
 All guides
All guidesHow to analyze customer reviews and improve customer care with NLP
Customer reviews have become a critical tool for businesses looking to improve their products, services, and customer satisfaction. In today’s digital world, review sites like Yelp and social media make it easier than ever for customers to share their experiences with the world. Customer care can range in the services and support that businesses provide to their customers before, during, and after purchase. Great customer care can create positive brand experiences that lead to greater loyalty and customer satisfaction. In the ever-evolving world of retail, it also helps keep your business competitive and at the forefront of your customer’s sentiment and desires.
While companies now have access to a wealth of customer feedback data, sifting through all of these reviews can be incredibly time-consuming and manual. By leveraging AI, teams can analyze customer reviews and feedback at scale, to gain insights into common review topics or customer sentiment. This allows businesses to identify common themes and pinpoint areas of improvement to enhance the customer experience.
However, businesses can face multiple challenges when implementing AI for customer care. This includes:
- Data quality and quantity: Improving customer care requires a vast amount of data in the form of customer reviews. Orchestrating data from various sources can not only be challenging to maintain, but even more difficult to sort, analyze, and enrich with quality insights.
- Dynamic review landscape: The changing nature and format of customer review data from multiple sources (e.g webpages, apps, social media, etc.) poses the challenge for businesses to account for continuous data updates and re-training needs.
- Cost & scalability: Developing accurate custom AI can be expensive in data, tools, and expertise. Leveraging foundation models, with human-in-the-loop verification, can help accelerate model development by automating the labeling process
Labelbox is a data-centric AI platform that empowers businesses to transform their customer care through advanced natural language processing. Instead of relying on time-consuming manual reviews, companies can leverage Labelbox’s assisted data enrichment and flexible training frameworks to quickly build AI systems that uncover actionable insights from customer reviews. Tackle unique customer care challenges with AI-driven insights to create more thoughtful and strategic customer interactions.
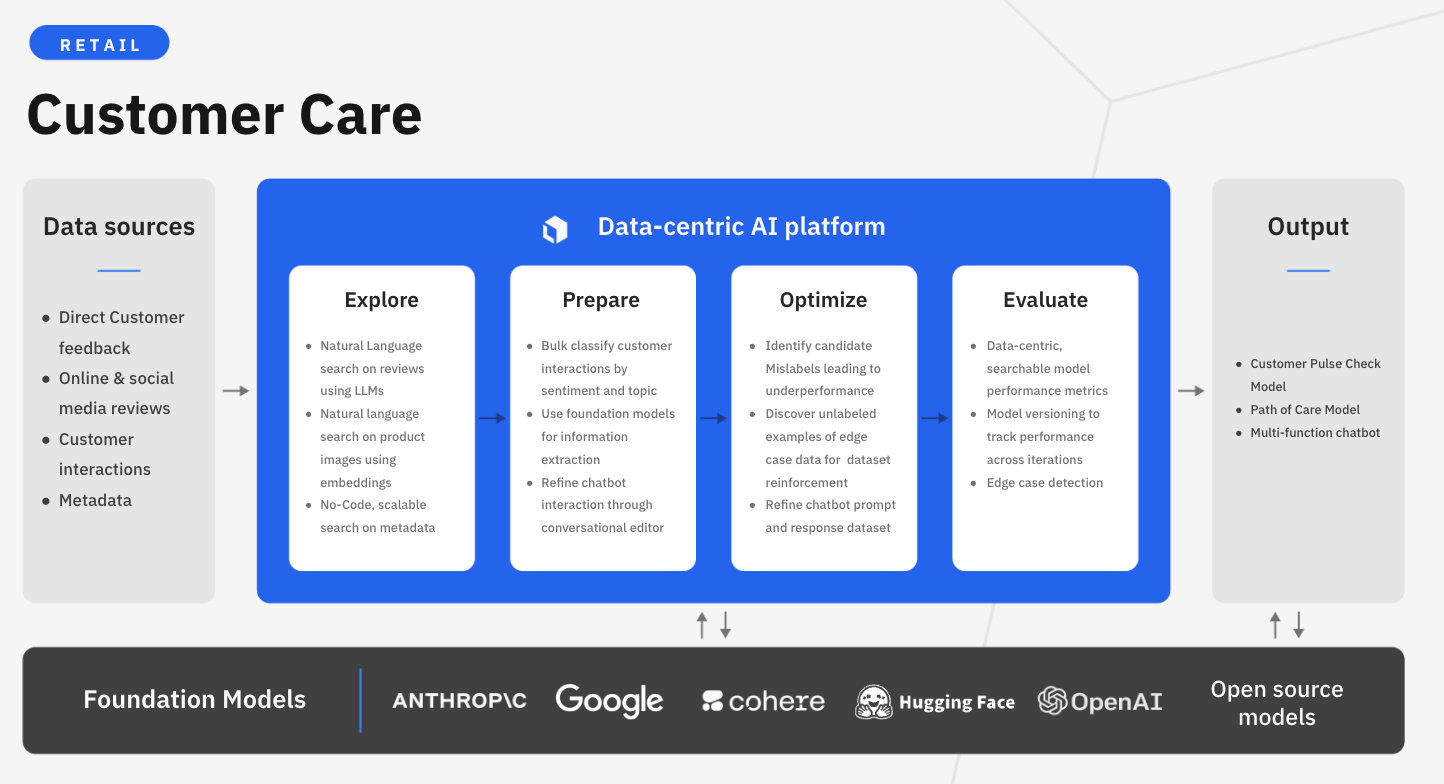
In this guide, we’ll walk through how your team can leverage Labelbox’s platform to build an NLP model to improve customer care. Specifically, this guide will walk through how you can explore and better understand review topics and classify review sentiment to make more data-driven business decisions around customer care initiatives.
