
 All guides
All guidesHow to accelerate image-text pair generation with BLIP-2
Generative AI has taken the world by storm, opening doors to a plethora of applications, from creating realistic images and videos to generating novel text and music. The success of these applications often hinges on the quality and quantity of data used to train the underlying machine learning models, the production of which is often time consuming and costly. As a result, leading AI teams have been innovating on ways to streamline the caption creation process and empower human annotators to work more efficiently without sacrificing quality.
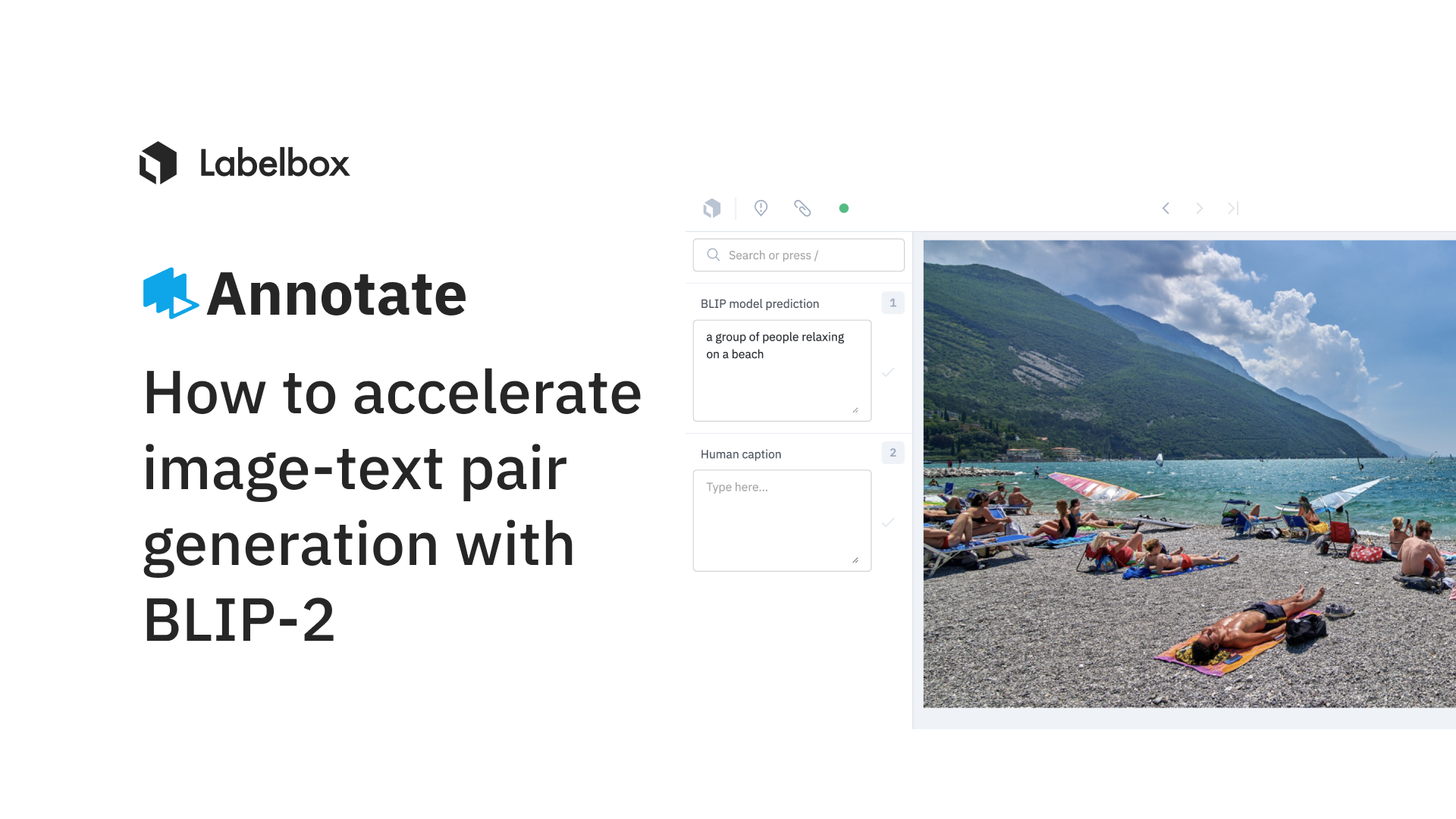
BLIP-2 (Bootstrapping Language-Image Pre-training) is an AI model that can perform various multi-modal tasks like visual question answering, image-text retrieval (image-text matching) and image captioning. It can analyze an image, understand its content, and generate a relevant and concise caption. BLIP-2 helps language models understand images without changing their original structure. It does this by using querying transformer (q-former) that acts as a bridge between the image and the language model.
