
 All guides
All guidesHow to create high-quality image segmentation masks quickly and easily

Enterprise AI teams often spend an enormous amount of time and energy on the development and curation of datasets. This is because, unlike academic machine learning models, the use of open source datasets for a commercial application is unlikely to yield an accurate representation of the real world. Instead, teams need to create a new labeled dataset tailored for their specific project.
In order to create this novel labeled dataset, data scientists and ML engineers have the choice between a variety of annotation types. In computer vision, the frequent choice for differentiating between objects with the highest degree of accuracy is image segmentation.
It’s important to stress that without the right tooling, however, image segmentation can be prohibitive for many projects, as it becomes very costly to label the amount of training data necessary to achieve performant model results.
What is image segmentation?
Image segmentation is one of the most labor intensive annotation tasks because it requires pixel level accuracy. Labeling a single image can take up to 30 minutes. With image segmentation, each annotated pixel in an image belongs to a single class. The output is a mask that outlines the shape of the object in the image.
Although image segmentation annotations come in a lot of different types (such as semantic segmentation, instance segmentation, and panoptic segmentation), the practice of image segmentation generally describes the need to annotate every pixel of the image with a class.

What are the benefits of using image segmentation for my machine learning model?
The primary benefit of image segmentation can be best understood by comparing the three most common annotation types within computer vision.
- Image classification: The goal is to simply identify which objects and other properties exist in an image.
- Image object detection: This goes one step beyond classification to find the position (using bounding boxes) of individual objects.
- Image segmentation: The goal is to recognize and understand what's in the image at the pixel level. Every pixel in an image belongs to a single class, as opposed to object detection where the bounding boxes of objects can overlap.
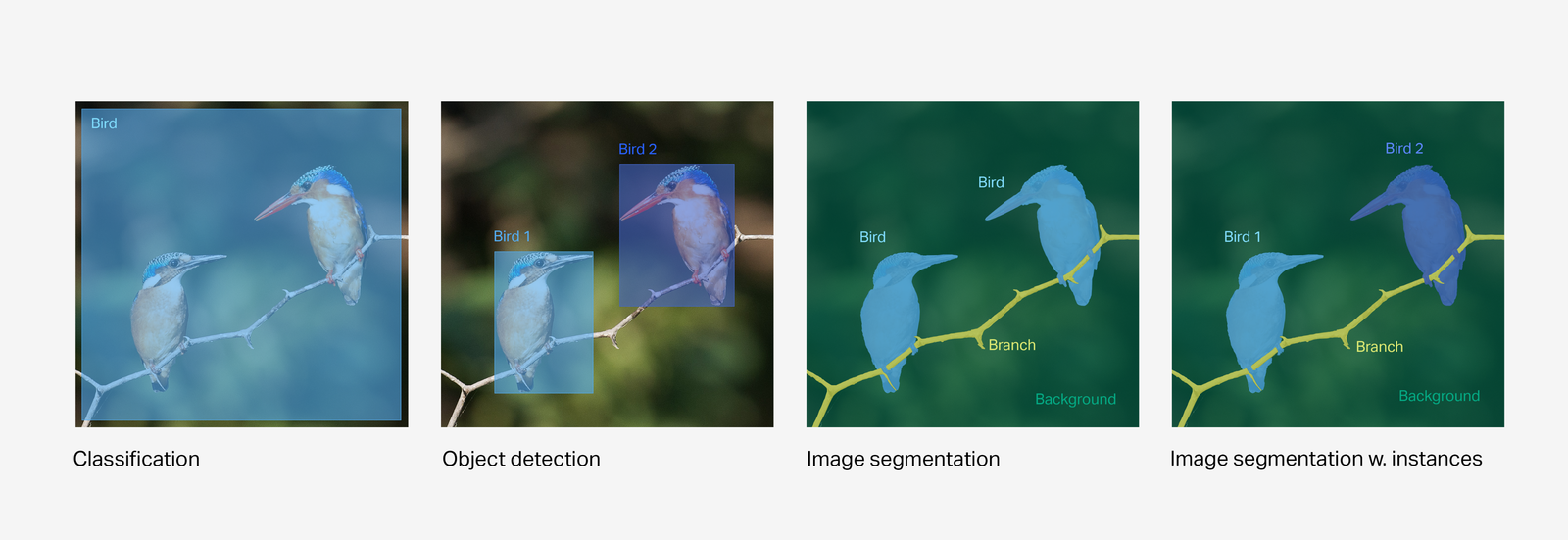
For a point of comparison, employing image segmentation is particularly useful when dealing with use cases in a model where you need to definitively know whether or not an image contains the object of interest — and also what isn’t an object of interest.
This is in contrast to other annotation types such as image classification or bounding boxes, which may be faster to label, but less accurate. In short, annotations generated from image segmentation tend to end up with the most widely applicable and versatile models, because they are the most focused on what is in the contents of an image.
How does an AI data factory support complex image segmentation?
AI data factories are commonly equipped with tools which allow labelers to outline complex shapes for image segmentation. The Labelbox pen tool allows you to draw freehand as well as straight lines. Having fast and ergonomic drawing tools help reduce the time-consuming nature of creating consistent, pixel-perfect labels.