See it in action: How to accelerate and train an NLP model to improve customer care
The walkthrough below covers Labelbox’s platform across Catalog, Annotate, and Model. We recommend that you create a free Labelbox account to best follow along with this tutorial.
Part 1: Explore and enhance your data
Part 2: Create a model run and evaluate model performance
You can follow along with both parts of the tutorial below in either:
Part 1: Explore and prepare your data
Follow along with the tutorial and walkthrough in either the Google Colab Notebook or Databricks Notebook. If you are following along, please make a copy of the notebook.
Ingest data into Labelbox
As customer reviews and feedback across channels proliferate, brands want to learn from customer feedback to foster positive experiences. For this use case, we’ll be working with a dataset of customer hotel reviews – with the goal of analyzing the reviews to demonstrate how a hospitality company could gain insight into how their customers feel about the quality of service they receive.
The first step will be to gather data:
For the purpose of this tutorial, we’ve provided a sample open-source Kaggle dataset that can be downloaded.
Please download the dataset and store it in an appropriate location on your environment. You'll also need to update the read/write file paths throughout the notebook to reflect relevant locations on your environment. You'll also need to update all references to API keys, and Labelbox ontology, project, and model run IDs
- If you wish to follow along and work with your own data, you can import your text data as a CSV.
- If your text snippets sit as individual files in cloud storage, you can reference the URL of these files through our IAM delegated access integration.
Once you’ve uploaded your dataset, you should see your text data rendered in Labelbox Catalog. You can browse through the dataset and visualize your data in a no-code interface to quickly pinpoint and curate data for model training.
Search and curate data
You’ll now be able to see your dataset in Labelbox Catalog. With Catalog, you can contextualize your data with custom metadata and attachments to each asset for greater context.
Explore topics of interest
With your data in Labelbox, you can begin to leverage Catalog to uncover interesting topics to get a sense of what customers are talking about from hotel reviews.
- Visualize your data – you can click through individual data rows to get a sense for what customers are writing reviews on
- Drill into specific topics of interest – leverage a natural language search, for example searching “interior design,” to bring up all related reviews related to interior design. You can adjust the confidence threshold of your searches accordingly (this can be helpful in gauging the volume of data related to the topic of interest)
- Begin to surface subtopics or trends within your initial search – for example is the interior design review related to the style of design, attention to detail, or the type of environment created from the interior design
- Easily find all instances of similar examples to data of interest
Create and save data slices
If you have a search query that you’re interested in saving or reusing in the future, you can save it as a slice. You can construct a slice by using one or more filters to curate a collection of data rows. Users often combine filters to surface high-impact data and then save the results as a slice.
In this example, we’ve surfaced reviews on the topic of breakfast that all talk about the value and price of the hotel’s breakfast. We can save this as a slice for future reference (“Breakfast_value”) and as we ingest more data that matches the slice’s criteria, they will automatically get filed into the slice.
Create an ontology
After we’ve explored our data, we now have a better understanding of what topics exist in our dataset and can create our ontology. Ontologies can be reused across different projects and they are required for data labeling, model training, and evaluation.
To create a new ontology:
1) Navigate to the ‘Schema’ tab
2) Hit ‘Create new ontology’
3) Select the media type that you wish to work with – for this use case ‘Text’
4) Give your ontology a name
5) Add objects and classifications based on you use case
6) Objects are named entities
- Person’s name
- Location
7) Classifications
- Review sentiment such as positive or negative (radio)
- Review topics such as breakfast, dinner, location, staff, interior design (checklist)
- Add sub-classifications as desired
8) Save and create your ontology
After creating an ontology, you can begin labeling your data to fine-tune or train a model.
