×![]()

 All blog posts
All blog postsLabelbox•November 29, 2022
Optimize pre-labeling efficiency with automation metrics

You can now optimize model-assisted labeling, better queue and review your data rows, and more.
Measure and improve pre-labeling workflows
Automating your data labeling process is not only a key component of an effective data engine, but is key to producing high-quality data, fast.
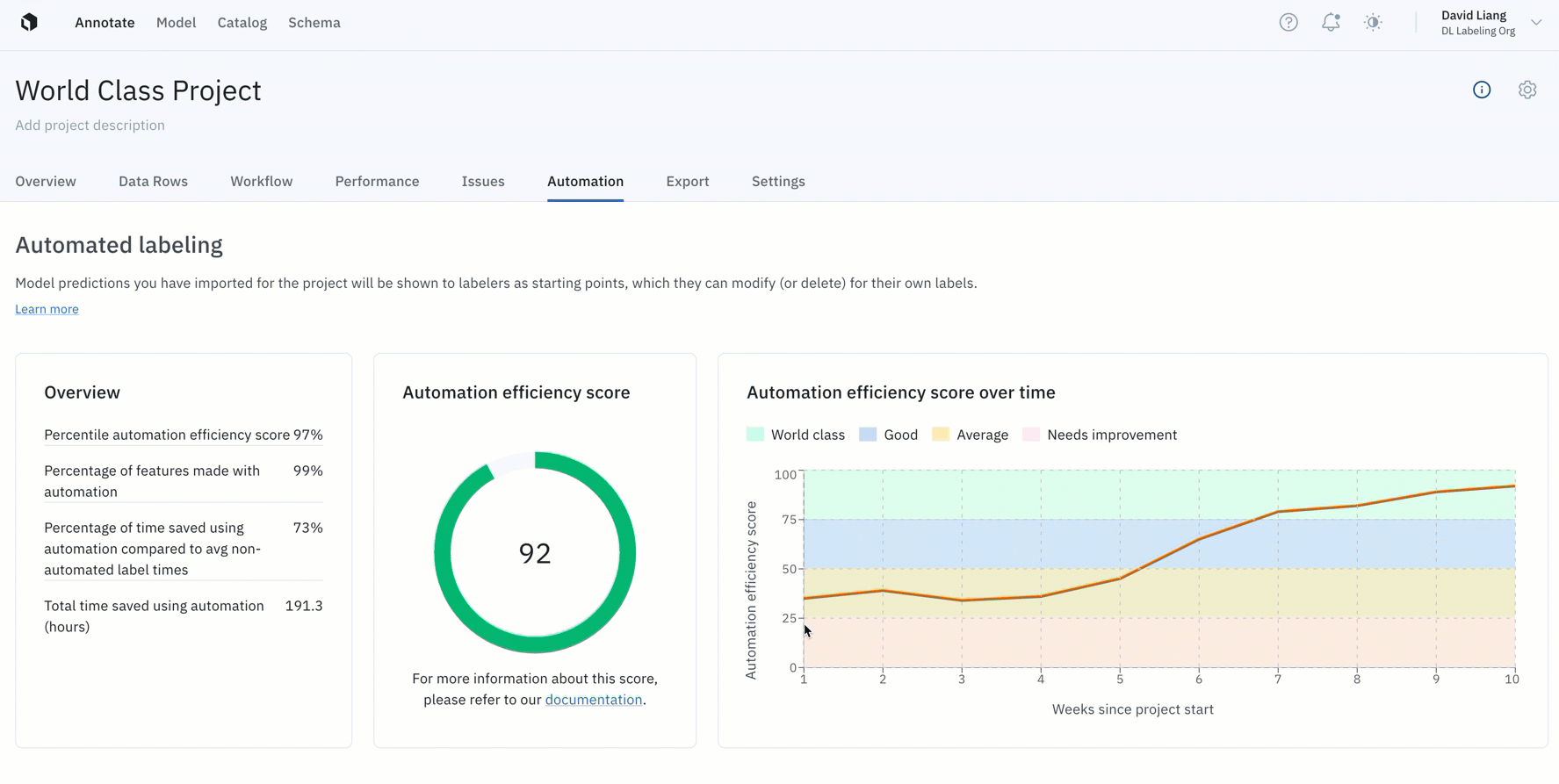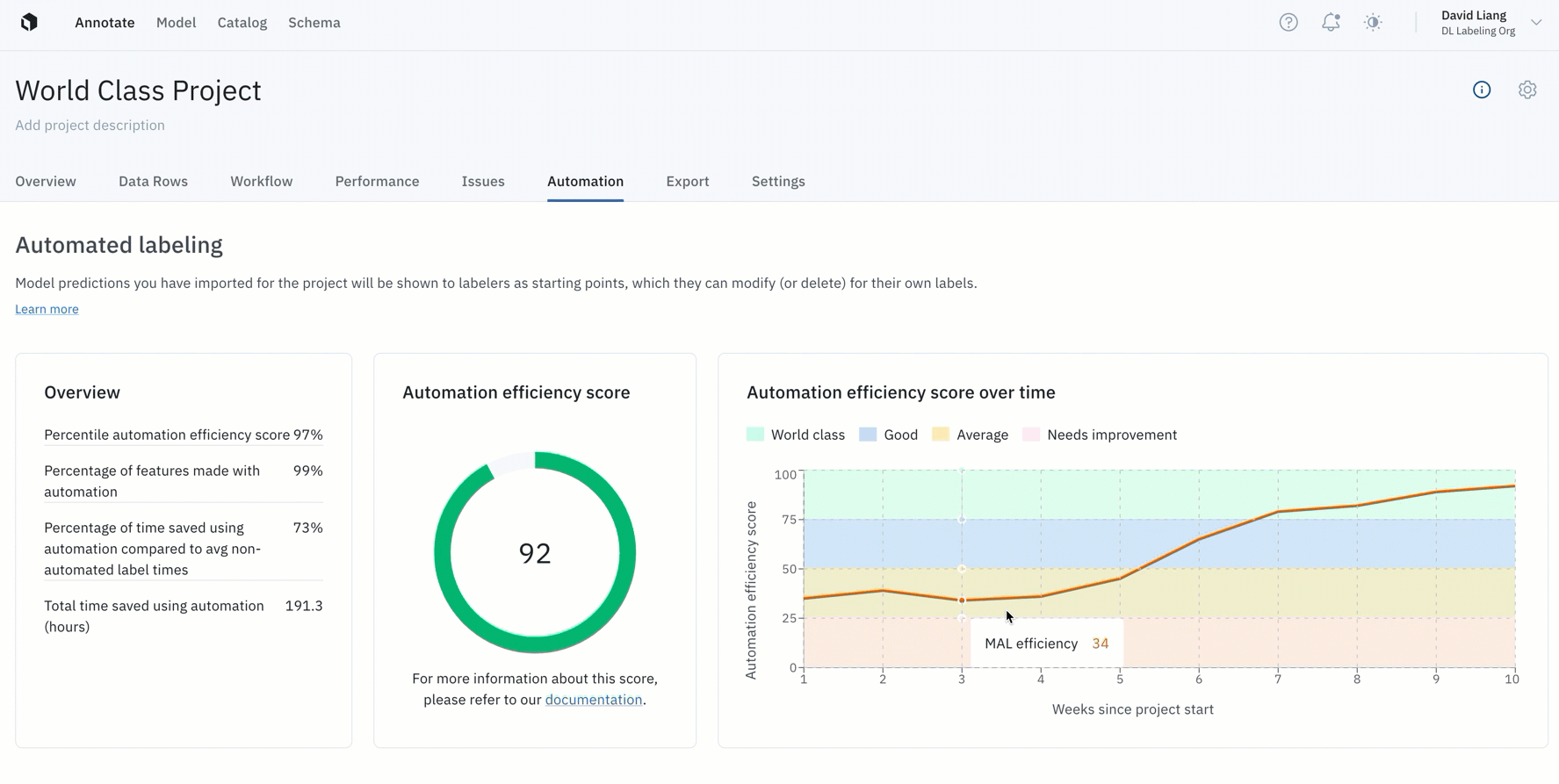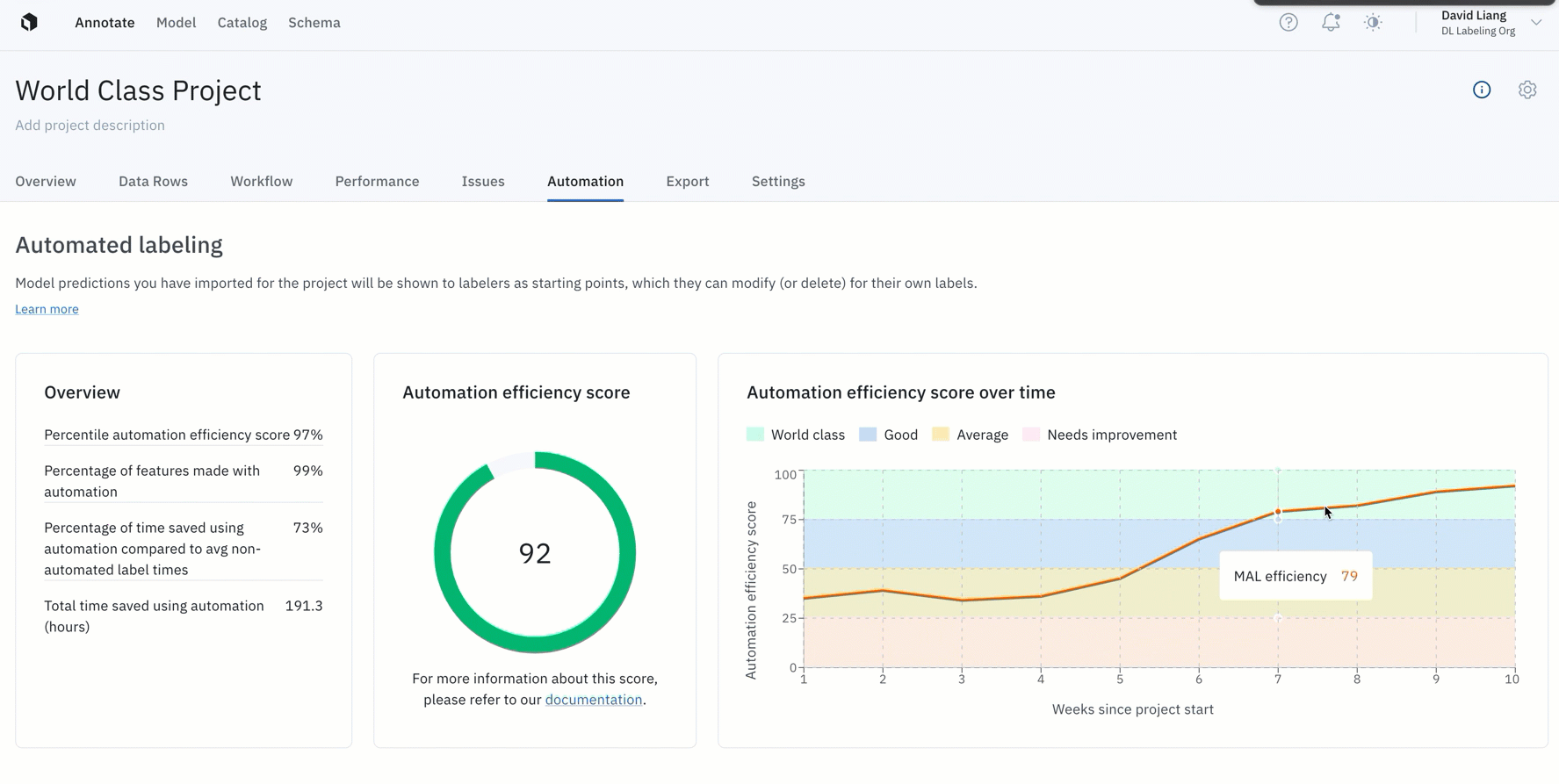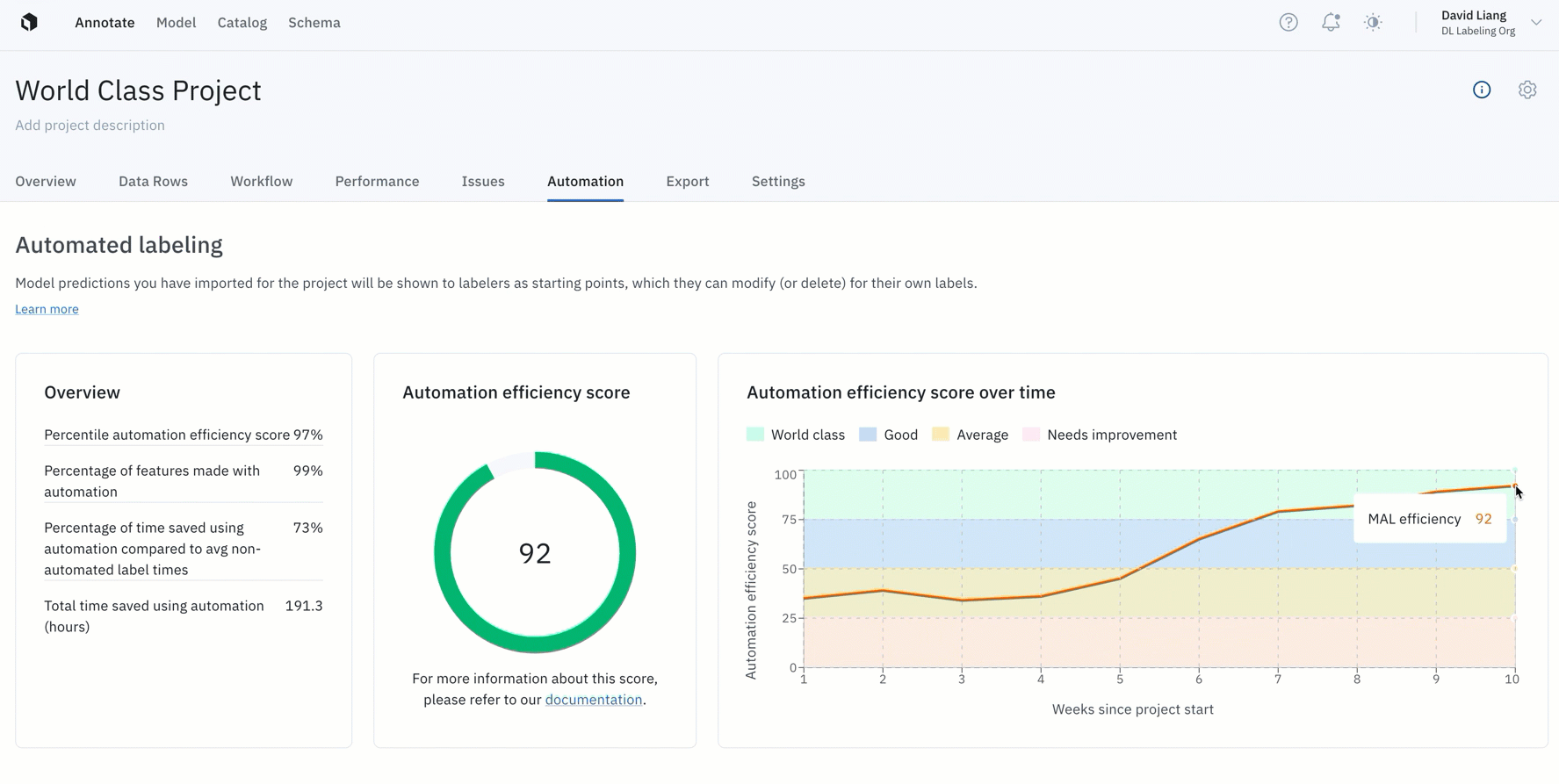
- You can now measure and improve pre-labeling efficiency workflows with the automation efficiency score
- Instead of operating blindly or spending more time manually tracking efficiency gains from pre-labeling, your team now has a tangible way to quantify how your use of pre-labeling accelerates model development
- Projects with an automation efficiency score of over 75 experience 65% in time savings by leveraging pre-labeling — all without sacrificing training data quality. In other words, world-class projects can save two-thirds in labeling time and costs
Learn more about the automation efficiency score in a recent blog post.
