
 All guides
All guidesBest practices for successful image annotation
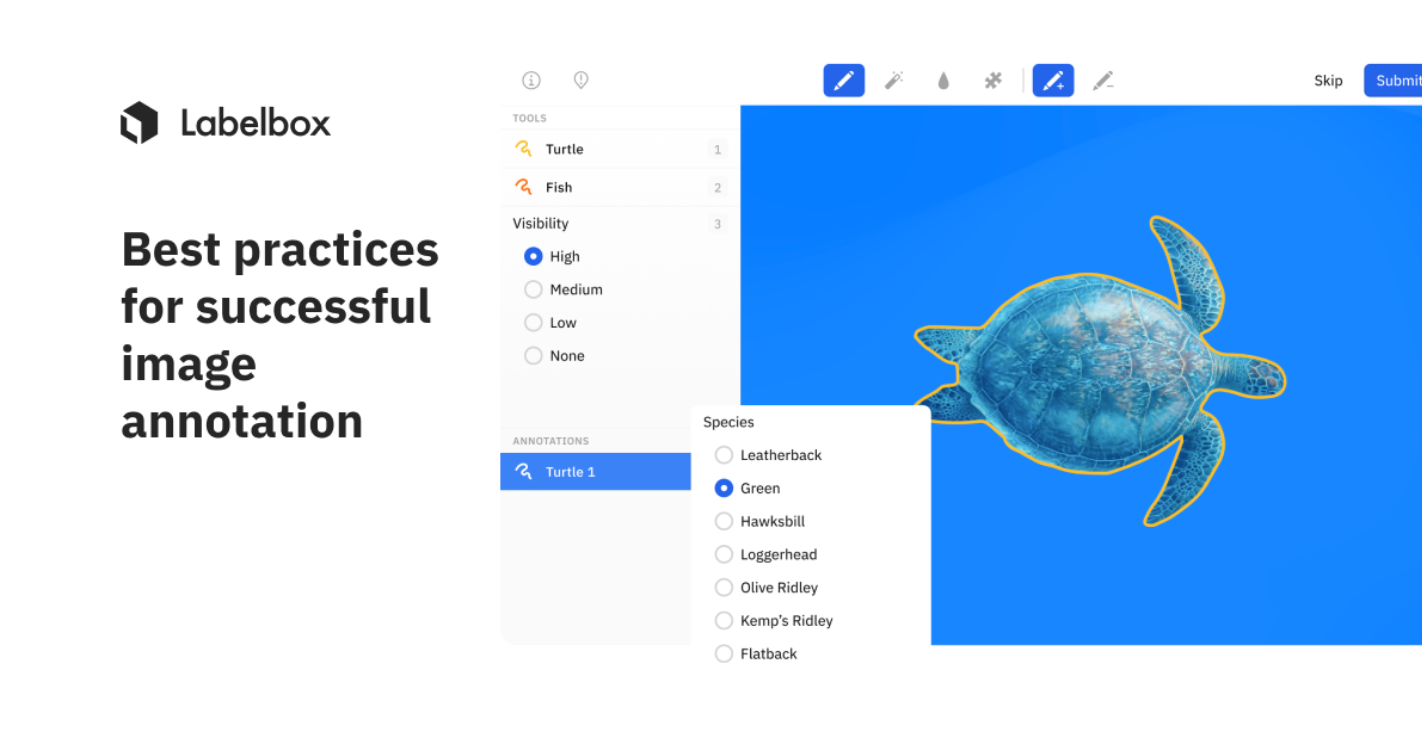
What is image annotation?
Image annotation is the task of labeling digital images, typically involving human input and, in some cases, computer-assisted help. Labels are predetermined by a machine learning (ML) engineer and are chosen to give the computer vision model information about the objects present in the image. The process of labeling images also helps machine learning engineers hone in on important factors in the image data that determine the overall precision and accuracy of their model.
Example considerations include possible naming and categorization issues, how to represent occluded objects (objects hidden by other objects in the image), how to deal with parts of the image that are unrecognizable, etc.
