
 All blog posts
All blog postsManu Sharma•April 19, 2023
GPT-4 vs PaLM: Assessing the predictive and generative performance of LLM models

Overview
Large language models (LLMs), such as GPT-4 from OpenAI, Bart, and Llama, have demonstrated remarkable abilities to engage in creative and compelling conversations, distill and summarize information from contextual cues, and deliver exceptional zero-shot performance on a wide range of predictive and generative tasks on previously unseen data.
If you have experimented with LLMs, you know that while undoubtedly powerful, they do also have their limitations. One primary drawback is their inability to stay up to date with the latest information, resulting in responses that may be out of date or incomplete. Additionally, the accuracy and appropriateness of model outputs can vary based on the prompt given. In some cases, LLMs can even “hallucinate” answers or produce results that are not relevant to the query.
The above are just some reasons why businesses might hesitate before trusting LLMs for automating internal workflows or customer-facing functions. While many people have encountered LLMs through the chat interfaces of OpenAI and Bart or through demos of LLM applications, such experiences don’t address critical questions such as:
- How will LLMs perform on new data and help solve my unique use case?
- How can I quickly experiment and compare different LLMs on my own data at scale in order to test which is the best for my use case?
In this blog post, we aim to put GPT-4 and PaLM — two of the largest and most powerful LLMs developed to date - to the test. We will provide a step-by-step walkthrough on how to apply GPT-4 and PaLM to a custom text dataset and systematically evaluate and compare their zero-shot predictive accuracy and generative ability. By doing so, we hope to help you learn how to confidently assess the potential and limitations of LLMs as well as inspire new use cases.
Experiment setup
Dataset and problem setup
We sampled 100 data points from the Wikipedia Movie Plots dataset from Kaggle. It contains a wealth of information, including long-form movie plots, genres, and other relevant information. For this use case, we are interested in assessing an LLM’s ability to predict the movie genres from the movie plots, as well as their ability to generate an appropriate and succinct summary.
We filtered the original dataset to include only the following categories: 'comedy', 'animated', 'sci-fi', 'thriller', 'action', 'family', 'fantasy', 'horror', 'adventure', 'drama'. Since a movie can fall into multiple genres, the task is classified as a multi-classification problem. The models will be evaluated on its precision, recall, F1 scores, and confusion matrix. The model will be evaluated on its precision, recall, F1 scores, and confusion matrix.
To evaluate summary generation, we tasked both LLMs with generating a short summary and manually read through them to evaluate them on three dimensions: clarity, accuracy, and conciseness.
Model and prompt setup
We chose to compare GPT-4 and PaLM models as they are among the most powerful generative models currently available and have APIs that support bulk inference. Creating effective prompts for large language models is an art, with various prompt engineering techniques available. For the purpose of this blog, we opted to use simple prompt templates that clearly describe the ML task and return format (a structured JSON format). This willl also allow us to easily integrate the prompts into downstream workflows. To create a fair comparison, we used identical prompts for both models during our evaluation.
The prompt without examples:
For this movie plot description, describe plot_summary, or answer N/A if you are not confident.The plot summary should be short 1 sentence description. Classify movie genres by picking one or more of the options: [comedy, animated, sci-fi, thriller, action, family, fantasy, horror, adventure, drama].
Return the result as a json: {"plot_summary" : "<answer>", "movie_genres" : ["<prediction>"]}
{insert movie plot}In this prompt, we asked the LLM to provide a short one sentence summary and classify the movie genres. We requested the output to be returned in a structured JSON format with the actual text asset inserted at the end.
We integrated each text data asset into the prompt template above and leveraged GPT-4 and PaLM models for inference. We then uploaded the resulting model outputs into a model run in Labelbox Model.
Findings and results
Visualize model predictions and metrics
We can now evaluate the results of the GPT-4 and PaLM models. To conduct a comprehensive analysis of a model, it is helpful to compare the predictions of each model with the original ground truth labels side-by-side. It is also essential to conduct a holistic metric analysis that evaluates the models overall performance on the task. To this end, we uploaded both models’ predictions and original ground truth labels to a Labelbox model run so that we could easily visualize the predictions, and see auto-generated quantitative model metrics.