A new way to queue and review
A vital aspect of a data engine involves the creation of large volumes of high-quality training data. Often, AI teams struggle to prioritize the right data to label and end up spending more money on data labeling than they should.
To help you better queue, review, surface and prioritize your training data, Labelbox has begun to roll out configuring new projects with batches, custom workflows, and the Data Rows tab.
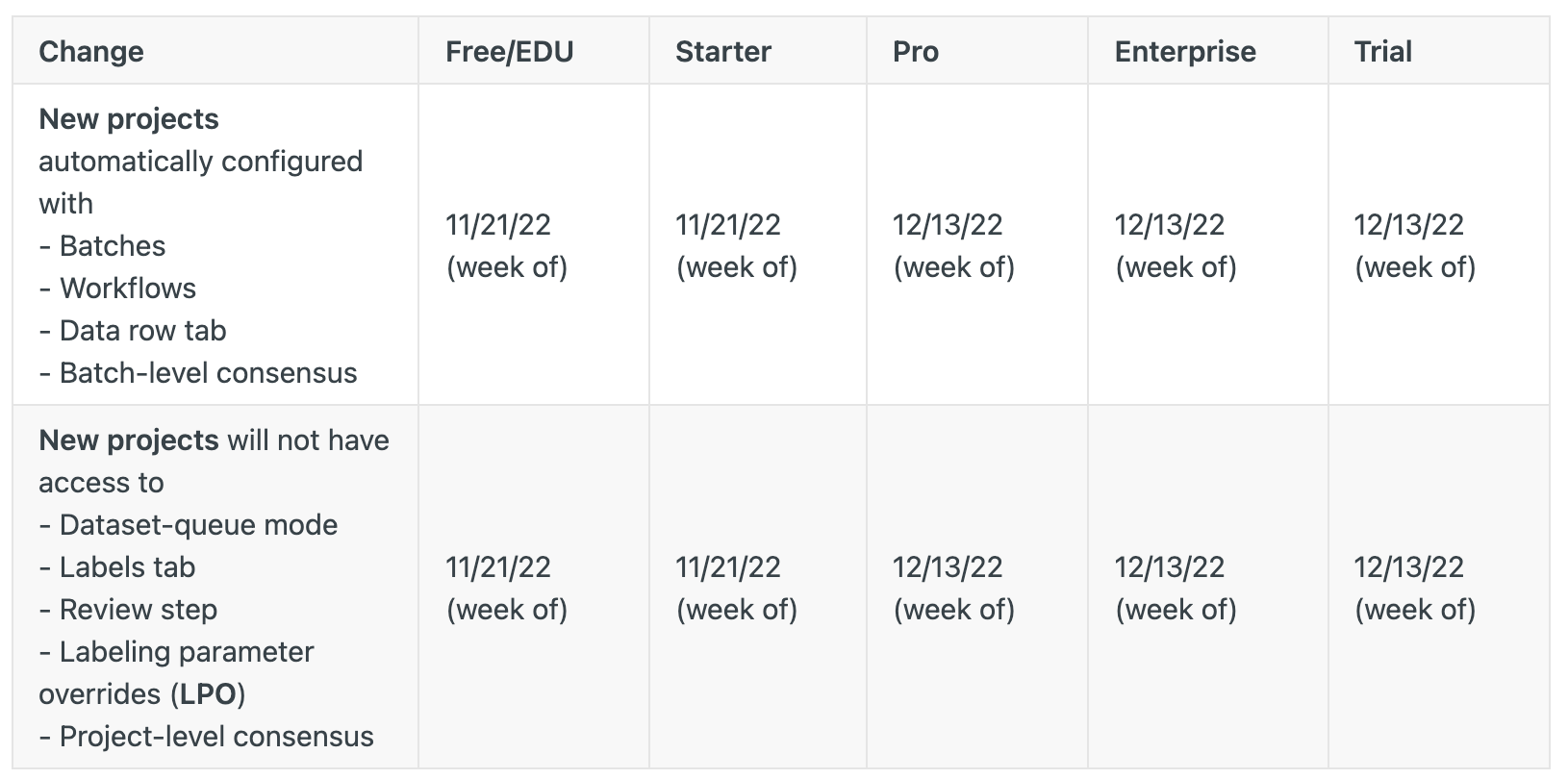
On November 21st, we released an update to Free, Education, and Starter users that automatically configured new projects with batch-based queueing, custom workflows, and the Data Rows tab.
- All new projects created after 11/21 will use: batch-based queueing, the Workflow tab for review, and see the Data Rows tab with no Labels tab.
- Projects created before 11/21 will continue to use: dataset-based queueing, the review step, and see the Labels tab and Data Rows tab with no Workflow tab.
- Towards the end of Q4 2022, Labelbox will open a migration path that will allow you to move your old projects into this new paradigm. For projects not migrated by the end of Q1 2023, Labelbox will automatically help migrate them to use batch-based queueing, workflows, and the Data Rows tab in early Q2 2023
Pro and Enterprise users can expect the same changes in mid-December.
To familiarize yourself with these new changes and workflows, please refer to the resources below:
- Migration guide: A new way to queue & review
- SDK changes: A new way to queue & review
- How to prepare and submit a batch for labeling (Batches)
- How to customize your annotation review process (Workflows)
- How to search, surface, and prioritize data within a project (Data Rows tab)
Pre-labeling support for annotating conversational text
The conversational text editor allows users to create unique message-based classifications that can identify user intent or sentiment.
- You can easily train an open-source model on your own data and tailor the language model to meet your specific business needs