Label data of interest
With Labelbox, you can label your data in the following ways:
1) Internal team of labelers: your team can start labeling directly in the Labelbox editor, utilizing automation tools and maintaining quality with custom workflows to maintain human-in-the-loop review.
2) External team of expert labelers with Labelbox Boost: leverage our global network of specialized labelers for a variety of tasks.
Workforce Boost provides a collaborative platform for labeling services in a self-serve manner — this is great for teams that don’t have the technical expertise to build a machine learning system yet are looking for an easy-to-use technology to get a quick turnaround on quality training data. You can learn more about our Boost offerings here.
3) Create pre-labels with foundation models
In addition to creating pre-labels for classification projects, you have the ability to send model predictions as pre-labels to your labeling project. This can be done in one of two ways:
- Model-assisted labeling: Import computer-generated predictions (or simply annotations created outside of Labelbox) as pre-labels on an asset. The imported annotations will be pre-populated in the labeling editor and a human can correct or verify and submit the prediction as ground truth.
- Model Foundry: Automate data workflows, including data labeling with world-class foundation models. Leverage a variety of open source or third-party models to accelerate pre-labeling and cut labeling costs by up to 90%.
Pre-label data with Model Foundry
Model Foundry acts as the copilot to create your training data – instead of going into unstructured text datasets blindly, you can use pre-existing LLMs to pre-label data or pre-tag parts of it, reducing manual labeling efforts and cost.
1) Select data you wish to label in Catalog
3) Hit "Predict with Model Foundry"
3) Choose a foundation model
- You can select a foundation model based on your use case to have the model take a first pass at labeling your data
- These pre-labels can be verified with human-in-the-loop review in Labelbox Annotate
- For this use case, we’ve selected the GPT-4 model
4) Configure the model’s settings
- Select the previously created ontology in the earlier part of the tutorial
- Labelbox will auto-generate a prompt based on your ontology and use case – in this case we wish to classify the sentiment (positive or negative) and classify a topic with one or more options (breakfast, dinner, location, staff, room, facilities, value for money, or interior design)
5) Generate preview predictions
- Before submitting the model run, you can generate prediction previews to understand how the model will perform
- It is recommended that you preview some predictions to confirm the model parameters are configured as desired
- Based on the preview, you can then make any adjustments to the settings or choose to submit the model run as-is
6) Name and submit the model run
7) View the model run in the Model tab to explore results
- Once your model run is complete, you navigate to the Model tab
- Explore the model’s results and click into each data row to dig deeper into the model’s predictions
- For this example, we can see that there are instances where GPT-4 has correctly tagged named entities and identified sentiment
Once you’ve evaluated and are satisfied with GPT-4’s predictions, you can send them to a labeling project in Labelbox Annotate.
Add a batch to a labeling project as pre-labels
Before you can send these model predictions to a labeling project as pre-labels, you need to create a labeling project.
Create a new labeling project
1) Navigate to the Annotate tab
2) Create a ‘New project’
3) Select the project type – in this case we want to create a ‘Text’ project
4) Name your project
5) Attach your model’s ontology (created in a previous step)
Once you’ve created your labeling project and configured the ontology, head back to the Model tab to send your batch of data with pre-labels to that labeling project.
1) Highlight all data rows of interest
2) Select ‘Manage selection’ > ‘Add batch to project’
3) Select the appropriate project that you created in the above step
4) You can give the batch a priority (from 1-5)
5) Select the appropriate model run of the predictions you wish to send
6) You can explore and select the various tags that have been applied and uncheck those that aren’t of interest
7) Submit the batch
You can now navigate back to your project in Annotate and hit ‘Start labeling’.
Verify data quality with custom workflows
Rather than starting from scratch, your internal or external team of labelers can now see predictions from the Model Foundry run. From here, you can validate or edit predictions as necessary and submit data rows to create ground truth labels.
As you begin to progress through your data rows, you’ll notice data rows that are initially marked up and reviewed by labelers in the ‘Initial review’ task (for your reviewers to verify and approve), with all submitted data rows falling into ‘Done’.
You can create customizable, multi-step review and rework pipelines to drive efficiency and automation for your review tasks. Set a review task based on specific parameters that are unique to your labeling team or desired outcome.
- Initial labeling task: reserved for all data rows that have been queued for labeling
- Initial review task: first review task for data rows with submitted labels
- Rework task: reserved for data rows that have been rejected
- Done task: reserved for data rows that have a) moved through their qualified tasks in the workflow or b) did not qualify for any of the tasks
Once all data rows have been reviewed and moved to the ‘Done’ step, you can begin the model training process.