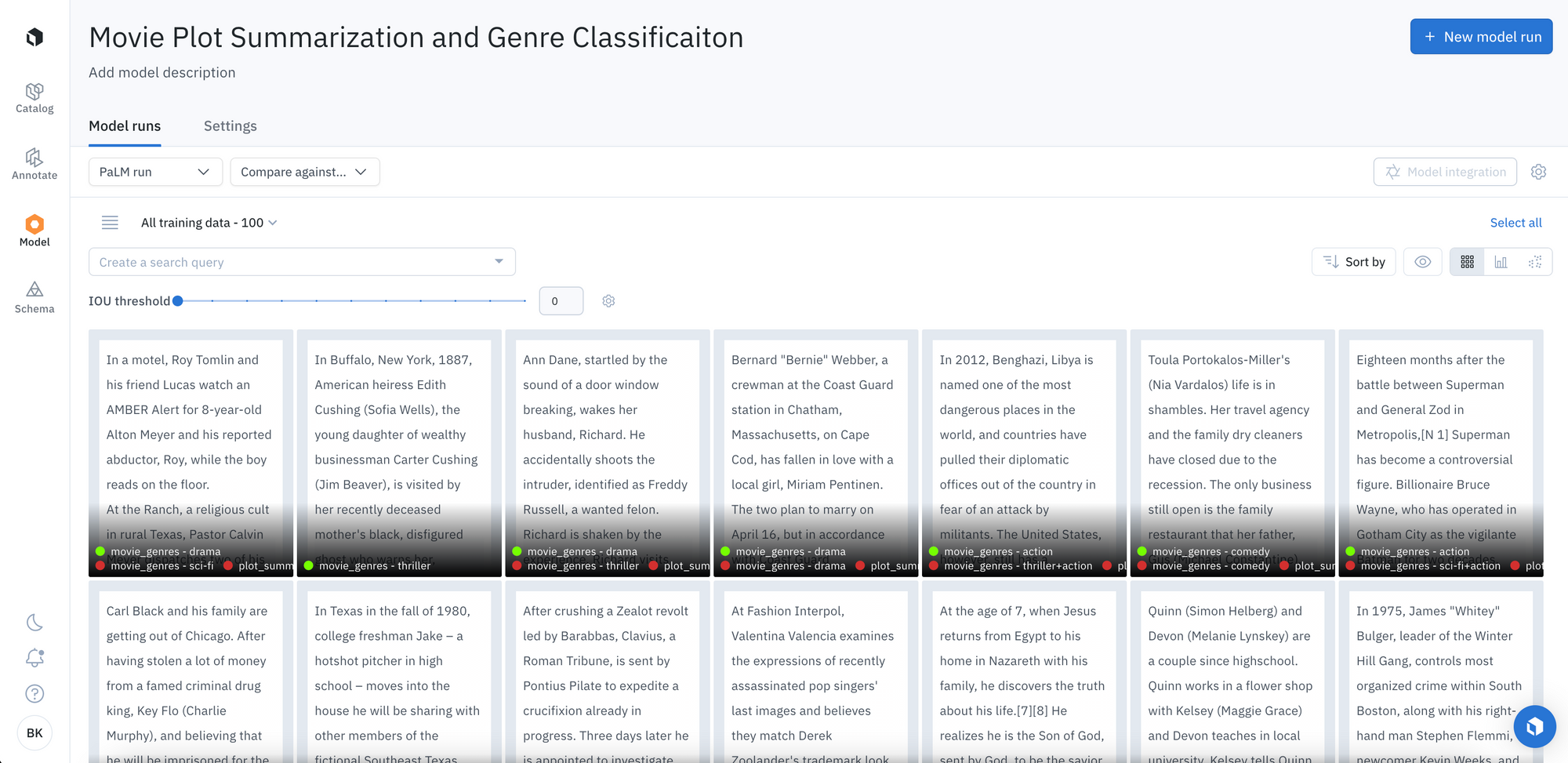
PaLM offers a unique feature that generates multiple safety attributes scores based on how likely the generated content is hateful, violent, sexual, and contains political or medical topics. This is helpful in customizing content moderation and in understanding the distribution of response attributes. By clicking on an asset to examine its prediction and metrics, you can easily view these scores.
