
 All guides
All guidesUsing Labelbox and Weights & Biases to fine tune your computer vision projects
Introduction
Repeatable, scalable, and diagnosable production artificial intelligence (AI), requires a sophisticated machine learning operations (MLOps) ecosystem. MLOps is the backbone of machine learning (ML) engineering, focused on streamlining development of AI/ML models and deploying, and monitoring those models in production.
In this post, we’ll explore an MLOps architecture that uses both Labelbox and Weights & Biases to develop a computer vision model for a manufacturing focused use case. The goal of the model is to reduce defects on a production manufacturing line using automated visual inspection and the model requires human judgment to curate (supervise) the training data for model development.

Key Components of AI Development
Developing a production caliber model is an extremely iterative process. Rarely, if ever, is a model trained once and ready for production. Typically, there are a series of experiments that need to be run across several combinations of datasets and models, followed by expert analysis to determine which one yields the best results. Each experiment must be meticulously tracked and analyzed as ML teams cycle through the development process.
It’s not uncommon for data science teams to jump into model training without a clear understanding of their data. This can greatly increase the number of model training iterations needed to achieve the desired result, drive up development cost and increase the risks of achieving shipping ML-powered products on time.
An efficient, data centric model development approach is valuable, and consists of two key ML Ops components, a data-centric AI platform (Labelbox) and a model diagnostics platform (Weights & Biases).
Improving your data and models