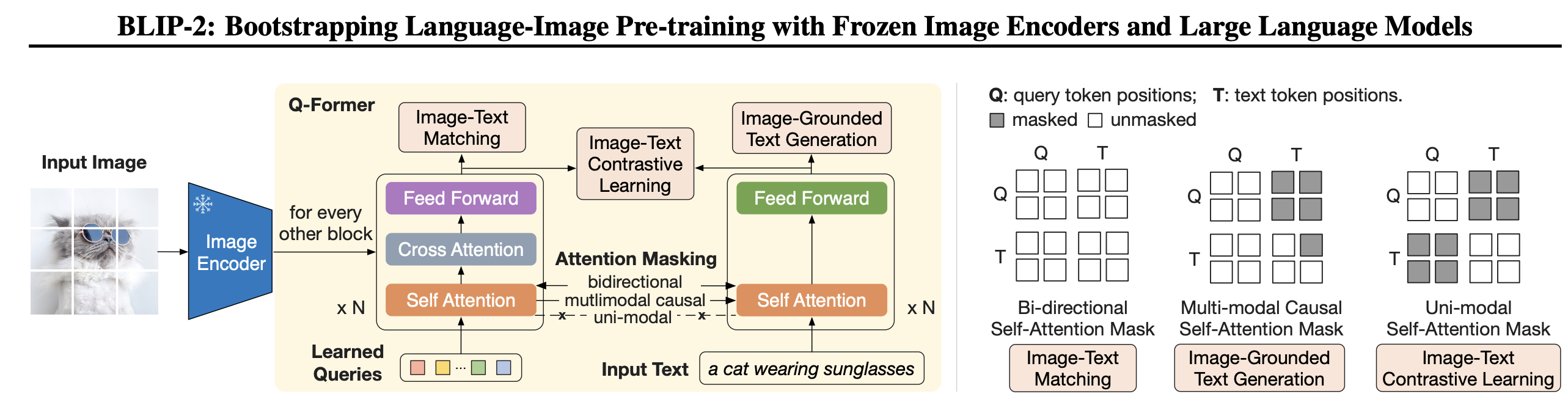
BLIP-2 achieves state-of-the-art performance on various vision-language tasks while being more compute efficient than existing methods. Powered by Large Language Models (LLMs), it can perform zero-shot image-to-text generation based on natural language instructions, enabling capabilities like visual knowledge reasoning and visual conversation.

Overview
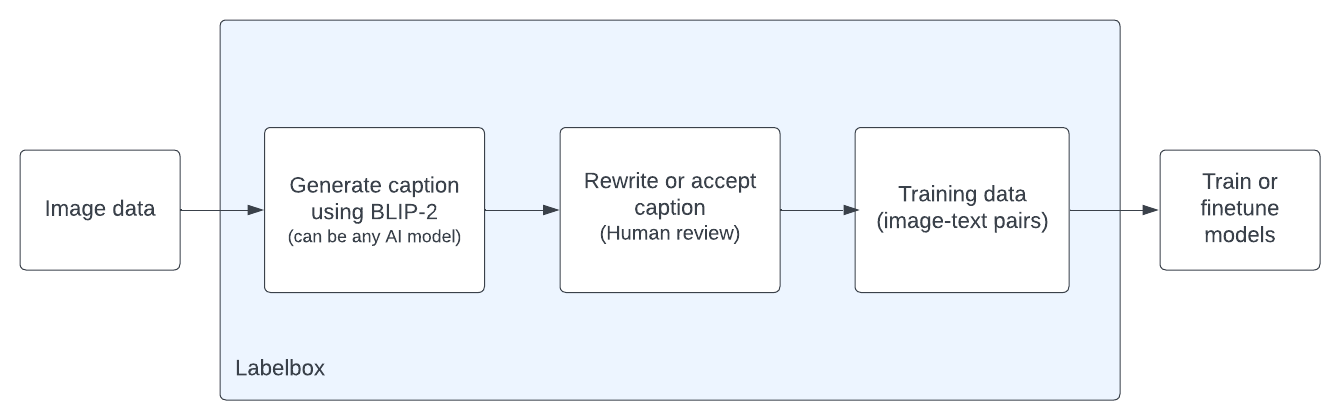
In this guide, we'll explore how to use BLIP-2-generated captions to create pre-labels for images so that a specialized workforce can further improve the image captions. Additionally, you can use any model to make pre-labels in Labelbox as shown here. Labelbox customers using model-assisted labeling have seen 50-70% reductions in labeling costs driven by dramatic reductions in labeling time and complexity. Therefore, using a model like BLIP-2 will further reduce labeling time.
