×![]()

 All blog posts
All blog postsLabelbox•December 19, 2022
How to improve model performance with active learning and weak supervision
AI teams of every maturity level often need to navigate similar sets of hurdles when it comes to improving model performance quickly: the problem of data and the problem of labeling said data.
Data issues are manifold — many teams have oceans of unstructured, inconsistent, diverse data from myriad sources, and mindfully curating a dataset that represents a realistic mix of necessary classes can be a laborious chore. And once the team moves on to getting their data labeled and verified via QA workflows to ensure quality, the time and costs required tends to climb. Even relatively small datasets can take weeks to label, depending on the complexity of the task.
That’s why leading AI teams, such as those at Edelman DxI, Deque Systems, and Advent Health Partners, are tackling these challenges with active learning and weak supervision. Read on to see how these teams have set up their AI development pipelines — and how much they’ve accelerated model performance as a result.
Improving model performance with active learning
Intelligent sampling via embeddings
When the AI team at Edelman DxI, a leading PR firm's research, analytics and data consultancy arm, set out to build an AI-powered platform to help their clients gauge the level of trust their audience had in their brand, figuring out how to pull a representative sample of data quickly became a challenge. Their data sources and types were varied, with articles on multiple blogs and new platforms, social media posts, survey answers, and more. They needed to make sure that both the content itself and its sources were distributed in a way realistic to what the AI model would encounter in production.
To get the right balance of content in their dataset, Edelman DxI built an intelligent sampling workflow, using embeddings taken from an off-the shelf-transformer model to map their data by semantics — text that expressed positive, negative, or neutral sentiments. Though the first version of their model was trained on data sampled from the off-the-shelf model, later iterations were sampled using the model itself, a strategy that refined their sampling and enabled the team to tune the data more specifically to the machine learning model requirements. Later, the team used the same method to sample data from a spread of sources.
When the AI team at Deque set out to build an AI solution to identify accessibility issues on websites and applications, the data they collected was also widely varied. To sort through their data for specific examples to train their object detection model on radio buttons or tables, they used Labelbox Catalog’s similarity search feature, also based on embedding data.
“The Catalog feature in Labelbox has helped us to cluster data points based on design patterns. So one pretty good example of this that we found is lists and forms and tables with embeddings. In the Catalog feature, we can very easily find additional unlabeled data points that are coming in from our production data stream and select those for labeling. So we don't have to label or sort through the thousands of images that we get coming in,” says Noé Barrell, Machine Learning Engineer at Deque Systems.
Hybrid uncertainty sampling and semi-supervised learning
The team at Advent Health Partners took a different active learning approach when faced with the challenge of utilizing data from varied sources and formats. As they set out to build a platform that extracted information from medical records to help hospitals, insurance companies, and other organizations process claims, appeals, and payments faster and more efficiently, they had to train their AI on new classes.
To sample data for the project, they evaluated their existing model over unlabeled samples and calculated the entropy of the output classification vector. The team then used these calculations to group data into two buckets: one with low entropy (meaning that the model was confident on this data), and one with high entropy, where the model had low confidence. The team could then sample data from these two groups, taking only 5-10% of their data from the low entropy group and the rest from the high entropy group, to train the model on new areas.
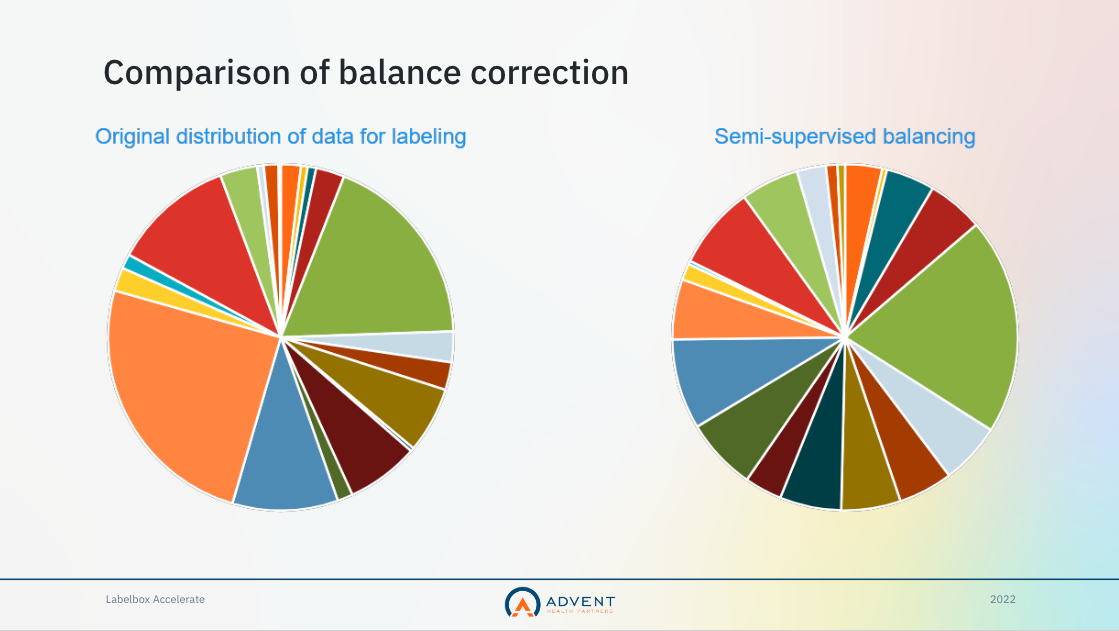
Once they trained the model on this dataset, the team realized that they had a serious class imbalance on their hands: one class was 25% of the dataset, while the least represented classes were only about 7% of the dataset. To correct this, they used the early version of their model to create a semi-supervised model that would balance the classes within their unlabeled data.