When your model is being developed/trained or when it is in production, there will be indicators that your model is either drifting or performing poorly. This will be noticed in the different statistics your model outputs - confidence, accuracy, loss, a fluctuation in the number of detections or the classes that are being detected, all of which will be tracked and triggered in a model diagnostics platform such as Weights & Biases.
But what about improving the actual dataset? Or understanding which specific data my model is performing poorly on and determining which new data will most improve my model? How do I quickly get that data labeled and back into model training? When transitioning from model diagnostics to data diagnostics, we recommend leveraging tools to quickly understand the data that your model is performing poorly on, find more data similar to that, and curate subsequent datasets in order to iterate through the model development process faster.
The bottom line is that model diagnostic tools and AI platforms supplement each other and should be used together. Let's dive deeper into what this looks like in practice.
How it looks in practice
Once Labelbox and Weights & Biases have been installed and are set up in your pipeline, what does it look like to embark on the model development journey for the first time (or subsequent times)? Let’s look at an example workflow, most of which can be performed in a seamless process by leveraging both the Labelbox and W&B SDKs:
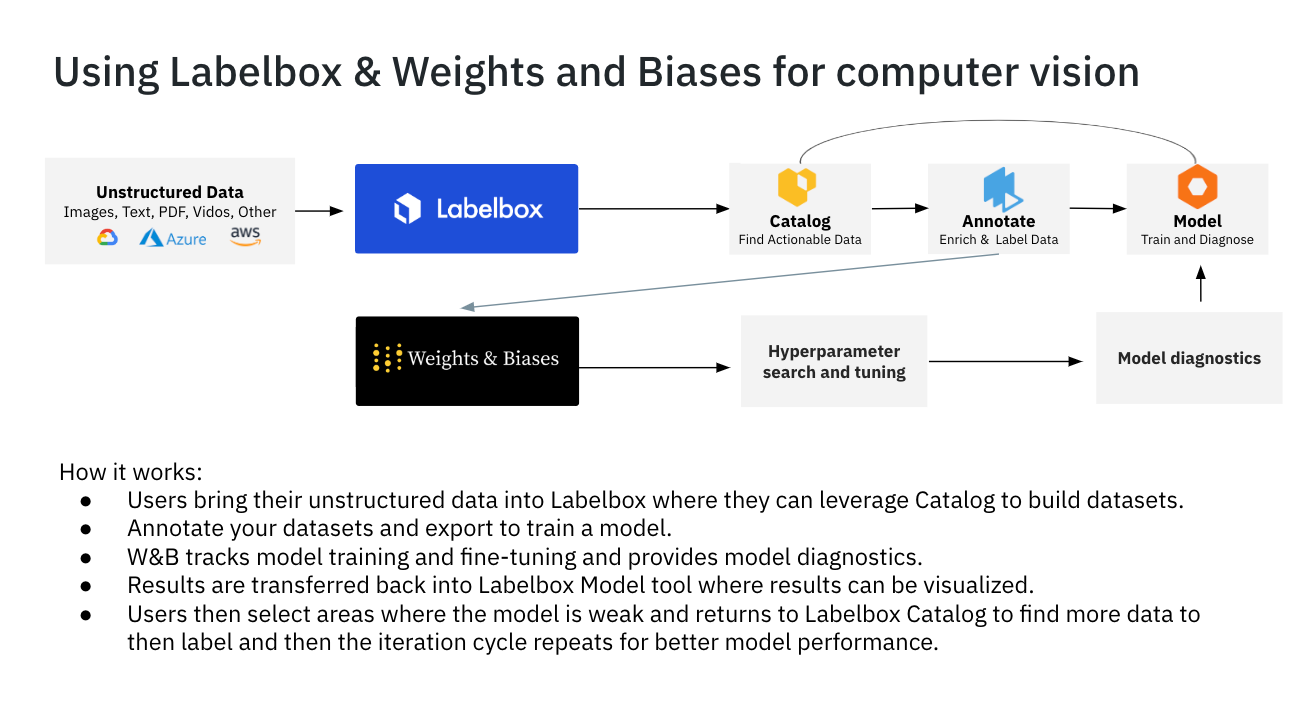
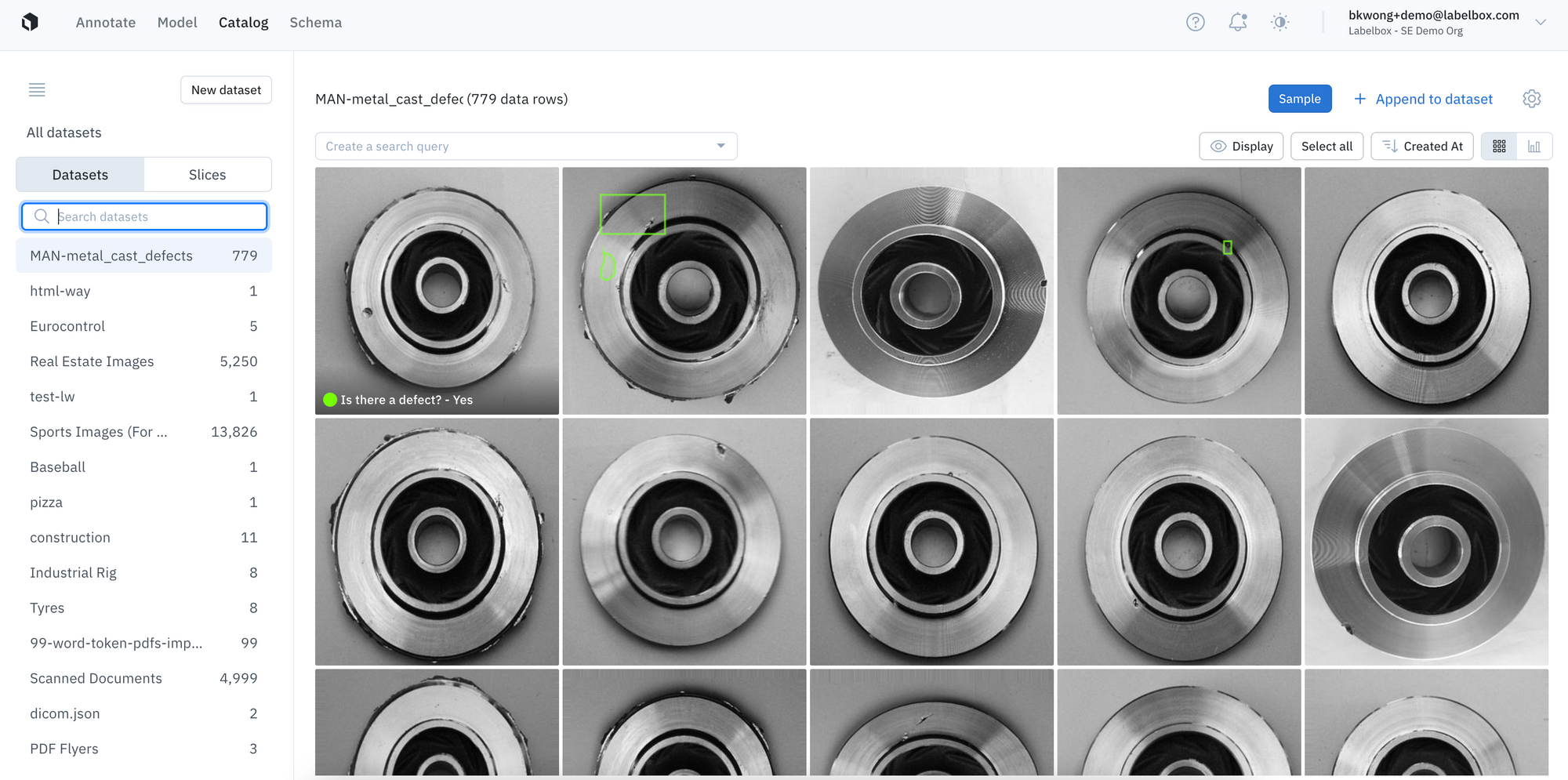
- Begin by first connecting your data source(s) in Labelbox Catalog for easy data visualization and curation.
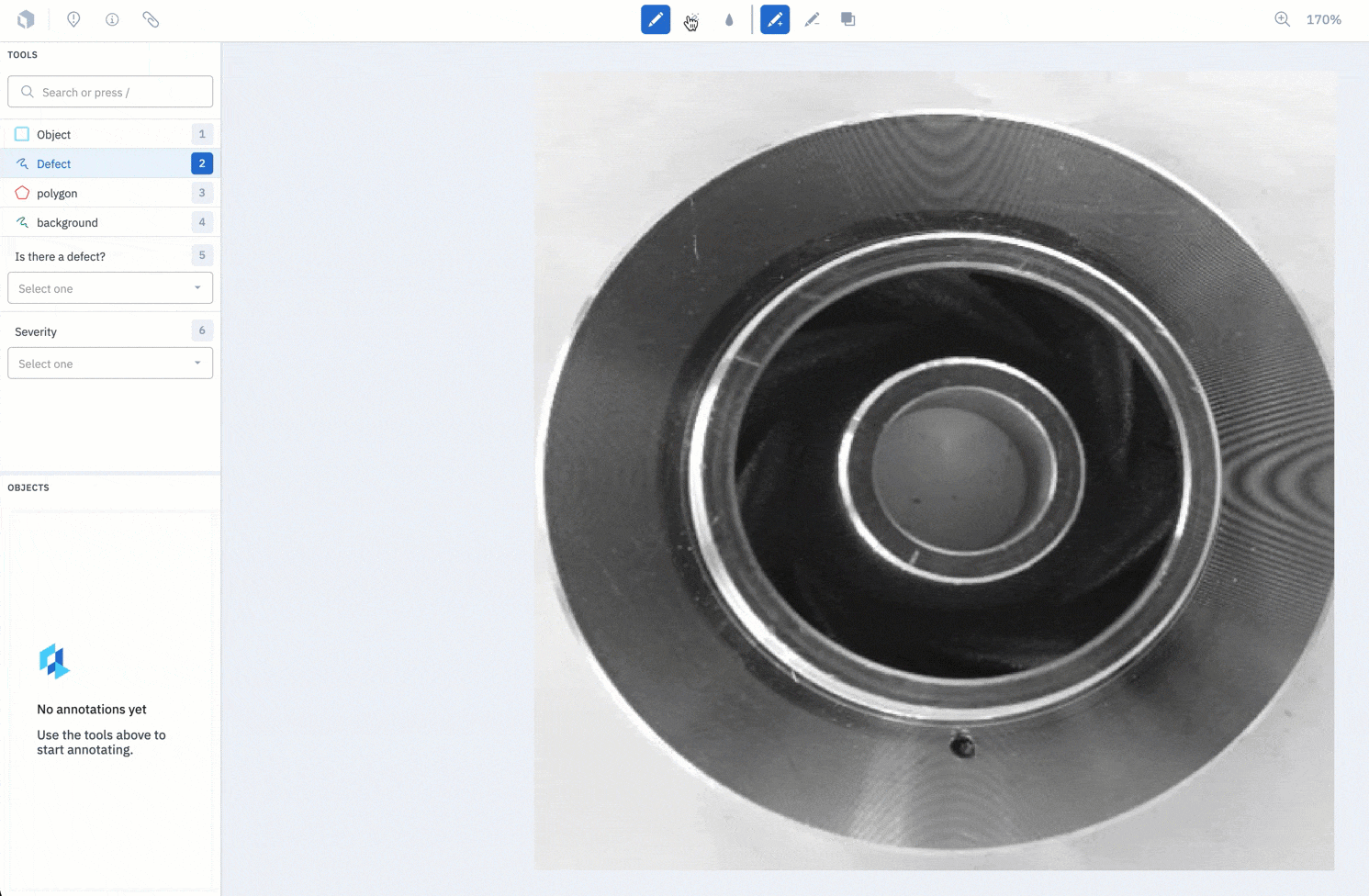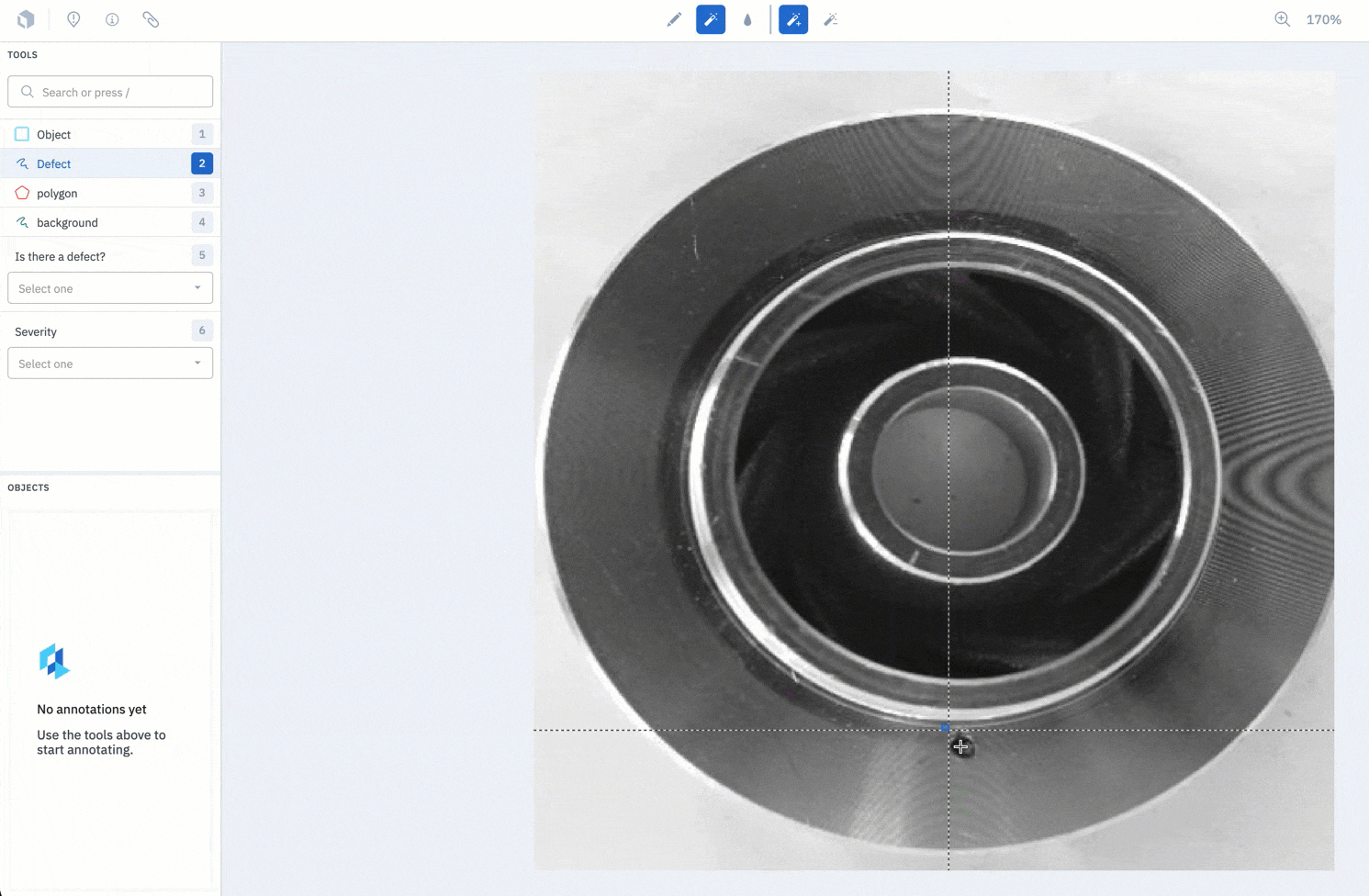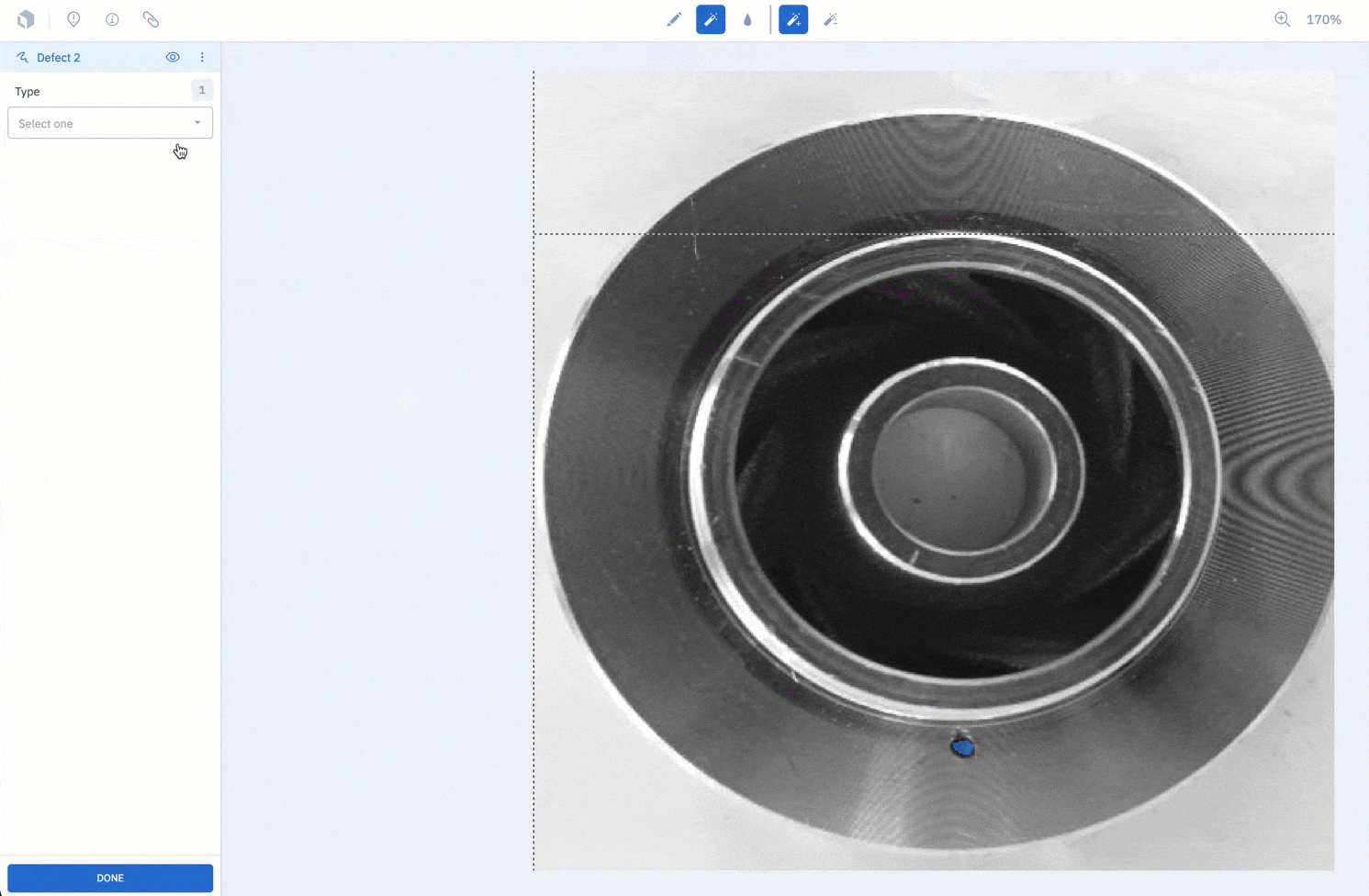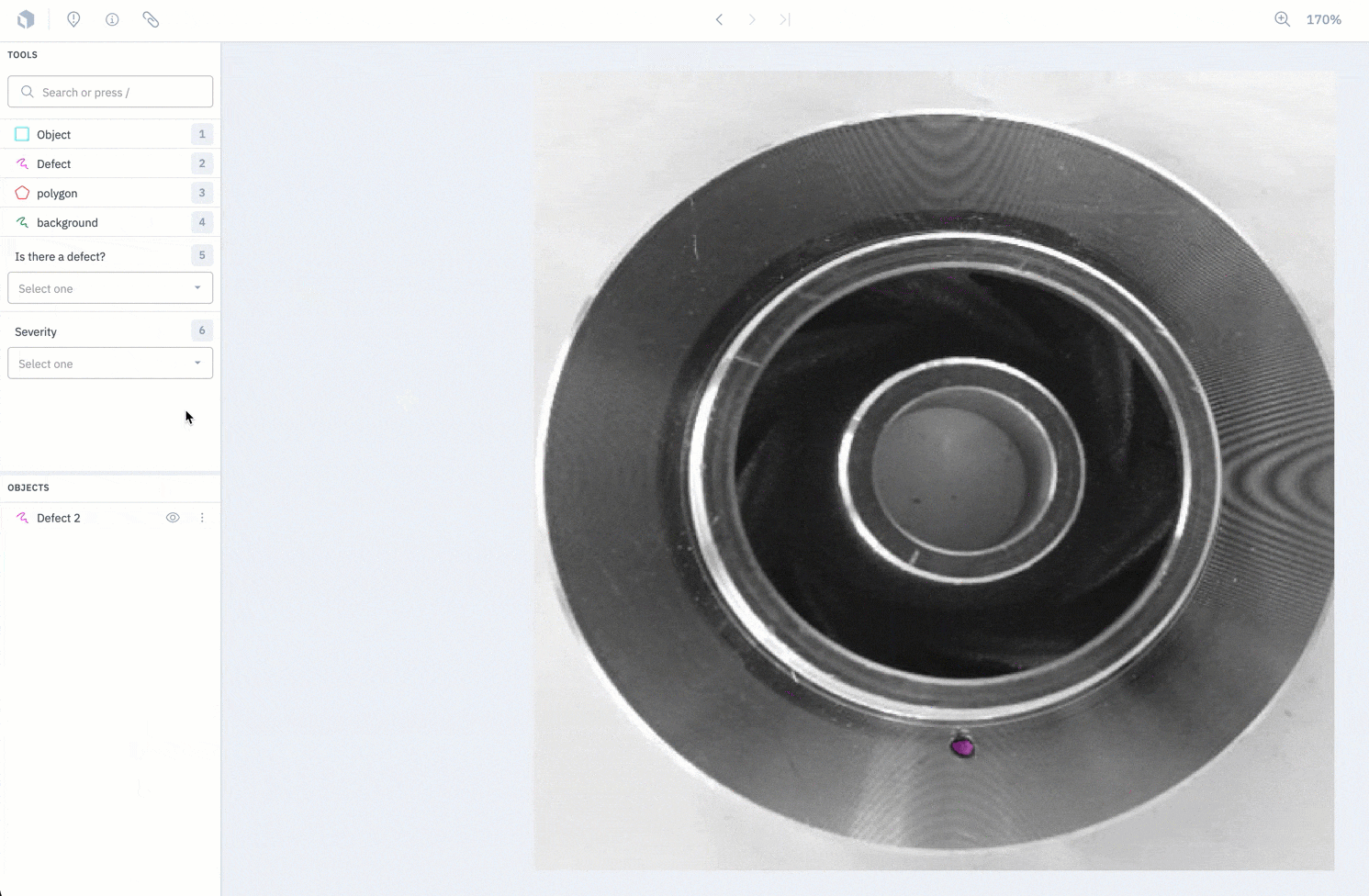
2. Label and review your data in Labelbox Annotate