Step 1: Create a project and attach an ontology.
project = client.create_project(name = "BLIP project", media_type=labelbox.MediaType.Image)
project.setup_editor(ontology)
ontology_from_project = labelbox.OntologyBuilder.from_project(project)Step 2: Initialize and load a pre-trained BLIP-2 model.
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16
)
model.to(device)Step 3: Collect inferences to be used as pre-labels.
queued_data_rows = project.export_queued_data_rows()
ground_truth_list = list()
for data_row in queued_data_rows:
url = data_row["rowData"]
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=30)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
text_annotation = labelbox.data.annotation_types.ClassificationAnnotation(
name="BLIP model prediction",
value=labelbox.data.annotation_types.Text(answer = generated_text)
)
ground_truth_list.append(Label(Step 4: Upload pre-labels to your project.
upload_task = labelbox.MALPredictionImport.create_from_objects(client, project.uid, str(uuid.uuid4()), ground_truth_list)
upload_task.wait_until_done()
print(upload_task.errors)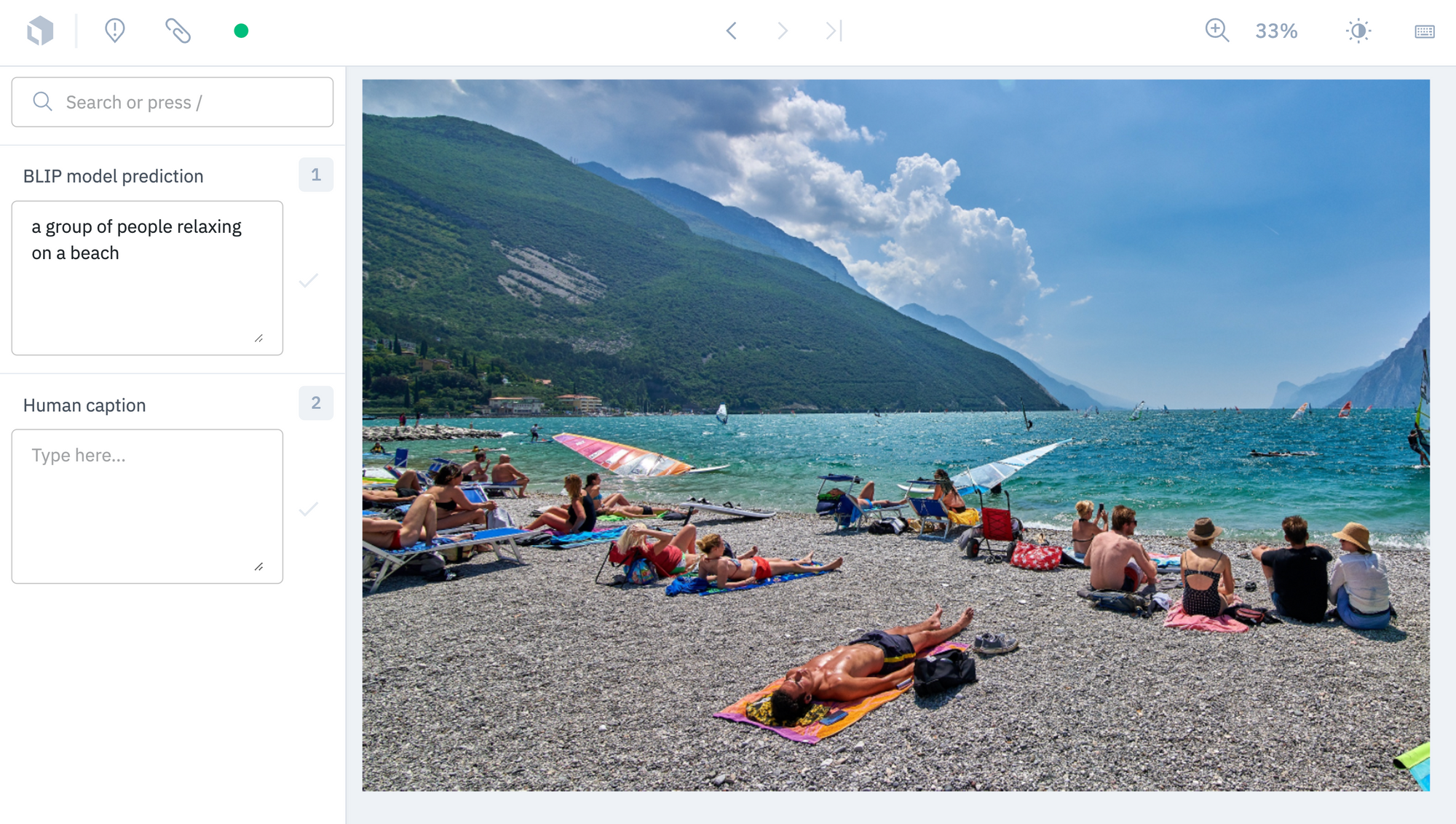
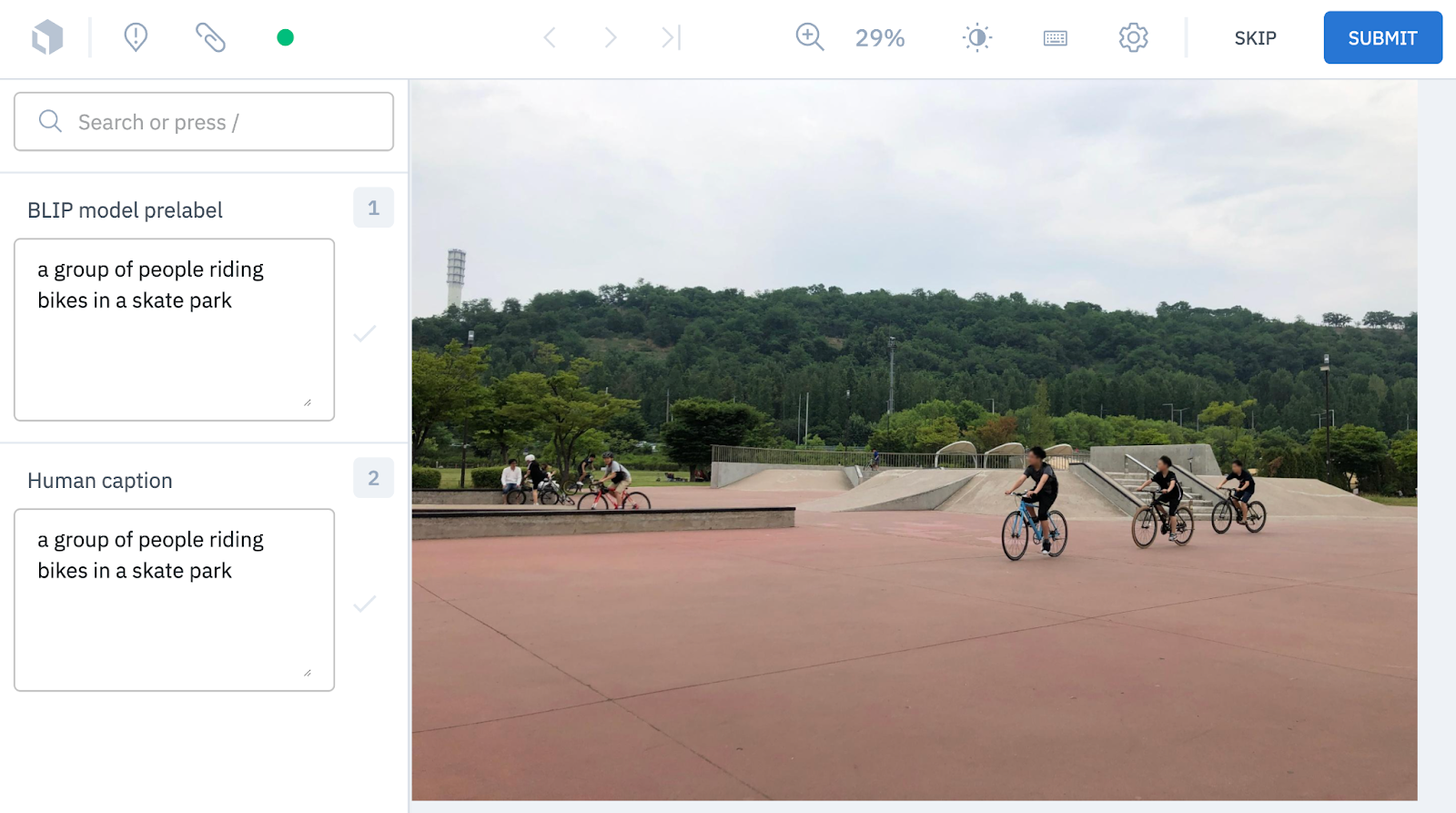
Review labels
After the labels have been annotated, you can use Workflows to create highly customizable, multi-step review pipelines, making your review process more efficient and automated. Workflows offer granular control over how your data rows get reviewed, saving you both time and resources. You can create tasks that enable you to filter based on who created the label, what annotations exist and when the label was created.