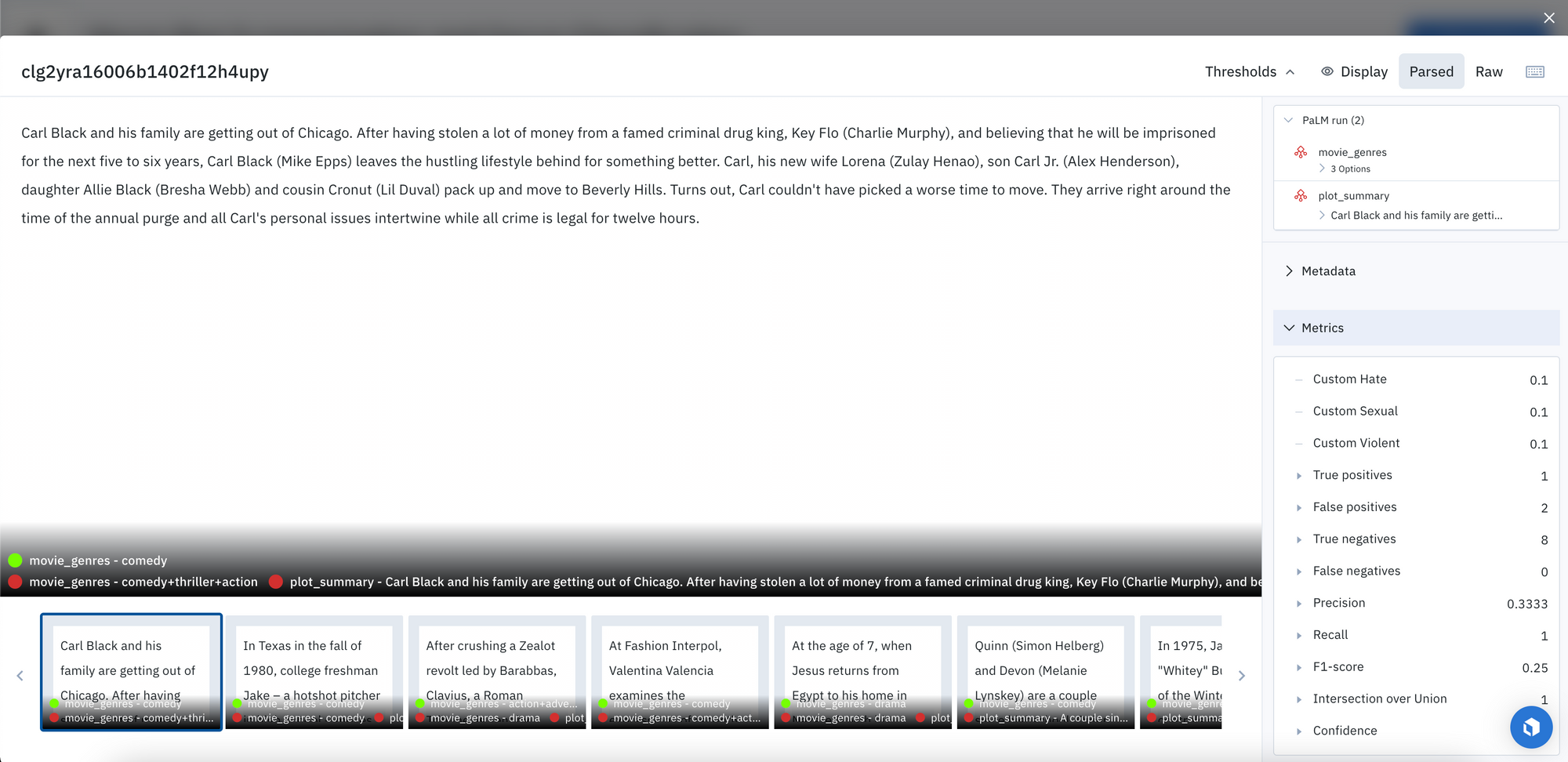
Quantitative comparison
Multi-label classification is a challenging task, especially in the context of movie genre classification, where the models must make zero-shot predictions on how movies have been classified by the dataset creator. In addition, the models must accurately predict only the relevant genres and exclude any irrelevant ones, making the classification task even more complex.
In our evaluation, we found that both models demonstrate impressive out-of-the-box zero-shot performance. PaLM scored higher on the overall precision score, whereas GPT-4 scored higher on overall recall scores.