3. Easily split data into train, test, and validate sets in Labelbox Model.
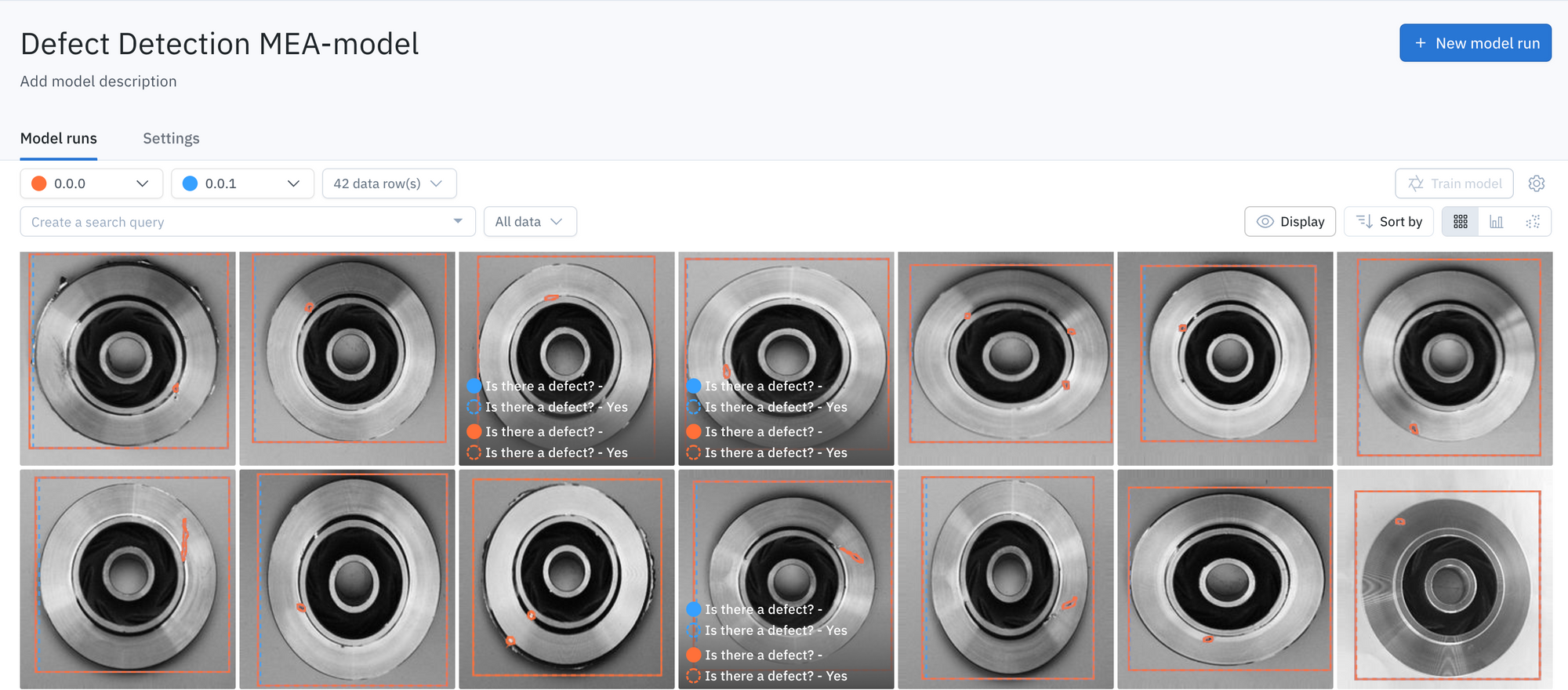
4. Send your data to Weights & Biases from Labelbox for handling model training and hyperparameter search and tuning.
5. Weights & Biases will handle model training and do a hyperparameters search to run a series of model experiments to be compared with each other.
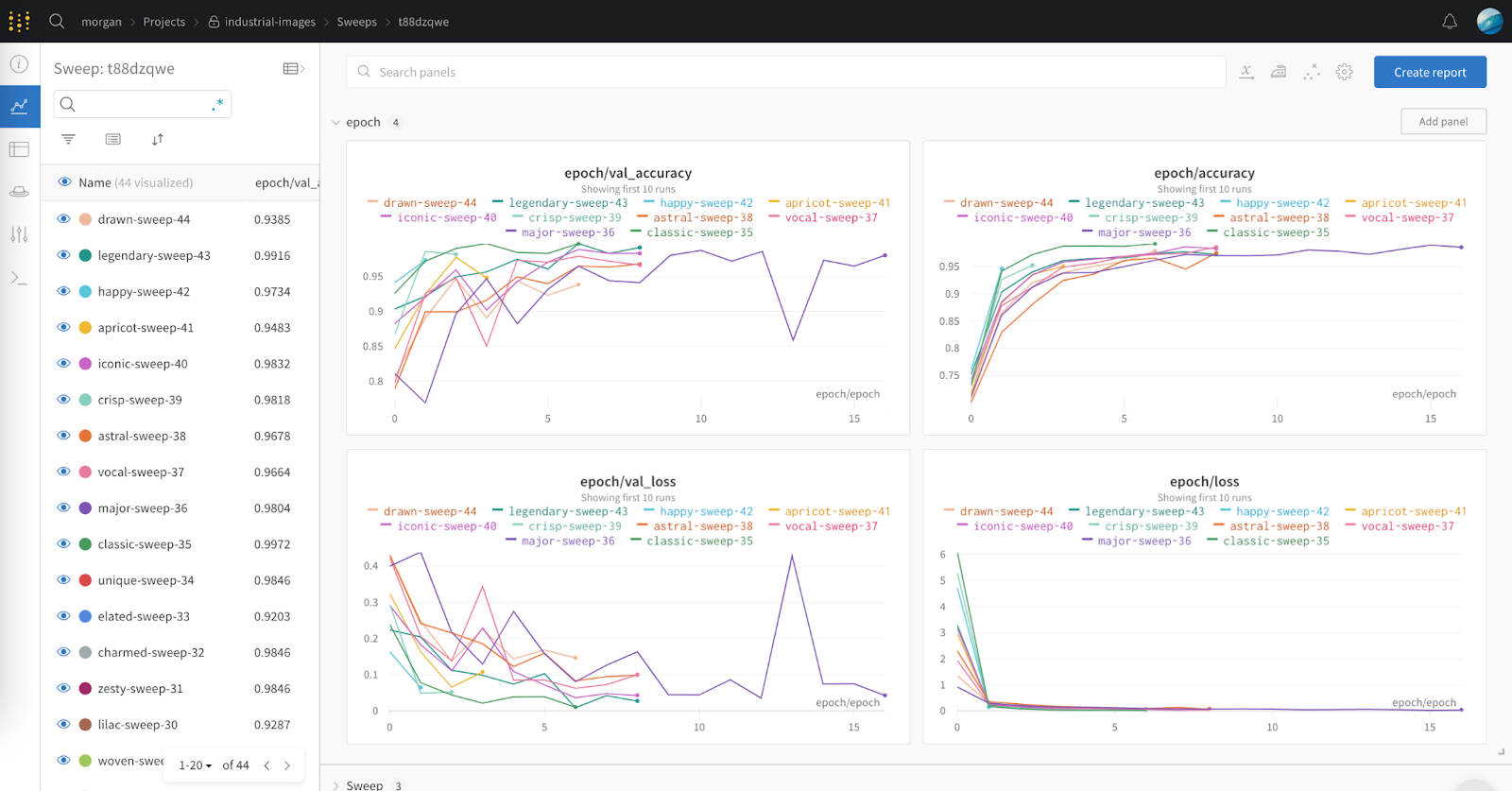
6. Visualize your results in W&B dashboards to quickly diagnose your model performance and create reports in order to share with colleagues and streamline communication.

7. Quickly visualize your results in Labelbox Model to quickly diagnose the data that is related to your model, rapidly query all of your data sources to find data similar to where your model performs poorly (edge cases), and seamlessly queue that data for labeling.