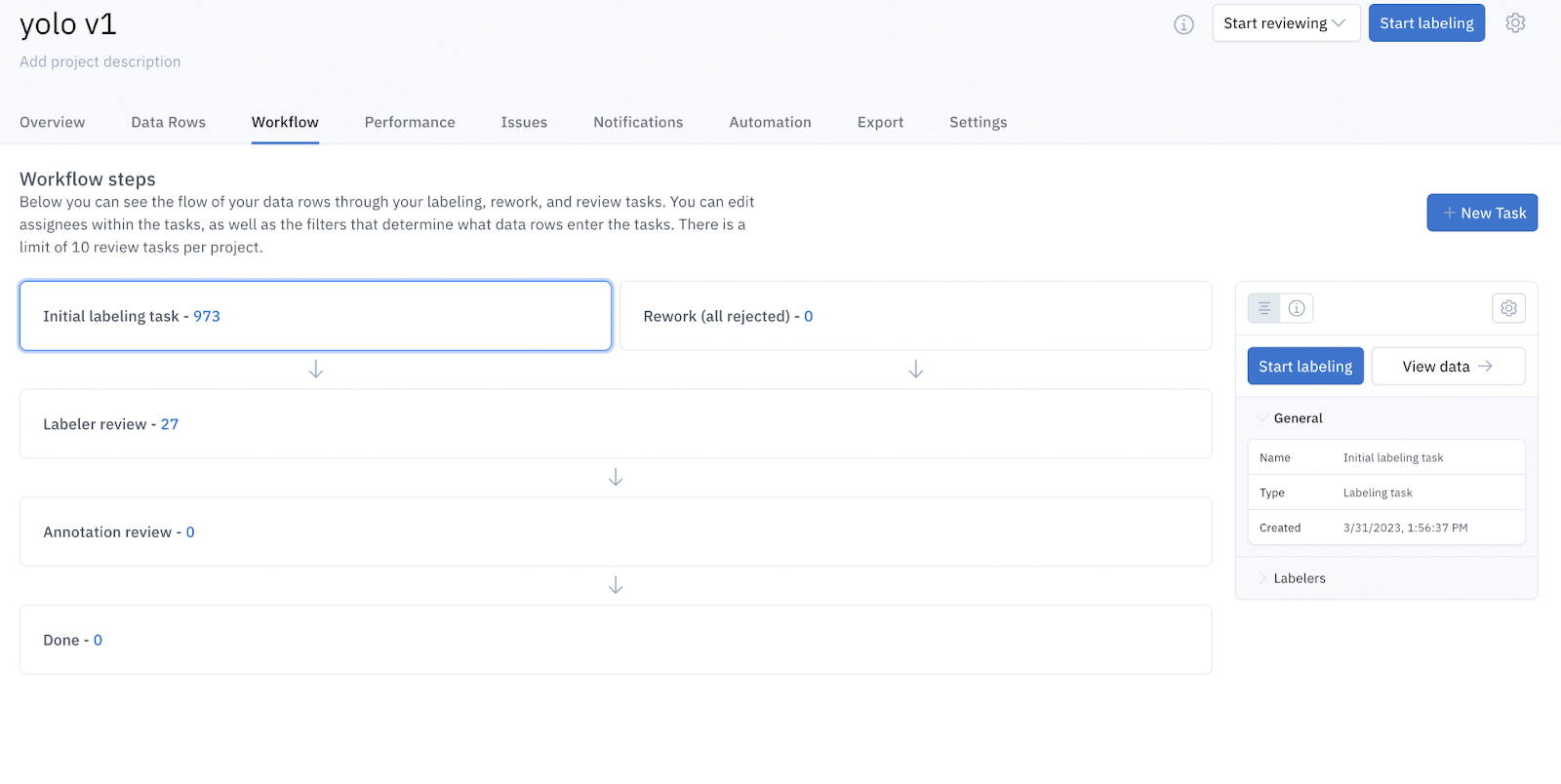
Export labels
After you are done reviewing the labels, you can easily export the annotations as show here.
"annotations": {
"objects": [],
"classifications": [
{
"feature_id": "clhdn79ae0ent076c4h579rxu",
"name": "BLIP model prediction",
"text_answer": {
"content": "a yellow flower with a green background"
}
}Conclusion
By using captions generated by BLIP-2 or inferences by AI models as pre-labels, AI teams can significantly reduce labeling time and costs. To learn more, explore this full script for using the BLIP-2 model to generate pre-labels. These captions can then be amended or approved in Labelbox by labelers. You can also learn more about the BLIP-2 model here and model-assisted labeling here.