How do you annotate an image?
From the example image below, a person has used an image annotation tool to apply a series of labels by placing bounding boxes around the relevant objects, thereby annotating the image. In this case, pedestrians are marked in blue and taxis are marked in yellow, while trucks are marked in yellow.
Depending on the business use case and project, the number of image annotations on each image can vary. Some projects will require only one label to represent the content of an entire image (e.g. image classification). Other projects could require multiple objects to be tagged within a single image, each with a different label (e.g. a bounding box).
Image annotation software is designed to make image labeling as easy as possible. A good image annotation app will include features like a bounding box annotation tool and a pen tool for freehand image segmentation.

What are the different types of image annotation?
To create a novel labeled dataset for use in computer vision projects, data scientists and ML engineers have the choice between a variety of annotation types they can apply to images. Researchers will use an image markup tool to help with the actual labeling. The three most common image annotation types within computer vision are:
- Classification: With whole-image classification, the goal is to simply identify which objects and other properties exist in an image without localizing them within the image
- Object detection: With image object detection, the goal is to find the location (established by using bounding boxes) of individual objects within the image
- Image segmentation: With image segmentation, the goal is to recognize and understand what's in the image at the pixel level. Every pixel in an image is assigned to at least one class, as opposed to object detection, where the bounding boxes of objects can overlap. This is also known as semantic segmentation.

Whole image classification provides a broad categorization of an image and is a step up from unsupervised learning as it associates an entire image with just one label. It is by far the easiest and quickest to annotate out of the other common options. Whole-image classification is also a good option for abstract information such as scene detection or time of day.
Bounding boxes, on the other hand, are the standard for most object detection use cases and require a higher level of granularity than whole-image classification. They provide a balance between annotation speed and targeting items of interest.
Image segmentation is usually chosen to support use cases in a model where you need to definitively know whether or not an image contains the object of interest as well as what isn’t an object of interest. This is in contrast to other annotation types such as classification or bounding boxes, which may be faster but usually convey less information.
Why is image annotation useful?
Image annotation is a vital part of training computer vision models that process image data for object detection, classification, segmentation, and more. A dataset of images that have been labeled and annotated to identify and classify specific objects, for example, is required to train an object detection model.
This kind of computer vision model is an increasingly important technology. For example, a self-driving vehicle relies on a sophisticated computer vision image annotation algorithm. This model labels all the objects in the vehicle's environment, such as cars, pedestrians, bicycles, trees, etc. This data is then processed by the vehicle's computer and used to navigate traffic successfully and safely.
There are many off-the-shelf image annotation models available. One such model is YOLO, an object detection model that generates bounding box annotations in real time. YOLO stands for "You only look once," indicating that the algorithm analyzes the image and applies image annotations in one pass, prioritizing speed.
How does an AI data engine support complex image annotation?
Image annotation projects begin by determining what should be labeled in the images and then instructing annotators to perform the annotation tasks using an image annotation tool.
Annotators must be thoroughly trained on the specifications and guidelines of each image annotation project, as every company will have different image labeling requirements. The annotation process will also differ depending upon the image annotation tool used.
Once the annotators are trained on proper data annotation procedures for the project, they will begin annotating hundreds or thousands of images on an image annotation tool.
Data engine software like Labelbox is not only equipped with an image annotation tool, but also allows AI teams to organize and store their structured and unstructured data while providing a model training framework.
This scalable and flexible image annotation tool allows you to perform all the tasks mentioned above, from image classification to advanced semantic segmentation.
In addition, a best-in-class data engine will typically include additional features that specifically help optimize your image annotation projects.
Model-assisted labeling
An AI data engine helps users automate several parts of their image annotation process to accelerate efforts without diminishing the quality of annotations.