In Part 1 of this tutorial, we have looked at how we can leverage Catalog to understand the topics that exist within your dataset and construct an appropriate ontology. To accelerate our initial labeling job, we leveraged Model Foundry as part of our model-assisted labeling pipeline to use pre-labels from GPT-4 to our labeling workforce for validation. Those initial annotations can be exported via a model run and can be used to train or fine-tune a model outside of Labelbox.
Part 2: Train or fine-tune a model and evaluate model performance
Follow along with the tutorial and walkthrough in either the Google Colab Notebook or Databricks Notebook. If you are following along, please make a copy of the notebook.
Train a custom model on a subset of data outside of Labelbox
In the previous step, we leveraged Model Foundry to create pre-labels that were passed through Annotate for review with human-in-the-loop validation. Now that we have our appropriate annotation data, we can train a series of initial models on sentiment, topic classification, and named entity recognition.
Model training occurs outside of Labelbox. Labelbox Model works with any model training and inference framework, major cloud providers (AWS, Azure, GCS), and any data lake (Databricks, Snowflake).
You can reference this step (Databricks) or this step (Google Colab) in either notebook.
Bring the trained model’s predictions back into a model run
Once the model has been trained, you can create an inference pipeline that leverages each model to classify different attributes for review. We can then leverage this for two things:
- Run inference on the model run dataset and upload it to Labelbox for evaluation
- Run inference on our remaining dataset and use the predictions for model-assisted labeling, to be refined in the platform and used to accelerate labeling efforts
Please follow this step (Databricks) or this step (Google Colab) to create an inference pipeline and to upload predictions to the model run and evaluate it against ground truth.
After following the notebook, you’ll be able to compare ground truth (green) versus the model’s predictions (red) for sentiment and topic.
Evaluate and diagnose model effectiveness
Diagnose model performance with model metrics
In addition to visualizing the difference between model predictions and ground truth, you can click into the ‘Metrics’ view to get a better sense of how your model is performing.
- Use the "Metrics view" to drill into crucial model metrics, such as confusion matrix, precision, recall, F1 score, and more, to surface model errors.
- Model metrics are auto-populated and interactive. You can click on any chart or metric to open up the gallery view of the model run and see corresponding examples
For example, we can click into false negatives or false positives to narrow down situations where there might be false positives – where ‘negative’ sentiment is predicted whereas ground truth sentiment is ‘positive’.
After running error analysis, you can make more informed decisions on how to iterate and improve your model’s performance with corrective action or targeted data selection.
Curate high-impact data to drastically improve model performance
Once you’ve identified an example of a corner-case where the model might be struggling, you can easily leverage Catalog to surface similar unlabeled examples to improve model performance.
- Select any corner-cases and select "Find similar in Catalog" from the Manage Selection dropdown. This will bring you back into Catalog and will automatically surface all similar data rows (both labeled and unlabeled) to the selected example.
- To only surface unlabeled reviews that you can send to your model for labeling, you can filter on the "Annotation is" filter and select "none." This will only show unlabeled text reviews that are similar to the selected corner case.
- Select all reviews that apply and select "Add batch to project"
Use model predictions as model-assisted labeling pipeline
Once you’ve filtered for and have selected reviews that you wish to label you can "Add batch to project" to send them to your labeling project in Annotate.
1) Name your batch
2) Select your labeling project from the dropdown
3) Include model predictions (from your model run) – this will perform better than the initial GPT-4 run with Model Foundry since it has been trained on your custom data
4) Select or uncheck any predictions as desired
5) Submit the batch
When you return to Labelbox Annotate, you will now see the original batch that we added at the start of the project, as well as the newly added batch ready for labeling.
Rather than starting from scratch, similar to the predictions created by GPT-4 in Model Foundry, your labelers will now see the custom model predictions and validate them with human-in-the-loop review in the same manner. This workflow helps accelerate model iterations, allowing your team to bring in the latest model prediction as pre-labels for your project to reduce the amount of human labeling effort required to create ground truth labels.
With new high-impact data labeled, you can retrain the model and can track model improvements across various runs for comparison and how this has affected model performance.
Customer reviews and feedback data represent an invaluable yet untapped opportunity for businesses. Manually analyzing this growing mountain of data is no longer practical. Instead, forward-thinking companies are turning to AI to efficiently sift through and extract actionable insights from reviews.
Natural language processing can help identify customer sentiment, pain points, and unmet needs. By leveraging AI to tap into this feedback treasure trove, businesses can drive measurable improvements in customer satisfaction, retention, and advocacy. They can refine products, enhance user experiences, and preemptively address concerns.
Labelbox is a data-centric AI platform that empowers teams to iteratively build powerful product recommendation engines to fuel lasting customer relationships. To get started, sign up for a free Labelbox account or request a demo.