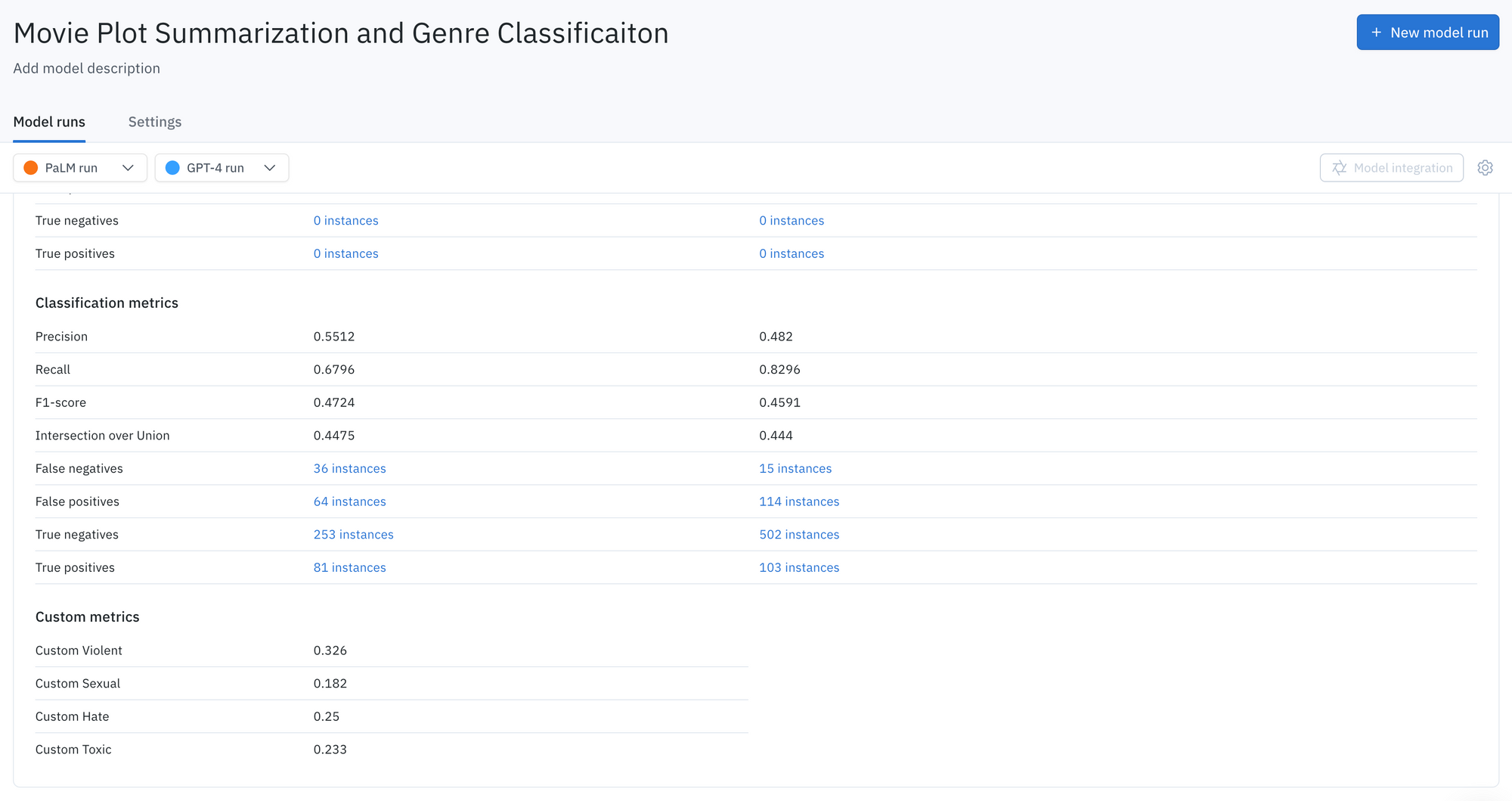
To gain a deeper understanding of each model’s performance, it is important to analyze where the models are performing well and where they might be struggling. By conducting an analysis by class, we can gain insight into specific areas where the models are successful and where they are falling short.