Improving model performance with weak supervision
While using active learning techniques to sample data more effectively can reduce the amount of data that needs to be labeled at a time for a specific AI project, actually labeling the data can still require a large amount of time, talent, and resources. This is especially true for data from disparate sources, of various formats, and other added complexity such as fixing data drift and finding rare edge cases.
At Advent Health Partners, the medical records processed by their AI-driven platform are regularly over five hundred pages long, containing image and text files of varying formats. Classifying each page typically takes labelers around thirteen seconds. To lower the time and costs of labeling, the team used model-assisted labeling with Labelbox. They used the semi-supervised model from their active learning workflow to create weak labels, reducing the average time per label to eight seconds.
“This cut a full twenty-five hours off of the amount of time required for labeling tasks, and we found that the labelers had an easier time,” said Robert Coop, Chief AI Officer at Advent Health Partners.
Edelman DxI’s AI team also leveraged weak supervision to integrate domain expertise in the process without requiring experts to do the labeling work. “Labeling is expensive. You can't scale the process if your domain experts are doing the labeling. The challenge is incorporating domain expertise into our ML solutions,” says David Bartram-Shaw, SVP and Global Head of Data Science at Edelman DxI.
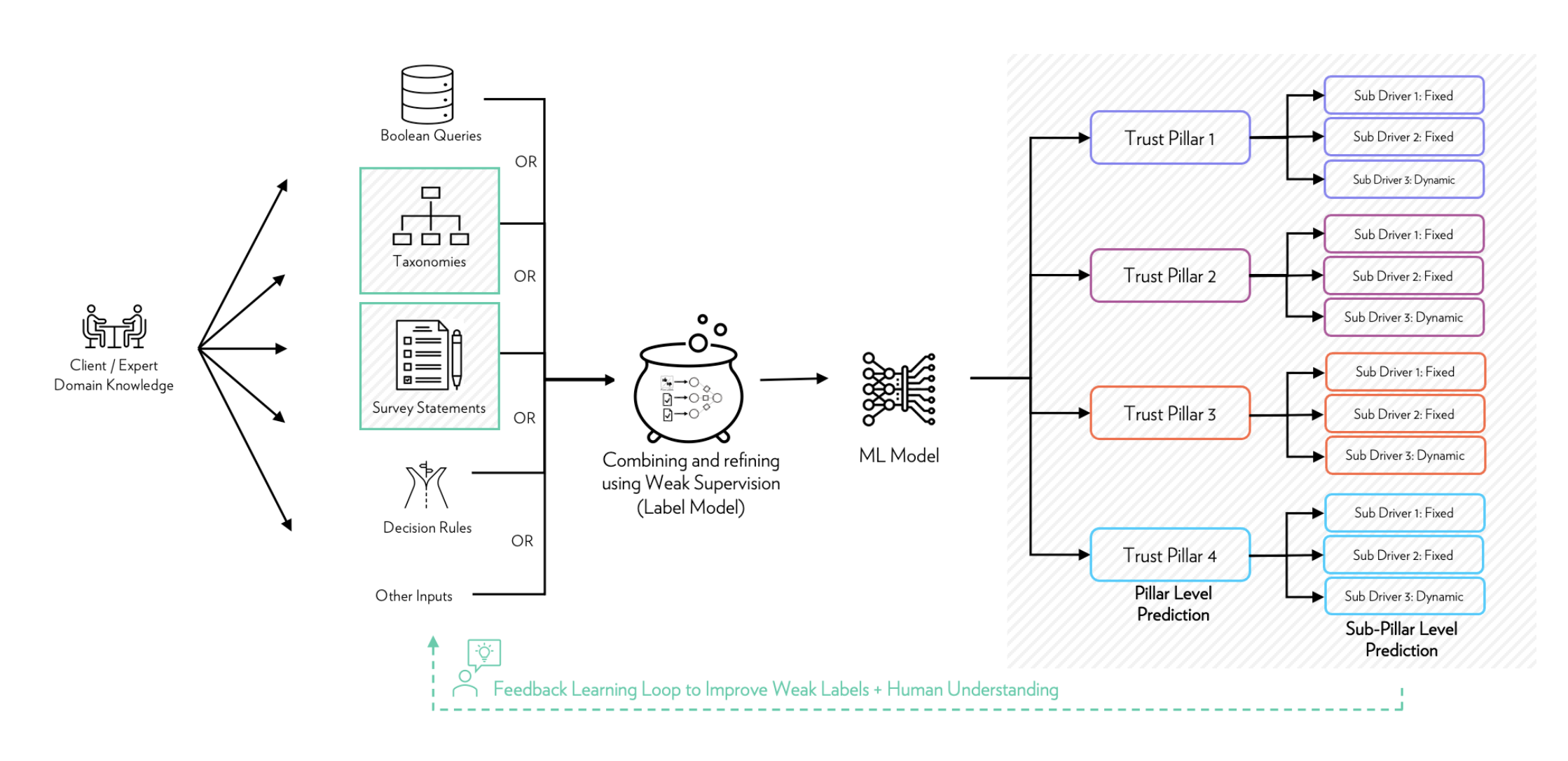
To accelerate and scale their labeling process, the Edelman DxI team set up a weak supervision loop that brought taxonomies and survey statements from clients and other domain experts, boolean queries, and other inputs into a labeling model, whose output was then used as weak labels for the model in training. As the model improved, these weak labels improved.
To learn more about how these leading AI teams leverage active learning and weak supervision strategies in their data engines, watch this session from Labelbox Accelerate 2022 on demand, featuring David Bartram-Shaw of Edelman DxI, Noé Barrell of Deque Systems, and Robert Coop of Advent Health Partners.