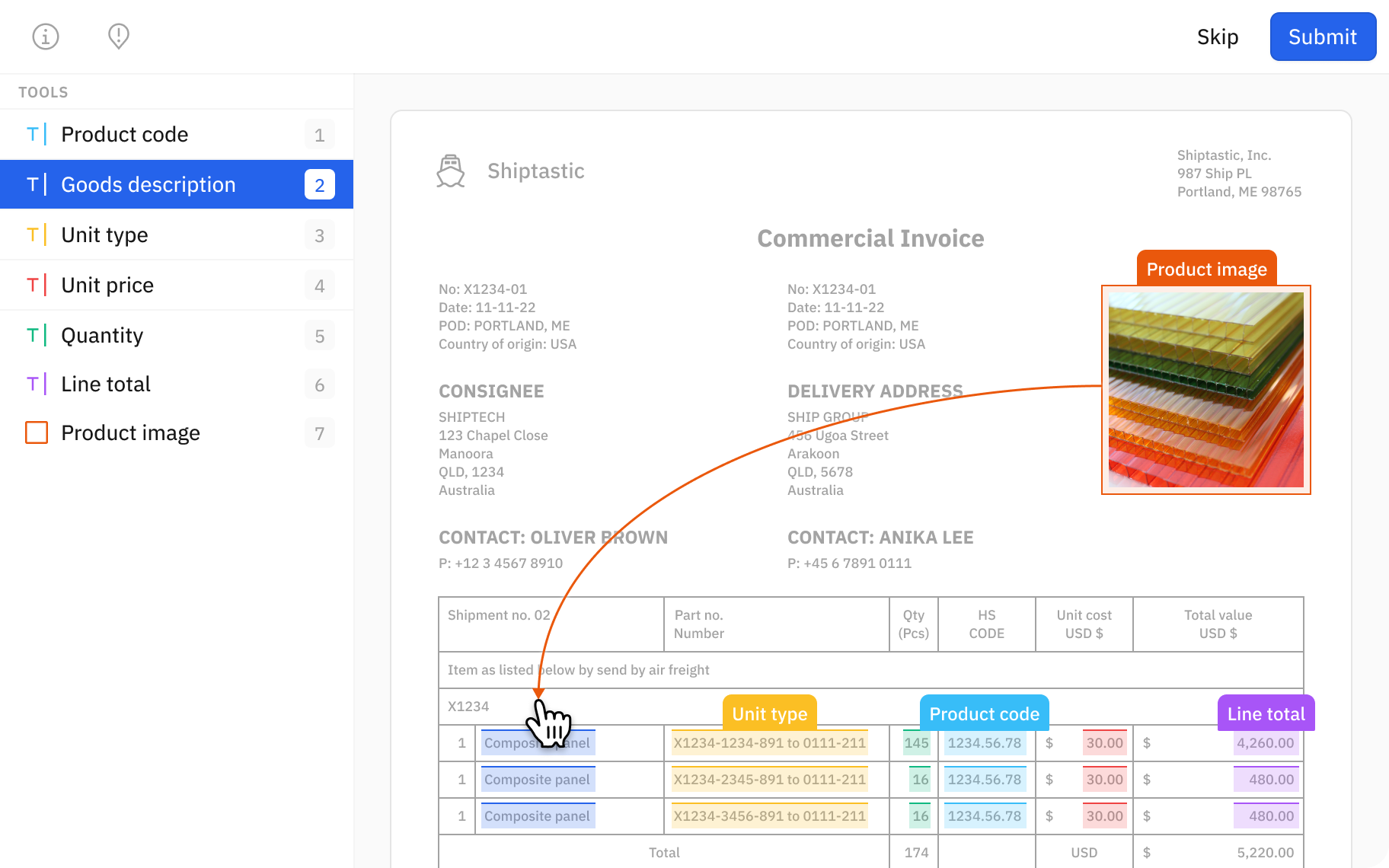
1. Automated queuing enables labelers to work continuously, eliminating the delays that occur as they wait to receive datasets, instructions, and other materials
2. Auto-segmentation tools that cut complex image segmentation drawing tasks down to seconds
3. Automate data operations and workflows programmatically with a Python SDK
4. AI teams can import model predictions as pre-labels, so that labelers can review and correct them instead of labeling data from scratch
This final labeling automation technique, called pre-labeling or model-assisted labeling, has been proven to reduce labeling time and costs by up to 50% for AI teams.