- The model-assisted labeling (MAL) workflow allows you to import computer-generated predictions, or annotations created outside of Labelbox, as pre-labels on an asset
- To make this process even faster, the editor now supports pre-labeling support for text entities (NER), message-based classifications and global classifications
Learn more about our conversational text editor or importing pre-labels in our documentation.
NER pre-labeling support for annotating PDF documents
The document editor now supports text entity imports for NER, allowing you to import text entity annotations as pre-labels on their assets.
With this update, the document editor supports both imports for text entity and bounding box imports – you can use model-assisted labeling to dramatically decrease iteration cycles and the overall time taken to reach a performant model.
Learn more about our document editor or importing pre-labels in our documentation.
Annotate large scale images with ease
We now support up to 5,000 vector annotations (i.e point, line, box, polygon) in the image editor.

If you’re annotating large scale images with numerous labels, this allows you to annotate with ease with no slow down. Learn more in our documentation.
SDK updates
We recently released a new version of our Python SDK (see changelog here). It includes the following major updates:
- Running `project.setup_editor`multiple times no longer resets the ontology. It instead raises an error if the editor is already set up for the project
- To avoid emptying the ontology via `setup_editor` please use `pip install –upgrade labelbox` to upgrade to the latest version of the SDK
- Conversational text data rows will be uploaded to a json file automatically on the backend to reduce the amount of i/o required in the SDK.
Please use `pip install –upgrade labelbox` to upgrade to the latest version of the SDK.
The latest guides on labeling operations
Check out the latest tutorials & walkthroughs on how to effectively manage your labeling operations:


