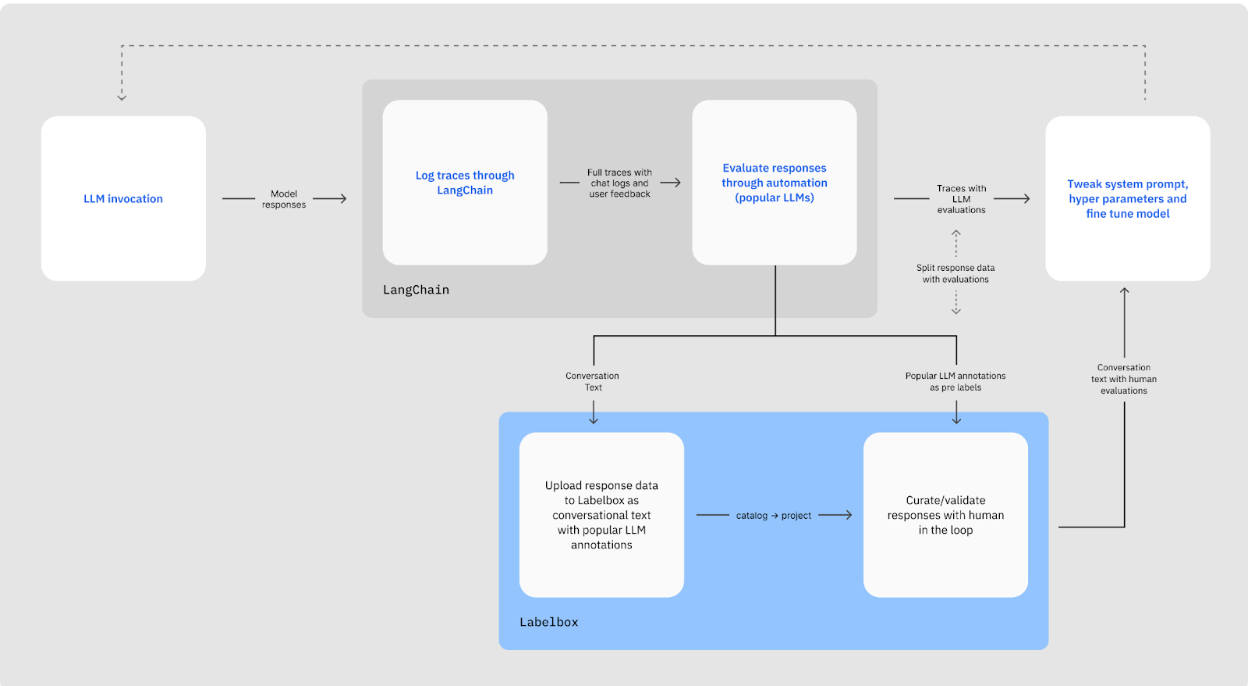
In this tutorial guide, we’ll walk through combining Labelbox and LangSmith by getting conversation data created with LangSmith to Labelbox.
Below is also a video guide for more details:
Steps
What you’ll need
- Labelbox API key
- LangSmith API key
- OpenAI API
You can also follow-along with this Colab notebook.