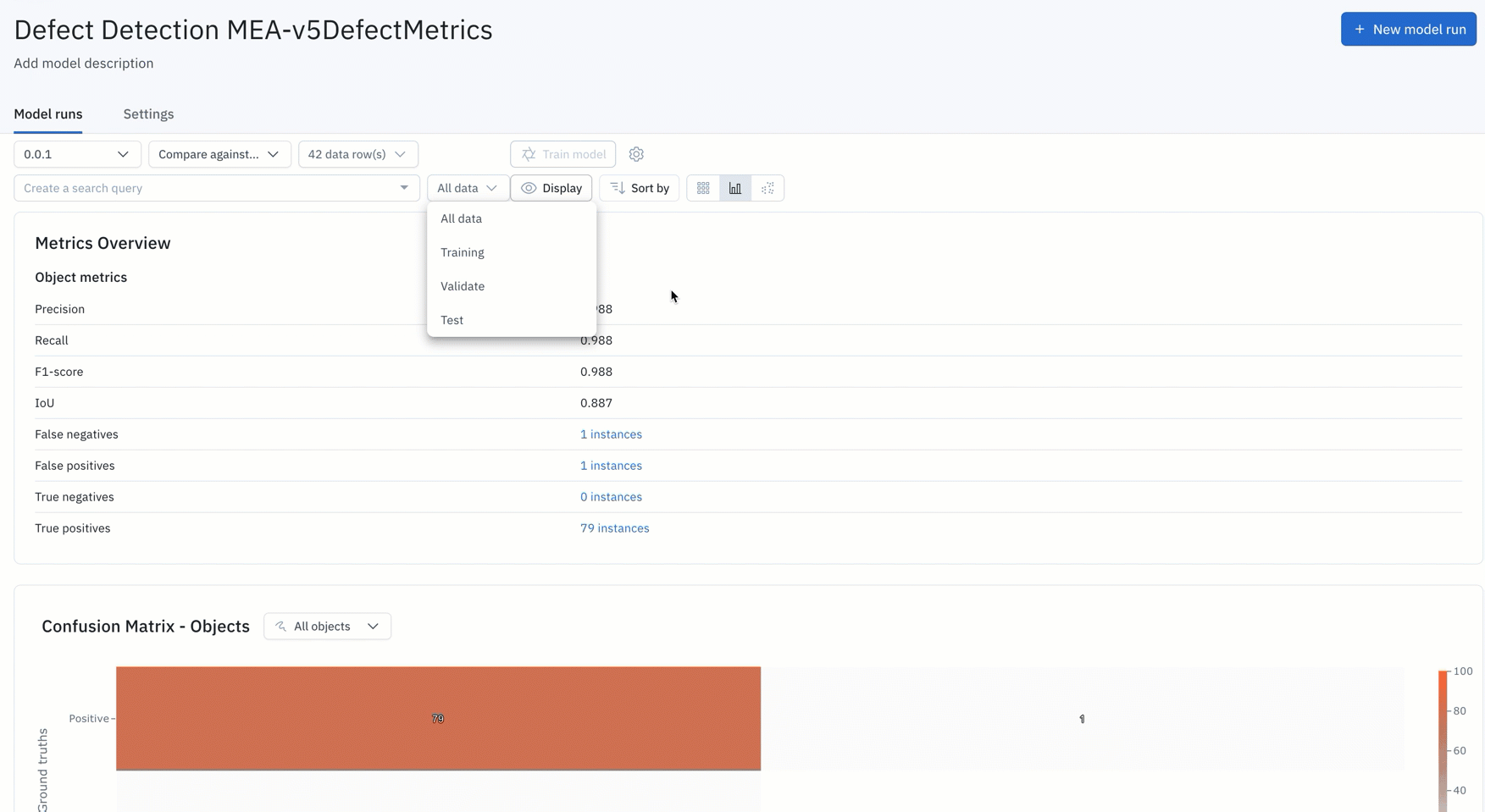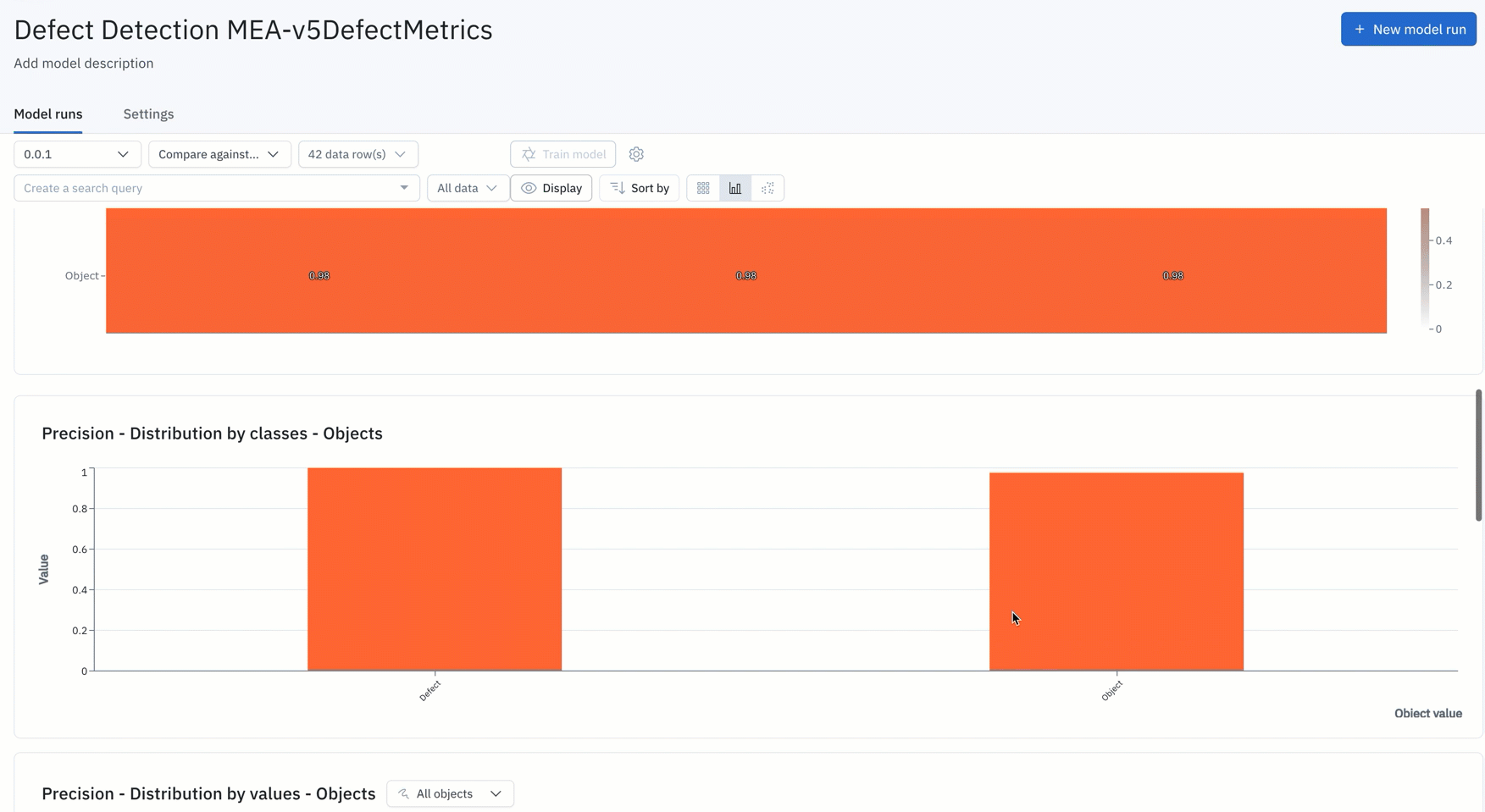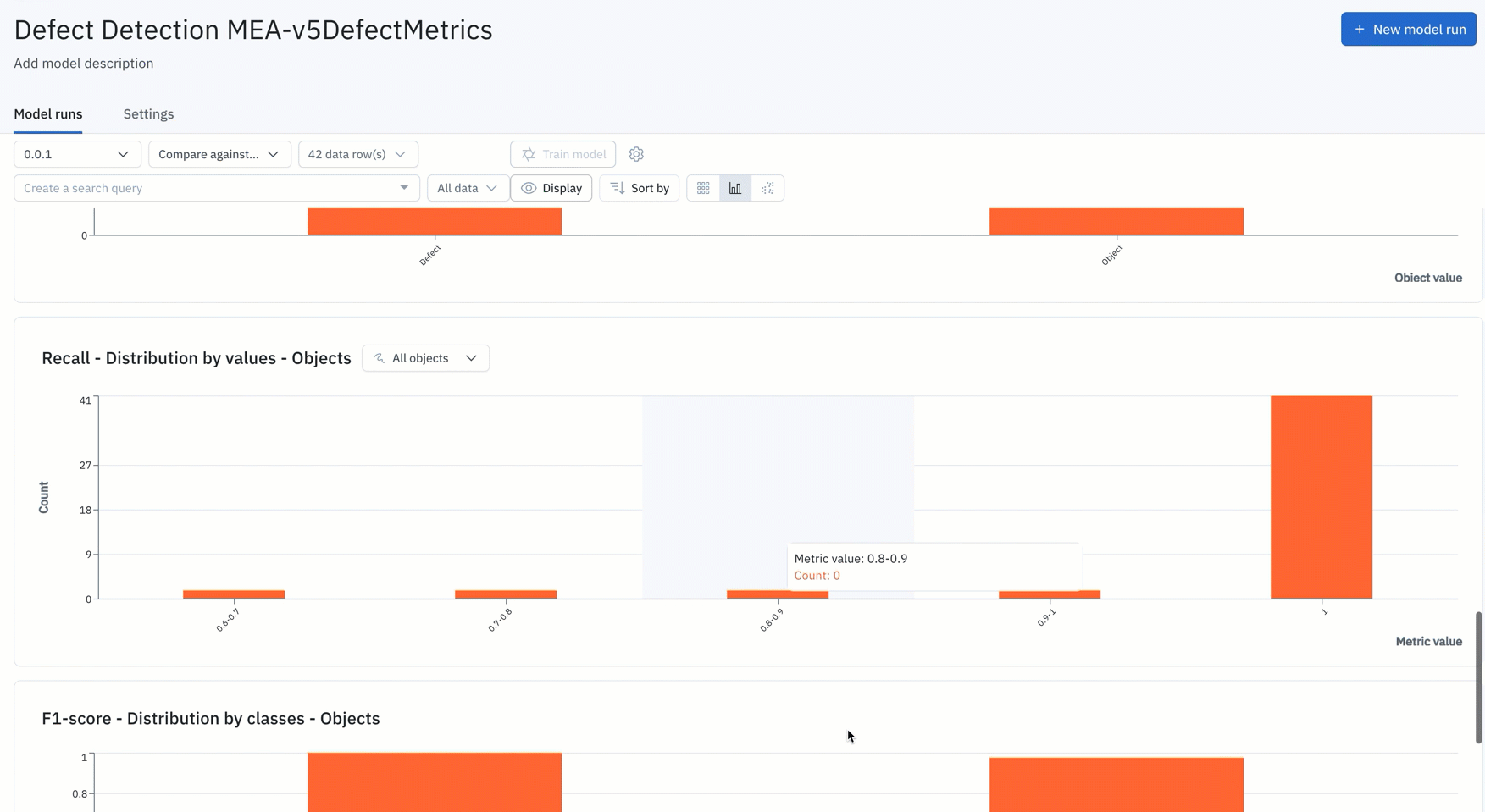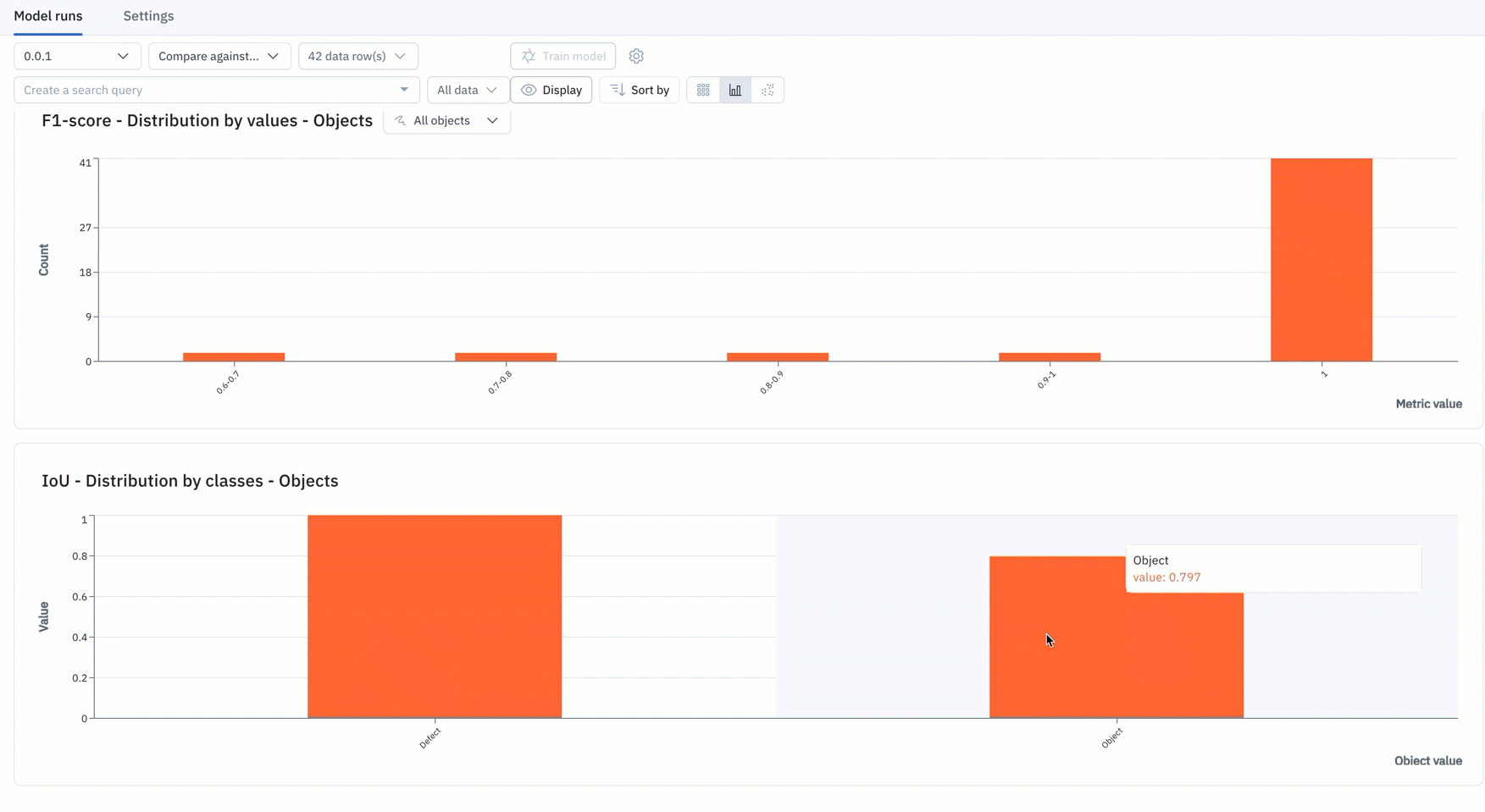
8. Rapidly repeat this iterative model development process until you have a production-worthy model, deploy that model, and continuously monitor
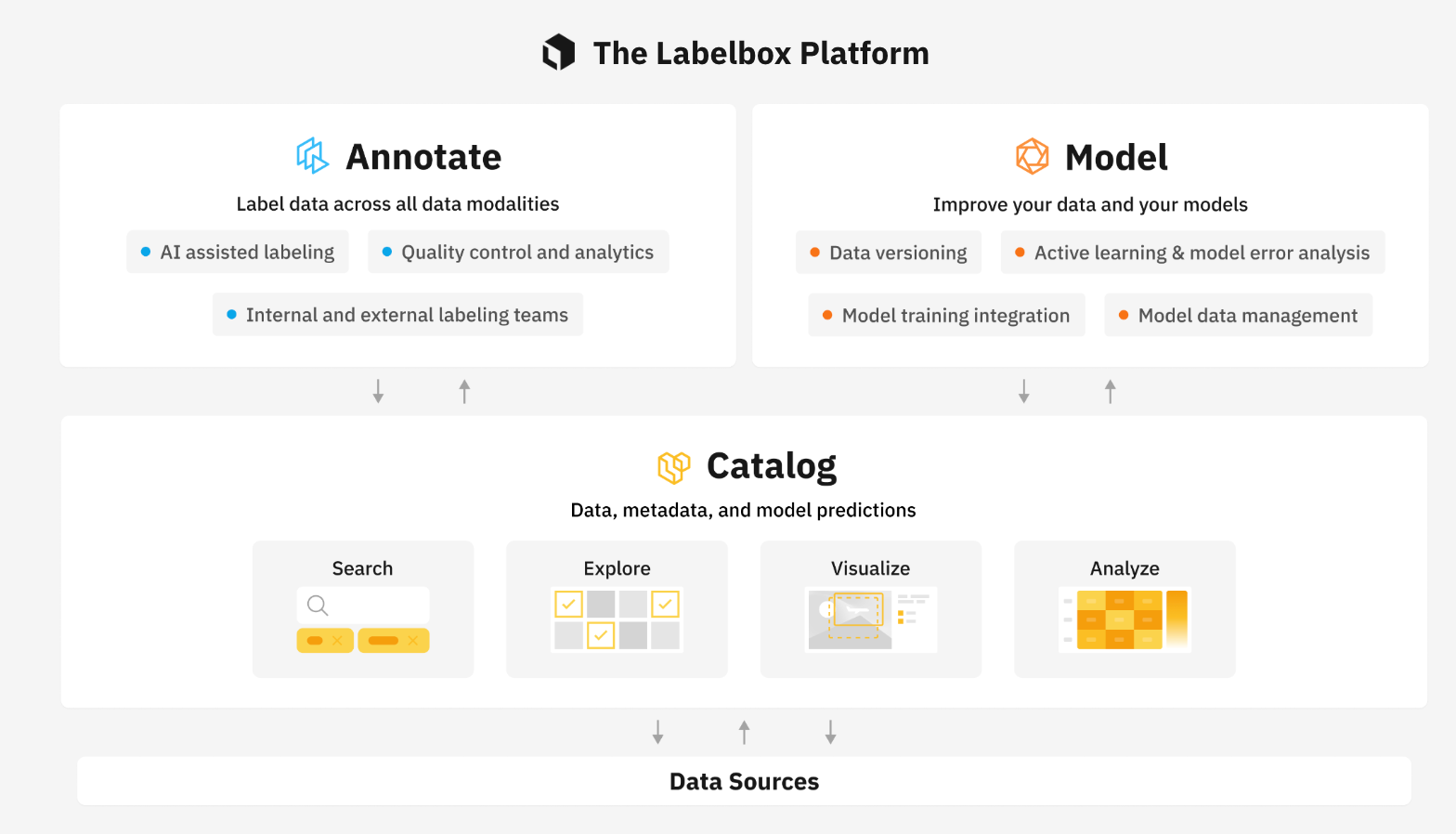
The Labelbox AI platform
One of the biggest mistakes made when creating an AI ecosystem is not integrating a data-centric approach into your MLOps pipeline and serves as a foundational tool for data curation and fast iterative improvement through the model development lifecycle.
Using Labelbox, ML Teams can easily connect to their sources (i.e. file systems, data lake platforms etc.) of unstructured data and quickly begin exploring and prioritizing their data curation efforts using Labelbox Catalog.
Once data has been assessed and prioritized for curation & labeling, a combination of weak supervision and human supervised labeling campaigns are supported with the use of Labelbox Annotate.