In addition, AI data factories typically include additional features that specifically help optimize your image segmentation project.
Automating the image segmentation labeling task

A best-in-class AI data factory helps users automate parts of the image segmentation process to accelerate efforts without diminishing the quality of annotations. One crucial part of this automation includes the incorporation of auto-segmentation tools that enable labelers to complete the complex image segmentation drawing tasks in seconds.
Another labeling automation technique, called pre-labeling or model-assisted labeling, has been proven to reduce labeling time and costs by up to 50% for AI teams. Model-assisted labeling involves the use of a model — whether it’s a generic off-the-shelf model, your own model in training, or a model built specifically to generate labels. The model’s output is used as pre-labels, enabling labelers to simply correct or edit them instead of labeling data from scratch.

Pre-labeling decreases labeling costs as the model gets smarter with every iteration, leaving teams more time to focus on manually labeling edge cases or areas where the model might not be performing as well. It’s not only faster and less expensive, but delivers better model performance.
Customization based on ontology for image segmentation

Being able to configure the label editor to your exact data structure (ontology) requirements, with the ability to further classify instances that you have segmented, is important for accurate and easy image segmentation. Labelbox’s ontology management feature includes classifications, custom attributes, hierarchical relationships, and more.
An emphasis on performance for a wide array of devices
As previously mentioned, image segmentation can be a time consuming process, taking up to 30 minutes to complete a single image. A focus on intuitive UI across multiple devices (even on lower-spec PCs or laptops) is important to reduce fatigue for professional labelers who are working on image segmentation labeling tasks for hours on end.
Dynamic queuing for large scale image segmentation projects

Standard queuing methods have image segmentation tasks distributed equally to active annotators. These equal distribution methods typically lead to inefficient workflows as not all annotators work at the same speeds and not all image segmentation tasks are created equal. With large scale projects, this also potentially leads to longer delays as annotators sit idle, waiting for new tasks.
An AI data factory supports more efficient labeling queues for image segmentation tasks by enabling a continuous workflow for annotators. With this method, new tasks will automatically be distributed at the rate of completion to eliminate idle time and help get your image segmentation project finished faster.
Software-first approach to image segmentation
A best-in-class data factory gives you options when it comes to labeling configuration for image segmentation tasks, adopting a software-first approach.
This software-first approach allows AI teams with image segmentation projects to use any labeling service or vendor with full transparency, collaborate easily with all stakeholders throughout the labeling process, and train their own models to automate labeling thereby significantly reducing their unit costs for image segmentation tasks.
This includes using an in-house image segmentation team, a BPO (business process outsourcing), or on-demand labeling services from Labelbox Boost.
Enabling the creation of synthetic data
AI teams are increasingly turning to synthetic data to meet their needs when real data is thin, or when handling sensitive information as the dataset won’t contain any real information during the model training process.
Synthetic data can also simulate edge cases and conditions that aren’t represented in real data or mitigate issues caused by potential changes in the camera sensor or lighting conditions, helping teams fill in the gaps in their dataset.
AI data factory enables teams to build a VAE(variational auto-encoder) or GAN (Generative Adversarial Networks) model to generate image data.
Synthetic data generation can be used for preserving privacy, and overcoming some imbalanced dataset problems (for example, if you are training on a cancer diagnosis dataset from patient records but there are only 2% of positive cases, you would want to generate a few synthetic positive examples that are anonymous).
While it can be helpful to bootstrap a model training with a larger dataset, synthetic data will inherit biases from the data it is modeling from, and the model might still struggle when facing with production data it has not learned about before. Thus, it is often recommended to collect diverse real-world data for training (and use active learning techniques to curate more efficiently), rather than relying on synthetic data.
Support for shared borders when creating image segmentation masks
When creating image segmentation masks, it’s important to be able to share borders between objects. With the Labelbox editor, it’s simple. Whenever you draw a new object, if you overlap the border of an already existing object, the new border you’re drawing will be shared.
This method works well when you are labeling objects from the background first. Sometimes, though, you want to be able to draw foreground objects first, and then be able to draw an object behind without messing up the masks you’ve already created. A best-in-class AI data factory will support shared borders to help you accelerate the image segmentation process.
What are some example real world image segmentation use cases?
Image segmentation is popular for real world machine learning models when high accuracy is required of the computer vision application being built.
Use cases employing image segmentation can be found as follows:
- Autonomous vehicles
- Medical imagery
- Retail applications
- Face recognition and analysis
- Video surveillance
- Satellite image analysis

Final thoughts on image segmentation with an AI data factory
Historically, image segmentation has been prohibitive for many projects, despite the benefits of pin-point accuracy, because the costs associated with labeling the amount of training data necessary to achieve performant model results can become astronomical.
However, an AI data factory can rewrite this precedent. With the features included in a best-in-class AI data such as a flexible pen tool, auto-segmentation, and model-assisted labeling techniques, image segmentation becomes a fast and accurate process — thus also becoming a more accessible technology to AI teams.
Investing in an AI data factory like Labelbox empowers teams with the tools to quickly build better image segmentation AI products.