Setup
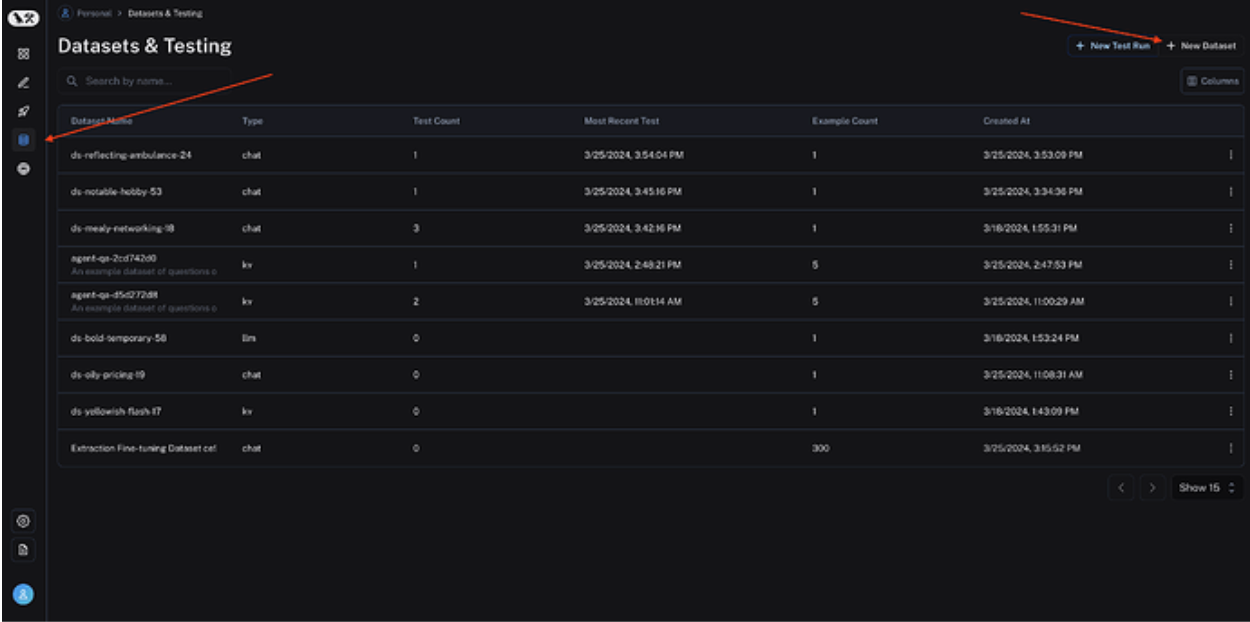
Utilizing LangSmith Python SDK, you can run a variety of LLMs on a test dataset, and example prompts to evaluate a model’s performance. First, you must create a dataset inside LangSmith. Make sure to keep track of the name you give your dataset and set the type as Chat:
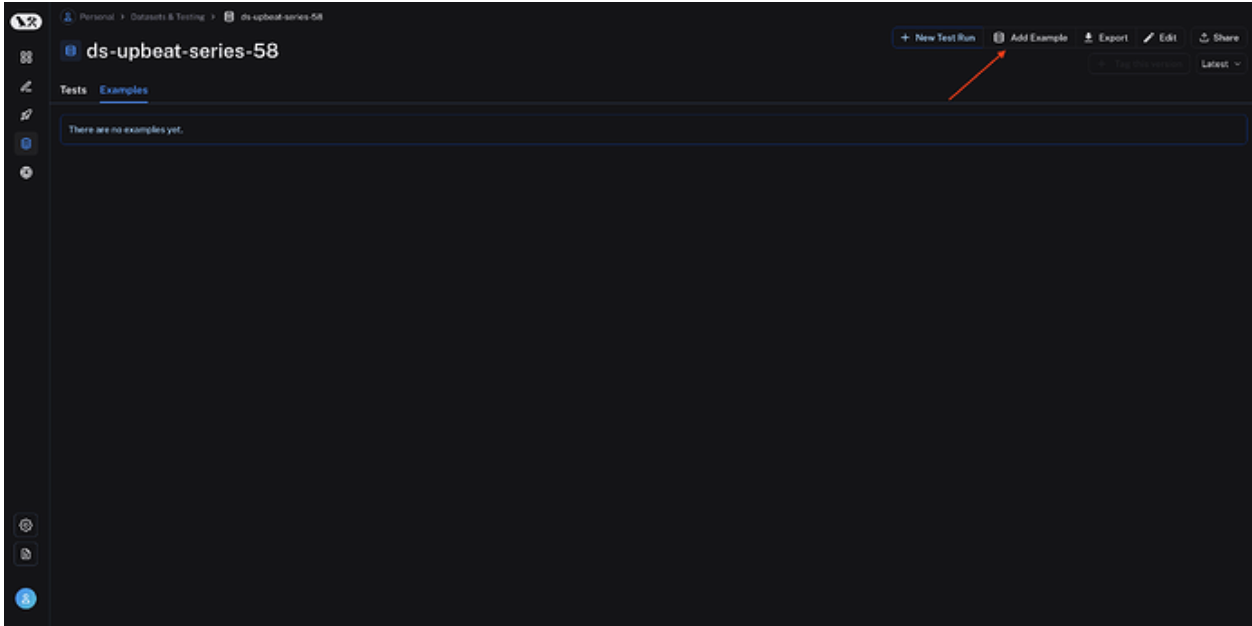
After you create your dataset, add a few example prompts that can be used to evaluate your model.