Pre-labeling decreases labeling costs as the model gets smarter with every iteration, leaving teams more time to focus on manually labeling edge cases or areas where the model might not be performing as well. It’s not only faster and less expensive, but delivers better model performance.
High-performance image annotation tools
The image annotation tool on the AI data engine you are testing can support a high number of objects and labels per image without sacrificing loading times.
Labelbox’s fast and ergonomic drawing tools provide efficiency to help reduce the time-consuming nature of creating consistent, pixel-perfect labels. A vector pen tool, for instance, allows users to draw freehand as well as generate straight lines. When you have the right tool for the job, image annotation is much easier.
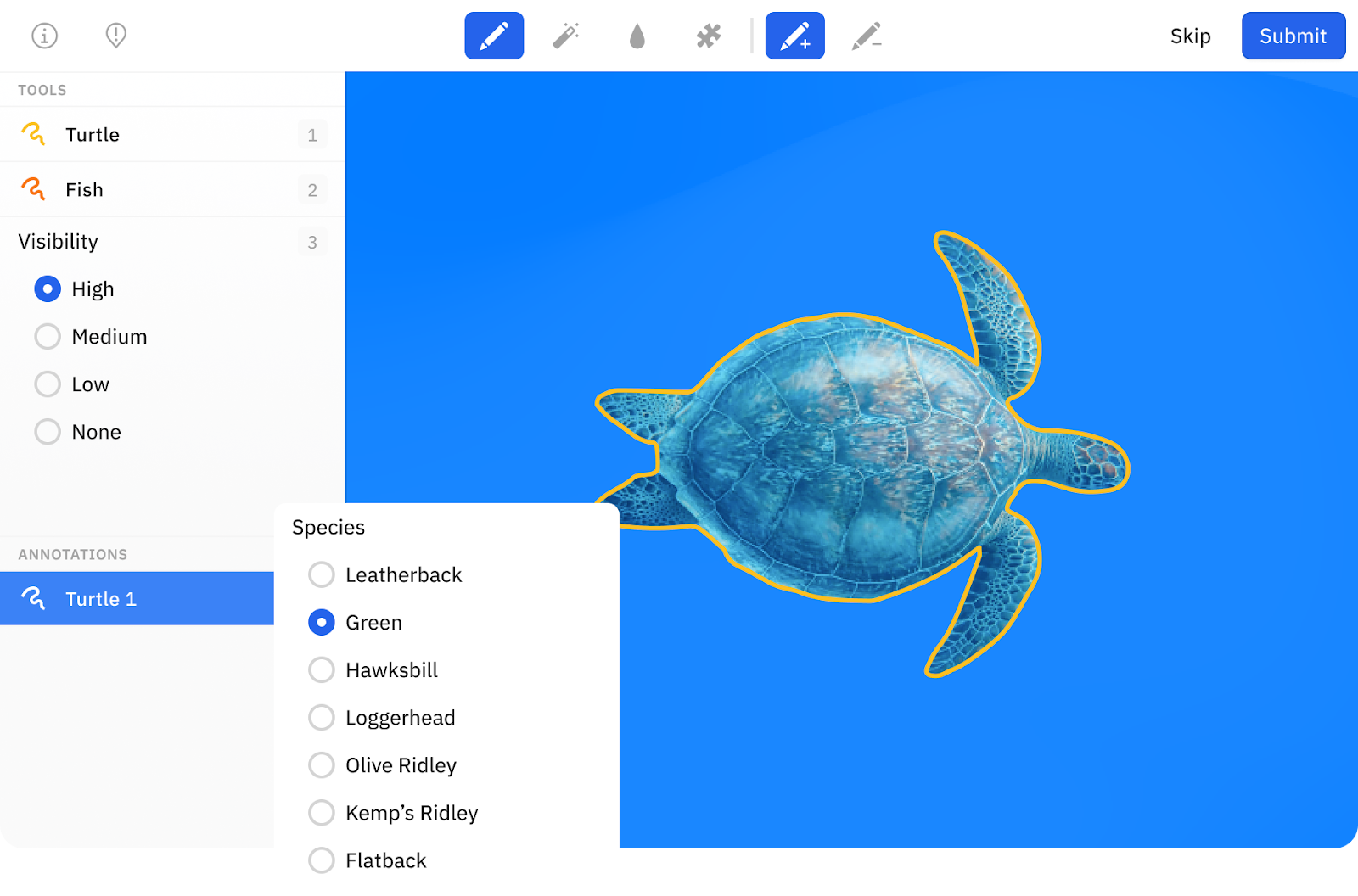
Customization based on ontology requirements
Labelbox’s suite of image annotation tools gives you the ability to configure the label editor to your exact data structure (ontology) requirements, with the ability to further classify instances that you have segmented.