Finally, the training data is curated into data splits for test, train and validation and can be easily integrated with a model diagnostics solution (Weights and Biases) to efficiently manage the first of many model training experiments and iterations. This integration is accomplished with the Labelbox Model product.
Weights & Biases’ Model Diagnostics Platform
A model diagnostics platform should offer quick iteration, easy collaboration, and a centralized system of record for ML teams. Because ML development is often closer to a science than traditional software engineering, experimentation is at its core, and tracking the progress of these experiments is critical.
Using Weights & Biases’ experiment tracking, ML teams can easily log their work in a standardized way, knowing that they can return to the results of their experiments days, months, or years later.
Ease of collaboration is critical for ML teams so that they can move quickly, and Weights & Biases’ Reports enables colleagues to share quick notes, training journals, and polished analysis to teammates and managers to unlock decision making and keep the team moving forward.
Finally, knowing that your multiple model checkpoints are securely stored gives you the full picture of which model is best to select for deployment and to send to the W&B Model Registry, where your MLOps or DevOps team can pull it down for deployment.

Conclusion
AI model development is an iterative process, which can be tedious and time consuming without a reliable MLOps pipeline. An efficient model development environment can be broken into two parts: a data-centric workflow for data ingestion, exploration, understanding, and preparation, and a model diagnostics platform for model training, tracking, evaluation, and versioning. Labelbox and Weights & Biases are leading platforms that were designed to complement this iterative process in mind, and when combined, can scale and help AI development teams build better models, faster than ever before.
We'll be releasing more technical guides in the coming weeks on how to best utilize Labelbox and Weights & Biases so stay tuned!