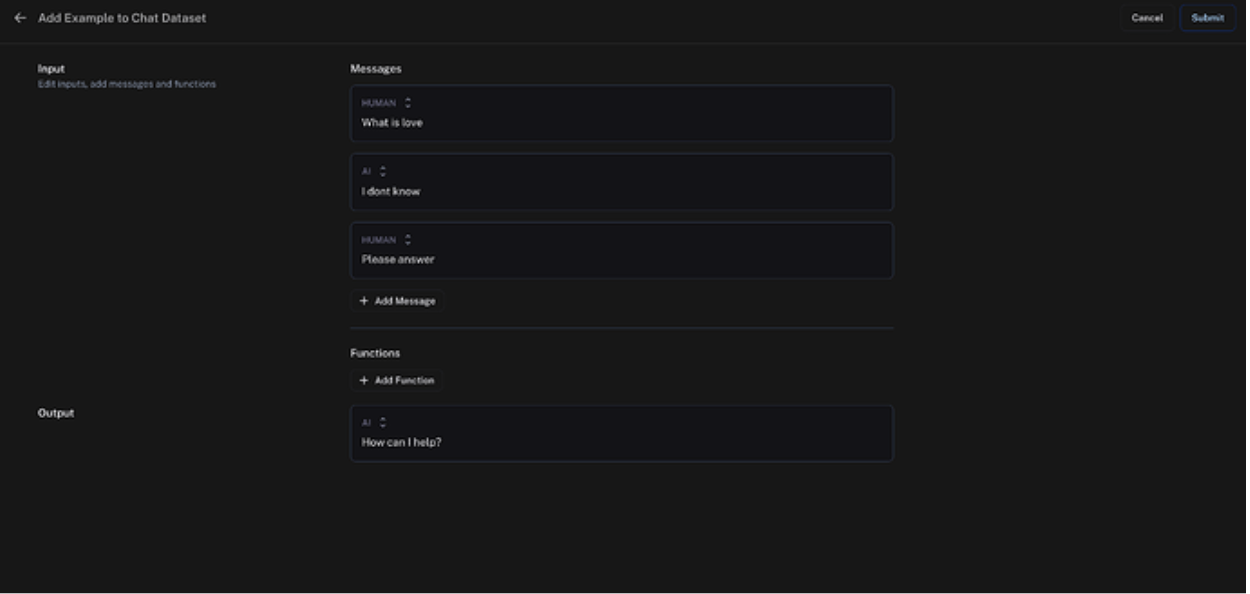
Evaluate Model
Now that you are set up, you can evaluate your model with your example prompts. The notebook included in this tutorial goes over this process. We will be using the chain_results after running our model on our dataset. Below is an example of what that would look like:
chain_results = run_on_dataset(
dataset_name=LS_DATASET_NAME,
llm_or_chain_factory=functools.partial(
create_agent, prompt=prompt, llm_with_tools=llm_with_tools
),
evaluation=evaluation_config,
verbose=True,
client=client,
project_name=f"tools-agent-test-5d466cbc-{unique_id}",
# Project metadata communicates the experiment parameters,
# Useful for reviewing the test results
project_metadata={
"env": "testing-notebook",
"model": "gpt-3.5-turbo",
"prompt": "5d466cbc",
},
)Create Labelbox Data Rows
With the chain results obtained above, you can format to Labelbox conversation data using the function below. Please see the Labelbox Import Conversation Text Data developer guides for more information.
from uuid import uuid4
def import_conversational (chain_results: dict[str:str], user_id_dict: dict[str:str], output_user_name: str) -> dict[str:str]:
"""Turn chain_result dictionary object from Langchain to conversation data for Labelbox
Args:
chain_results (dict[str:str]): LangChain evaluation results.
user_id_dict (dict[str:str]): Dictionary matching chat type of LangChain(user) to Labelbox type with corresponding Labelbox UserID and Chat Alignment.