Ontology management includes classifications, custom attributes, hierarchical relationships, and more. You'll be able to quickly annotate images with the labels that matter to you, without the clutter of irrelevant options.
A streamlined user interface that emphasizes performance for a wide array of devices
An intuitive design helps lower the cognitive load on image labelers which enables faster image annotation. Moreover, an uncluttered online image annotation tool is built to run quickly, even on lower spec PCs and laptops. Both are critical for professional labelers who are working in an annotation editor all day.
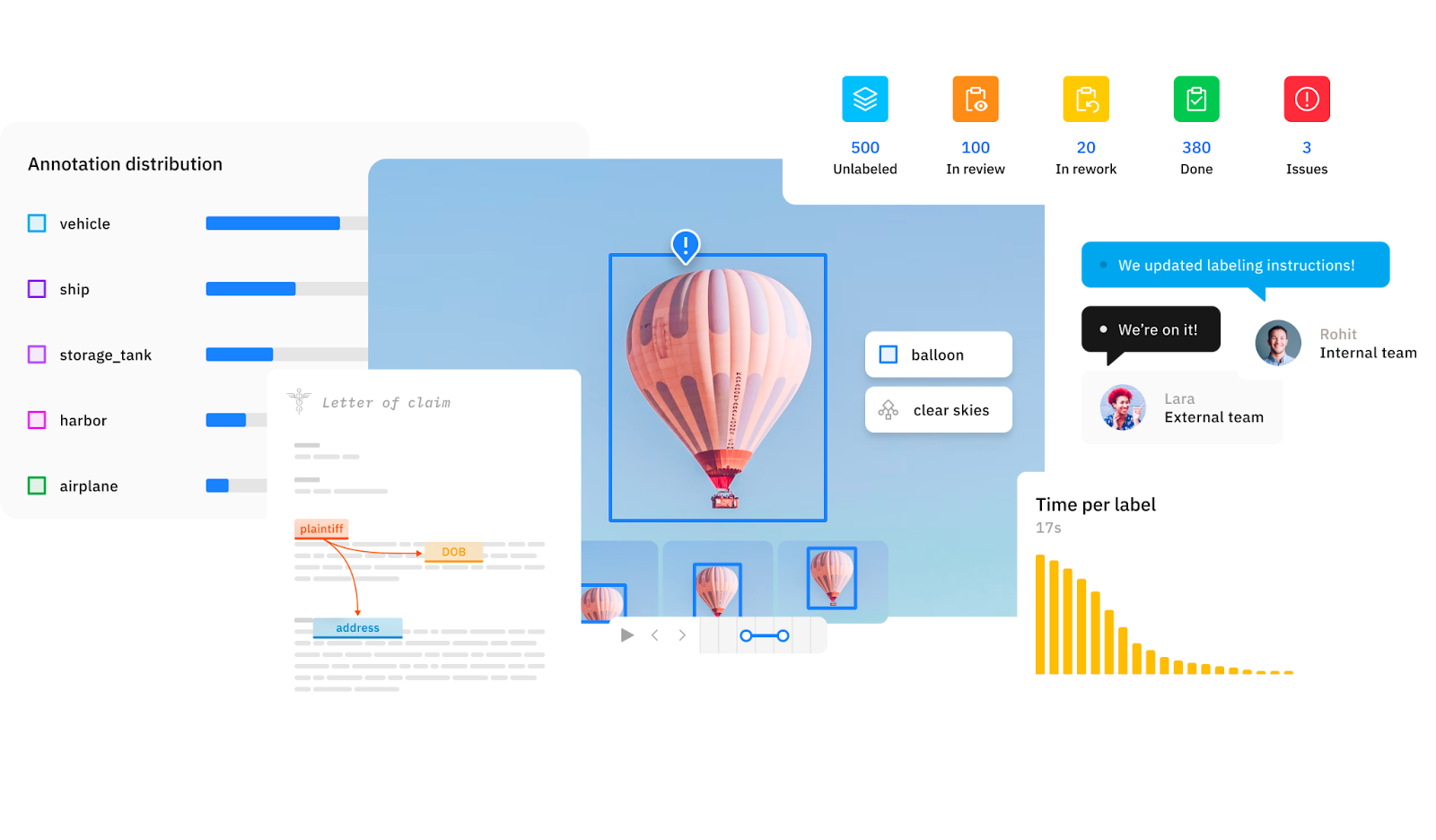
Seamlessly connect your data via Python SDK or API
Stream data into your AI data engine and push labeled data into training environments like TensorFlow and PyTorch. Labelbox was built to be developer-friendly and API first, so you can use it as infrastructure to scale up and connect your computer vision models to accelerate labeling productivity and orchestrate active learning.

Benchmarks and consensus
Data quality is measured by both the consistency and the accuracy of labeled data. The industry-standard methods for calculating data quality are benchmarks (aka gold standard), consensus, and review.