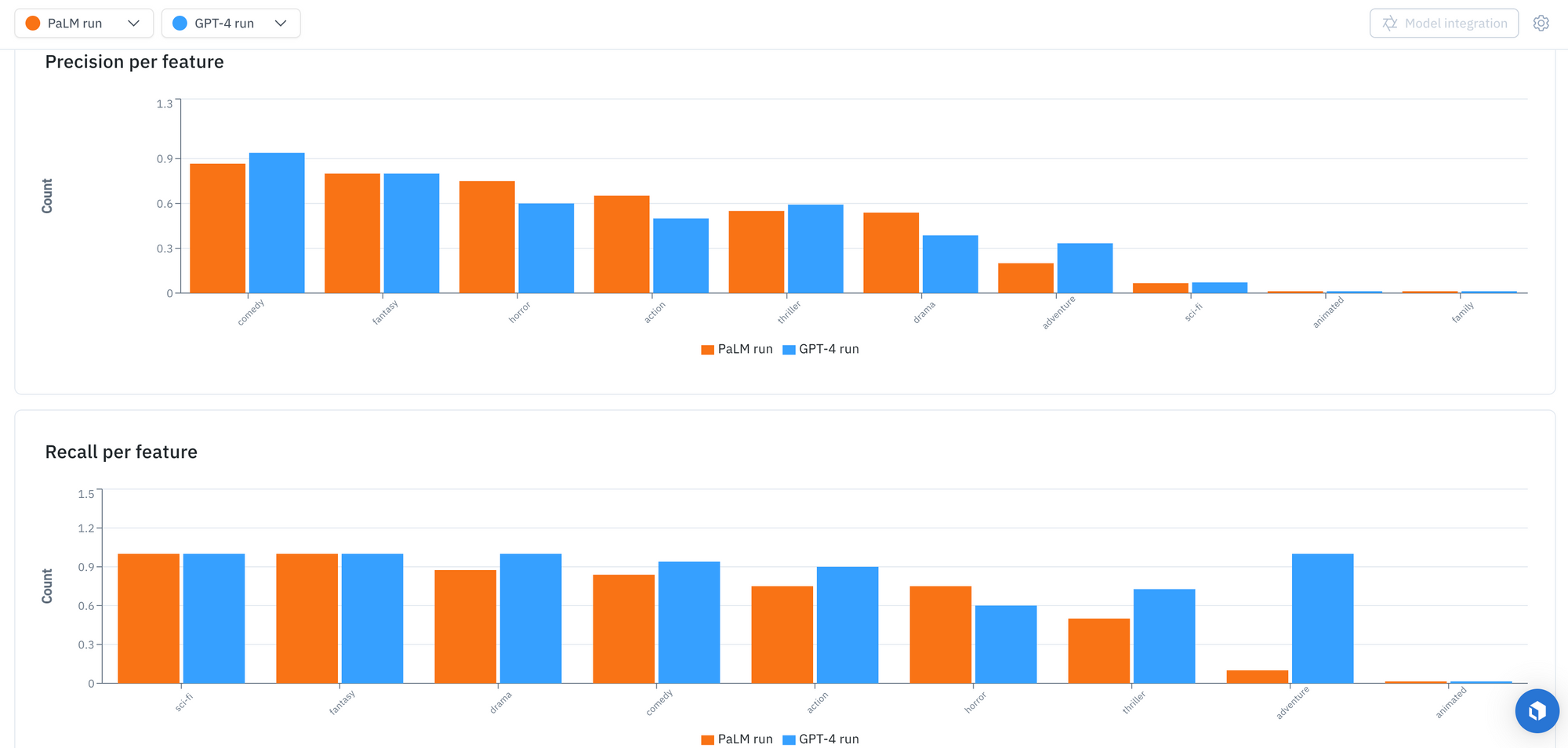
For example, although both models perform well in terms of recall for ‘sci-fi’ and ‘drama’ genres, they have a low precision score, indicating that both models are overly confident in assigning these labels to movie plots. As a result, only a small portion of 'sci-fi' genre predictions correspond to the actual ground truth labels, contributing to the low precision score. This is also true for GPT-4’s performance on the ‘adventure’ genre.
On the other hand, both models are very good at classifying ‘fantasy’ and ‘comedy’ genres. The genres ‘animated’ and ‘family’ had a very small sample size of only one data point each, which isn’t sufficient for meaningful analysis.
Qualitative comparison
Let’s now take a look at how GPT-4 and PaLM summarize selected movie plots. Overall, both models performed well in being able to capture the movie plot in a single sentence, although they differed slightly in their level of conciseness and abstraction. PaLM was able to generate shorter summaries, while GPT-4 was able to convey more captivating plot details.
Check out a few examples below:
Conclusion
Now, let’s consider and evaluate the performance of GPT-4 and PaLM in a real-world scenario. If you want to implement an automated workflow for tagging and summarizing text assets, such as movie plots in this case, both models could provide satisfactory results without any additional fine-tuning. However, the models' zero-shot predictions may not exactly match your requirements. For instance, both models are overly confident in predicting ‘sci-fi’ genre movies, leading to deviation from the original dataset’s labels. To address this issue, you could either perform more prompt tuning or fine-tune the models on several hundred examples of (movie plot, genre) pairs to train them to classify and summarize the texts according to your preferences.
In conclusion, both models perform well on multi-label classification and summarization tasks with zero-shot learning. PaLM outperforms GPT-4 in overall precision scores, while GPT-4 performs better in overall recall scores. Both models show similar performance, success and failure patterns, for certain movie genres. In terms of summarization, PaLM tends to produce shorter summaries, while GPT-4 is able to include more engaging plot details. A feature worthy of note is PaLM’s ability to attribute safety scores for its generated response, which can be greatly helpful for content moderation use cases.