{<Langchain user>: {id: <labelbox userid>, "alight", <Labelbox alignment (right or left)>}}
output_user_name (str): LangChain output user type.
Returns:
list[<labelbox data tows>]
"""
lb_conversations = []
for conversational in chain_results["results"].values():
lb_conversation = {
"row_data": {
"type": "application/vnd.labelbox.conversational",
"version": 1,
"messages": []
},
"global_key": str(uuid4()),
"media_type": "CONVERSATIONAL",
}
if "input" in conversational["output"]:
for input in conversational["output"]["input"]:
lb_conversation["row_data"]["messages"].append({
"content": input["data"]["content"],
"user": {
"userId": user_id_dict[input["type"]]["id"],
"name": input["type"]
},
"canLabel": True,
"align": user_id_dict[input["type"]]["align"],
"messageId": str(uuid4())
})
if "output" in conversational["output"]:
output = conversational["output"]["output"]
lb_conversation["row_data"]["messages"].append({
"content": output,
"user": {
"userId": user_id_dict[output_user_name]["id"],
"name": output_user_name
},
"canLabel": True,
"align": user_id_dict[output_user_name]["align"],
"messageId": str(uuid4())
})
lb_conversations.append(lb_conversation)
return lb_conversationsThe function uses a dictionary python object parameter (user_id_dict) to match LangSmith user types to Labelbox types along with their alignment inside the editor. The messages in this example are all marked as “canLabel: True.” This means that all messages can be annotated inside our editor. Also, the global key is set randomly through the UUID Python library, but you can have the global_key set to the ID associated with the example run to avoid importing duplicate information.
Import Data Rows into Labelbox
Now that you have created your data rows with your conversational data, you can import them into Labelbox. Please reference these documents from Labelbox for more information. The script below demonstrates creating a Labelbox dataset and importing your data rows.
import labelbox as lb
client = lb.Client(api_key="<YOUR_API_KEY>")
dataset = client.create_dataset(name='<dataset_name>')
dataset.create_data_rows("<data row payload>")Use Cases and Implication
Utilizing Labelbox with LangSmith can better develop chatbots by engaging large language models (LLMs) for conversation intent classification. This combination enables constant model tracking and evaluation because LangSmith and Labelbox ensure the chatbot performance adheres to human preferences through proper training data. Also, alongside a human-in-the-loop system, semantic search and pre-trained models for pre-labeling allow nuanced analysis.
Combining efforts between Labelbox and LangSmith enhances the performance of RAG-based agents by improving reranking models and preprocessing documents to make them more relevant. Considering a broader collection of retrieved text or incorporating more human-generated labels rather than relying only on a single document can facilitate the generation of high-quality training labels, hence making the chatbot responses more relevant and accurate.
The tutorial above demonstrates the combination of LangSmith with Labelbox, enabling some of the mentioned use cases.
Conclusion
Once you have your data rows inside Labelbox, you can send them to an annotate project where you can apply a variety of annotations or have a popular LLM model generate pre-labels that can then be evaluated with a human in the loop. After annotating your data rows, you can utilize the generated labels to train your LLM further. You can then reassess and annotate your predictions using the same workflow.
If you’re interested in learning more about the capabilities offered by Labelbox and LangChain for supporting generative AI development, check out our partnership announcement for additional entails and use cases.
Interested in joining the conversation? Let us know what you think in our original post here.
Reach out to the Labelbox sales team to start implementing a hybrid evaluation system for your production generative AI applications.