An essential part of an AI data scientist’s job is figuring out what combination of these quality assurance procedures is right for annotated images used in your ML project. Quality assurance is an automated process that operates continuously throughout your training data development and improvement processes. With Labelbox consensus and benchmark features, you can automate consistency and accuracy tests. These tests allow you to customize the percentage of your data to test and the number of labelers that will annotate the test data.
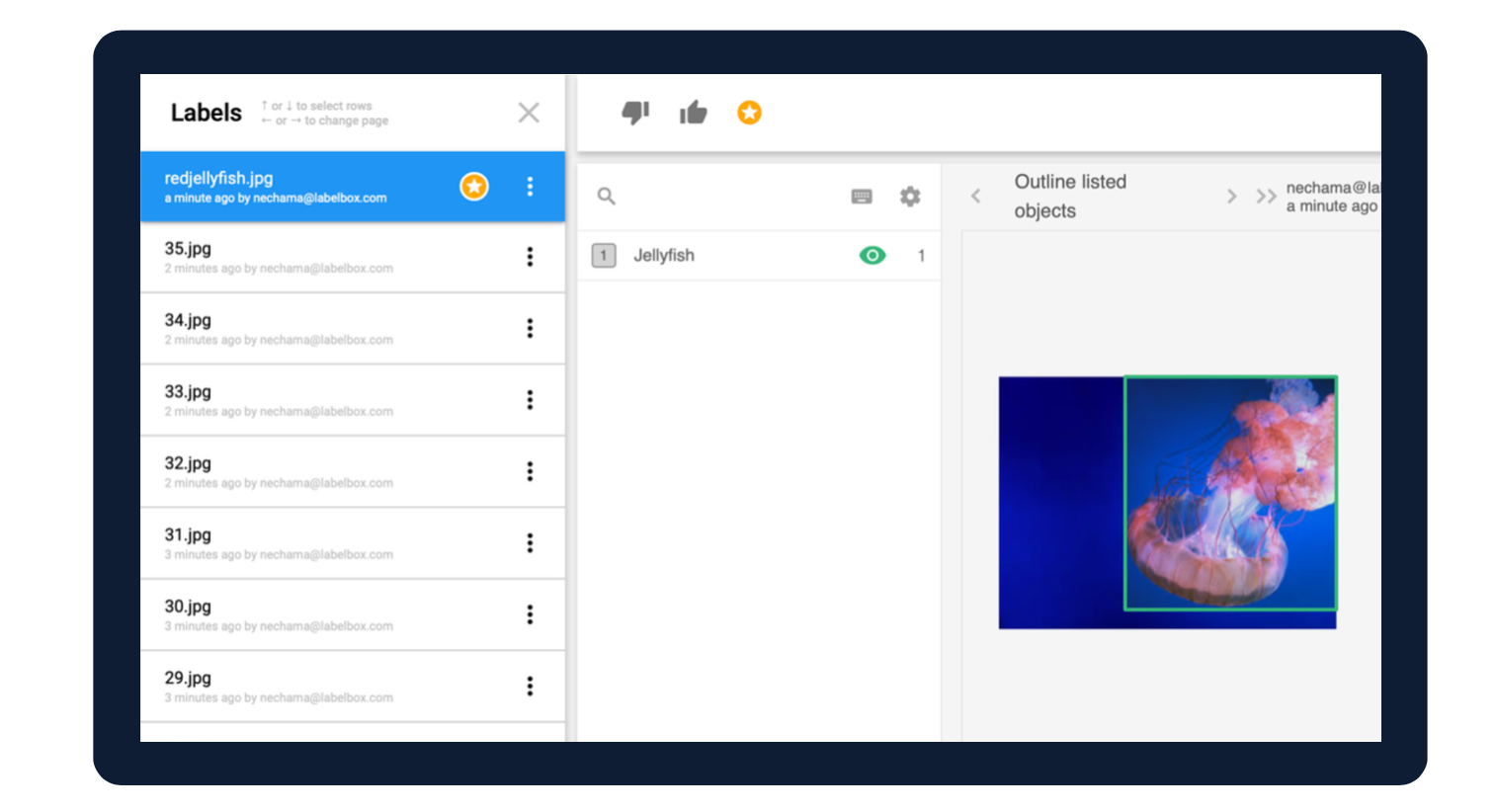
Collaboration and performance monitoring
Having an organized system to invite and supervise all your labelers during an image annotation project is important for both scalability and security. An AI data engine should include granular options to invite users and review the work of each one.
With Labelbox, setting up a project and inviting new members is extremely easy, and there are many options for monitoring their performance, including statistics on seconds needed to label an image. You can implement several quality control mechanisms, including activating automatic consensus between different labelers or setting gold standard benchmarks.

Automatic annotation tool

If you are using image annotation to train a machine learning model, Labelbox allows you to use your model to create pre-labeled images for your labeling team using an automatic image segmentation tool.
Labelers can then review the output of the computer vision annotation tool and make any necessary corrections or adjustments. Instead of starting from scratch, much of the work is already done, resulting in significant time savings.
Final thoughts on image annotation with an AI data engine
The real-world applications for image annotation are endless, from content moderation to self-driving cars to security and surveillance. And, while there are many components to image annotation (classification, detection, segmentation), ultimately the annotation process itself is just a way to produce high quality data for model training.
When engineers at Tesla developed their Full Self Driving (FSD) vehicle technology in 2020, a key part of their success was an AI data engine. OpenAI currently uses their own proprietary AI data engine to train, deploy and maintain popular successful models such as GPT-3 and DALL-E 2.
From these examples, we can see how an AI data engine is key to deploying successful AI products, as it is the foundational infrastructure for how team members interface with data and models. Unfortunately, not all teams have the time and resources to architect an intricate and complex data engine for every use case.
Luckily, AI teams today don’t have to build and maintain data engines for their projects like Tesla and OpenAI did — they can invest in one instead. A best-in-class AI data engine gives you the ability to visualize, curate, organize, label data to improve model performance. Labelbox can help you get there.
Download the Complete guide to data engines for AI to learn how investing in a data engine can help your team build transformative AI products fast.


